| Скачать .docx | Скачать .pdf |
Реферат: Доверительный интервал. Проверка статистических гипотез
Доверительный интервал.
Проверка статистических гипотез
1. Доверительный интервал
Точечные оценки являются приближенными, так как они указывают точку на числовой оси, в которой должно находиться значение неизвестного параметра. Однако оценка является приближенным значением параметра генеральной совокупности, которая при разных выборках одного и того же объема будет принимать разные значения, поэтому в ряде задач требуется найти не только подходящее значение параметра а, но и определить его точность и надежность.
Для этого в математической статистике используется два понятия – доверительный интервал и доверительная вероятность. Пусть для параметра а из опытных данных получена несмещенная оценка ![]() Требуется определить возможную при этом величину ошибки и вероятность того, что оценка не выскочит за пределы этой ошибки (надежность).
Требуется определить возможную при этом величину ошибки и вероятность того, что оценка не выскочит за пределы этой ошибки (надежность).
Зададимся некоторой вероятностью b (например, b = 0,99) и найдем такое значение e > 0, для которого
![]()
Представим это выражение в виде
![]()
Это значит, что с вероятностью b точное значение параметра а находится в интервале le
![]()
![]() le
le
![]()
Здесь параметр а – неслучайная величина, а интервал le
является случайным, так как ![]() - случайная величина. Поэтому вероятность b лучше толковать, как вероятность того, что случайный интервал le
накроет точку а. Интервал le
называют доверительным интервалом, а вероятность b - доверительной вероятностью (надежностью).
- случайная величина. Поэтому вероятность b лучше толковать, как вероятность того, что случайный интервал le
накроет точку а. Интервал le
называют доверительным интервалом, а вероятность b - доверительной вероятностью (надежностью).
Пример. Если при измерении какой-то величины Х указывается абсолютная погрешность Dх, то это, по существу, означает, что погрешность измерения, являясь случайной величиной, равномерно распределена в интервале (-Dх, Dх) и ![]() где Х* - измеренная величина, а х – ее точное значение. Здесь b = 1, e = Dх и le
= (x*- Dх, x* + Dх).
где Х* - измеренная величина, а х – ее точное значение. Здесь b = 1, e = Dх и le
= (x*- Dх, x* + Dх).
1.1 Доверительный интервал для математического ожидания
В качестве еще одного примера рассмотрим задачу о доверительном интервале для математического ожидания. Пусть проведено n независимых опытов измерения случайной величины Х с неизвестным математическим ожиданием mx и дисперсией s2 . На основании опытных данных Х1 , Х2 , ... , Хn построим выборочные оценки

Требуется построить (найти) доверительный интервал le , соответствующий доверительной вероятности b, для среднего генерального mx .
Так как среднее выборочное ![]() представляет сумму n независимых одинаково распределенных случайных величин
представляет сумму n независимых одинаково распределенных случайных величин ![]() то при достаточно большом объеме выборки согласно центральной предельной теоремы ее закон близок к нормальному. Существует эмпирическое правило, по которому при объеме выборки n³ 30 выборочное распределение можем считать нормальным.
то при достаточно большом объеме выборки согласно центральной предельной теоремы ее закон близок к нормальному. Существует эмпирическое правило, по которому при объеме выборки n³ 30 выборочное распределение можем считать нормальным.
Ранее было показано, что ![]() Найдем теперь такую величину e(b) > 0, для которой выполняется равенство
Найдем теперь такую величину e(b) > 0, для которой выполняется равенство
![]()
Считая случайную величину ![]() нормально распределенной, имеем
нормально распределенной, имеем
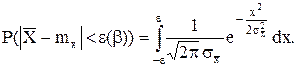
После замены ![]() имеем
имеем
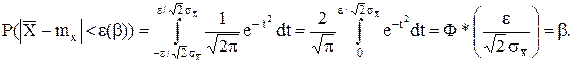
По табличным значениям функции Лапласа Ф*(z) находим аргумент, при котором она равна b. Если этот аргумент обозначить Zb , то тогда
![]()
Среднее квадратичное значение ![]() приближенно можно заменить
приближенно можно заменить
![]()
![]() где
где 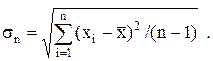
Таким образом, доверительный интервал для среднего генерального равен:
le
= ![]()
Если пользоваться табличными значениями интеграла вероятностей
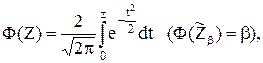
то доверительный интервал принимает вид
le
= ![]()
1.2 Распределение Стьюдента
При малом объеме выборки (n < 30) полученный доверительный интервал для среднего генерального, использующий нормальное распределение случайной величины ![]() , может быть очень грубым.
, может быть очень грубым.
Для более точного получения доверительного интервала необходимо знать закон распределения случайной величины ![]() при малом объеме выборки. Для этого воспользуемся следующим результатом. Пусть Х1
, Х2
, ... , Хn
– выборка нормально распределенной случайной величины Х, тогда, как доказано, случайная величина
при малом объеме выборки. Для этого воспользуемся следующим результатом. Пусть Х1
, Х2
, ... , Хn
– выборка нормально распределенной случайной величины Х, тогда, как доказано, случайная величина
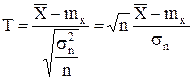
подчиняется распределению Стьюдента cn – 1 степенью свободы, плотность распределения которого имеет вид
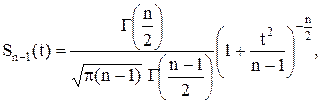
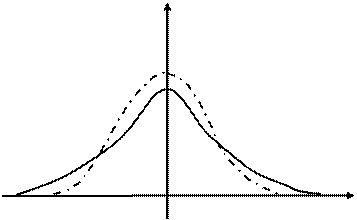
где 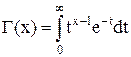 - гамма функция. Эта плотность, как видно из формулы, зависит только от числа опытов n. Ниже представлены графики плотностей нормированной (mx
= 0, s = 1) нормально распределенной и с распределением Стьюдента (n = 4) случайных величин.
- гамма функция. Эта плотность, как видно из формулы, зависит только от числа опытов n. Ниже представлены графики плотностей нормированной (mx
= 0, s = 1) нормально распределенной и с распределением Стьюдента (n = 4) случайных величин.
 |
|
![]()
![]()
|
0,3
0,2
0,1
-4 -3 -2 -1 1 2 3 4 t
На основании найденных ![]() можно, пользуясь распределением Стьюдента, найти доверительный интервал для mx
, соответствующий доверительной вероятности b. Действительно, так как
можно, пользуясь распределением Стьюдента, найти доверительный интервал для mx
, соответствующий доверительной вероятности b. Действительно, так как ![]() то
то
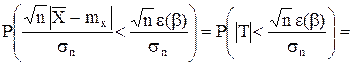
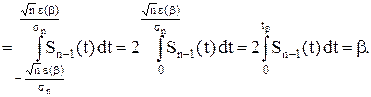
Пользуясь таблицей значений интеграла
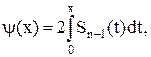
по значению b найдем величину  а следовательно, и сам доверительный интервал le
=
а следовательно, и сам доверительный интервал le
= ![]()
2. Проверка статистических гипотез
Принятие решения о параметрах генеральной совокупности играет исключительно важную роль на практике. Рассмотрим вопрос о принятии решения на примере. Пусть фирма, выпускающая конденсаторы, утверждает, что среднее пробивное напряжение конденсаторов равно или превышает 300 В. Испытав 100 конденсаторов, мы получили, что среднее выборочное пробивное напряжение равно 290 В, а несмещенное выборочное среднее квадратичное отклонение sn = 40 В. Можно ли с доверительной вероятностью 0,99 утверждать, что среднее пробивное напряжение превышает 300 В.
Здесь нас интересует односторонняя оценка – среднее пробивное напряжение должно превышать 300 В.
Выскажем статистическую гипотезу – генеральное среднее mx = 300 В, а затем проверим, соответствует ли она результатам наблюдения. Поскольку объем выборки больше 30, то выборочное среднее можно считать гауссовской случайной величиной с генеральной дисперсией s2 »sn 2 . Введем центрированную и нормированную величину
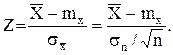
Утверждение о том, что среднее выборочное напряжение ![]() эквивалентно утверждению, что случайная величина
эквивалентно утверждению, что случайная величина
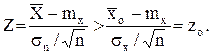
Найдем вероятность того, что гауссовская случайная величина Z с mz = 0 и sz = 1 принимает значения больше zo :
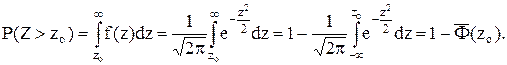
Эта величина должна равняться доверительной вероятности 0,99. Тогда ![]() и по таблицам значений функции
и по таблицам значений функции ![]() находим аргумент zo
= -2,33. Вычислим теперь наблюдаемое значение случайной величины Z:
находим аргумент zo
= -2,33. Вычислим теперь наблюдаемое значение случайной величины Z:
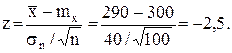
Мы видим, что наблюдаемое значение z = - 2,5 нe принадлежит интервалу [-2,33;¥), поэтому гипотезу нужно отвергнуть.
Приведем пример гипотезы с двухсторонней оценкой. Пусть фирма, выпускающая стабилитроны определенного типа, утверждает, что номинальное напряжение стабилизации стабилитронов равно 10 В. Естественно, что отклонение напряжения стабилизации в меньшую или большую стороны одинаково нежелательно. Выдвинем гипотезу, что генеральное среднее напряжение стабилизации равно 10 В, а затем проверим эту статистическую гипотезу по результатам наблюдения.
Пусть при испытании 100 стабилитронов среднее выборочное равно 10,3 В, а несмещенное выборочное среднее квадратичное отклонение равно 1,2 В. Можно ли с доверительной вероятностью 0,95 считать выдвинутую гипотезу справедливой? Так как объем выборки больше 30, то можно, как и в предыдущем примере, ввести гауссовскую случайную величину Z. Найдем

и приравняем правую часть полученного соотношения 0,95. Тогда ![]() и zo
=1,96. Это значит, что наблюдаемое значение z должно принадлежать интервалу (-1,96; 1,96). Поскольку
и zo
=1,96. Это значит, что наблюдаемое значение z должно принадлежать интервалу (-1,96; 1,96). Поскольку ![]()
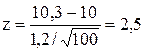 не попадает в указанный интервал, то гипотеза отвергается.
не попадает в указанный интервал, то гипотеза отвергается.
Если объем выборки n < 30, то случайная величина ![]() cчитается стьюденской случайной величиной T. Поэтому повторяя все указанные выше выкладки для проверки статистических гипотез, значения аргумента ищутся для распределения Стьюдента. При этом, так как "хвосты" стьюденского распределения по отношению к гауссовским удлиняются, доверительные интервалы расширяются, а возможности принятия гипотез улучшаются.
cчитается стьюденской случайной величиной T. Поэтому повторяя все указанные выше выкладки для проверки статистических гипотез, значения аргумента ищутся для распределения Стьюдента. При этом, так как "хвосты" стьюденского распределения по отношению к гауссовским удлиняются, доверительные интервалы расширяются, а возможности принятия гипотез улучшаются.
3. Функция риска
доверительный интервал вероятность статистическая гипотеза
Пусть имеются две противоположные гипотезы Но и Н1 и некоторая связанная с ними случайная величина Y. И пусть у - значение случайной величины Y, полученное в результате испытаний, которое принадлежит множеству D - множество всех значений случайной величины Y. Требуется провести проверку гипотезы Но относительно конкурирующей гипотезы Н1 на основании результатов испытания.
Разобьем множество D на две части - Dо и D1 с условием принятия гипотезы Но при попадании полученного значения у в Dо и гипотезы Н1 - при попадании у в D1. Выбор решающего правила, то есть разбиение множества Dна две части Dо и D1 в любой задаче проверки гипотез возможен больше, чем одним способом. Возникает вопрос, какое из этих разбиений в каждой конкретной задаче считать наилучшим? Чтобы решить поставленную задачу нужно обладать некоторой дополнительной информацией. Такая информация носит название априорной.
Будем считать известными два условных распределения вероятностей случайной величины Y:
![]() - плотность распределения случайной величині Y при условии, что верна гипотеза Но
;
- плотность распределения случайной величині Y при условии, что верна гипотеза Но
;
![]() - плотность распределения случайной величині Y при условии, что верна гипотеза Н1
;
- плотность распределения случайной величині Y при условии, что верна гипотеза Н1
;
Кроме того нам потребуется априорная вероятность р того, что гипотеза Но имеет место.
Введем в рассмотрение события:
А – верна гипотеза Но , тогда р = р(А);
![]() – верна конкурирующая гипотеза Н1
, тогда р(
– верна конкурирующая гипотеза Н1
, тогда р(![]() ) = 1 - р;
) = 1 - р;
В – в результате эксперимента значение у попало в интервал Dо ;
![]() – в результате эксперимента значение у попало в интервал D1
.
– в результате эксперимента значение у попало в интервал D1
.
Тогда по результатам эксперимента возможны только четыре события:
АВ – верна гипотеза Но и принято решение о ее истинности;
![]() В – верна гипотеза Н1
, а принято решение о истинности гипотезы Но
;
В – верна гипотеза Н1
, а принято решение о истинности гипотезы Но
;
А![]() – верна гипотеза Но
, а принято решение о истинности гипотезы Н1
;
– верна гипотеза Но
, а принято решение о истинности гипотезы Н1
;
![]()
![]() – верна гипотеза Н1
и принято решение о ее истинности.
– верна гипотеза Н1
и принято решение о ее истинности.
Ясно, что события ![]() В и А
В и А![]() определяют ошибочные решения. Событию
определяют ошибочные решения. Событию ![]() В соответствует так называемая ошибка первого рода, а событию А
В соответствует так называемая ошибка первого рода, а событию А![]() - ошибка второго рода.
- ошибка второго рода.
Для ответа на вопрос, какое из решающих правил следует считать лучшим, введем понятие функции потерь и функцию риска.
Функция потерь – дискретная случайная величина С, которая каждому из событий АВ, ![]() В, А
В, А![]() ,
, ![]()
![]() ставит в соответствие потери
ставит в соответствие потери ![]() , выраженные в каких-то единицах. Правильному решению естественно положить нулевые потери, а ошибкам первого и второго ряда положить соответственно положительные потери (числа) С1
и С2
, которые нужно задать.
, выраженные в каких-то единицах. Правильному решению естественно положить нулевые потери, а ошибкам первого и второго ряда положить соответственно положительные потери (числа) С1
и С2
, которые нужно задать.
Пусть ро
= р(АВ или ![]()
![]() ), р1
= р(
), р1
= р(![]() В), р2
= р(А
В), р2
= р(А![]() ). Определение значений этих вероятностей будет проведено ниже. Ряд распределения для случайной величины С имеет вид
). Определение значений этих вероятностей будет проведено ниже. Ряд распределения для случайной величины С имеет вид
| С | 0 | с1 | с2 |
| р | ро | р1 | р2 |
Определение. Математическое ожидание М(С) случайной величины С называется функцией риска и обозначается буквой r.
Таким образом, r = М(С) = 0 ро + с1 р1 + с2 р2 = с1 р1 + с2 р2 .
Введение функции риска приводит к естественному выбору решающего правила. Из двух правил лучшим считается то, которое приводит к меньшему риску. Для нахождения минимума функции риска найдем вероятности р1 и р2 :
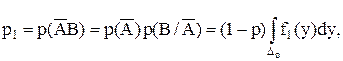
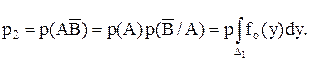
Тогда
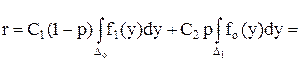
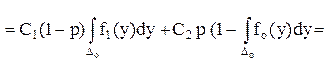

Для того, чтобы интеграл был минимальным, а значит и минимальное значение принимала функция риска r, нужно в состав Dо включить только те у, в которых подыинтегральная функция
С1 (1-р) f1 (y) – pC2 fo (y) < 0,
а в состав D1 - остальные значения у.
Последнее неравенство можно записать в виде
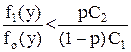
Функция f1 (y)/fo (y) называется отношением правдоподобия.
Итак, оптимальное решающее правило заключается в следующем: полученное в результате эксперимента значение у подставляется в отношение правдоподобия f1 (y)/fo (y) и сравнивается с числом
l = 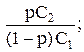
если полученное в результате вычисления число f1 (y)/fo (y) меньше l, принимается гипотеза Но ; в противном случае – гипотеза Н1 .
Величина l носит название порога, а оптимальное решающее правило носит название порогового критерия оптимальности.