| Скачать .docx | Скачать .pdf |
Реферат: Алгоритмы поиска и выборки
Лабораторная работа 8.
Тема: Алгоритмы поиска и выборки.
Задания:
1. Написать программу реализующую алгоритм последовательного поиск целевого значения из выборки N чисел (использовать любой язык программирования).
2. Написать программу реализующую алгоритм двоичного поиска целевого значения из выборки N чисел (использовать любой язык программирования).
3. Провести анализ наихудшего и среднего случаев.
4. Оформить отчет в MSWord и показать работающую программу преподавателю.
Теоретический минимум.
Алгоритмы поиска и выборки
Поиск необходимой информации в списке — одна из фундаментальныхзадач теоретического программирования. При обсуждении алгоритмов поиска мы предполагаем, что информация содержится в записях, составляющих некоторый список, который представляет собой массив данных в программе. Записи, или элементы списка, идут в массиве последовательно и между ними нет промежутков. Номера записей в списке идут от 1 до N — полного числа записей. В принципе записи могут быть составлены из полей, однако нас будут интересовать значения лишь одного из этих полей, называемого ключом. Списки могут быть не отсортированными или отсортированными по значению ключевого поля. В не отсортированном списке порядок записей случаен, а в отсортированном они идут в порядке возрастания ключа.
Поиск нужной записи в не отсортированном списке сводится к просмотру всего списка до того, как запись будет найдена. Это простейший из алгоритмов поиска. Мы увидим, что этот алгоритм не очень эффективен, однако он работает на произвольном списке.
В отсортированном списке возможен также двоичный поиск. Двоичный поиск использует преимущества, предоставляемые имеющимся упорядочиванием, для того, чтобы отбрасывать за одно сравнение больше одного элемента. В результате поиск становится более эффективным.
С поиском конкретного значения связана задача выборки, в которой требуется найти элемент, удовлетворяющий некоторым условиям. Скажем, нам может понадобиться пятый по величине элемент, седьмой с конца или элемент со средним значением. Мы обсудим два подхода к этой задаче.
1. Последовательный поиск
В алгоритмах поиска нас интересует процесс просмотра списка в поисках некоторого конкретного элемента, называемого целевым. При последовательном поиске мы всегда будем предполагать, хотя в этом и нет особой необходимости, что список не отсортирован, поскольку некоторые алгоритмы на отсортированных списках показывают лучшую производительность. Обычно поиск производится не просто для проверки того, что нужный элемент в списке имеется, но и для того, чтобы получить данные, относящиеся к этому значению ключа. Например, ключевое значение может быть номером сотрудника или порядковым номером, или любым другим уникальным идентификатором. После того, как нужный ключ найден, программа может, скажем, частично изменить связанные с ним данные или просто вывести всю запись. Во всяком случае, перед алгоритмом поиска стоит важная задача определения местонахождения ключа. Поэтому алгоритмы поиска возвращают индекс записи, содержащей нужный ключ. Если ключевое значение не найдено, то алгоритм поиска обычно возвращает значение индекса, превышающее верхнюю границу массива. Для наших целей мы будем предполагать, что элементы списка имеют номера от 1 до N . Это позволит нам возвращать 0 в случае, если целевой элемент отсутствует в списке. Для простоты мы предполагаем, что ключевые значения не повторяются.
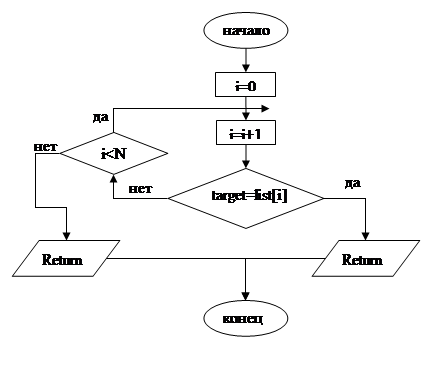
Алгоритм последовательного поиска последовательно просматривает по одному элементу списка, начиная с первого, до тех пор, пока не найдет целевой элемент. Очевидно, что чем дальше в списке находится конкретное значение ключа, тем больше времени уйдет на его поиск. Это следует помнить при анализе алгоритма последовательного поиска.
Вот как выглядит полный алгоритм последовательного поиска.
SequentialSearch(list.target,N)
listсписок для просмотра
target
целевое значение
N
число элементов в списке
for i=l to N do
if (target=list[i])
return i
end if
end for
return 0

Анализ наихудшего случая
У алгоритма последовательного поиска два наихудших случая. В первом случае целевой элемент стоит в списке последним. Во втором его вовсе нет в списке. Посмотрим, сколько сравнений выполняется в каждом из этих случаев. Мы предположили, что все ключевые значения в списке уникальны, и поэтому если совпадение произошло в последней записи, то все предшествующие сравнения были неудачными. Однако алгоритм проделывает все эти сравнения пока не дойдет до последнего элемента. В результате будет проделано N сравнений, где N — число элементов в списке.
Чтобы проверить, что целевое значение в списке отсутствует, его придется сравнить со всеми элементами списка. Если мы пропустим какой-то элемент, то не сможем выяснить, отсутствует ли целевое значение в списке вообще или оно содержится в каком-то из пропущенных элементов. Это означает, что для выяснения того, что ни один из элементов не является целевым, нам потребуется N сравнений.
Так что N сравнений необходимо как для того, чтобы найти значение, содержащееся в последнем элементе списка, так и для того, чтобы выяснить, что целевого значения в списке нет. Ясно, что N дает верхнюю границу сложности любого алгоритма поиска, поскольку, если сравнений больше N , то это означает, что сравнение с каким-то элементом выполнялось по крайней мере дважды, а значит была проделана лишняя работа, и алгоритм можно улучшить.
Между понятиями верхней границы сложности и сложности в наихудшем случае есть разница. Верхняя граница присуща самой задаче, а понятие наихудшего случая относится к решающему ее конкретному алгоритму.
Анализ среднего случая
Для алгоритмов поиска возможны два средних случая. В первом предполагается, что поиск всегда завершается успешно, во втором — что иногда целевое значение в списке отсутствует.
Если целевое значение содержится в списке, то оно может занимать одно из N возможных положений: оно может быть первым, вторым, третьим, четвертым и так далее. Мы будем предполагать все эти положения равновероятными, т.е. вероятность встретить каждое из них равна 1/N.
Прежде, чем читать дальше, ответьте на следующие вопросы.
• • Сколько сравнений требуется, если искомый элемент стоит в спи
ске первым?
• • А если вторым?
• • А если третьим?
• • А если последним из N элементов?
Если Вы внимательно посмотрели на алгоритм, то Вам несложно определить, что ответы будут выглядеть 1, 2, 3 и N соответственно. Это означает, что для каждого из N случаев число сравнений совпадает с номером искомого элемента. В результате для сложности в среднем случае мы получаем равенство
![]()
![]() Если мы допускаем, что целевого значения может не оказаться в списке, то количество возможностей возрастает до N
+ 1.
Если мы допускаем, что целевого значения может не оказаться в списке, то количество возможностей возрастает до N
+ 1.
Как мы уже видели, при отсутствии элемента в списке его поиск требует N сравнений. Если предположить, что все N + 1 возможностей равновероятны, то получится следующая выкладка:
![]()
![]()
![]() (Когда N
становится очень большим, значение 1/(
N
+
1) оказывается близким к 0.)
(Когда N
становится очень большим, значение 1/(
N
+
1) оказывается близким к 0.)
Видно, что допущение о возможности отсутствия элемента в списке увеличивает сложность среднего случая лишь на 1/2. Ясно, что по сравнению с длиной списка, которая может быть очень велика, эта величина пренебрежимо мала.
2. Двоичный поиск
При сравнении целевого значения со средним элементом отсортированного списка возможен один из трех результатов: значения равны, целевое значение меньше элемента списка, либо целевое значение больше элемента списка. В первом, и наилучшем, случае поиск завершен. В остальных двух случаях мы можем отбросить половину списка.
Когда целевое значение меньше среднего элемента, мы знаем, что если оно имеется в списке, то находится перед этим средним элементом. Когда же оно больше среднего элемента, мы знаем, что если оно имеется в списке, то находится после этого среднего элемента. Этого достаточно, чтобы мы могли одним сравнением отбросить половину списка. При повторении этой процедуры мы сможем отбросить половину оставшейся части списка. В результате мы приходим к следующему алгоритму
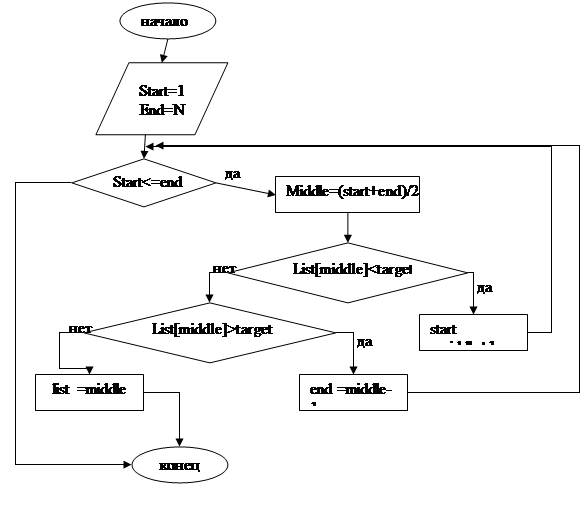
BinarySearch (list .target ,N ) list список для просмотра target целевое значение N число элементов в списке
start=l
end=N
while start<=end do
middle=(start+end)/2
select(Compare(list[middle].target)) from
case -1: start=middle+l
case 0: return middle
case 1: end=middle-l
end select
end while
return 0

В этом алгоритме переменной start присваивается значение, на 1 большее, чем значение переменной middle , если целевое значение превышает значение найденного среднего элемента. Если целевое значение меньше значения найденного среднего элемента, то переменной end присваивается значение, на 1 меньше, чем значение переменной middle . Сдвиг на 1 объясняется тем, что в результате сравнения мы знаем, что среднее значение не является искомым, и поэтому его можно исключить из рассмотрения.
Всегда ли цикл останавливается? Если целое значение найдено, то ответ, разумеется, утвердительный, поскольку выполняется оператор return. Если нужное значение не найдено, то на каждой итерации цикла либо возрастает значение переменной start , либо уменьшается значение переменойend . Это означает, что их значения постепенно сближаются. В какой-то момент эти два значения становятся равными, и цикл выполняется еще один раз при соблюдении равенства start =end =middle . После этого прохода (если элемент с этим индексом не является искомым) либо переменная start окажется на 1 больше, чем end и middle , либо наоборот, переменная end окажется на 1 меньше, чем start и middle . В обоих случаях условие цикла while ложным, и цикл больше выполнятся не будет. Поэтому выполнение цикла завершается всегда.
Возвращает ли этот алгоритм правильный результат? Если целевое значение найдено, то ответ безусловно утвердительный, поскольку выполнен оператор return. Если же средний элемент оставшейся части списка не подходит, то на каждом подходе цикла происходит исключение половины оставшихся элементов, поскольку все они либо чересчур велики, чересчур малы. Ранее мы говорили, что в результате мы придем к единственному элементу, который следует проверить. Если это нужный нам ключ то будет возвращено значение переменной middle . Если же значение ключа отлично от искомого, то значение переменной start превысит значение end или наоборот, значение переменной end станет меньше значения start . Если бы целевое значение содержалось в списке, то оно было бы меньше или больше значения элемента middle . Однако значения переменных start и end показывают, что предыдущие сравнения исключили все остальные возможности, и поэтому целевое значение отсутствует в списке. Значит цикл завершит работу, а возращенное значение будет равно нулю, что указывает на неудачу поиска. Таким образом, алгоритм возвращает верный ответ.
Поскольку алгоритм всякий раз делит список пополам, мы будем предполагать при анализе, что N=2k
-1 для некоторого k. Если это так, то сколько элементов останется при втором проходе? А третьем? Вообще говоря, ясно, что если на некотором подходе цикл имеет дело со списком из 2j
-1 элементов, то в первой половине списка 2j
-1
-1 элементов, один элемент в середине, и 2j
-1
-1 элементов во второй половине списка. Поэтому к следующему проходу остаётся 2j
-1
-1 элемент (при ![]() ). Это предложение позволяет упростить последующий анализ, но необходимости в нем нет.
). Это предложение позволяет упростить последующий анализ, но необходимости в нем нет.
Анализ наихудшего случая.
В предыдущем абзаце мы показали, что степень двойки в длине оставшейся части списка при всяком проходе цикла уменьшится на 1, а также, что последняя итерация цикла производится, кода размер оставшейся части становится равным 1, а это происходит при j=1 (так как 21 -1=1). Это означает, что при N=2k -1 число проходов не превышает k. Решая последние уравнение относительно k, мы заключаем, что в наихудшем случае число проходов равно k=log2 (N+1).
В анализе может помочь и дерево для процесса поиска. В узлах дерева решение стоят элементы, которые проверяются на соответствующем проходе. Элементы, проверка которых будет осуществляться в том случае, если целевое значение меньше текущего элемента, а сравниваемые в случае, если целевое значение больше текущего – в правом поддереве. Дерево решение для списка из 7 элементов изображено на рисунке1. В общем случае дерево относительно сбалансировано, поскольку мы всегда выбираем середину различных частей списка. Поэтому для подсчета числа сравнений мы можем воспользоваться формулами для бинарных деревьев.
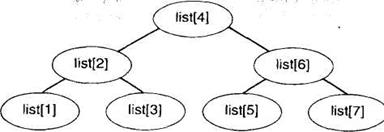 |
Поскольку мы предполагаем, что N=2k -1, соответствующие дерево решение будет всегда полным. В нем будет k уровней, где k=log2 (N+1). Мы делаем по одному сравнению на каждом уровне, поэтому полное число сравнений не превосходит log2 (N+1).
Рис. 1. Дерево решений для поиска в списке из семи элементов
Анализ среднего случая (изучить самостоятельно)
2.3. Выборка
Иногда нам нужен элемент из списка, обладающий некоторыми специальными свойствами, а не имеющий некоторое конкретное значение. Другими словами, вместо записи с некоторым конкретным значением поля нас интересует, скажем, запись с наибольшим, наименьшим или средним значением этого поля. В более общем случае нас может интересовать запись с К-ыы по величине значением поля.
Один из способов найти такую запись состоит в том, чтобы отсортировать список в порядке убывания; тогда запись с К-ыш по величине значением окажется на К-оы месте. На это уйдет гораздо больше сил, чем необходимо: значения, меньшие искомого, нас, на самом деле, не интересуют. Может пригодиться следующий подход: мы находим наибольшее значение в списке и помещаем его в конец списка. Затем мы можем найти наибольшее значение в оставшейся части списка, исключая уже найденное. В результате мы получаем второе по величине значение списка, которое можно поместить на второе с конца место в списке. Повторив эту процедуру К раз, мы найдем К-ое по величине значение. В результате мы приходим к алгоритму
FindKthLargest(list,K,N)
list список для просмотра
N число элементов в списке
К порядковый номер по величине требуемого элемента
for i=l to К do
largest=list[1]
largestLocation=1
for j=2 to N-(i-l) do
if list [j]>largest then
largest=list[j]
largestLocation=j
end if
end for
Swap(list[N-(i-l)],list[largestLocation])
end for
return largest
Какова сложность этого алгоритма? На каждом проходе мы присваиваем переменной largest значение первого элемента списка, а затем сравниваем эту переменную со всеми остальными элементами. При первом проходе мы делаем N — 1 сравнение, на втором — на одно сравнение меньше. На К- омпроходе мы делаем N — К сравнений. Поэтому для поиска К-ого по величине элемента нам потребуется
![]()
сравнений, что по порядку величины равно O (KN ). Следует заметить также, что если К больше, чем N /2, то поиск лучше начинать с конца списка. Для значений К близких к 1 или к N этот алгоритм довольно эффективен, однако для поиска значений из середины списка есть и более эффективные алгоритмы.
Поскольку нам нужно лишь К-ое по величине значение, точное местоположение больших К—\ элементов нас на самом деле не интересует, нам достаточно знать, что они больше искомого. Для всякого элемента из списка весь список распадается на две части: элементы, большие взятого, и меньшие элементы. Если переупорядочить элементы в списке так, чтобы все большие шли за выбранным, а все меньшие — перед ним, и при этом выбранный элемент окажется на Р-ом месте, то мы будем знать, что он Р-ый по величине. Такое переупорядочивание потребует сравнения выбранного элемента со всеми остальными, т.е. N — 1 сравнений. Если нам повезло и Р = К, то работа закончена. Если К < Р, то нам нужно некоторое большее значение, и проделанную процедуру можно повторить со второй частью списка. Если К > Р, то нам нужно меньшее значение, и мы можем воспользоваться первой частью списка; при этом, однако, К следует уменьшить на число откинутых во второй части элементов. В результате мы приходим к следующему рекурсивному алгоритму.
KthLargestRecursive(list.start,end,К)
list список для просмотра
start индекс первого рассматриваемого элемента
end индекс последнего рассматриваемого элемента
К порядковый номер по величине требуемого элемента
if start< end then
Partitiondist, start,end.middle) if middle=K then
return list[middle] else
if K<middle then
return KthLargestRecursive(list,middle+1,end,K) else
return KthLargestRecursive(list,start,middle-l,K-middle)
end if
end if
end if
Если предположить, что в среднем при разбиении список будет де литься на две более или менее равные половины, то число сравнений будет приблизительно равно
N + N/2 + N/4 + N/8+…+1 , т.е. 2N. Поэтому сложность алгоритма линейна и не зависит от К.
Литература:
1. Дж. Макконелл Анализ алгоритмов. Вводный курс
2. Д.Э. Кнут Искусство программирования. Том 3.