| Похожие рефераты | Скачать .docx |
Дипломная работа: Разработка программно–алгоритмических средств для определения надёжности программного обеспечения на основании моделирования работы системы типа "клиент–сервер"
ФЕДЕРАЛЬНОЕ АГЕНТСТВО ПО ОБРАЗОВАНИЮ
Государственное образовательное учреждение высшего профессионального образования
«Нижегородский государственный университет им. Н.И. Лобачевского»
Физический факультет
Кафедра физики полупроводников и оптоэлектроники
Дипломная работа
Разработка программно–алгоритмических средствдля определения надёжности программного обеспечения на основании моделирования работы системы типа "клиент–сервер"
студента 5–го курса
«Допустить к защите»
зав. каф. ФПО,
д.ф.–м.н., проф.
ПАВЛОВ Д.А.
Научный руководитель,
доцент каф. ФПО, к.ф.–м.н.
Рецензент:
доцент каф. ЭТТ, к.ф.–м.н.
Москва 2008 г.
Оглавление
Сокращения..................................................................................................... 4
Введение........................................................................................................... 5
1. Аналитический обзор литературы............................................................. 7
1.1 Надежность как характеристика качества ПО......................................... 7
1.2 Текущее состояние вопроса...................................................................... 9
1.3 Выводы.................................................................................................... 19
2. Теоретическая часть.................................................................................. 21
2.1 Существующие модели надежности ПО................................................. 21
2.2 Содержательная постановка задачи....................................................... 24
2.3 Разработка модели надежности ПО типа клиент–сервер...................... 29
2.3.1 Модель надежности клиентских программ......................................... 29
2.3.2 Модель с заменой вероятностей состояний на средние численности состояний........................................................................................................................ 34
2.3.3 Модель для случая N модулей–клиентов............................................ 37
2.3.4 Модель для случая l ¹ const............................................................... 42
2.4 Разработка обобщенной модели надежности ПО типа клиент–сервер 46
3. Экспериментальная часть.......................................................................... 52
3.1 Обоснование выбранного метода реализации....................................... 52
3.2 Алгоритм функционирования программы............................................ 52
3.3 Практические результаты моделирования............................................. 55
3.3.1 Оценка времени, необходимого для уменьшения количества ошибок до расчетного уровня......................................................................................... 55
3.3.2 Влияние количества клиентов на надежность ПО............................... 57
3.3.3 Влияние количества программистов на надежность ПО.................... 59
3.3.4 Влияние интенсивности обращений клиентов к серверу.................... 61
3.3.5 Определение начального количества ошибок в ПО........................... 62
3.3.6 Поиск начального количества ошибок в программе по начальной и конечной интенсивностям отказов................................................................................ 65
Выводы.......................................................................................................... 68
Список использованных источников............................................................ 70
Приложение А. Примеры моделей надежности ПО.................................... 73
ВС – вычислительное средство
ВТ – вычислительная техника
ЖЦ – жизненный цикл
КИС – корпоративная информационная система
ММП – метод максимального правдоподобия
МНК – метод наименьших квадратов
ООД – область определения данных
ОС – операционная система
ПИ – программное изделие
ПК – программный комплекс
ПО – программное обеспечение
ПТС – программно–техническое средство
СВМО – среднее время между отказами
СМО – система массового обслуживания
СПО – системное программное обеспечение
ТЗ – техническое задание
ТУ – технические условия
ЭП – экстремальное программирование
Архитектура современных корпоративных информационных систем (КИС) является, как правило, функционально распределенной. Она характеризуется многопотоковой организацией вычислений, при которой запросы реализуются параллельно и распределяются по нескольким процессорам (серверам). Основным средством реализации функций обработки информации и управления в таких системах является программное обеспечение (ПО). Существенной особенностью КИС является непрерывность процессов ввода и обработки информации, цикличный характер вычислительных процессов. В связи с этим важнейшей проблемой, возникающей при создании КИС, является обеспечение высокого уровня надежности их функционирования. В распределенных системах, архитектура которых обеспечивает возможность полного или частичного резервирования аппаратных средств, основным фактором, определяющим надежность функционирования, является программное обеспечение.
Многочисленные научные публикации [1-4] и накопленный опыт разработки программных систем в России и за рубежом свидетельствуют о том, что достаточно уверенно прогнозировать уровень надежности функционирования ПО весьма трудно. Проблема заключается в том, что существующие методы и модели прогнозирования надежности ПО не в полной мере пригодны для практического применения.
В настоящее время в области машинной обработки информации существуют две взаимосвязанные проблемы: стоимость обработки информации и ненадежность программного обеспечения, организующего и выполняющего процесс обработки информации. При этом первая проблема находится в зависимости от второй, так как высокая стоимость проектирования, тестирования и сопровождения программ обработки информации определяется прежде всего ненадежностью ПО [5].
Необходимость повышения надежности программного обеспечения обусловлена еще и тем, что в настоящее время ПО несет значительно большую функциональную нагрузку в решении задач управления, чем технические средства.
Поэтому целью данной дипломной работы разработка программно–алгоритмических средств для проведения оценки надежности программного обеспечения на основе построения модели надежности ПО, позволяющей проводить расчет характеристик надежности ПО (таких как, время наработки до отказа, коэффициент готовности, вероятность отказа) и на основе этой модели прогнозировать изменение этих характеристик во времени.
В качестве теоретической основы использованы: теория массового обслуживания, теория вероятностей, теория линейного программирования, методы разработки программного обеспечения, международные и отечественные стандарты по программному обеспечению. В качестве метода исследования выбран метод Монте–Карло.
В качестве информационных источников в работе использовались научные данные и сведения из книг, журнальных статей, а также международные и отечественные стандарты по разработке и применению программного обеспечения, результаты собственных расчетов и проведенных экспериментов.
1. Аналитический обзор литературы
1.1 Надежность как характеристика качества ПО
В работах [6-9] дается определение основных характеристик качества ПО, а также приводятся рекомендации по их измерению, даются метрики и критерии. В частности, дается номенклатура показателей надежности ПО. В стандарте [10] вводится шесть характеристик качества, в том числе для оценки надежности: завершенность, устойчивость к ошибкам, восстанавливаемость, согласованность, правильность работы, своевременность. Основные показатели качества ПО отображены в таблице 1.
Таблица 1 – Показатели качества ПО
| Показатель |
Описание |
| Удобство сопровождения |
ПО должно быть таким, чтобы существовала возможность его усовершенствования в ответ на изменения требований заказчика или пользователя |
| Надежность |
Определяется рядом характеристик, таких как безотказность, защищенность и безопасность |
| Эффективность |
ПО должно разумно расходовать ресурсы и обладать достаточными скоростными и временными характеристиками |
| Удобство в использовании |
ПО должно быть удобным в эксплуатации и быть рассчитанным на технический уровень эксплуатирующего персонала, обладать соответствующим пользовательским интерфейсом и документацией |
Данные показатели не вытекают непосредственно из того, какие действия может выполнять программный продукт. Они характеризуют поведение программы при выполнении этих действий.
Надежность — один из важнейших факторов, определяющих общую производительность и эффективность систем. В связи с этим уже на стадии проектирования системы вопросам надежности должно уделяться пристальное внимание. В этот период, когда устанавливается первоначальная взаимозависимость между характеристиками системы, затратами и графиком выполнения работ, должны быть сформулированы и требования к надежности, так как именно они в значительной мере определяют реализуемость проекта и стоимость будущей системы.
В КИС компьютер, как часть системы, обычно выполняет функции управления и должен работать в режиме реального времени. Поэтому при разработке ПО необходимо учитывать аппаратные средства, средства взаимодействия с пользователем и среду окружения [8]. Поскольку многие свойства ПО сложной системы проявляют себя только тогда, когда она собрана целиком и запущена в рабочий режим, то не учет этих факторов в совокупности может привести к построению ненадежного ПО. График соотношения надежности ПО и аппаратуры показан на рис. 1.
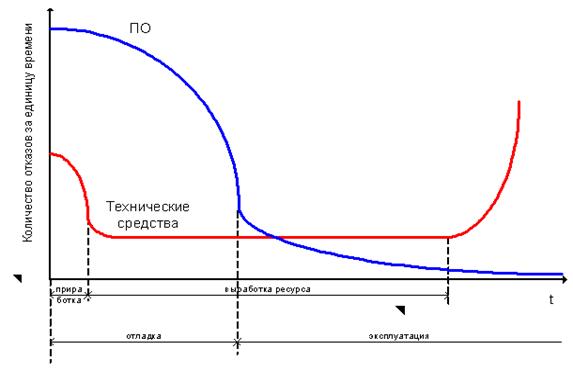
Рисунок 1 – Соотношение надежности программы и аппаратуры
Можно выделить три типа системных (программно–аппаратных) компонентов, склонных к отказам:
аппаратные средства системы, отказывающие либо из–за ошибок конструирования, либо из–за ошибок изготовления, либо из–за износа (старения), либо из–за эксплуатации в тяжелых недопустимых по ТУ условиях;
ПО системы, которое может отказать из–за ошибок в спецификациях, в архитектуре, в программном коде;
человеческий фактор, который своими действиями нарушает запланированную работу системы либо производит незапланированные в ПО действия.
В данной дипломной работе будут рассмотрены вопросы надежности ПО.
В [11] говорится о высокой стоимости ПО как следствие его низкой надежности. Типичное распределение стоимости ПО приведено на рис. 2.
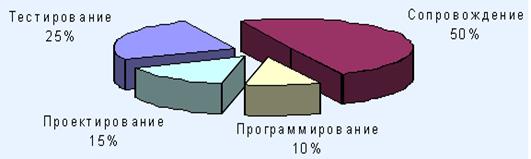
Рисунок 2 – Типичное распределение стоимости ПО
Отсюда делается вывод, что наилучший путь сокращения стоимости ПО – в уменьшении стоимости его тестирования и, главное, сопровождения, то есть в повышении надежности.
1.2 Текущее состояние вопроса
Теория надежности как наука получила развитие применительно к сложным техническим системам. Необходимость и полезность контроля технических компонент систем и систем в целом, с целью проверки соответствия их текущих характеристик заданным, доказаны практикой. В этом плане выполнено значительное количество работ по надежности применительно к техническим системам, разработано множество моделей обеспечения разумными методами надежности сложных систем и их технической готовности.
Эти модели в ряде случаев позволяют не только оценивать показатели надежности и готовности технических систем и их компонентов, но и дают возможность предсказывать значения этих показателей на основе накопленного опыта. Кроме того, ряд моделей позволяет на основе накопленных данных высказывать предположения в отношении режимов работы, при которых наиболее часто проявляются отклонения от нормального функционирования, а также о применяемом подходе к восстановлению (ремонту) системы или ее компонентов после сбоя.
Под системой в теории надежности принято понимать совокупность подсистем или элементов, функционально объединенных в соответствии с некоторым алгоритмом взаимодействия при выполнении заданной задачи в процессе применения по назначению. Под это определение системы полностью подходит программное обеспечение. В работе [12] указывается, что исследования в области программной надежности находятся на начальной стадии своего развития.
К основным проблемам исследований надежности ПО относятся:
прежде всего – разработка методов оценки и прогнозирования надежности ПО;
определение основных факторов, влияющих на надежность ПО;
разработка методов, обеспечивающих достижение заданного уровня надежности ПО;
совершенствование методов повышения надежности ПО в процессе проектирования и эксплуатации.
Основная причина ошибок в ПО – это его сложность. Для борьбы со сложностью выделяются две концепции:
независимость;
иерархическая структура.
В работе [11] приводится правило "n ± 1": Проверка правильности фазы n проекта должна осуществляться проектировщиками (исполнителями) фаз (n+1) и (n–1). Кроме того, в [11] приводится обоснование необходимости как можно более раннего обнаружения ошибок проектирования ПО. Оно заключается в том, что стоимость исправления ошибки со временем возрастает (рис. 3б), а вероятность правильно исправить ошибку – падает (рис. 3б).
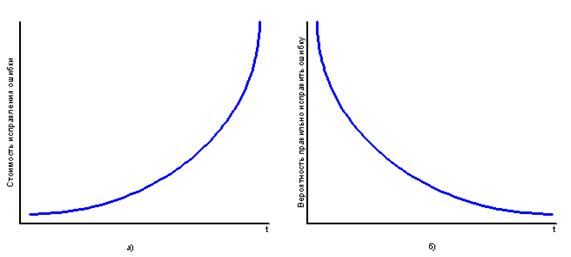
Рисунок 3 – Обоснование необходимости раннего обнаружения ошибки
При этом вероятность правильно исправить ошибку находится в противоречии с вероятностью обнаружить ошибку. Вероятность обнаружить ошибку возрастает со временем при уточнении требований заказчика и во время опытной эксплуатации. В этой связи важно решить задачу оптимизации времени обнаружения ошибки при минимальных затратах на ее исправление (см. рис. 4).
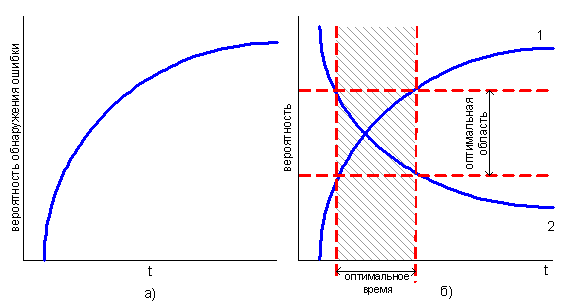
Рисунок 4 – Вероятность обнаружения ошибки и задача оптимизации
На рис.4а изображена зависимость вероятности обнаружить ошибку от времени, а на рис.4б: линия 1 – зависимость вероятности обнаружить ошибку от времени; линия 2 – вероятность исправить ошибку; также представлены области оптимального соотношения и оптимального времени для обнаружения и исправления ошибок в ЖЦ ПО.
Кроме того, дается определение тестирования и сопутствующих ему понятий. Тестирование – процесс выполнения программы с намерением найти ошибку. Валидация (испытание) – попытка найти ошибку, выполняя программу в заданной реальной среде.
Процентные частоты появления ошибок в ПО [13-15] по типам ошибок представлены в табл. 2.
Таблица 2 – Процентные частоты появления ошибок в ПО
| Тип ошибки |
Частота появления, % |
| Не полная или ошибочная спецификация |
28 |
| Отклонение от спецификации |
12 |
| Пренебрежение правилами программирования |
10 |
| Ошибочная выборка данных |
10 |
| Ошибочная логика или последовательность операций |
12 |
| Ошибочные арифметические операции |
9 |
| Нехватка времени для решения |
4 |
| Ошибка обработки прерываний |
4 |
| Ошибка в исходных данных |
3 |
| Неточная запись |
8 |
Как видно из таблицы 2, основное количество ошибок делается из–за неверной спецификации или ТЗ. Эти ошибки, в свою очередь, могут быть разделены на следующие категории:
Таблица 3 – Категории ошибок в ПО
| Причина ошибки |
Частота появления, % |
| Ошибки в числовых значениях |
12 |
| Недостаточные требования к точности |
4 |
| Ошибочные символы или знаки |
2 |
| Ошибки оформления |
15 |
| Неправильное описание или требование к аппаратуре |
2 |
| Исходные данные для разработки неполные, неточные или ошибочные |
52 |
| Двусмысленность требований |
13 |
Из этих таблиц следует, на что нужно обращать особое внимание при проведении валидации и верификации ПО.
Тестирование программы ведется до тех пор, пока интенсивность программных ошибок не уменьшится до заранее заданного уровня. Ориентировочно можно исходить из того, что интенсивность программных ошибок на этапе испытаний должна быть не больше интенсивности аппаратных отказов.
Программные отказы и аппаратные отказы имеют общие признаки:
объект не выполняет заданной функции;
времена до отказов и времена устранения отказов носят случайный характер;
методы обработки статистических данных одинаковы.
И отличия:
аппаратный отказ зависит либо от времени, либо от объема выполненной работы, а программный отказ – от той функции, которую выполняет изделие под управлением программы (то есть с какой вероятностью программа выйдет на участок, который содержит ошибку);
обнаружение и устранение аппаратного отказа не означает, что такой отказ не повториться, а обнаружение и устранение программной ошибки означает, что такой отказ больше не повториться (но могут появиться новые ошибки);
программный отказ может никогда не реализоваться при данных условиях эксплуатации программы;
аппаратные отказы подразделяют на внезапные и постепенные.
Программные отказы возникают, как правило, внезапно и по природе своей не совпадают с внезапными аппаратными отказами, так как вероятность их возникновения не связана с продолжительностью работы изделия. Она связана с условной вероятностью того, что программа содержит ошибку в данной части программы и вероятности того, что изделие будет работать под управлением этой части программы.
Если аппаратная часть жестко задана и интенсивность отказов ее не меняется (только увеличивается в результате старения), то ПО имеет в процессе эксплуатации ряд модификаций с уменьшающейся (в идеале) интенсивностью отказов. Следует иметь в виду, что ПО в ПТС определяет наибольшее количество ошибок. В настоящее время около половины отказов сложных вычислительных систем обусловлено ошибками ПО, а с ростом надежности технических средств составит 90% отказов от общего числа [16].
Можно выделить 4 группы принципов обеспечения надежности:
предупреждение ошибок;
обнаружение ошибок;
исправление ошибок;
обеспечение устойчивости к ошибкам.
В работе [17] говорится, что для повышения надежности программных комплексов необходимо применять разнообразие. Этот метод предполагает реализацию одной и той же функции разными алгоритмами и с применением разных средств разработки. Также предлагается применять глубоко эшелонированную защиту. Этот метод предполагает применение многоуровневой защиты с перекрытием, т.е. с перекрывающимися назначениями защит разных уровней. Предлагается применять также смягченную деградацию систем, т.е. когда часть системы при выходе из строя другой части частично берет на себя выполнение ее функций.
Возможные действия, направленные на минимизацию ошибок и сбоев:
предотвращение ошибок за счет структурного программирования;
сокрытие информации или дозированный доступ к данным со стороны программных средств и объектов в объектно–ориентированном программировании;
отладка;
устойчивость к сбоям;
обработка исключительных ситуаций (перехват ошибок, например, деление на ноль) и локализация ошибок и сбоев;
восстановление программы после сбоя;
верификация и валидация (верификация отвечает на вопрос, правильно ли и качественно ли создана программа, а валидация (или аттестация) – на вопрос правильно ли работает программа).
В работе [13] говорится о повышении надежности ПО с помощью введения избыточности. Для повышения надежности ПО пользуются методом резервирования. Для этого разрабатывают две или более различных по алгоритмам версий программы для решения одной и той же задачи. Для этого хорошо подходит метод, когда одну и ту же программу пишут две независимые группы программистов, даже если при этом они реализуют один и тот же алгоритм (задача не должна быть при этом тривиальной). Это очень ресурсоемкий метод и поэтому редко используется на практике. Такое ПО параллельно выполняется в процессе эксплуатации. Сюда же подходит метод быстрого, но не точного решения и долгого и точного, с последующим сравнением результатов. ПО считается правильно отработавшим, если результат сравнения удовлетворяет какому–либо критерию близости результатов, например разность результатов не должна превышать некоторого значения.
Надежность ПО повышается также с помощью применения различных методов тестирования. Полное тестирование ПО объективно невозможно, поэтому обычно применяют следующие виды тестирования:
тестирование ветвей;
математическое доказательство правильности алгоритма решения задачи (в некоторых работах именно в этом смысле употребляется слово верификация). В [11] показывается, что доказательство правильности программы с помощью исчисления предикатов первого порядка не исключает ошибки в программе, так как относится к доказательству правильности внутренней спецификации на конкретный модуль. Этот метод заключается в том, что с помощью аппарата формальной математической логики пишут входные условия и выходные утверждения, а затем показывают, что, производя над входными условиями действия согласно тем, что записаны в программе, получается выходное утверждение. Часто пользуются обратным методом, т.е. идут от выходного утверждения к входному утверждению. Этот метод труден и утомителен, а многие конструкции языков программирования не поддаются доказательству с точки зрения формальной логики. Этот метод не работает, если выходное утверждение само не правильно. Тогда можно доказать, что программа приводит к этому утверждению, но это оказывается бесполезно с практической точки зрения. Тем не менее, метод имеет право на жизнь, потому что позволяет обнаруживать ошибки во внутренней логике модуля, но применим в основном к программам численных вычислений и применим к незначительному подмножеству языка программирования;
символическое тестирование (или с помощью специально подобранных тестовых наборов), еще называется статическим тестированием. Удобно при локализации ошибки, проявление которой выявлено при конкретном узком или строго заданном диапазоне входных значений;
динамическое тестирование (с помощью динамически генерируемых входных данных), что удобно при быстром тестировании во всем широком диапазоне входных параметров;
тестирование путей выполнения программы;
функциональное тестирование;
проверки по времени выполнения программы;
проверка по использованию ресурсов и стрессовое тестирование.
В работе [8] говорится, что существует 4 основные составляющие функциональной надежности программных систем:
безотказность – свойство программы выполнять свои функции во время эксплуатации;
работоспособность – свойство программы корректно (так как ожидает пользователь) работать весь заданный период эксплуатации;
безопасность – свойство программы быть не опасной для людей и окружающих систем;
защищенность – свойство программы противостоять случайным или умышленным вторжениям в нее.
В этом случае высокий уровень функциональной надежности может быть достигнут только за счет уменьшения эффективности работы программы. В работе [19] говорится, что в соответствии с ГОСТ 19.004–80 различают следующие виды работ, направленные на устранение ошибок в ПО: проверка, отладка и испытание программы.
Чем интенсивнее использование ПО, тем быстрее выявляются в нем ошибки. На рис.5 приведена зависимость числа обнаруженных ошибок от числа использующих ПО пользователей:
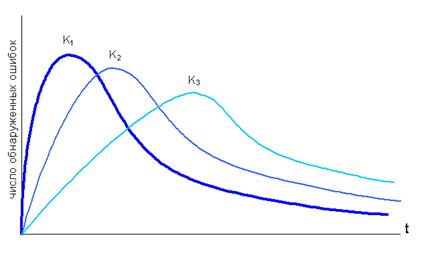
Рисунок 5 – Интенсивность обнаружения ошибок от интенсивности использования, где K – число пользователей, K1 > K2 > K3.
В [19] подчеркивается, что при заключительных приемо–сдаточных и сертификационных испытаниях для определения надежности ПО организуются многочасовые и многосуточные прогоны функционирования комплекса программ в реальной или имитационной внешней среде в условиях широкого варьирования исходных данных с акцентом на стрессовые ситуации.
Если интенсивное тестирование программ в течении достаточно длительного времени не приводит к обнаружению дефектов или ошибок, то создается ощущение бесполезности дальнейшего тестирования, и программа передается на эксплуатацию. Экспериментальные исследования характеристик обнаружения ошибок в сложных программах позволило оценить темп обнаружения ошибок, при котором сложные комплексы программ передаются на регулярную эксплуатацию: 0,02 – 0,05 ошибок в день на человека, т.е. специалисты выявляют только около одной ошибки каждые два месяца.
Интенсивность обнаружения ошибок ниже 0,001 ошибок в день на человека, т.е. меньше одной ошибки в год на 3–4 специалистов, по видимому, может служить эталоном высокого качества отладки и надежности для ПО обработки информации и соответствует очень высокому уровню наработки на отказ » 5 – 10 тысяч часов.
В [20] к числу основных факторов, влияющих на надежность ПО отнесены:
взаимодействие ПО с внешней средой (программно–аппаратная средства, трансляторы, ОС). Этот фактор вносит наименьший вклад в надежность ПО при современном уровне надежности аппаратуры, ОС и компиляторов;
взаимодействие с человеком (разработчиком и пользователем) (см. например метрику Холстеда);
организация ПО (проектирование, постановка задачи и способы их достижения и реализации) и качество его разработки. Этот фактор вносит наибольший вклад в надежность;
тестирование.
В соответствии с этим способы обеспечения и повышения надежности ПО могут быть следующими:
усовершенствование технологии программирования (например, формальное описание этапов программирования при помощи языка UML);
выбор алгоритмов, не чувствительных к различного рода нарушениям вычислительного процесса (использование алгоритмической избыточности);
резервирование программ – N–версионное программирование;
верификация и валидация программ с последующей коррекцией.
1.3 Выводы
На основе сделанного обзора можно констатировать: на сегодняшний день отсутствует общее решение проблемы надежности ПО и есть много частных решений, не учитывающие такие существенные факторы как интенсивность внесения и устранения ошибок в программе, время разработки ПО. Ни одна из моделей не может считаться достаточной для оценки надежности. Таким образом, сегодняшний уровень понимания проблемы надежности, в основном качественный, позволяет нам рассматривать программу как черный ящик с поступающими ему на вход данными и внешними воздействиями, а на выходе выдающий нам поток ошибок, устраняемый с большим или меньшим успехом. Стоит актуальная задача построения более совершенных моделей. В данной дипломной работе предлагается модель, основанная на марковской теории систем массового обслуживания (СМО), с решением задачи появления и устранения ошибок в программе как марковского процесса гибели и размножения с непрерывным временем и нахождением его характеристики.
2. Теоретическая часть
2.1 Существующие модели надежности ПО
Прогнозирование надежности ПО в процессе его эксплуатации осуществляется на основе математических моделей надежности программ.
В работе [11] приведены вероятностные модели надежности. Теория надежности для аппаратного обеспечения развита довольно хорошо, и, как показано выше, есть применить ее и к надежности ПО. В этих моделях ищется число ошибок, оставшихся в программе. Это необходимо знать для завершения процесса тестирования, и оценки стоимости сопровождения, которая пропорциональна количеству оставшихся в программе ошибок. Также эти модели позволяют находить надежность программы, которая понимается как вероятность, что программа будет функционировать без ошибок в течение заданного интервала времени, а также – среднее время между отказами программы.
В [20] дается классификация моделей надежности ПО. Наиболее известных моделей надежности ПО в настоящее время существует около десятка, поэтому в данной работе они сгруппированы по признакам. В качестве классификационных признаков выбраны следующие (рис.6):
временная структура процессов проявления ошибок в ПО (время появления ошибки, количество ошибок за заданный интервал времени);
сложность программы (мера сложности ПО – длина, количество функций или модулей, данных и т.п.);
разметка ошибок (искусственное внесение в ПО известных ошибок);
структура пространства входных данных;
структура текста программы (распределение ошибок по тексту программы).
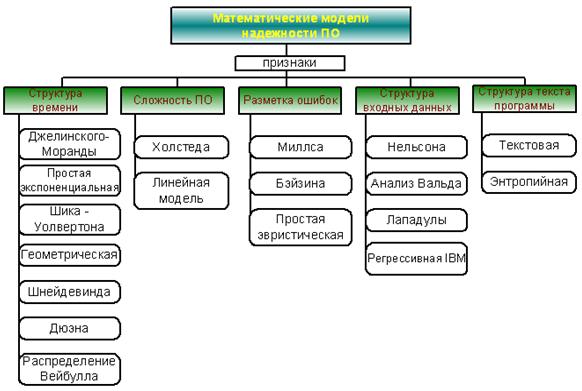
Рисунок 6 – Классификация моделей надежности ПО
Как показано в [19] на практике простейшие, элементарные ошибки программ и данных могут приводить к катастрофическим последствиям при функционировании ПО. В то же время, крупные системные дефекты могут только несколько ухудшать эксплуатационные характеристики ПО. Поэтому невозможно ранжировать типы первичных ошибок по степени влияния на надежность и следует одинаково тщательно относиться к их обнаружению и устранению.
Статистика ошибок в комплексных программах и их характеристики могут служить ориентиром для разработчиков при распределении усилий на отладку и предохранять их от излишнего оптимизма при оценке достигнутого качества и надежности ПО. Они помогают:
оценивать реальное состояние проекта и планировать необходимые трудоемкость и длительность до его завершения;
выбирать методы и средства проектирования, программирования и тестирования.
Регистрация, сбор и анализ характеристик ошибок в программах является сложным и трудоемким процессом. Поэтому имеется относительно небольшое число работ, в которых опубликованы реальные характеристики ошибок.
При автономной, и в начале комплексной отладки доля системных ошибок невелика (~ 10%), но она существенно возрастает (до 35–40%) на завершающих этапах комплексной отладки. В процессе сопровождения системные ошибки являются преобладающими (~ 80% от всех ошибок).
Различными авторами были сделаны ряд уточнений вышеизложенной модели (к настоящему времени предложено около 15 математических моделей для описания количества ошибок в ПО различной степени сложности). Однако ни одна из этих моделей не имеет явных преимуществ по точности аппроксимации распределений и прогнозирования числа ошибок в программах по сравнению с простейшей экспоненциальной моделью. Обзор наиболее характерных моделей надежности ПО дается в Приложении А.
В работе [20] дается сравнение моделей. Модели Джелинского–Моранды и Шика–Уолвертона целесообразны при моделировании надежности ПО небольшого объема, а модифицированная модель Шика–Уолвертона – для ПО больших проектов. Если при моделировании необходимо получить значения надежности (например, среднюю наработку до отказа), то лучше использовать геометрические модели. Некоторые модели не имеют решений (то есть расходятся при определенных входных условиях). Если имеются данные об интервалах времени между ошибками, то лучше воспользоваться геометрической моделью, а если имеются данные о числе ошибок, приходящихся на единицу времени, то лучше применять модель Шнейдевинда. Экспоненциальная и дискретная модели были проверены при тестировании реальных программ и хорошо соответствуют действительности [21].
В заключение в [20] делается вывод, что на сегодняшний день невозможно выбрать наилучшую модель среди десятка предложенных.
Из–за значительных неопределенностей во всех вышеописанных моделях в [11] рекомендуется использовать несколько моделей одновременно и объединять их результаты.
В [19] говорится, что модели дают удовлетворительный результат при относительно высоких уровнях интенсивности проявления ошибок, то есть при невысокой надежности ПО. В этих условиях математические модели предназначены для приближенной оценки:
потенциально возможной надежности функционирования программ в процессе испытаний и эксплуатации;
числа пропущенных ошибок;
время тестирования, требуемое для обнаружения следующей ошибки;
время, необходимое для обнаружения с заданной вероятностью большинства имеющихся ошибок.
Можно предположить, что оценки, приведенные для нескольких конкретных систем, позволят прогнозировать эти характеристики для других проектов. Вероятностный подход к надежности ПО должен дать ответ на один из самых сложных вопросов при тестировании ПО – когда нужно остановиться и завершить тестирование, то есть, в течении какого времени времени нужно тестировать программу, чтобы она удовлетворяла требованиям по надежности? С помощью предложенной в данной работе модели надежности можно получить ответ на этот вопрос.
2.2 Содержательная постановка задачи
Имеется ПО типа "клиент–сервер". Сервер обслуживает запросы от N программ–клиентов (далее просто клиенты, рис.7). В ПО равномерно по области определения входных данных (ООД) (A, B) расположены Er ошибок.
Ошибками (отказами) ПО являются:
Отказы в программе. Если ПО не модифицируется, то интенсивность его отказов остаётся постоянной.
Внутренние отказы в программе. Такие отказы обусловлены фундаментальными ограничениями алгоритма, используемого в ПО (например, использование эвристических алгоритмов может привести к случайным отказам).
Отказы, обусловленные ограничением на функционирование в реальном времени. В рассматриваемых системах среда может изменяться динамически. Поэтому если планирования или расчёта отклика слишком велико, то к моменту выполнения отклика среда может быть уже изменена настолько, что вычисленный или спланированный отклик не будет иметь требуемого эффекта.
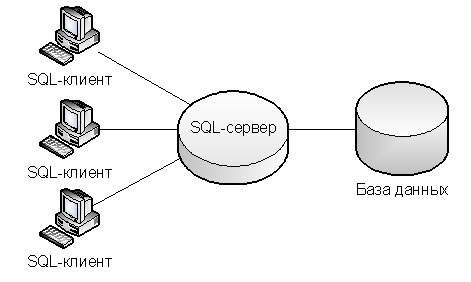
Рисунок 7 – Типовая клиент-серверная структура
Сервер сложнее программ–клиентов с точки зрения разработки ПО в S раз. S – коэффициент сложности сервера по отношению к клиентам. Каждый k–ый (k = 1, 2, …, N) клиент порождает пуассоновский поток данных к серверу интенсивностью lобр. Данные от клиента распределены по ООД по нормальному закону с характеристиками mk и sk, где mk распределено между клиентами равномерно по всей области входных данных, 3sk – распределено равномерно на меньшем из участков отсекаемых mk на оси области данных. Это нужно для имитации неравномерности использования ООД при малом количестве клиентов.
На запрос клиента сервер отвечает данными, которые распределены равномерно по всей области определения данных (A, B).
На рис. 8 изображено распределение запросов одного клиента по области всех возможных запросов к серверу, а также показано равномерное распределение ошибок по ООД. При попадании запроса клиента или ответа сервера в область ООД, содержащую ошибку, считается, что ошибка обнаружена и соответствующий модуль выводится из эксплуатации для ее исправления:
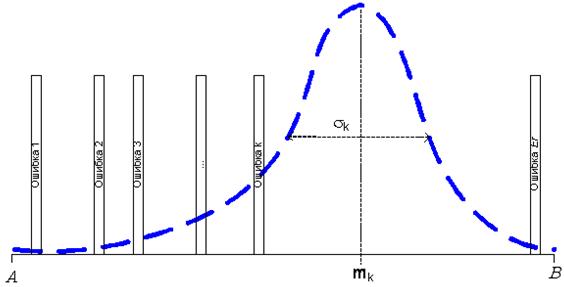
Рисунок 8 – Распределение запросов k–го клиента на области данных
Входными данными для модели являются:
P – количество программистов, обслуживающих систему;
K – количество программ–клиентов;
a – ширина одного запроса клиента как доля от ООД (от 0 до 1, где 1 – это вся ООД);
Dt – шаг итерации (сутки);
s – коэффициент сложности сервера по сравнению с программой–клиентом;
lобр – интенсивность потока обращений одного клиента к серверу (1/сутки);
lиспр – интенсивность потока исправления ошибки одним программистом (1/сутки);
lвнес – интенсивность внесения ошибки при исправлении одним программистом (1/сутки) или
pвнес – вероятность внести ошибку при исправлении одним программистом;
M – количество итераций (количество попыток обращений программ–клиентов к серверу в одном розыгрыше);
R – количество розыгрышей для усреднения;
Er – начальное количество ошибок.
Для моделирования потоков запросов в ПО применяется метод Монте–Карло.
Также есть возможность оценить первоначальное количество ошибок по следующему алгоритму: Принимаем ООД за единицу. Каждый клиент в запросе генерирует долю a от ООД. За время Dt клиент обратиться к серверу (Dt*lобр) раз. За время Dt все клиенты обратятся к серверу (Dt*lобр*K) раз. И объем данных, который будет затронут в ООД при этом равен (Dt*lобр*K*a). Так как в нашей модели ошибки распределены равномерно по ООД, то за время Dt будет обнаружено (Dt*lош), где lош – первоначальная интенсивность ошибок в системе. Если бы за время Dt клиенты затронули всю ООД, то было бы обнаружены все Er ошибок. Поэтому можно записать следующую пропорцию:
![]() .
.
Отсюда находим Er:
![]() .
.
При этом считается, что каждый из K клиентов обратился к серверу с запросом с данными непересекающимися в ООД. Однако в реальности клиенты чаще всего обращаются к серверу с однотипными запросами, поэтому полагаем К=1. Тогда первоначальное количество ошибок можно оценить как:
![]()
Поставленная задача позволяет определить такие важные характеристики функционирования программного комплекса, как:
расчет текущего времени наработки до отказа;
расчет среднего времени наработки до отказа за все время моделирования работы системы;
расчет вероятности отказа ПО в единицу
расчёт коэффициента готовности
Таким образом, наша задача может использоваться для предсказания характеристик ПО и оценки времени, необходимого затратить для достижения заданного уровня надежности ПО при имеющихся ресурсах, выработки рекомендаций по повышению надежности ПО.
Данная задача имеет смысл для систем типа "клиент-сервер" с целью определения надёжности системы на этапе тестирования.
2.3 Разработка модели надежности ПО типа клиент–сервер
2.3.1 Модель надежности клиентских программ
С помощью метода динамики средних [22] построим марковскую модель поведения программы состоящей из многих (примерно однотипных) модулей или (что сейчас применяется наиболее часто) построим модель программной системы типа "клиент–сервер". Характерной особенностью такой системы является запуск сервером параллельных однотипных потоков, каждый из которых обслуживает запросы одной программы–клиента или работа сервера со многими однотипными клиентскими программами. В этом случае потоки или программы–клиенты полностью идентичны и каждый из них может выходить из строя независимо от остальных. Особенностью этой системы в отличие от систем, рассматриваемых в теории массового обслуживания, (например, обслуживание ремонтной бригадой автомобиля, или однотипных аппаратных комплексов) заключается в том, что при выходе из строя (обнаружении ошибки) в одном модуле (потоке или клиенте) и устранении этой ошибки, эта ошибка автоматически устраняется и во всех других модулях (потоках), так как эти потоки размножаются путем запуска на выполнение одного и того же кода программы. Учтем эту особенность при применении метода динамики средних. При этом временем на замену модуля с ошибкой на исправленный модуль мы пренебрегаем.
Метод динамики средних представляет собой удобный математический аппарат только в том случае, когда число возможных состояний системы S сравнительно велико (от нескольких десятков и более). В этом случае обычный математический аппарат теории непрерывных марковских цепей перестает быть удобным. Метод динамики средних позволяет составить и решить уравнения непосредственно для интересующих нас средних характеристик, минуя использование вероятности состояний.
Итак, пусть имеется сложная (типа клиент – сервер) программная система S, состоящая из большого числа однородных модулей (потоков или клиентов) N, каждый из которых может случайным образом переходить из состояния в состояние. Пусть (для простоты) все потоки событий (в случае программы – это потоки внешних данных или запросов от клиентских программ к серверу), переводящие систему S и каждый ее модуль из состояния в состояние – пуассоновские (может быть даже с интенсивностями, зависящими от времени). Тогда процесс, протекающий в системе, будет марковским.
Допустим, что каждый модуль может быть в любом из n возможных состояний: x1, x2, …, xn, а состояние системы S в каждый момент времени характеризуется числом элементов (модулей), находящихся в каждом из этих состояний. Исследуем процесс, протекающий в системе S. Отвлечемся от возможных состояний системы в целом (а именно, SN, 0, …, 0 – все модули находятся в состоянии x1, а в других состояниях нет ни одного элемента; SN–1, 1, …, 0 – один элемент находится в состоянии x2, все остальные – в состоянии x1 и так далее. Очевидно, таких состояний будет очень много – N!), поэтому рассмотрим отдельный модуль x (так как все модули одинаковы) и рассмотрим для него граф состояний (рис.9).
Введем в рассмотрение случайную величину Xk(t) – число модулей, находящихся в момент времени t в состоянии xk. Будем ее называть для краткости численностью состояния xk в момент t. Очевидно, что для любого момента времени t сумма численностей всех состояний равна общей численности модулей:
![]() .
.
Xk(t) для любого фиксированного момента времени t представляет собой случайную величину, а в общем случае – случайную функцию времени. Найдем для любого t основные характеристики случайной величины – ее математическое ожидание mk(t) = M[Xk(t)] и дисперсию Dk(t) = D[Xk(t)].
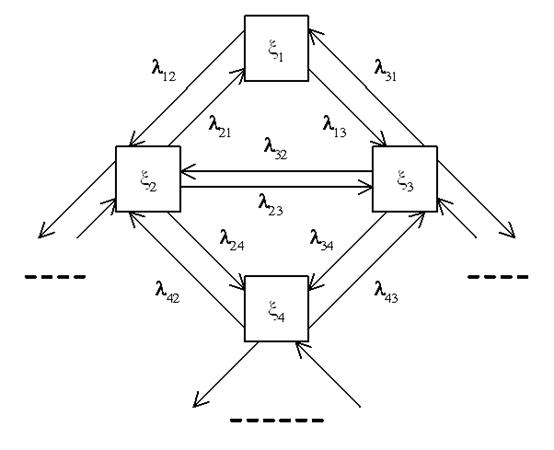
Рисунок 9 – Граф состояний одного модуля
Для того, чтобы найти эти характеристики, нам надо знать интенсивности всех потоков событий, переводящих модуль (элемент) (не всего комплекса программ, а именно модуль) из состояния в состояние (см. рис.9). Тогда численность каждого состояния Xk(t) можно представить как сумму случайных величин, каждая из которых связана с отдельным (i–тым) модулем, а именно: равна единицы, если этот модуль в момент времени t находится в состоянии xk, и равна нулю, если не находится в этом состоянии:
![]() (1)
(1)
Очевидно, для любого момента времени t общая численность состояния xk равна сумме случайных величин (1):
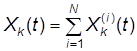 .
.
По теореме сложения математических ожиданий и теореме сложения дисперсий получаем:
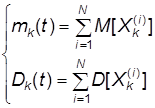 (2)
(2)
Найдем основные характеристики – математическое ожидание и дисперсию – случайной величины ![]() , заданной выражением (1). Эта величина имеет два возможных значения: 0 и 1. Вероятность первого из них равна pk(t) – вероятности того, что модуль находится в состоянии xk (так как программные модули одинаковы, то для всех эта вероятность одинакова). Ряд распределения каждого из случайных величин
, заданной выражением (1). Эта величина имеет два возможных значения: 0 и 1. Вероятность первого из них равна pk(t) – вероятности того, что модуль находится в состоянии xk (так как программные модули одинаковы, то для всех эта вероятность одинакова). Ряд распределения каждого из случайных величин ![]() один и тот же и имеет вид:
один и тот же и имеет вид:
| возможное значение (xj): |
0 |
1 |
| вероятность (pj): |
1–pk(t) |
pk(t) |
Математическое ожидание случайной величины, заданное таким рядом, равно:
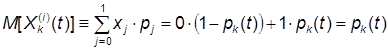
А дисперсия:
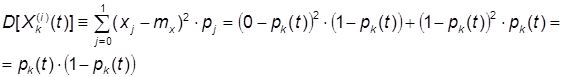
Подставляя эти вероятности в формулы (2), найдем математическое ожидание и дисперсию численности каждого состояния Xk(t):
![]() (3)
(3)
![]() (4)
(4)
Таким образом, нам удалось для любого момента времени t найти математическое ожидание и дисперсию численности состояния xk. Зная их, можно для любого момента времени t указать ориентировочно диапазон практически возможных значений численности:
![]()
Итак, не определяя вероятностей состояний программной системы S в целом, а опираясь только на вероятности состояний отдельных модулей, можно оценить, чему равна для любого момента времени t численность каждого состояния. Если мы знаем вероятности всех состояний одного модуля p1, p2, …, pn, как функции времени, то нам известны и средние численности состояний m1, m2, …, mn и их дисперсии D1, , D2, …, Dn.
Таким образом, поставленная задача сводится к определению вероятностей состояний одного отдельного модуля. Эти вероятности, как известно, могут быть найдены как решение дифференциальных уравнений Колмогорова. Для этого нужно знать интенсивности потоков событий (интенсивности запросов от клиентов и интенсивности восстановлений), переводящих каждый модуль из состояния в состояние.
Заметим, что вместо дифференциальных уравнений для вероятностей состояний удобнее писать уравнения непосредственно для средних численностей состояний, что видно из (3).
2.3.2 Модель с заменой вероятностей состояний на средние численности состояний
Пусть программа S состоит из N одинаковых модулей (или потоков) и граф состояния каждого модуля представлен на рисунке:
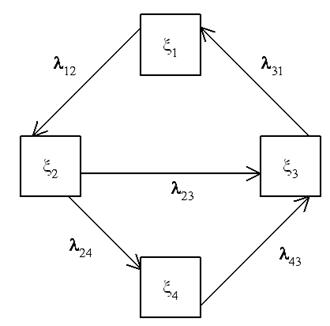
Рисунок 10 –Граф состояний модуля
В начальный момент времени t = 0 все модули находятся в состоянии x1.
Непосредственно по графу (см. рис. 10) составляем уравнения Колмогорова для вероятностей состояния;
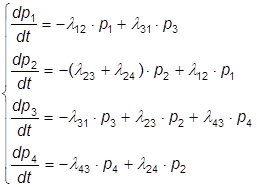 (5)
(5)
Умножим левую и правую части каждого из уравнений (5) на число модулей N и введем в левых частях N под знак производной, а также учтем (3), тогда:
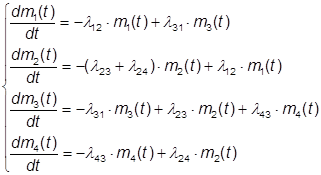 (6)
(6)
В системе уравнений (6) (которые называются уравнениями динамики средних) неизвестными функциями являются уже непосредственно средние численности состояний (точнее математические ожидания численности состояний). Как видно, эти уравнения составлены по тому же правилу, что и уравнения для вероятностей состояний. Поэтому их можно было составить сразу, минуя промежуточный этап.
Очевидно, что для каждого момента времени t средние численности состояний удовлетворяют нормировочному условию:
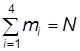 (7)
(7)
И поэтому одно (любое) из уравнений системы (6) можно отбросить. Отбросим, например, третье уравнение из (6), а в остальные уравнения вместо m3 подставим выражение согласно (7):
![]() .
.
Тогда окончательно получим:
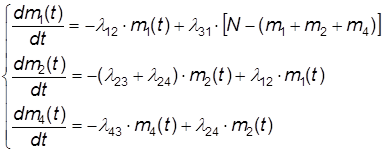 (8)
(8)
Эту систему нужно решать при начальном условии: t = 0; m1 = N; m2=m3=m4=0.
Решение такой системы дифференциальных уравнений (а для стационарного режима – системы алгебраических уравнений) легко провести на ЭВМ методом численного интегрирования.
Предположим, что это осуществлено и нами получены четыре функции m1(t), m2(t), m3(t) и m4(t). Найдем дисперсии численностей состояний D1(t), …, D4(t).
Из (3) и (4) следует:
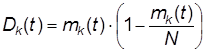 ,
,
где k = 1, … – число состояний модуля(9)
Зная математические ожидания и дисперсии численности состояний, мы получаем возможность оценить и вероятности различных состояний системы в целом, то есть вероятность того, что численность какого–то состояния будет заключена в определенных пределах. Действительно, так как число модулей N в программной системе велико, то по закону больших чисел можно полагать, что численность k–го состояния приближенно распределено по нормальному закону. И, следовательно, вероятность того, что случайная величина Xk (численность k–го состояния) будет заключена в границах от a до b, будет выражаться формулой:
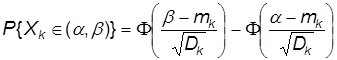 , где F(x) – функция Лапласа.
, где F(x) – функция Лапласа.
2.3.3 Модель для случая N модулей–клиентов
Распространим модель на наиболее часто встречающийся на практике случай, когда каждый модуль–клиент находится в одном из двух состояний: рабочем или нерабочем.о в нерабочем состоянии.
Пусть к серверу может обращаться N клиентов, порождающих N потоков. Каждый поток может находиться в одном из двух состояний:
x1 – рабочий;
x2 – не рабочий (обнаружена ошибка).
Переход модуля из состояния x1 в состояние x2 происходит под действием потока данных (запросов) с интенсивностью l; среднее время восстановления (обнаружения и исправления ошибки в модуле) модуля равно
![]() .
.
Составим уравнения динамики средних и решим их при условии, что в начальный момент все модули находятся в рабочем состоянии.
Граф состояний каждого модуля имеет вид, показанный на рисунке:
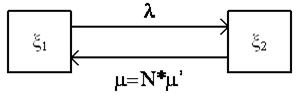
Рисунок 11 – Граф состояния модуля
где: m = N×m’ так как при исправлении ошибки в одном модуле, ошибка мгновенно исправляется во всех остальных модулях тоже;
m1(t) – среднее число функционирующих модулей в момент времени t;
m2(t) – среднее число не функционирующих программных модулей (потоков) в момент времени t.
Уравнение динамики средних будет:
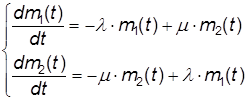 (10)
(10)
И начальное условие m1(0) = N при t = 0.
Учтем, что для любого момента времени t выполняется нормировочное условие, из которого следует что:
![]() (11)
(11)
Подставляя (1) в первое уравнение из (10), получим:
![]()
Решением этого уравнения будет:
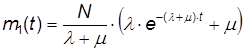 (12)
(12)
Из (11) и (12) находим m2(t):
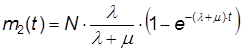 (13)
(13)
При t ® ¥ имеем стационарный режим:
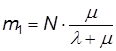 ;
;
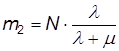 .
.
Построим на графике функции m1(t) и m2(t).
Для случая программной системы с большим количеством программ N, m будет всегда больше l. Это означает, что среднее количество работающих модулей m1 всегда будет больше среднего числа неработающих модулей m2. Причем в этом случае m = N×m’ и при N ®¥:
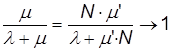 ,
, 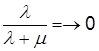
Отсюда можно сделать вывод, что чем больше пользователей системы (и чем больше количество потоков N), тем она надежнее или тем быстрее станет надежной.
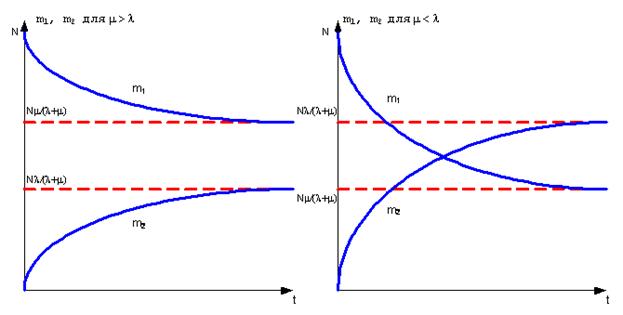
Рисунок 12 – Графики m1(t) и m2(t)
Определим дисперсию численностей состояний из (9):
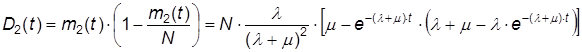
Очевидно, что дисперсии численности первого и второго состояния будут одинаковыми: D(t) = D2(t) = D1(t).
При t ® ¥
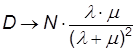
График функции D(t) изображен на рисунке:
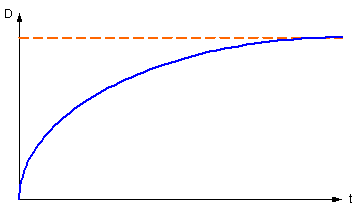
Рисунок 13 – График D
Например, в стационарном состоянии для N=200, l = 2 запроса/сутки и ![]() суток получим следующие значения:
суток получим следующие значения:
![]()
– число работающих модулей.
![]()
![]()
Вообще говоря, для полноты картины в модели нужно учесть, что интенсивность потока ошибок l ¹ const, и уменьшается со временем, так как количество ошибок в программе уменьшается на единицу с интенсивностью m и стремиться к некоторому постоянному уровню. Например,
![]()
Вообще, если быть более строгим в рассуждениях, то мы имеем дело фактически с одним объектом, который после каждого исправления становится новым объектом с новым количеством ошибок (не обязательно меньшим) и это говорит о том, что в данной системе нет отсутствия последействия, то есть процесс не пуассоновский, а, следователь:но, и не марковский. Поэтому, вообще говоря, нужно брать процесс Эрланга второй степени и применять метод приведения процесса к марковскому (метод псевдосостояний), описанный в [11]. Этот метод в работе не рассматривается из–за его сравнительной сложности и из–за того, что этим эффектом можно пренебречь при большом количестве состояний клиентов и/или большом количестве программ–клиентов, а также учитывая то предположение, что новый объект (новая программа) появляется мгновенно после исправления в ней ошибки.
2.3.4 Модель для случая l ¹ const
Итак, процесс работы клиент–серверного ПО зависит от количества исправленных в ней до этого ошибок. То есть от интенсивности потоков событий, переводящих элемент из состояния в состояние, зависят от того сколько элементов было в системе в данном состоянии. Чем большее количество раз ПО было на доработке (исправление ошибок в нем), тем меньше поток ошибок в будущем. Считаем, что ошибки исправляются корректно, то есть при исправлении не вносятся новые ошибки или вносятся, но гораздо реже, чем исправляются. При этом уменьшается интенсивность потока событий, переводящий каждый элемент (модуль или поток или процесс) ПО из состояния «исправен» (работоспособен) в состояние «неисправен».
Предложенный подход позволяет построить достоверную модель численности состояний ПО, исходя из этого предположения. Итак, пусть система S состоит из большого числа N однородных элементов (модулей или потоков одного модуля), каждый из которых может быть в одном из двух состояний:
x1 – работоспособен (работает);
x2 – не рабочий (обнаружена ошибка и исправляется).
На каждый модуль действует поток ошибок с интенсивностью l, которая зависит от количества исправленных ранее в модуле ошибок. Каждый неисправный элемент исправляется в среднем со скоростью m в единицу времени. В начальный момент (t = 0) все элементы (модули) исправны. Все потоки событий – пуассоновские (может быть с переменной интенсивностью). Напишем уравнения динамики средних для средних численностей состояний. Граф состояний одного модуля имеет вид, представленный на рисунке:
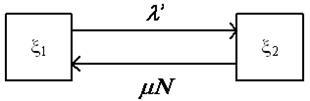
Рисунок 14 – Граф состояния модуля
Здесь l` – интенсивность потока ошибок в зависимости от предыдущих исправлений.
Найдем l` от числа предыдущих исправлений этого модуля. Выскажем предположение, что l` уменьшается с количеством исправленных ошибок до некоторого постоянного значения нечувствительности к исправлениям (например, когда количество исправленных ошибок становится равным количеству вносимых ошибок, или количество ошибок в модуле становится столь малым, что они начинают срабатывать с постоянной интенсивностью) по экспоненциальному закону и стремиться к некоторому минимуму тем быстрее, чем быстрее исправляются ошибки m – как показано на рис.15.
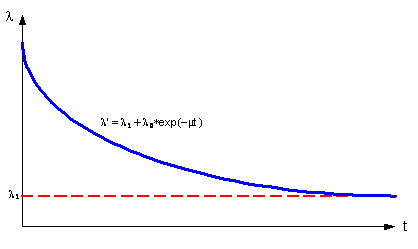
Рисунок 15 – Интенсивность потока ошибок
Для упрощения предположим, что l` обратно пропорционально m(m) числу модернизаций модуля, то есть убывает по гиперболическому закону:
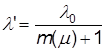 .(14)
.(14)
На основе графа (см. рис. 14) дифференциальные состояния динамики средних запишутся в виде:
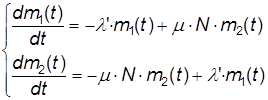 (15)
(15)
где m1(t), m2(t) – средние численности состояний x1 и x2.
Из этих двух уравнений можно выбрать одно, например, второе, а первое отбросить. Во второе уравнение подставим выражение для m1(t) из условия:
m1(t) + m2(t) = N.
Тогда получим вместо системы уравнений (15) одно дифференциальное уравнение:
![]()
Из предположения (14) имеем:
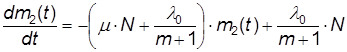 (16)
(16)
При этом количество модернизаций m зависит от интенсивности исправления модуля m и количества программистов (или групп программистов) P работающих над исправлением модулей. Предположим, что:
m(m) = m×P×t(17)
Окончательно получим уравнение для m2(t):
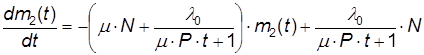 (18)
(18)
Решать это уравнение нужно при начальном условии m2(t=0) = 0 численными методами.
2.4 Разработка обобщенной модели надежности ПО типа клиент–сервер
Рассмотрим теперь уравнения смешанного типа. До сих пор мы описывали процессы, протекающие в ПО, либо с помощью уравнений для вероятностей состояний, либо с помощью уравнений динамики средних, где неизвестными функциями являются средние численности состояний. Уравнения первого типа применяются тогда, когда ПО сравнительно простое и его состояния сравнительно немногочисленны. Уравнения второго типа специально предназначены для описания процессов, происходящих в ПО, состоящего из многочисленных модулей. Для таких систем нам удалось найти не вероятности состояний, а средние численности состояний.
На практике чаще встречаются ситуации смешанного типа. Для такого ПО и напишем уравнения. Эта модель применима для ПО, которое состоит из элементов–модулей разного типа: немногочисленных (уникальных) (например, в архитектуре клиент–сервер это – сервер) и многочисленных (в архитектуре клиент–сервер это – клиенты), причем состояния тех и других взаимообусловлены.
В этом случае для модулей первого типа можно составить дифференциальные уравнения, в которых неизвестными функциями являются вероятности состояний. Для модулей же второго типа – средние численности состояний. Такие уравнения будем называть уравнениями смешанного типа.
Рассмотрим ПО S, состоящее из большого количества N одинаковых клиентских программ и одного сервера, который координирует работу всех клиентских программ. Как сервер, так и отдельные клиенты могут отказывать (зависать). Интенсивность потока отказов сервера зависит от числа x работающих программ–клиентов (то есть фактически зависит от интенсивности входных данных и их диапазона):
![]() (19)
(19)
Интенсивность потока неисправностей каждого модуля–клиента при работающем сервере равна l` (см. (14)).
Среднее время устранения ошибки в сервере, учитывая сложность сервера, больше чем среднее время устранения ошибки в клиенте:
![]() ,(20)
,(20)
где m0 – скорость устранения ошибок в клиенте (скорость исправления ошибки программистом), S – коэффициент сложности сервера.
Опишем процесс, протекающий в ПО, с помощью уравнений смешанного типа, в которых неизвестными функциями будут:
вероятности состояний сервера;
средние численности состояний клиентов.
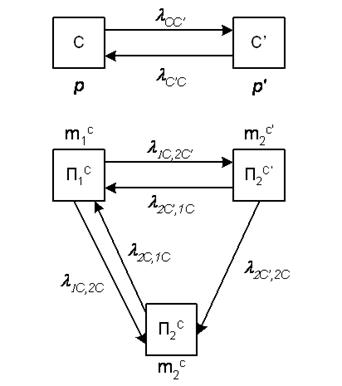
Рисунок 16 – Граф смешанной системы
Опишем нашу систему при помощи графа, показанного на рис.16. Этот граф распадается на два подграфа. Первый (верхний) – это подграф состояний сервера, который может быть в одном из двух состояний:
C(t) – работает;
С’(t) – не работает (ошибка обнаружена и исправляется).
Что же касается программы–клиента, то для нее мы учитываем возможность находиться в одном из трех состояний:
П1С(t) – клиент работает при работающем сервере;
П2С(t) – клиент не работает при работающем сервере;
П2С’(t) – клиент не работает при не работающем сервере;
Состояние сервера характеризуется в момент времени t одним из событий C(t) и C’(t). Вероятности этих событий обозначим через p(t) и p’(t) = 1 – p(t), а численности состояний П1С(t), П2С(t) и П2С’(t) соответственно: X1С(t), X2С(t) и X2С’(t).
Соответствующие математические ожидания обозначим как:
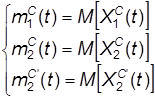 (21)
(21)
Очевидно, для любого момента времени t:
![]() (22)
(22)
где N – число клиентов, работающих с сервером.
Определим интенсивности потоков событий для графа (см. рис. 16). Прежде всего, по условию задачи (19):
![]() (23)
(23)
Из (20) следует:
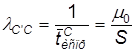 (24)
(24)
Далее, программа–клиент переходит из состояния П1С(t) в состояние П2С’(t) не сама по себе, а только вместе и одновременно с сервером (когда тот зависает). Поэтому:
![]() (25)
(25)
Аналогично:
![]() (26)
(26)
Для остальных переходов не трудно установить соответствующие интенсивности, если учесть тот факт, что второй (нижний) подграф отличается от рассмотренного ранее (см. рис. 14) только наличием еще одного состояния П2С’, когда клиентская программа простаивает на время исправления ошибки в программе–сервере. С учетом этого имеем:
![]() (27)
(27)
![]() (28)
(28)
![]() (29)
(29)
Напишем для графа (см. рис. 16) дифференциальные уравнения смешанного типа, приближенно описывающие нашу систему (аргумент t для краткости записи опущен):
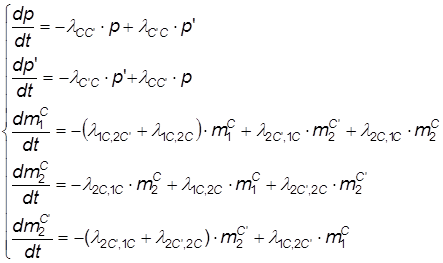 (30)
(30)
где:
![]()
![]()
Отметим, что, положив в (30) все левые части равными 0, можно найти решение для стационарного режима, а он существует, так как система эргодическая.
Заметим, что из этой системы уравнений можно исключить два уравнения: одно из первых двух, пользуясь уравнением p + p’ = 1, и одно – из последующих трех, пользуясь соотношением нормировки (22).
Эти уравнения решаются при условии, что в начале сервер и все программы–клиенты работают: t = 0; p = 1; p’ = 0; ![]() ;
; ![]() (31)
(31)
В случае, если важно исследовать, скажем, как быстро система восстанавливается при выходе из строя сервера, то начальные условия нужно выбрать другими: t = 0; p = 0; p’ = 1; ![]() ;
; ![]() ,
, ![]() (32)
(32)
3.1 Обоснование выбранного метода реализации
Основной проблемой нахождения надежности ПО при помощи моделей надежности является необходимость знать начальное количество ошибок в ПО. Эту величину определить достаточно трудно (практически не возможно).
Поэтому одним из преимуществ предлагаемой модели по сравнению с другими является то, что в ней не используется предположение о начальном количестве ошибок N0 в ПО. Вместо нее используются достаточно просто измеряемые характеристики ПО, такие как интенсивность появления ошибок и интенсивность устранения ошибок. Хотя предложенная модель надежности и не использует эту величину, тем не менее, можно воспользоваться ее результатами для нахождения начального количества ошибок в программе N0 методом обратного расчета. Это позволит найти такие характеристики надежности ПО, как время наработки до отказа, его вероятность и время достижения нужной надежности при заданных начальных условиях.
3.2 Алгоритм функционирования программы
Программа написана в интегрированной среде разработки программ Delphi с применением объектно-ориентированного (ОО) подхода, который обеспечивает более быструю и компактную реализацию алгоритма.
При одном розыгрыше выполняются следующие шаги:
Разыгрывается размещение Er ошибок на ООД, распределенных на ней равномерно;
Для каждого из K клиентов разыгрывается в начале и только один раз mki и ski.
Далее итеративно (M раз подряд) с шагом Dt для каждого клиента:
Если клиент исправен, то он может обращается с запросами к серверу с интенсивностью
lобр. Вероятность обращения клиента к серверу равна ![]() . В случае обращения клиента к серверу разыгрывается случайная величина xi, распределенное по нормальному закону с параметрами mki и ski – входное данное для запроса к серверу. Область, занимаемая входными данными запроса от одного клиента к серверу на ООД, есть величина xi ± a/2.
. В случае обращения клиента к серверу разыгрывается случайная величина xi, распределенное по нормальному закону с параметрами mki и ski – входное данное для запроса к серверу. Область, занимаемая входными данными запроса от одного клиента к серверу на ООД, есть величина xi ± a/2.
Если в интервал (xi ± a/2) попадает хотя бы одна ошибка на ООД, то считается, что в клиенте обнаружена ошибка, и он выводится из эксплуатации для ее исправления одним из свободных программистов. Если свободных программистов нет, то неисправный клиент становится в очередь и ожидает, когда один из программистов освободится.
Если в запросе клиента к серверу ошибки нет, то этот запрос направляется серверу на обработку и ответа. При этом разыгрывается ответ от сервера клиенту аналогично 3а). Если в область (xi ± a/2) попадает хотя бы одна ошибка из списка ошибок сервера, то считается, что в сервере произошла ошибка. В этом случае работа системы останавливается и все программисты пытаются исправить эту ошибку в сервере со скоростью lиспр каждый. Вероятность исправления ошибки одним программистом равна ![]() .
.
Если шаге 3b) в клиенте обнаружена на ошибка и есть свободный программист, то свободный программист пытается исправить ошибку в клиенте с вероятностью ![]() .
.
Если ошибка исправляется, то она удаляется из списка ошибок. Таким образом, эта ошибка уже не может возникнуть в других клиентах. При этом если есть клиенты, в которых была обнаружена такая же ошибка, то эти клиенты считаются тоже исправленными. При исправлении ошибки каждый программист может внести новую ошибку с вероятностью ![]() или pвнес. Причем, если программист внес ошибку в программу, то он может внести туда еще одну ошибку с вероятностью равной квадрату вероятности внесения предыдущей ошибки. Вновь внесенные ошибки вносятся в список ошибок. При этом эти новые ошибки не считаются обнаруженными в клиенте или сервере, то есть если обнаруженная ошибка исправляется, то клиент или сервер считается исправленными даже, если при этом были сделаны новые ошибки.
или pвнес. Причем, если программист внес ошибку в программу, то он может внести туда еще одну ошибку с вероятностью равной квадрату вероятности внесения предыдущей ошибки. Вновь внесенные ошибки вносятся в список ошибок. При этом эти новые ошибки не считаются обнаруженными в клиенте или сервере, то есть если обнаруженная ошибка исправляется, то клиент или сервер считается исправленными даже, если при этом были сделаны новые ошибки.
За один временной такт Dt разыгрывается сценарий обмена данными для всех работающих на этот момент времени клиентов. Для неисправных клиентов или неисправного сервера разыгрывается вероятностный процесс исправления ошибки в них.
В результате разыгрывается M итераций согласно п. 3, и получаем одну реализацию случайных функций ![]() ,
, ![]() ,
, ![]() и
и ![]() (согласно 3а) на временном интервале M*Dt.
(согласно 3а) на временном интервале M*Dt.
Испытания проводим еще R раз и таким образом получаем R реализаций случайных функций ![]() ,
, ![]() ,
, ![]() и
и ![]() . Для каждого момента времени tj (для j = 1, … M) с шагом Dt находим статистическое среднее для этих функций и получаем средние функции
. Для каждого момента времени tj (для j = 1, … M) с шагом Dt находим статистическое среднее для этих функций и получаем средние функции ![]() ,
, ![]() ,
, ![]() и
и ![]() .
.
Также в процессе розыгрыша производится:
Расчет текущего времени наработки до отказа;
Расчет среднего времени наработки до отказа за все время розыгрыша;
Расчет вероятности отказа ПО в единицу времени как P = (< объем запроса >*< количество ошибок в клиентах и сервере > х (< количество работающих клиентов > + 1)*< интенсивность обращения >*< шаг итерации по времени >;
Расчет коэффициента готовности: Кг = 1 – < время простоя всей программы > / < время работы >
Программа предупреждает, если задается интенсивность такая, что на интервал времени Dt приходится больше одного события (т.е Dt*l должно быть меньше единицы) – для соблюдения условия ординарности потока событий.
3.3 Практические результаты моделирования
3.3.1 Оценка времени, необходимого для уменьшения количества ошибок до расчетного уровня.
Найдем время необходимое для уменьшения количества ошибок в 2 раза. Пусть (рис.17):
K (кол-во программ-клиентов) = 10;
P (кол-во программистов) = 3;
a (ширина запроса клиента) = 0,0001;
N0 (начальное количество ошибок) = 100;
s (сложность сервера) = 2;
Dt (шаг итерации) = 0,001 (сутки);
lобр (интенсивность потока обращений клиента к серверу) = 100/сутки;
lиспр (интенсивность потока исправления ошибки) = 0,2/сутки;
pвнес (вероятность внесения ошибки при исправлении) = 0,005
M (количество итераций) = 200000;
Общее время розыгрыша: 200 (сутки);
К (число розыгрышей) =5.
По формуле (27) получаем: ![]() дня, что является очень оптимистичной оценкой. Для этой модели надежности Джелински, Моранда, Шумана получаем
дня, что является очень оптимистичной оценкой. Для этой модели надежности Джелински, Моранда, Шумана получаем ![]() лет, что явно сильно завышено. Программное моделирование дает результат T1/2 = 135 суток (рис.18).
лет, что явно сильно завышено. Программное моделирование дает результат T1/2 = 135 суток (рис.18).
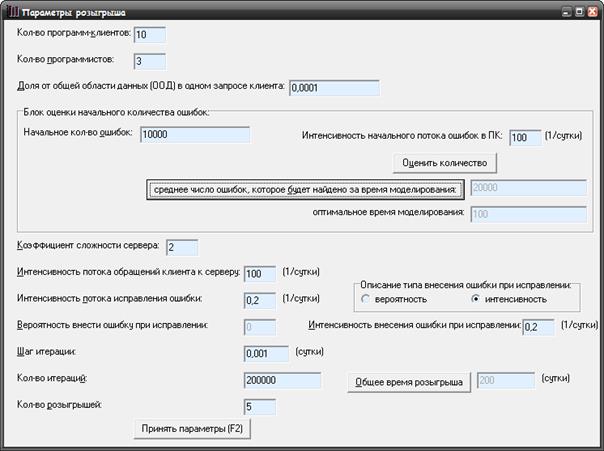
Рисунок 17 – Форма для ввода начальных параметров розыгрыша
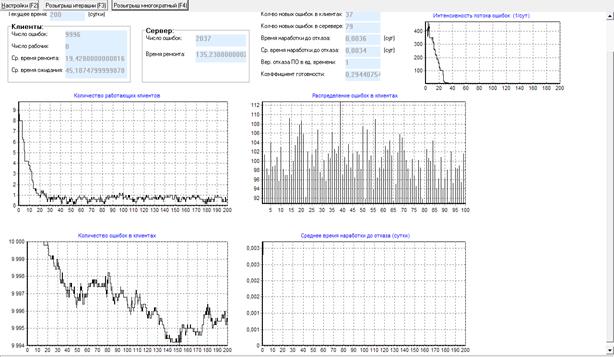
Рисунок 18 – Форма с результатами моделирования
3.3.2 Влияние количества клиентов на надежность ПО
Изучим влияние количества программ–клиентов на поведение ПО.
Сначала проведем моделирование при следующих условиях:
K (кол-во программ-клиентов) = 10;
P (кол-во программистов) = 3;
a (ширина запроса клиента) = 0,00001;
N0 (начальное количество ошибок) = 250;
s (сложность сервера) = 2;
Dt (шаг итерации) = 0,002 (сутки);
lобр (интенсивность потока обращений клиента к серверу) = 500/сутки;
lиспр (интенсивность потока исправления ошибки) = 1/сутки;
pвнес (вероятность внесения ошибки при исправлении) = 0,1/сутки
M (количество итераций) = 50000;
Общее время розыгрыша: 100 (сутки);
К (число розыгрышей) =50
Получены следующие результаты (рис.19):
Рисунок 19 – Влияние количества клиентов на надежность ПО (10 клиентов)
Из рисунка видно, что ПО начнет устойчиво работать (т.е. количество работающих клиентов сравняется с количеством неработающих клиентов) на 15 сутки, что хорошо согласуется с расчетной моделью. Теперь увеличим количество клиентов с 10 до 100:
K (кол-во программ-клиентов) = 100;
P (кол-во программистов) = 3;
a (ширина запроса клиента) = 0,00001;
N0 (начальное количество ошибок) = 250;
s (сложность сервера) = 2;
Dt (шаг итерации) = 0,002 (сутки);
lобр (интенсивность потока обращений клиента к серверу) = 500/сутки;
lиспр (интенсивность потока исправления ошибки) = 1/сутки;
pвнес (вероятность внесения ошибки при исправлении) = 0,1/сутки
M (количество итераций) = 85000;
Общее время розыгрыша: 170 (сутки);
К (число розыгрышей) =50
Видно, что на 170 сутки почти все ошибки исправлены (рис.20). Это происходит из–за того, что клиентов больше и их запросы охватывают большую область данных и, следовательно, обнаруживается большее количество ошибок и большее количество ошибок исправляется.
При десяти клиентах (рис.19) в ПО на 170 сутки еще будет оставаться около 50 ошибок.
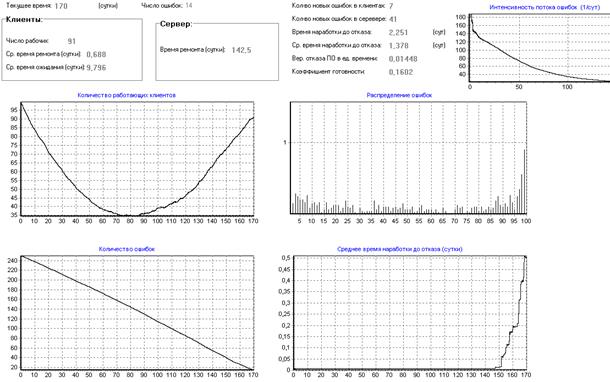
Рисунок 20 – Влияние количества клиентов на надежность ПО (100 клиентов)
3.3.3 Влияние количества программистов на надежность ПО
Теперь покажем, что при малой нагрузке на сервер (малом количестве клиентских программ) увеличение количества программистов, исправляющих ошибки, дает малый эффект. Количество неисправленных ошибок к концу тестирования остается таким же. Уменьшается только время ожидания программы исправления в очереди.
Начальные условия розыгрыша:
K (кол-во программ-клиентов) = 10;
P (кол-во программистов) = 12;
a (ширина запроса клиента) = 0,00001;
N0 (начальное количество ошибок) = 250;
s (сложность сервера) = 2;
Dt (шаг итерации) = 0,002 (сутки);
lобр (интенсивность потока обращений клиента к серверу) = 500/сутки;
lиспр (интенсивность потока исправления ошибки) = 1/сутки;
pвнес (вероятность внесения ошибки при исправлении) = 0,1/сутки
M (количество итераций) = 50000;
Общее время розыгрыша: 100 (сутки);
К (число розыгрышей) =50
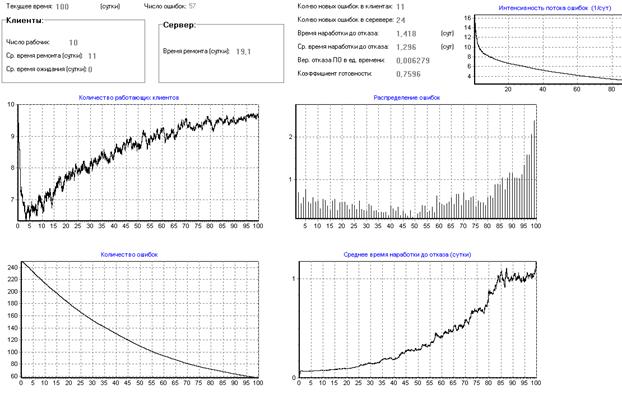
Рисунок 21 – Влияние количества программистов на надежность ПО
Видно (рис.21), что программа начнет устойчиво работать, как и раньше, только на 10–15 сутки, то есть увеличение количества программистов не приводит к ожидаемому эффекту, и часть программистов, скорее всего, будет простаивать.
Гораздо эффективнее в этой ситуации увеличивать нагрузку при тестировании. Например, увеличивая количество клиентов.
Увеличение количества программистов может оказать даже отрицательное влияние на надежность ПО, если при устранении ошибок в ПО они интенсивно вносят в него новые ошибки. Пусть при 12 программистах каждый из них вносит ошибку с интенсивностью 0,6 вместо 0,1 ошибок в сутки.
Начальные условия розыгрыша:
K (кол-во программ-клиентов) = 10;
P (кол-во программистов) = 12;
a (ширина запроса клиента) = 0,00001;
N0 (начальное количество ошибок) = 250;
s (сложность сервера) = 2;
Dt (шаг итерации) = 0,002 (сутки);
lобр (интенсивность потока обращений клиента к серверу) = 500/сутки;
lиспр (интенсивность потока исправления ошибки) = 1/сутки;
pвнес (вероятность внесения ошибки при исправлении) = 0,6/сутки
M (количество итераций) = 50000;
Общее время розыгрыша: 100 (сутки);
К (число розыгрышей) =50
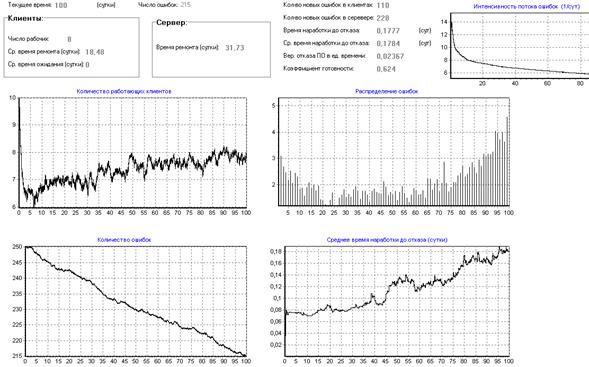
Рисунок 22 – Влияние количества программистов на надежность ПО
Из рис.22 видно, что за 100 дней работы системы количество ошибок практически не уменьшилось.
3.3.4 Влияние интенсивности обращений клиентов к серверу
Увеличение интенсивности обращения каждого клиента к серверу не дает ожидаемого эффекта, т.к. каждый клиент обычно работает в своей узкой части ОД и выбивает ошибки из этой части, при этом значительная ОД остается не проверенной, а значит с ошибками. Проведем розыгрыш при увеличении интенсивности обращений с 500 до 2500 в сутки (рис.23).
Начальные условия розыгрыша:
K (кол-во программ-клиентов) = 10;
P (кол-во программистов) = 3;
a (ширина запроса клиента) = 0,00001;
N0 (начальное количество ошибок) = 250;
s (сложность сервера) = 2;
Dt (шаг итерации) = 0,0004 (сутки);
lобр (интенсивность потока обращений клиента к серверу) = 2500/сутки;
lиспр (интенсивность потока исправления ошибки) = 1/сутки;
pвнес (вероятность внесения ошибки при исправлении) = 0,1/сутки
M (количество итераций) = 250000;
Общее время розыгрыша: 100 (сутки);
К (число розыгрышей) =10
3.3.5 Определение начального количества ошибок в ПО
Данная модель в сочетание с предложенной марковской моделью надежности ПО позволяет оценить количество ошибок в программе следующим образом – получить расчетный результат, а затем подобрать начальное количество ошибок в ПО таким образом, чтобы результаты розыгрыша совпадали с результатом расчета.
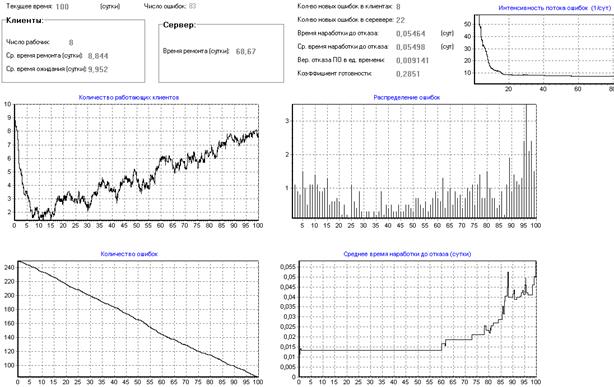
Рисунок 23 – Влияние интенсивности обращений клиентов к серверу
Для решения этой задачи с помощью программы моделирования необходимо добиться того, чтобы начальная интенсивность потока ошибок l0 из модели надежности ПО типа клиент–сервер совпадала с начальной интенсивностью потока ошибок в программе моделирования. Напрямую это сделать невозможно, так как в программе моделирования такого параметра нет. Для этого в программе моделирования нужно положить a = 0.5, то есть каждое обращение клиента к серверу и ответ сервера к клиенту должен с вероятностью 1 порождать ошибку. Затем необходимо добиться того, чтобы количество обращений за сутки клиентов к серверу (т.е. K*lобр) было равно l0. Остальные начальные параметры программы моделирования необходимо положить равными аналогичным параметрам модели надежности.
Найдем начальное количество ошибок для примера рассмотренного ранее. Для того чтобы начальная интенсивность потока ошибок в программе моделирования была равна l0=10, положим a = 0.5, а lобр при 3–х программистах положим равной 3,3. Итак:
Начальные условия розыгрыша:
K (кол-во программ-клиентов) = 10;
P (кол-во программистов) = 3;
a (ширина запроса клиента) = 0,5;
N0 (начальное количество ошибок) = 9;
s (сложность сервера) = 3;
Dt (шаг итерации) = 0,0001 (сутки);
lобр (интенсивность потока обращений клиента к серверу) = 3,3/сутки;
lиспр (интенсивность потока исправления ошибки) = 0,5/сутки;
pвнес (вероятность внесения ошибки при исправлении) = 0/сутки
M (количество итераций) = 100000;
Общее время розыгрыша: 10 (сутки);
К (число розыгрышей) =50
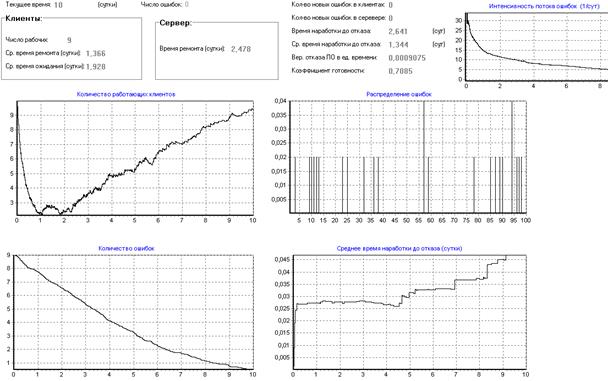
Рисунок 24 – Определение начального количества ошибок в ПО
Как видно из рис.24, при начальном количестве ошибок в программе равном 9 получили результат аналогичный полученному в модели, то есть клиенты начнут устойчиво работать на 4 сутки. Число 9 было получено методом подбора различных начальных значений количества Er ошибок в программе на начальный момент времени.
Таким образом, комбинируя модель и розыгрыш можно вычислить первоначальное количество ошибок в ПО и другие его характеристики.
3.3.6 Поиск начального количества ошибок в программе по начальной и конечной интенсивностям отказов
Наша модель позволяет решать обратную задачу, т. е. зная количество программистов, интенсивность их работы и интенсивность отказов в начале опытной эксплуатации и в конце опытной эксплуатации можно подобрать начальное количество ошибок в программе, совпадающее с ними.
Проведем такое исследование для периода опытной эксплуатации ПО и исследуем возможность передачи системы в промышленную эксплуатацию [25]. Известно, что ее обслуживает 3 программиста. Количество программ–клиентов – 10. Интенсивность отказов в начале опытной эксплуатации была 1 отказ в сутки. Через пол года работы получили интенсивность отказов – 1 отказ в месяц или 0,033 отказа в сутки. При этом объем одного запроса вычислим как отношение объема одного запроса к размеру всей базы данных. Он равен: a = 0,01Кб/10000Кб = 0,000001. Попробуем методом подбора найти первоначальное количество ошибок такое, чтобы оно удовлетворяло начальным и конечным условиям задачи. С учетом того, что каждую минуту одна из программ–клиентов получает данные, получаем интенсивность обращения к серверу – 1500 обращений в сутки.
Розыгрыш показывает, что таким начальным и конечным условиям соответствует ПО с 20–25 ошибками в начале работы и 10–14 ошибок на 180 сутки и коэффициент готовности 0,9. Для розыгрыша:
Начальные условия розыгрыша:
K (кол-во программ-клиентов) = 10;
P (кол-во программистов) = 3;
a (ширина запроса клиента) = 0,000001;
N0 (начальное количество ошибок) = 25;
s (сложность сервера) = 2;
Dt (шаг итерации) = 0,0005 (сутки);
lобр (интенсивность потока обращений клиента к серверу) = 1500/сутки;
lиспр (интенсивность потока исправления ошибки) = 2/сутки;
pвнес (вероятность внесения ошибки при исправлении) = 0,1/сутки
M (количество итераций) = 360000;
Общее время розыгрыша: 180 (сутки);
К (число розыгрышей) =5
Был получен результат (рис.25).

Рисунок 25 – Поиск начального количества ошибок
Из полученных данных видно, что после 180 дней опытной эксплуатации в системе останется примерно 5 ошибок и коэффициент готовности будет более 0.95, а среднее время наработки на отказ будет более 20 суток. Это приемлемые значения для надежности такой системы и следовательно ее можно передавать в промышленную эксплуатацию.
Моделирование следующих 180 дней промышленной эксплуатации показывают, что за это время будет обнаружено и исправлено всего 3, 4 ошибки, а коэффициент готовности достигнет 0.99 и среднее время наработки до отказа будет около 60 дней (рис.26).

Рисунок 26 – Поиск начального количества ошибок
Для сравнения проведем розыгрыш для количества ошибок, равном 100 и неизменных остальных начальных условиях (рис.27).

Рисунок 27 – Поиск начального количества ошибок
Из полученных результатов видно, что к концу опытной эксплуатации программы с таким начальным количеством ошибок через 180 дней еще останется около 25 ошибок, коэффициент готовности – 0.9, а среднее время наработки до отказа – около 6 суток, что говорит о низкой надежности ПО, вследствие чего программа не готова к передаче в промышленную эксплуатацию и необходимо продлить ее опытную эксплуатацию еще на полгода.
В ходе выполнения дипломной работы были изучены существующие модели надежности ПО и методы разработки качественного (прежде всего надежного, Кг > 0,999) ПО в условиях ограниченных ресурсов. На основе проведенного аналитического обзора современного состояния дел было выяснено, что на данный момент отсутствует общее решение проблемы надежности ПО, а есть множество частных решений, которые не учитывают такие существенные факторы, как интенсивность внесения и устранения ошибок в программе, время разработки ПО. Кроме того, влияние объема и сложности текста программ на надежность ПО в настоящее время непрерывно уменьшается. Таким образом, ни одну из существующих моделей нельзя считать достаточной для оценки надежности ПО малого и среднего объема (до 100 тысяч строк) из–за неопределенности их входных параметров, таких как начальное количество ошибок в ПО, количество ветвлений, циклов и т.п.
В ходе выполнения работы была создана новая математическая модель надежности ПО на основе марковских систем массового обслуживания, позволяющая проводить расчет характеристик надежности ПО.
Предлагаемая модель является более простой по отношению к рассмотренным. Основным ее преимуществом является отсутствие в ней начального количества ошибок в ПО.
Основным практическим результатом работы является программа для прогнозирования поведения надежности ПО со временем, основанная на методе Монте–Карло и предложенной модели надежности ПО. Сочетание двух подходов – марковской модели надежности ПО и прогнозирования при помощи метода Монте–Карло – позволяет более точно и более всесторонне оценить характеристики надежности ПО. Работа модели показана на конкретных примерах. Полученные результаты хорошо согласуются с результатами, полученными на практике.
Таким образом, созданная программа моделирования позволяет, задавая различные начальные условия, наблюдать поведение надежности ПО во времени. Это позволяет использовать ее для решения оптимизационных задач (например, поиска оптимальных ресурсов для достижения заданного уровня надежности, оптимальной интенсивности тестирования при заданных характеристиках клиент–сервера и количестве программистов). В частности, это позволяет найти начальное количество ошибок в ПО.
Таким образом, модель и программу моделирования можно рекомендовать использовать при разработке и сопровождении ПО, когда уровень надежности должен быть высоким, а достигнуть и подтвердить его не просто.
Список использованных источников
1. А.В. Антонов, А.С. Степанянц. Методы анализа надежности (безошибочности) программного обеспечения программно-технических средств //Труды ІІ Междунар. конф. "Идентификация систем и задачи управления" (SICPRO-2003). – С.924-942.
2. Ханджян А.О. Анализ современного состояния разработки надежного программного обеспечения //Естественные и технические науки. – М., 2005. – №2. – С. 220 – 227.
3. Лисс В.А. Математические модели надежности программного обеспечения распределенных систем //Известия СПбГТУ "ЛЭТИ". Сер. "Информатика, управление и компьютерные технологии". – 2005. – Вып.2. – С.26-32.
4. В.Г. Промыслов, А.В. Антонов, С.И. Масолкин, А.С. Степанянц. Оценка надежности программного обеспечения на различных этапах жизненного цикла сложных программ // Труды V Междунар. конф. "Идентификация систем и задачи управления" (SICPRO-2006). – С.1300-1304.
5. Шураков В. В. Надежность программного обеспечения систем обработки данных: Учебник.— 2–е изд., перераб. и доп.— М.: Финансы и статистика, 1987.—272 с.: ил.
6. ГОСТ Р ИСО/МЭК 9126–93. Информационная технология. Оценка программной продукции. Характеристики качества и руководства по их применению. – 12 с.
7. ГОСТ 28195–89. Оценка качества программных средств. Общие положения. – М.: Госком. СССР по стандартам – 38 с.
8. Соммервилл И. Инженерия программного обеспечения. – М.: Вильямс, 2002. – 624 с.
9. Larson D., Miller K. Silver Bullets for Little Monsters: Making Software More Trustworthy, IEEE IT Pro, March/April 2005 (русская версия: Ларсон Д., Миллер К. Серебряные пули для маленьких монстров //Открытые системы №5–6, 2005 С.20 – 23)
10. ISO/IEC 91261:1998. Информационная технология. – Характеристики и метрики качества программного обеспечения. – Часть 1: Характеристики и подхарактеристики качества.
11. Майерс Г. Надежность программного обеспечения. – М.: Мир, 1980. – 360 с.
12. Гаспер Б.С. Надежность функционирования автоматизированных систем. – Пермь: ПГТУ, 1999. – 70 с.
13. Иыуду К.А. Надежность, контроль и диагностика вычислительных машин и систем. – М.: Высшая школа, 1989. – 320 с.
14. Липаев В.В. Функциональная безопасность программных средств. – М.: СИНТЕГ, 2004. – 340 с.
15. Vincent J., Waters A., Sinclair J. Software quality assurance. Vol II. A programmer guide. – Englewood Cliff, New Yersey: Prentice–Hall. – 1988. – 192 p.
16. Тейер Т., Липов М., Нельсон Э. Надежность ПО. – М.: Мир, 1981. – 328 с.
17. Международный стандарт. МЭК 60880–2. Программное обеспечение компьютеров в системах важных для безопасности атомных электростанций. – IEC. М.: 2002. – 90 с.
18. Кулаков А.Ф. Оценка качества программы ЭВМ. – К.: Техника, 1984. – 168 с.
19. Липаев В.В. Надежность программных средств. – М.: СИНТЕГ, 1998. – 232 с.
20. Полонников Р.И., Никандров А.В. Методы оценки надежности программного обеспечения. – СПб: Политехника, 1992. – 80 с.
21. Штрик А.А., Осовецкий Л.Г., Мессих И.Г. Структурное проектирование надежных программ встроенных ЭВМ. – Л.: Машиностроение, 1989. – 296 с.
22. Вентцель Е.С. Исследование операций. – М.: Сов. Радио, 1972. – 552 с.
23. Гаспер Б.С. Надежность функционирования автоматизированных систем. – Пермь: ПГТУ, 1999. – 70 с.
24. Куракин А.Л. Фактор надежности в оптимизации аппаратуры для научных исследований //Технологии приборостроения №1(5) (СНИИП) – 2003. – С. 62‑65.
25. Ханджян А.О. Моделирование надежности программного обеспечения. - http://www.software-testing.ru/lib/handzhyan/software_quality_modeling.htm
Приложение А. Примеры моделей надежности ПО
Экспоненциальная модель роста надежности Джелински, Моранда, Шумана
Это одна из самых распространенных на сегодняшний день моделей надежности ПО опирается на теорию надежности аппаратуры [11, 13, 16, 19, 20, 21, 23].
Один из способов оценки СВМО – наблюдение за поведением программы в течение некоторого периода времени и нанесение на график значений между последовательными ошибками. На рис. А.1 изображено увеличение надежности ПО (кривые R1, R2, R3 – функции надежности, т. е. вероятность того, что ни одна ошибка в программе не произойдет или не будет обнаружена на временном интервале [0…t]) при исправлении в нем ошибок.
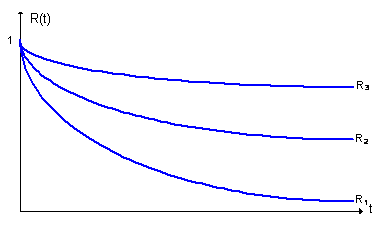
Рисунок A.1 – Увеличение надежности ПО при исправление в нем ошибок
Для разработки модели вводят следующие предположения:
li = Z(t) постоянно до обнаружения и исправления ошибки или интенсивность обнаружения ошибок;
li = Z(t) = K · ( N – i ) – т.е. Z(t) прямо пропорционально числу оставшихся ошибок, где N – неизвестное первоначальное число ошибок, i – число обнаруженных ошибок, K – некоторая неизвестная константа. Эта зависимость отображена на рис.А.2.
Рисунок A.2 – Функция риска
При обнаружении и исправлении ошибки функция риска уменьшается на K.
Неизвестные N и K можно оценить, если некоторое количество ошибок уже обнаружено. Предположим, что обнаружено n ошибок, а x[1], x[2], …, x[n] – интервалы времени между этими ошибками. Тогда, в предположении что Z(t) постоянно между ошибками, плотность вероятности для x[i] будет равна
p( x[i] ) = K · ( N – i ) · exp{ –K · ( N – i ) · x[i] }.
Значение N даст основной результат – оценку полного числа ошибок. Знание K позволяет использовать уравнение для предсказания времени до появления (n+1)‑й ошибки и последующих ошибок.
Это частный случай модели Шумана. Предположим, что интервалы времени отладки между обнаружениями двух ошибок имеет экспоненциальную зависимость и частота ошибок пропорциональна числу еще необнаруженных ошибок. Таким образом, функция плотности распределения времени обнаружения i–ой ошибки, отсчитываемого от момента выявления (i–1)–ой ошибки имеет вид
![]() ,
,
где
![]()
и N – число первоначально присутствующих в ПО ошибок.
Эта модель построена на следующих допущениях:
время до следующего отказа распределено экспоненциально;
интенсивность отказов пропорционально оставшимся в ПО ошибкам.
Тогда вероятность безотказной работы ПО:
![]() , (А.1)
, (А.1)
где
li=CD * ( N0–(i–1) ), (А.2)
CD – коэффициент пропорциональности,
N0 – первоначальное число ошибок в ПО.
В (А.1) отчет времени начинается от момента последнего (i–1)–го отказа.
Если известны все моменты обнаружения ошибок ti и каждый раз в этот момент устраняется одна ошибка, то, используя метод максимального правдоподобия, можно получить уравнение для определения значения начального количества ошибок N0.
По методу максимального правдоподобия находим CD и N0. Функция правдоподобия имеет вид:
![]() .
.
![]()
Откуда получаем условия для нахождения экстремумов:
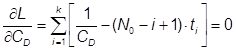 ,
, 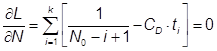
Отсюда получаем решение для CD и N0:
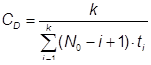 ,(А.3)
,(А.3)
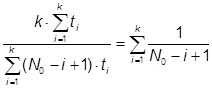 .(А.4)
.(А.4)
Уравнение (А.4) решается методом перебора.
Пусть в ходе отладки зафиксированы интервалы времени между отказами ПО t1=10, t2=20, t3=25 ч. Определим по вышеприведенным формулам вероятность ![]() отсутствия 4–го отказа, начиная с момента устранения 3–го отказа.
отсутствия 4–го отказа, начиная с момента устранения 3–го отказа.
Решаем (А.4) методом перебора и получаем N=4. Следовательно, из (А.3) имеем CD=0,02. Тогда из (А.1, А.2) получаем P(t4)=exp(0,02*t4) и, следовательно, l4=0,02 и среднее время до следующего отказа программы составляет <t4>=1/l4=50 ч.
Это одна из первых и простых моделей. Модель использована при разработке весьма ответственных проектов (например, для программы Apollo). В ее основу положены следующие допущения:
интенсивность обнаружения ошибки R(t) пропорциональна текущему числу ошибок в программе;
все ошибки равно вероятны и их появления независимы друг от друга;
время до следующего отказа распределено экспоненциально;
ошибки постоянно исправляются без внесения новых ошибок;
R(t) = const на интервале между двумя соседними ошибками;
В соответствии с этими допущениями функцию распределения (риска) интенсивности ошибок между (i–1) и i–ой ошибками можно представить как:
R(t) = K×[N0 – (i–1)],
где K – коэффициент пропорциональности; N0 – исходное число ошибок в ПО.
Все интервалы времени
Dti = ti – ti–1
имеют экспоненциальное распределение:
P(Dti) = exp{– K×[N0 – (i–1)] ×Dti }.
Из принципа максимального правдоподобия для K и N0 получают следующие оценки:
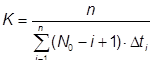 ,(А.5)
,(А.5)
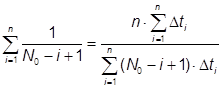 .(А.6)
.(А.6)
Нелинейное уравнение (А.6) достаточно сложно для решения численными методами, так как оно имеет локальные экстремумы и не всегда имеет решение.
Модель позволяет найти время до обнаружения следующей ошибки tn+1 и время необходимое для обнаружения всех ошибок T:
![]() ,
,
![]() .
.
Можно посчитать Dn – количество ошибок, которое следует обнаружить и устранить для повышения наработки между обнаружениями ошибок от T1 до T2:
Dn = N0 · T0 · ( 1/T1 – 1/T2).(А.7)
Также можно получить затраты времени Dt на проведение тестирования, которые позволяют устранить Dn ошибок и соответственно повысить наработку от T1 до T2:
Dt = N0 · T0 · ln( T2 / T1 ) / K .(А.8)
Коэффициент готовности:
![]() ,
,
Коэффициент простоя КП = 1 – КГ, где t' – период проверок, t1 – время затрат ресурсов на проверки, tВ – длительность восстановления работоспособности программы.
Относительная длительность отладки в этой модели:
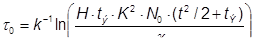 ,
,
где H – количество систем, в которых функционирует программа; tЭ – длительность эксплуатации программы; c ‑ коэффициент увеличения затрат ресурсов на единицу машинного времени.
Средняя наработка на отказ:
Тср = 1/l.
Следует подчеркнуть статистический характер приведенных соотношений.
Из (А.8) видно, что время, затрачиваемое на тестирование, пропорционально квадрату первоначального количества ошибок T0 в программе. Приведем пример: пусть N0 = 1000; T0 = 1 час. Требуется повысить надежность программы с T1 =1 час до T2 = 1 месяц = 720 часов. Тогда из (А.7) Dn = 999, что фактически означает, что нужно обнаружить все ошибки для получения устойчивой работы ПО в 1 месяц. И на это будет затрачено время Dt ~ 60 дней (при расчете K по формуле (А.5) было сделано предположение о неизменности ![]() , в этом случае
, в этом случае
K=n*T0/(сумма ар. прогрессии)).
На практике же будет затрачено гораздо меньше времени и найдено гораздо меньше ошибок, так как предположение о равномерности использования всего текста программы в процессе эксплуатации не верно. И, скорее всего, будет за меньшее время обнаружено 99% ошибок в той части программы, которая исполняется чаще, чем другая. В малоэксплуатируемой части останется не обнаруженными до 99% ошибок. Отсюда следует вывод о большой важности точного подбора входных данных при тестировании как можно более соответствующих режиму эксплуатации и вывод о необходимости сокращать время тестирования за счет меньшего тестирования малоиспользуемых ветвей программы. При этом важно не забывать о различных режимах эксплуатации ПО: нормальном, аварийном, ждущем и т.п.
Постулат, что программа не меняется за исключением исправления ошибки, а новые ошибки не вносятся, является спорным. Желание выразить надежность ПО некоторой функцией времени вполне логично, однако в действительности она от времени не зависит. Надежность ПО является функцией числа ошибок, их серьезности и расположения, а также того, насколько интенсивно система используется (интенсивность входного потока данных).
Статистическая модель Миллса
Описана в [11] и [20]. Программа специально "засоряется" некоторым количеством заранее известных ошибок. Эти ошибки вносятся в программу случайным образом, а затем делается предположение, что для ее собственных и искусственно внесенных ошибок вероятность обнаружения при последующем тестировании одинакова и зависит только от их количества. Тестируя программу в течении некоторого времени и отсортировывая собственные и внесенные ошибки можно оценить N – первоначальное число ошибок в программе.
Пусть: S – число специально внесенных ошибок; n – число найденных собственных ошибок в программе; u – число найденных внесенных ошибок; n+u – количество обнаруженных ошибок при тестировании.
Тогда по методу максимального правдоподобия имеем: N = S · n / u.
Основное допущение модели – распределение «посеянных» ошибок совпадает с распределением по программе собственных ошибок, и, следовательно, обнаружение, как тех, так и других ошибок равновероятно – что является существенным недостатком этой модели.
При этом можно выдвигать и проверять гипотезы об N. Пусть в программе не более k собственных ошибок и внесли нее еще S ошибок. Теперь программа тестируется, пока не будут обнаружены все специально внесенные ошибки. Причем в этот момент подсчитывается число обнаруженных собственных ошибок (обозначим его, как и раньше, как n). Введем уровень значимости C:
![]() (А.9)
(А.9)
С – мера доверия к модели, то есть мера правильности нашего предположения о количестве k собственных ошибок и дает оценку для количества ошибок
![]() ,
,
которое нужно внести в программу, чтобы проверить гипотезу с заданным уровнем значимости.
Например, если мы утверждаем, что в программе нет ошибок (k = 0), и внося в программу 4 ошибки, все их обнаруживаем, не встретив ни одной собственной ошибки, то C = 0.80. А чтобы достичь уровня 95 %, надо было бы внести в программу 19 ошибок.
Этот метод не очень эффективен в случае применения его в реальной практике, так как если предположить что в программе своих ошибок n = 1000 (что более реально, чем n = 0), то для достижения уровня правдоподобия 0,95 в программу придется ввести 19019 ошибок, что само по себе уже тяжелая задача.
Формулу (А.9) можно модифицировать так, чтобы устранить недостаток, заключающийся в том, что C нельзя предсказать до тех пор, пока не будут обнаружены все искусственно внесенные ошибки (а это может и не произойти за ограниченное время, отведенное на тестирование). Модифицированной формулой можно пользоваться уже после того, как найдено j внесенных ошибок:
 (А.10)
(А.10)
Это математически очень простая и интуитивно понятная модель. Процесс внесения ошибок – само слабое звено модели, так как должны вноситься "типичные" для данной программы ошибки (то есть искусственно внесенные ошибки должны иметь то же распределение вероятности, что и собственные ошибки). Кроме того, эта модель не учитывает системных ошибок, то есть ошибок вносимых на этапе проектирования, а не самого кодирования.
Модель Бейзина
Пусть ПО содержит Nk команд [20]. Случайным образом из них выбирается n команд, в которые вводятся ошибки. Затем для тестирования случайным образом выбирается r команд. Если в ходе тестирования будет обнаружено n собственных и m привнесенных («посеянных») ошибок, то полное число N0 ошибок содержащихся в программе перед началом тестирования (следует из метода максимального правдоподобия) можно определить как:
![]() .
.
Простая экспоненциальная модель
В отличие от модели Джелинского–Моранды R(t) ¹ const [20].
Пусть N(t) – число обнаруженных к моменту времени t ошибок и пусть функция риска пропорциональна числу оставшихся к моменту t в программе ошибок: R(t) = K×(N(0) – N(t)).
Продифференцируем обе части этого уравнения по времени:
![]() .
.
Учитывая, что dN(t)/dt есть R(t) (число ошибок, обнаруженных в единицу времени), получим дифференциальное уравнение:
![]()
с начальными условиями N(0) = 0, R(0) = K×N0.
Решением этого уравнения является функция:
R(t) = K×N0×exp(–K×t).(А.11)
Для K и N0 получают следующие оценки (с применением МНК) для первых n ошибок:
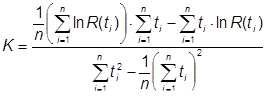 ,
,
![]() ,
,
где
![]() .
.
Используя (А.11) можно определить время необходимое для снижения интенсивности появления ошибок с R1(t) до R2(t):
![]() .
.
Дискретная модель Шика–Уолвертона
Эта модель рассмотрена в работах [12, 20, 21]. Применяется при следующих допущениях:
предполагается, что частота проявления ошибок (интенсивность отказов) линейно зависит от времени испытаний ti между моментами обнаружения последовательных i–й и (i–1)–й ошибок;
появление ошибок равновероятно и независимо;
ошибки корректируются без введения новых.
Тогда:
![]() ,
,
где k – коэффициент пропорциональности, обеспечивающий равенство единице площади под кривой вероятности обнаружения ошибок.
В этом случае для оценки вероятности безотказной работы получается выражение, соответствующее распределению Релея:
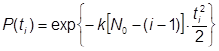 ,
,
где P(ti) = P(T³ti).
Отсюда плотность распределения времени наработки на отказ:
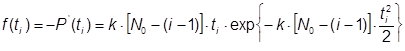 .
.
Использовав функцию максимального правдоподобия, получим оценку для N0 и K:
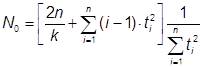 ,
, 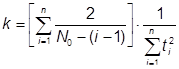 .
.
Модель Вейбулла
В [12] и [20] приводится модель надежности ПО с учетом ступенчатого характера изменения надежности при устранении очередной ошибки.
Функция риска для этой модели представляется в виде: R(t) = (a/b) ×(t/b)a–1, где a > 0, и b > 0 – константы модели; t – интервал времени безошибочной работы.
Если a > 1, то интенсивность обнаружения ошибок растет со временем, если a < 1, то – падает.
Плотность распределения вероятности до появления очередной ошибки описывается распределением Вейбулла:
![]() .
.
Наработка до отказа выражается через гамма–функцию:
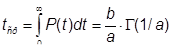 ,
,
где P(t) – вероятность безотказной работы и P(t) = 1 – Q(t), где Q(t) – вероятность отказа:
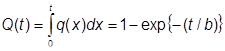 .
.
Для оценки параметров a и b используются следующие формулы:
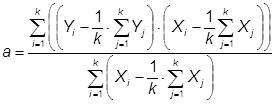 ,
,
где
b = exp{–b0/a},
![]() ,
,
k – число интервалов тестирования,
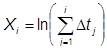 ,
,
Dtj – длина j–го интервала тестирования,
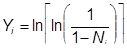 ,
,
Ni – нормированное суммарное число ошибок, обнаруженных к моменту ti.
Определение надежности по результатам тестирования
Рассмотрены в работе [13]. Оценку надежности ПО при стохастическом (когда входные данные выбираются согласно своим функциям распределения и основным статистическим моментам) функциональном тестировании целесообразно производить на основании заключительной серии стохастических тестов (например, при приемочных испытаниях), когда отказы программы отсутствуют. Тогда для оценки вероятности безотказной работы программы может быть использована формула (оценка безошибочности ПО производится таким же методом как оценка безотказности аппаратуры):
![]() ,(А.12)
,(А.12)
где pн – нижняя доверительная граница вероятности безотказной работы ПО при однократном прохождении набора стохастических входных данных; gн – доверительная вероятность; n – число проходов при тестировании.
Пусть, например, n=150 прохождений со случайными исходными данными. Исходы всех тестов положительные (ошибок не обнаружено), т.е. количество отказов ПО равно нулю. Необходимо определить нижнюю доверительную границу вероятности безотказной работы ПО при одном прохождении, при gн = 0,9.
Согласно (А.11) имеем pн = 0.985.
Сделанное выше допущение относительно независимости результатов отдельных тестов программы не вполне обосновано, так как наличие ошибки в ПО обнаруживается скорей всего, большим количеством тестов, чем это можно ожидать, исходя из независимости их результатов. Поэтому представляет интерес другой подход, где ПО рассматривается как сообщение, состоящее из N символов. Пусть каждый стохастический тест проверяет в среднем r символов из N и пусть один из N элементов содержит ошибку.
Пусть вероятность того, что при одном тесте ошибка не будет обнаружена, оценивается как 1 – r/N. Вероятность того, что при n независимых тестах ошибка не будет обнаружена, равна (1 – r/N)n. Если ошибочных символов в ПО больше чем один, то вероятность их обнаружения одним тестом будет еще больше, так как эта оценка является оценкой снизу.
Пусть n = 150; r/N = 0,3. Тогда вероятность обнаружения ошибки в ПО
p = 1 – (1 – r/N)150 = 1 – 1,72×10–20 @ 1.
Настолько высокая оценка вероятности обнаружения ошибок получается благодаря тому, что в соответствии с данной моделью каждый символ программы проверяется в среднем многократно, и вероятность того, что некоторый символ ни в одном тесте не проверяется, весьма мала.
Модель избыточности
Можно попробовать использовать подход, предложенный в статье [24] для описания эффективности защиты ПО от сбоев посредством введения в нее избыточного кода. Эффективность защиты (в расчете на которую в ПО вводится избыточный код, который снижает функциональные характеристики ПО, в частности, быстродействие и требует больших ресурсов (например, для использования образцового в этом отношении языка JAVA нужно как минимум 128 Мб ОЗУ)), априорно определим как вероятность P (являющейся функцией времени T периодичности работы программного модуля) нужности (срабатывания) защиты. Эта вероятность в рассматриваемом случае может быть выражена произведением вида:
P = Pe * Pr * Pd,(А.13)
где Pe – вероятность того, что сбой произойдет (например, закончатся ресурсы оперативной памяти и не будет выделена память);
Pr – вероятность того, что защита от этого сбоя сработает;
Pd – вероятность того, что сообщение о сбое будет получено и обработано (т.е. что диагностика сработает).
По сути данной задачи речь идет о двух типах случайных событий:
1. событии (нежелательном) состоящем в том, что произошел прогнозируемый сбой;
2. событии (желательном) состоящем в том, что защита сработает.
Рассмотрим случай, когда оба типа событий характеризуются постоянными интенсивностями (поскольку временные зависимости этих параметров обычно не известны). Пусть:
e – интенсивность (то есть вероятностью возникновения в единицу времени) возникновения ошибки (сбоя);
lr – интенсивностью отказа (не срабатывания) защиты, характеризующая надежность защиты;
ld – интенсивность срабатывания диагностики, характеризующая надежность системы диагностики Pd.
Тогда сомножители, входящие в формулу (А.13), можно представить в следующем виде:
|
|
(А.14) (А.15) (А.16) |
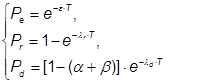
где T – периодичность работы программного модуля;
a, b – вероятности ошибок 1–го и 2–го рода диагностики.
Диагностика представляет собой устройство (или программу), обеспечивающее оповещение оператора о сбое и принятии решения о дальнейшей работе. Исправный диагностический модуль по аналогии с размыкателем характеризуется двумя ошибками: ошибка 1–го рода – ложное срабатывание (например, выключение без наличия сбоя), ошибка 2–го рода – отсутствие срабатывания при наличии сбоя. Защита не эффективна в обоих случаях.
Подстановка (А.13) – (А.15) в (А.12) дает выражение:
![]() ,(А.17)
,(А.17)
где
![]() .
.
Функция (А.16) достигает максимума при значении T равном:
![]() (А.18)
(А.18)
Значение T* представляет собой оптимальное время T защищенности программы. Таким образом, этот метод позволяет определить оптимальную периодичность работы программы, при которой защита с заданными характеристиками e, lr, ld дает оптимальный эффект. Либо можно оценить одну из характеристик e, lr, ld при заданных остальных и заданном T*.
Например, оценим T*:
e – один раз в месяц, т.е. равна 3,7e–7;
lr = e;
ld – один раз в минуту, т.е. равен 0,017.
Тогда T* = 59 с.
Теперь, оценим ld при следующих условиях:
T* = 60 с;
e – один раз в год, т.е. равна 3,3e–8;
lr = e.
Тогда из (А.17) имеем
![]() .
.
Получаем ld = 1,67e–02 1/с или один раз в минуту.
Модель Дюэна
Модель рассмотрена в работе [20]. Эта модель была предложена для оценки роста надежности. Для этого рассматривается отношение интенсивности обнаружения ошибок к общему времени тестирования. В основу модели положены следующие предположения:
обнаружение любой ошибки равновероятно;
общее число ошибок N(t), обнаруженных к произвольному моменту t, распределено по закону Пуассона со средним значением n(t) = a×tb.
Из этого следует, что
![]() .
.
Из МНК получают следующую оценку для a и b:
![]() ,
,
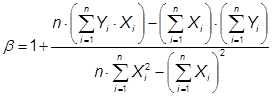 ,
,
где
Xi = ln(ti), Yi = ln(i/ti),
![]() ,
,
Для использования этой модели требуется только знание моментов времени ti проявления ошибок.
Метод Холстеда оценки числа оставшихся в ПО ошибок
Модель рассмотрена в работе [20]. На сегодняшний момент это единственная модель, с помощью которой можно оценить число ожидаемых (то есть потенциальных) ошибок в ПО еще на этапе составления ТЗ на ПО.
Для программы вводится понятие длины программы N и объем программы (в битах) V:
N = n1×log2n1 + n2×log2n2,
V = N×log2(n1 + n2),(А.19)
где n1 – число различных операций (например, таких как IF, =, DO, PRINT и т.п.); n2 – число различных переменных и констант.
Далее рассматривается потенциальный объем программы (в битах) V*:
![]() ,(А.20)
,(А.20)
где ![]() – только число входных и выходных переменных.
– только число входных и выходных переменных.
Величина ![]() может быть выявлена уже на стадии ТЗ или технического проекта на разработку ПО.
может быть выявлена уже на стадии ТЗ или технического проекта на разработку ПО.
Еще вводится понятие уровня программы L, который определяется как отношение потенциального объема V* к объему V:
L = V*/V.
Также вводятся величины:
E = V/L = V2/V*,
l = L×V*
– уровень языка программирования. Значения l для некоторых языков программирования: Ассемблер – 0,88; Фортран – 1,14; PL–1 – 1,53; С/С++ – 1,7; Pascal – 1,8; JAVA – 1,9.
Из этого следует, что
V = (V*)2/l.(А.21)
Оценка времени, затрачиваемое на разработку ПО:
T = E/S = (V*)3/(l×S) (А.22)
где S – параметр Страуда (психофизиологическая характеристика времени, необходимого человеческому мозгу для выполнения элементарной мыслительной операции. S лежит в пределах от 5 до 20 различий в секунду. Холстедом используется значение S = 18, характеризующее процесс программирования как довольно напряженную умственную работу).
Используя (А.21) можно оценить выигрыш во времени разработки при переходе от одного языка программирования l1 к другому языку l2:
![]() .
.
Например, выигрыш при переходе с C/C++ на JAVA составит около 10%, а с ассемблера на JAVA – 50%.
Основное предположения этой модели:
общее число ожидаемых ошибок N в программе определяется сложностью ее создания (и это верно, за исключением того, что в вышеперечисленные характеристики ПО не входит сложность проектирования, а учитывается только сложность кодирования!).
мозг человека может обработать одновременно и безошибочно 7±2 объектов (гипотеза Миллера).
Тогда, взяв нижнюю границу в 5 объектов и добавив еще один объект, мы получим максимальное число ![]() = 6 различных входных и выходных параметров для потенциально безошибочной программы. Тогда потенциальный объем V0* по (17): V0* = (6+2) ×log2(6+2) = 24 логических бита.
= 6 различных входных и выходных параметров для потенциально безошибочной программы. Тогда потенциальный объем V0* по (17): V0* = (6+2) ×log2(6+2) = 24 логических бита.
Следовательно, после обработки 24 битов информации на языке программирования человек совершит одну ошибку.
![]() .
.
Это означает, что на каждые 3000 бит объема V* приходится одна ошибка. Тогда для реального объема ПО из (П1.20) следует, что число ошибок в ПО:
![]() (А.23)
(А.23)
Модель IBM
Модель рассмотрена в работе [20]. Эта модель предназначена для оценки количества вносимых ошибок в сопровождаемом ПО, находящемся в эксплуатации, при его модификации. Модель построена на данных сопровождения 19 версий ОС OS/360 фирмы IBM.
Пусть Mi – число модулей i–ой (новой) версии. Из них
СИМi – число измененных по отношению к предыдущей версии модулей,
НМi – число новых модулей (то есть Мi = Мi–1 + НМi),
МИМi – число многократно измененных и исправленных модулей (10 и более раз),
ИМi – число модулей, в которые внесено менее 10 изменений.
Из практики сопровождения OS/360 и создания ее новых версий были выявлены следующие зависимости:
ИМi = 0,9 × НМi + 0,15 × СИМi
МИМi = 0,15 × ИМi + 0,06 × СИМi.
Число ожидаемых ошибок равно:
N = 23 × МИМi + 2 × ИМi .
Основные выводы, следующие из модели IBM, таковы:
количество ожидаемых ошибок в следующей версии может увеличиться по сравнению со старой версией, если будет изменено достаточно большое количество старых модулей (СИМ) и/или будет введено достаточно большое количество новых модулей (НМ). Поэтому перед выпуском такой версии понадобятся дополнительные усилия по ее тестированию;
введение новых модулей быстрее приводит к появлению ошибок, чем исправление старых модулей. Однако, если удастся вместо изменения большого числа старых модулей создать несколько новых с требуемой функциональностью, то это приведет к уменьшению оценки ожидаемых ошибок. То есть на некотором этапе усовершенствования ПО поддержка старых модулей является не эффективной, а более целесообразно с точки зрения надежности написать новые модули.
Рассмотрена в [16]. Предполагается, что Er – количество ошибок в начальный момент времени и в течение времени t устраняется ec(t) ошибок в расчете на одну команду. Тогда:
![]()
– количество оставшихся ошибок на одну команду, где IT – число машинных команд, которое предполагается постоянным.
Предполагается, что частота отказов z(t) пропорциональна числу ошибок, оставшихся в ПО, то есть z(t) = с · er(t).
Тогда вероятность безотказной работы на интервале времени (0, t):
![]() .
.
Простая эвристическая модель двух независимых групп тестирования Руднера
Описана в [11] и [20]. В этой модели исключается основной недостаток модели Миллса. Здесь тестирование осуществляется двумя независимыми группами.
Пусть есть две независимые группы тестирования.
N1 и N2 – число ошибок, обнаруженных каждой группой соответственно. N12 – число одинаковых ошибок, обнаруженных обеими группами (т.е. число ошибок обнаруженных дважды), N – число всех ошибок программы (см. рис. 74).
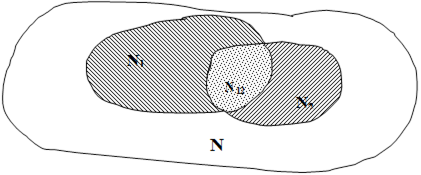
Рисунок A.3 – Область ошибок программы
Эффективность тестирования каждой из групп представим как
E1 = N1/N, E2=N2/N.
Предположим, что вероятность обнаружения всех ошибок каждой группой одинакова (это следует из того, что у каждой группы были одинаковые условия и одинакова квалификация их составов). Тогда можно рассматривать каждое подмножество пространства N как аппроксимацию всего пространства, т.е. если 1–я группа обнаружила 10% всех ошибок, то она должна была найти примерно 10% всякого случайным образом выбранного подмножества, например, подмножества N2. Тогда (N1/N) » (N12/N2) и (N2/N) » (N12/N1). Тогда получаем:
N = (N1 ·N2)/ N12.(А.24)
Например, две группы нашли 20 и 30 ошибок соответственно. Из них – 10 ошибок общие. Имеем согласно формуле (А.24) общее число ошибок N = 60 и из них не обнаружено 60 – 20 – 30 + 10 = 20 ошибок.
В работе [16] предлагается описывать количество ошибок в программе как линейную функцию от сложности программы, то есть
![]()
где zi – показатели сложности ПО такие как:
количество ветвлений;
количество циклов;
количество вычислений;
число комментариев;
количество вызовов функций и т.п.;
ai – весовые коэффициенты.
Методом регрессионного анализа (МНК) по данным об ошибках пяти различных проектов показано, что наибольший вклад в N вносят общее число ветвлений z4 и общее число логических операторов z6 и, что N = 0,0454 · z4 + 0,254· z6; со стандартной ошибкой – 54,4 и доверительным интервалом – 0,982.
В работе [5] рассмотрены модели количества ошибок, основанные на знании объема исходных текстов ПО. Данные модели не учитывают квалификацию программиста и подобные трудно измеримые факторы. В этих моделях используются коэффициенты пропорциональности, которые нужно искать из опытных данных не совсем ясными методами.
Похожие рефераты:
Проект информационно-вычислительной сети Мелитопольского межрайонного онкологического диспансера
Электронный документооборот страхового общества
Проблемы информационной безопасности банков
Билеты и ответы по Информатике за 11-й класс
Математическое обеспечение комплекса задач “Автоматизированная система документооборота учереждения
Устройство и назначение системы BIOS ЭВМ
Диагностика отказов системы регулирования уровня в баке
Техническая диагностика средств вычислительной техники
Защита информации в системах дистанционного обучения с монопольным доступом
Автоматизация технологических процессов и производств
Курс лекции по компьютерным сетям
Администрирование корпоративной сети на основе Microsoft Windows 2000 Advanced Server