| Скачать .docx |
Реферат: Сеть на основе нейрочипа
Министерство общего и профессионального образования
Московский Энергетический Институт
филиал в городе Смоленске
Кафедра вычислительной техники
РАСЧЕТНО-ПОЯСНИТЕЛЬНАЯ ЗАПИСКА
к курсовой работе по курсу
"Сети ЭВМ и средства коммуникации"
на тему
«Сеть на основе нейрочипа»
гр. ВМ1-97 студент: Вальков К.Г. преподаватель: Аверченков О.Е. |
г. Смоленск 2000г.
Аннотация
Автор: Вальков Константин Георгиевич, Группа ВМ1-97, Смоленский филиал Московского Энергетического Института, кафедра Вычислительной техники.
Данная работа включает в себя : 20 страниц теоретического введения, 4 страницы описания разработки системы и 6 страницы анализа разработки. В пункт приложения входят три модуля : документированный текст программы, схема принципиальная - электрическая , техническое задание.
Название работы : «Обработка информации поступающей с аэродинамических датчиков (датчики анализа скорости ветра) и передача поступающей информации по сети в ЭВМ, сеть реализовать на основе нейрочипа».
Количество страниц: 47
рисунков: 7
приложений: 3
Содержание: Данная расчетно-пояснительная записка является результатом проведенного анализа работы нейрочипа с последующей реализацией сети на его основе и выводами результативности его применения в данном случае. Результатом является схема и программная реализация работы сети на основе нейрочипа для подсчета скорости ветра и в случае превышения некоторого порога (скорость ветра 50м/с ) передача сигнала на центральную ЭВМ.
1. Введение
1.1. Причины и последствия объединения компьютеров в сеть
Для того, чтобы максимально эффективно использовать вычислительные ресурсы компьютеров, их необходимо объединить в сеть. Задолго до того, как появился микропроцессор, большие вычислительные системы объединяли с помощью телеграфных линий связи. Однако бурное развитие компьютерных сетей началось только с появлением LAN (LocalAreaNetwork), когда использование компьютера небольшими фирмами стало экономически обоснованным. С появлением возможности объединять LAN в WAN (WideAreaNetwork) специалисты начали думать об осуществлении идеи полной автоматизации производства - CIM (ComputerIntegratedManufacturing). Однако несмотря на падение цен на микропроцессоры и оперативную память, идея полностью автоматизированного предприятия в то время так и не осуществилась.
LON (LocalOperatingNetwork) предназначена именно для автоматизации производства.
До XVIII века создавали только механические станки и применяли осязаемые виды энергии. Одной из важнейших предпосылок промышленной революции явились открытия в области физики, например преобразование энергии из одного вида в другой, которое позволило привести в действие ткацкий станок с помощью пара и заставило двигаться автомобиль. Таким образом, появилась возможность ограничить использование людей в качестве рабочей силы и все больше заменять их труд машинами. Следствием этого стало развитие крупных предприятий.
Наше время - время информационных технологий. Мы все больше и больше учимся обрабатывать информацию с помощью машин, хранить, передавать и распределять ее. Телефонная сеть, персональный компьютер, радио, Интернет - примеры того, как изменился мир благодаря информационным технологиям.
Компьютер и компьютерные сети все чаще применяются для автоматизации производственных процессов. Fieldbus-системы, которые представляет и LON, могут стать существенной составной частью будущих сетей, базисом для разработок, которые в ближайшем будущем приобретут большую значимость. Идея СIМ стала особенно привлекательной сейчас, когда стало известно, каким образом можно объединить датчики и исполнительные механизмы «в поле» (от англ. «inthefield», имеется в виду термин Fieldbus - полевая шина), не прибегая к большим затратам. Еще несколько лет назад автомобили имели от 20 до 50 датчиков и исполнительных механизмов; через несколько лет, по нашим оценкам, их число должно значительно возрасти -до 500 и более. То же самое будет происходить в области автоматизации систем зданий, домашнего хозяйства, промышленности и т. д.
Итак, объединение компьютерных систем управления в сеть может быть экономически эффективно на основе Fieldbus-технологии.
До сих пор взгляд человека на организацию окружающего его мира носит ярко выраженный центристский характер. Для многих фирм, партий и т.д. характерна жесткая иерархическая структура. Этот подход привносится и в область управления техникой. О том, что иерархическая структура не оптимальна, известно давно. Это должно натолкнуть нас на мысль, что нужно стремиться к децентрализации технологических процессов.
LON создается без использования традиционных PLC (ProgrammableLogicController) -контроллеров с программируемой логикой. Основная идея LON заключается в наиболее децентрализованном распределении интеллекта на основе новых концепций.
1.2. Управление техническими процессами
1.2.1. Классический подход
Для управляющих систем традиционна централизованная структура . Исходя из централизованноcти системы, управляющее вычислительное устройство запрашивает данные датчиков или приборов и после обработки возвращает их обратно. Датчики, как и исполнительные механизмы, не обладают интеллектом. Более современная структура включает в себя концентраторы , которые заменили длинные параллельные линии передачи данных. Преимущества такого подхода известны: улучшенная электрическая совместимость, более простое формирование соединений, низкая стоимость линий передачи данных, экономия на клеммах и т. д. Однако возникают трудности, связанные с переходом от одних принципов передачи данных к другим, так как во многих случаях отсутствует совместимость ряда параметров. Результатом этого становится усложнение управляющей станции. С появлением интегральных микроэлементов широкое распространение получили контроллеры с программируемой памятью, прошедшие стандартизацию в условиях эксплуатации. Причем с развитием микропроцессорной техники цены на аппаратное обеспечение резко снизились.
Тем временем обозначилась новая тенденция - замена контроллеров с программируемой памятью промышленными персональными компьютерами, которые обладают рядом преимуществ. Во-первых, они позволяют применять более доступное по цене аппаратное обеспечение; во-вторых, можно разработать простое в применении и недорогое программное обеспечение, которое поставляют различные фирмы, постоянно совершенствуя его. Значительно реже возникает необходимость самостоятельной разработки и обслуживания. Единственной проблемой может быть выбор подходящих программ реального времени, предлагаемых рынком в достаточном количестве.
1.2.2. Децентрализованный подход
С некоторого времени получили широкое распространение шинные системы, в частности Fieldbus-системы, которые по сравнению с концентраторами данных экономически более выгодны. Fieldbus-системы представляют собой новую технологию, которая предлагает новый образ мышления при системном проектировании. Узлы Fieldbus-системы могут децентрализованно использовать интеллект для управления, регулирования и контроля. В предельном случае это может быть система с полным отсутствием центрального управления (функции контроллеров с программируемой памятью, очевидно, распределяются между различными узлами сети, такими как датчики, исполнительные механизмы и устройства индикации). То, что данный подход позволяет мыслить совершенно иначе, понятно на таком примере.
Представим себе стаю уток, летящих в форме треугольника . Если они управляются централизованно, то «центральный компьютер» постоянно должен рассчитывать траекторию полета для каждой утки. Если хотя бы одна из них будет застрелена охотником, то компьютер с помощью соответствующего алгоритма, должен будет снова заполнить образовавшееся пустое пространство, изменив траекторию полета остальных уток. Естественно, для такой сложной системы, как центральный компьютер. подобный алгоритм реализовать непросто.
Предположим теперь, что утки объединены в сеть посредством некой Fieldbus-системы. Теперь требуется лишь задать каждой утке угол, под которым она должна лететь по отношению к впереди летящей, и расстояние до нее. Если какая-либо из уток будет застрелена, то система относительно быстро восстановится сама и для заполнения пустого пространства не потребуется каких-либо дополнительных затрат. Интеллект каждой утки в этом случае может быть относительно невысоким.
Само собой разумеется, что и в центрально-ориентированную систему могут быть встроены простые параллельные процессы, как это сделано в Fieldbus-системах. Однако такое решение 'при разработке центрально-ориентированной системы не напрашивается. Центрально-ориентированная система «принуждает» разработчика думать централизованно, строя сложные алгоритмы. К тому же в центрально-ориентированной системе всегда используются дорогостоящие многозадачные пользовательские системы, требующие больших затрат на разработку и обслуживание. Устройства Fieldbus-систем, наоборот, применяют в больших количествах, поэтому себестоимость их производства весьма мала.
1.3. Информационный обмен как основа распределенных систем
1.3.1. Иерархия системы
Объединение систем компьютеров в сеть приобретает настолько сложный характер, что плоская архитектура сети теряет всякий смысл. Во всех областях автоматизации предпочтение отдается сетям с вертикальной иерархией систем, в которых на каждом уровне можно реализовать логически обособленный набор функций. Рассмотрим пятиуровневую модель некоего автоматизированного производства [рис.1-4]. Слева от нее находится сеть, с помощью которой можно упорядочить уровни. Понятно, что количество уровней и их вид зависят от набора параметров, определяющих конкретную систему. При автоматизации систем зданий эта схема выглядит совсем не так, как в случае системы управления технологическими процессами. Разумеется, от начальных условий (набора функций для конкретного уровня) зависит, какая сеть и на каком уровне будет использована, - практика заставляет думать более гибко.
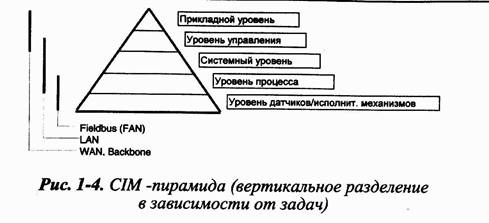
В основе терминологии, принятой в этой книге, лежит следующее правило: исходя из общепринятого определения LAN (например, IEEE 802.3), все сети, находящиеся иерархически ниже, должны называться FAN (FieldbusAreaNetworks). He должно проводиться разделения на «шины датчиков и исполнительных механизмов», «мультиплексные шины» и т. д., так как основным поводом для него служат маркетинговые интересы. Иерархически вышестоящими по отношению к LAN следует считать WAN, связывающие LAN между собой, а в определенных случаях и FAN (например, при прямом соединении LonWorks сетей ISDN). Для полноты картины назовем GAN - так называемые глобальные спутниковые сети, находящиеся иерархически выше WAN.
1.3.2. Семиуровневая модель ISO / OSI
Для описания сетевого взаимодействия Международная организация по стандартизации ISO (InternationalOrganisationforStandardisation) разработала модель сетевого объединения компьютеров (в то время речь шла прежде всего об объединении с помощью WAN и LAN), которая была названа OSI (OpenSystemInterconnection, в русской терминологии - модель взаимодействия открытых систем). Встречается и полное название - модель ISO/OSI. Принцип, который лег в ее основу, был относительно прост. Все необходимые коммуникационные функции были собраны и упорядочены в рамках семиуровневой иерархической модели. При меньшем количестве уровней разбиение на модули не дает преимуществ. Большее количество уровней нежелательно, так как существующий между ними интерфейс приводит к так называемым вертикальным издержкам - непроизводительным затратам системных ресурсов. Исходя из этих соображений и было выбрано магическое число семь.
Когда разрабатывали стандарт ISO/OSI, меньше всего думали о функциях реального времени и не предвидели появления Fieldbus-систем. Несмотря на это, позже модель ISO сочли подходящей для спецификации и описания. Поскольку она положена в основу большинства существующих систем, вырабатывается общий образ мышления, возможно, отчасти сглаживающий ее недостатки.
Все физические и механические параметры модели определяются на нижнем уровне, который является передающим. На более высоких уровнях определяется способ доступа к шине, описывается составление кадров данных и осуществление их защиты при передаче (связь абонентов типа «точка-точка»). Если между двумя устройствами установлено соединение, то при этом образуются как минимум две связи типа «точка-точка», которые могут быть совершенно различными.
На уровне 3 выполняется маршрутизация, то есть выбор пути. В телефонной сети на этом уровне осуществляют связь пути с номером телефона, поэтому его часто называют коммутационным. Уровень 4 управляет связью «точка-точка»: он отвечает за то, чтобы пакеты данных, посланные отправителем, дошли до получателя в нужном порядке, то есть управляет потоком информации.
На уровне 5 организуются сеансы - одновременный обмен данными между различными абонентами. В определенных ситуациях задачей этого уровня является идентификация участников и синхронизация сессий после их прерывания. На уровне 6 происходит согласование общего набора символов (языка).
Уровень 7, как и уровень 1, занимает особое место: он представляет собой интерфейс с внешним миром, а также службы прикладного уровня - либо самостоятельно, либо требуя этого от уровней, лежащих ниже него, которые в свою очередь также могут обратиться к ниже лежащим уровням (иерархическая система).
Рассмотрим различные предметные области (наборы параметров, описывающих систему), например, системы автоматизации зданий и технологических процессов. Требования, предъявляемые к производительности этих двух управляющих систем, совершенно различны. Из соображений безопасности при автоматизации технологических процессов никогда не производят подключения большого количества узлов к одному сегменту. Очевидно, по этой же причине в Fieldbus-системах, применяемых в этой области, стараются использовать не более 1000 или даже 100 узлов. Но если можно ограничить количество узлов и отказаться от маршрутизаторов (коммутационных узлов), то уровень 3 не нужен, может отпасть необходимость и в уровне 4. Выигрыш огромен: из коммуникационной колонны выпадает несколько интерфейсов, система становится дешевле, повышается ее быстродействие.
При автоматизации зданий хотят, наоборот, иметь по возможности как можно больше узлов. Помимо того пользовательская сеть, объединяющая системы освещения, обогрева и регулировки климата, должна соединяться с системами сигнализации и охраны. При этом важно, чтобы узлы могли обмениваться данными различными путями. Таким образом, уровни 3 и 4 оказываются необходимы.
Приведенные примеры показывают, что модель ISO/OSI не требует интеграции всех семи уровней в реальную систему.
Функции нереализованных уровней можно перенести на другие уровни. Почти все Fieldbus-системы, используемые для автоматизации процессов, имеют всего три уровня, тогда как те, что применяются для автоматизации зданий, имеют по крайней мере пять уровней. LonWorks - одна из немногих Fieldbus-систем, в которой присутствуют все семь уровней. Это объясняется двумя причинами. Первая указана почти во всех изданиях корпорации ECHELON: при универсальности применения LonWorks полностью обеспечивает объединение сетей компьютеров.
Вторая причина упоминается не так часто. Уже сейчас видно, что LonWorks в конечном итоге значительно превзойдет производительность всех существующих Fieldbus-систем. Если на сегодняшний день мы еще не можем автоматизировать все возможные процессы с помощью LonWorks, то уже в недалеком будущем такая возможность представится.
Еще несколько замечаний относительно модели ISO/OSI. Различают два направления коммуникации [рис.1-6]. Коммуникация между некоторым уровнем п и уровнем выше (n +1) осуществляется посредством интерфейса, построенного на основе спецификаций служб. Верхний уровень является «пользователем служб» (SU, ServiceUser), а нижний - их «поставщиком» (SP, ServiceProvider). Обмен информацией между уровнями осуществляется в точках доступа к службе (ServiceAccessPoints, SAP), причем элемент более высокого уровня может обращаться к элементу более низкого уровня. Это важно, если, например, нужно соединить уровни с помощью другого пути, что достигается выбором специальных SAP.
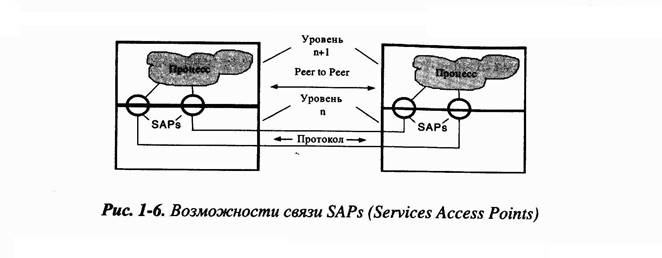
Горизонтальная коммуникация (коммуникация между двумя одинаковыми лежащими напротив друг друга уровнями) осуществляется посредством протокола типа Peer-to-Peer - протокола взаимодействия между элементами сети. Таким образом, на семи уровнях существует семь протоколов.
1.4. Топологии
Сети можно классифицировать по физической и логической структуре. Высказывание «сеть построена по принципу кольцевой или шинной структуры» является неполным. Например, в основе Fieldbus-системы может быть физическая шина, которой на верхнем уровне соответствует логическое кольцо. Возможен и обратный вариант. Вопрос о том, какая архитектура оптимальна, решают по-разному в каждом конкретном случае. LonWorks предполагает различные топологические структуры, и все они имеют право на существование. Рассмотрим их разновидности.
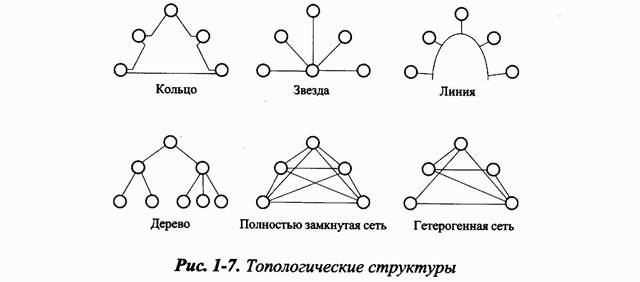
С точки зрения реализации самая простая структура — кольцо [рис1-7], в котором все узлы соединены друг с другом по принципу «точка-точка». Механизмы передачи данных могут использоваться самые различные. Наиболее быстрым в области Fieldbus-систем является «способ сдвигающего регистра»: каждый узел имеет в своем распоряжении такой регистр, который сдвигает поступающие данные. Поскольку все узлы логически соединены последовательно, то кольцо образует один большой сдвигающий регистр, состоящий из отдельных узлов - сдвигающих регистров. Явная адресация в этом случае отсутствует, кадр идентифицируется по его началу; после фазы конфигурации каждый узел может самостоятельно определить, какие биты зарезервированы для него. Если предположить, что все узлы посылают и принимают данные с максимально возможной скоростью, то система теоретически имеет наименьшее время реакции.
Однако на практике наибольший интерес представляют кольца другого типа. Представьте себе кольцо, в котором узлы могут принимать и посылать данные в обоих направлениях. Если разрушить такое кольцо в какой-либо точке, то для передачи данных на все остальные узлы можно использовать противоположное направление. Это часто необходимо для систем, требующих высокой надежности (например, системы наблюдения). LonWorks допускает такой вид топологии.
При топологии типа «звезда» вся информация проходит через центральный узел. Как и в кольце, все связи строятся по принципу «точка-точка», что часто упрощает систему коммуникационной техники и разводки кабеля. Многие локальные сети, физически построенные по типу «линия» или «кольцо», имеют разводку кабеля, подобную «звезде». Однако системы типа «звезда», несмотря на их широкое распространение, являются коммутационными. Все основные функции коммутационной системы сосредоточены в центральном коммуникационном устройстве. Терминальное оборудование (телефонные аппараты, факс-машины и т. д.) обладает относительно невысоким интеллектом; отсюда следует, что его можно покупать по довольно низкой цене. Причем производительность и интеллект находятся в одном центральном устройстве, что упрощает обслуживание системы.
Применительно к системам управления топология типа «звезда» обладает рядом преимуществ: контроллер с программируемой памятью является классической централизованной системой. Внедрение интеллектуальных компонентов ввода/вывода в области автоматизации технологических процессов до сих пор не достигло значительного продвижения на рынке; контроллеры с программируемой памятью и на сегодняшний день играют доминирующую роль. Для широкого распространения децентрализованных систем нужно провести серьезную работу.
«Шина» - лучше называть ее «линия» - одна из самых широко распространенных топологических структур. Однако следует помнить об ее недостатке. Несмотря на то, что каждый узел электрически имеет всего одно соединение с линией, физически для подключения требуются либо сдвоенные, либо Т-образные разъемы, затраты на которые часто недооценивают. Значительная часть стоимости узла приходится именно на соединение, из-за чего эта структура не может применяться во многих последовательных системах, хотя в параллельных способна обеспечить более высокую производительность.
Основной проблемой этой топологической структуры является доступ к шине . В связи с этим необходимо упомянуть один очень важный аспект: для многих приложений требование «real-time» (реального масштаба времени) является критическим. Под реальным масштабом времени подразумевается гарантированное время реакции системы. Например, водитель автомобиля должен иметь гарантию, что при нажатии на педаль тормоза желаемый эффект торможения будет достигнут без задержки.
Рассмотрим этот аспект более подробно. Полное время задержки реакции есть сумма задержек всех процессов, происходящих в системе. Задержка, вызываемая шиной, может быть минимальной по сравнению с другими - в этом случае она не оказывает существенного влияния на процесс управления. Существует и еще один момент, которому часто не уделяют должного внимания. Real-time требуют многие системы, однако, по экономическим соображениям, определенное время реакции обычно гарантируют лишь с высокой вероятностью. Какой смысл гарантировать время реакции «абсолютно», в то время как надежность системы задается вероятностными величинами (ведь система может включать в себя множество непомехозащищенных электронных компонент)? Если время задержки гарантируется с экономически приемлемой вероятностью, этого вполне достаточно. Эта идея и была подхвачена LonWorks (LonWorks гарантирует время доступа с определенной вероятностью, которую, можно определить так, что система будет пригодна даже в случаях, касающихся безопасности человека).
И еще несколько кратких замечаний относительно методов доступа. В локальных сетях чаще всего применяют два метода доступа к шине: маркерный и множественный. Последний носит название CSMA/CD (CarrierSenseMultipleAccess/ Collision Detection-множественный доступ с контролем несущей / распознаванием коллизий). Маркерный метод доступа проще, но, к сожалению, по сравнению с CSMA/CD его реализация обходится, как правило, значительно дороже. Суть этого метода состоит в следующем. В шинной системе существует один маркер, который передается от узла к узлу согласно определенному алгоритму. Узел, который в какой-то момент владеет маркером, получает право отправлять сообщения (занимать шину). Нужно следить за тем, чтобы во время работы системы не происходило обмена двумя или более маркерами, чтобы маркер не терялся и т.д.. Метод CSMA означает, что прежде чем получить доступ к шине, узлы «прислушиваются» к среде (listenbeforetalk –слушать прежде, чем говорить).
1.5. Инструментарий
Одна из наиболее важных причин успеха на рынке Fieldbus-систем –наличие инструментария для их разработки, настройки и сопровождения. Здесь уместно привести классический пример из истории 16-разрядных микропроцессоров. После разработки разными компаниями первых трех моделей анализ их производительности показывал: у 8086 она была очень небольшой, у 68000 – значительно выше, а наибольшую производительность демонстрировал Z8000 со своими чрезвычайно гибким набором регистров. Но именно последний исчез с рынка в первую очередь, 68000 также не смог приблизится по объему продаж к 8086. это объясняется рядом причин, но одна из них стала решающей: фирма Zilog, разработавшая Z8000, не смогла своевременно предложить соответствующий инструментарий. Поэтому компании, представляющие на рынок новые типы микропроцессоров, должны четко представлять себе полную стоимость будущей системы на всех этапах ее существования ( разработка, реализация и сопровождение).
Несомненно, что с появлением NEURONChip («нейронного чипа»-программно-аппаратный комплекс, предназначенный для разработки и отладки приложений для NEURONChip) в распоряжение разработчиков поступил необходимый инструментарий – LonBuilder. Echelon не стала повторять ошибок других компаний и не концентрировала вес свои ресурсы на разработке новых версий NEURONChip. Наоборот, приоритет был отдан разработке нового и улучшению существующего инструментария. Если сравнить результаты достигнутые в этом направлении LON-технологией и другими Fieldbus-системами, то LON значительно опережает все остальные. Так от стандартного аппаратного языка Assembler, компания Echelon перешла к программированию NEURONChip на языке более высокого уровня NEURONC.
Язык программирования приложения для NEURONChip (CPU-3) основывается на ANSI-C, является ответвлением языка программирования С. Он был создан для NC и не может применятся для других процессоров.
В основе построения локальной сети в стандарте LONWORKS лежит применение специализированных гибридных микросхем NEURON Chip в качестве микроконтроллеров узлов локальной сети.
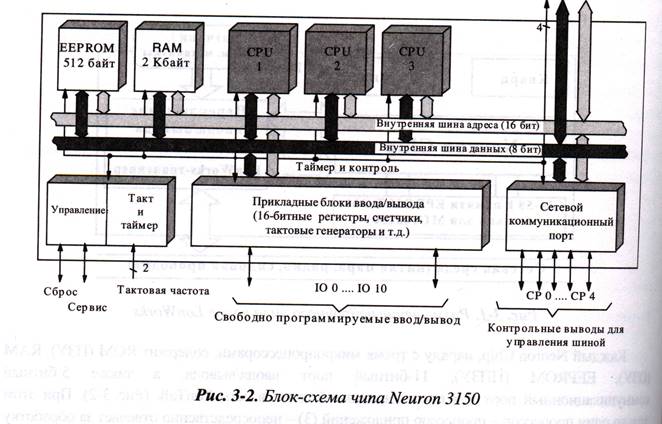
Микроконтроллер NEURON Chip содержит три 8-разрядных процессора, объединенных внутренней шиной со встроенными блоками общей оперативной и энергонезависимой памяти, а также периферийными устройствами (сетевым коммуникационным портом, таймерами, управляющими регистрами, портами ввода/вывода). Модель NEURON MC143120 также предусматривает использование и внешней памяти хранения программ. Несмотря на архитектурную симметричность внутренних процессоров, функциональное назначение каждого из них строго детерминировано. Два из них управляют сетевой передачей данных на основе многоуровнего сетевого протокола, а один предназначен для обслуживания прикладной части программного обеспечения узла. Синхронизация работы процессоров осуществляется за счет использования общих областей памяти данных. Уникальность адреса каждого из микроконтроллеров стандарта LONWORKS может быть обеспечено благодаря наличию собственного 48-разрядного идентификационного кода, записываемого в энергонезависимую память при их производстве.
Взаимодействие с внешними устройствами производит процессор прикладного уровня посредством 11-выводного порта ввода/вывода. Функциональное назначение выводов порта может быть задано прикладным программным обеспечением, в зависимости от типов внешних устройств, обслуживаемых микроконтроллером.
В случае недостаточной вычислительной или функциональной мощности микроконтроллера NEURON Chip для реализации функций узла по взаимодействию с внешними устройствами, в составе узла может быть применен дополнительный микроконтроллер, удовлетворяющий задаче сбора данных или управления. В этом случае порт ввода/вывода может быть использован для связи микроконтроллеров с целью организации обмена данными по параллельному интерфейсу, а сам микроконтроллер NEURON Chip выполняет только коммуникационные функции.
Для реализации сетевых функций микроконтроллера служит 5-выводной коммуникационный порт, управляемый процессором, обслуживающим два нижних уровня сетевого протокола. С целью сопряжения микроконтроллера с физическим каналом связи, к коммуникационному порту подключаются приемопередатчики в соответствии с выбранным типом канала связи.
1.5.1. Основные характеристики микроконтроллеров NEURON Chip.
Количество микропроцессоров в кристалле - 3, типа MC143120.
Уникальный 48-битный код (NEURON ID).
11 двунаправленных линий ввода/вывода.
2 16-битных таймера/счетчика.
5 линий коммуникационного интерфейса.
Микроконтроллеры NEURON выпускаются в 64 выводном QFP (NEURON 3150) и 32 выводном SOIC корпусах (NEURON 3120xx ).
| Производитель | Наименование | EEPROM | RAM | ROM |
| Motorola | MC143120B1DW | 0.5K | 1K | 10K |
| MC143150B1FU | 0.5K | 2K | Нет | |
| MC143120E2 | 2K | 2K | 10K | |
| Toshiba | TMPN3120B1F | 0.5K | 1K | 10K |
| TMPN3150B1F | 0.5K | 2K | Нет | |
| TMPN3120E1 | 1K | 1K | 10K |
Промышленно выпускаемые в стандарте LONWORKS приемопередатчики обеспечивают организацию следующих типов каналов связи: линейного, свободной топологии, RS-485, радиочастотного, элекросетевого и т.д. Скорость передачи данных в каналах, в зависимости выбранного типа канала, обеспечивается в диапазоне 330 бит/с – 1.25 Mбит/c.
Для сопряжения каналов связи различных типов могут применяться специальные маршрутизаторы, построение которых основано на применении двух микроконтроллеров NEURON, связанных по параллельному интерфейсу порта ввода/вывода, и имеющих собственные приемопередатчики, соответствующие характеристикам типов сопрягаемых каналов. На программно-логическом уровне построения маршрутизатора, устройству могут быть предписаны различные функции по передаче данных между сегментами локальной сети.
Программное обеспечение микроконтроллеров NEURON составляется из трех разделов: системного программного обеспечения, прикладного, и программного обеспечения уровня связи данных.
Структурная схема нейрочипа изображена на рисунке [рис.3-2]
Системное программное обеспечение является резидентным для каждого из микроконтроллеров. Его программный код либо прошивается во встроенный узел ROM моделей NEURON3120 на этапе производства микроконтроллеров, либо записывается в модуль внешней памяти моделей NEURON3150. На программно-логическом уровне системное программное обеспечение полностью реализует функции многоуровневого сетевого протокола LONWORKS, планировщика задач для прикладного уровня программного обеспечения, и содержит код библиотеки программных функций для управления портом ввода/вывода микроконтроллера. На основе применения программных средств, предоставляемых системным программным обеспечением, на базе порта ввода/вывода возможна организация нескольких типов интерфейсов с внешними устройствами: дискретного, параллельного, I2C, RS-232, Microwire, MicroLan и т.д.
Системная часть программного обеспечения реализует также полный набор операций для управления сетевым взаимодействием узлов системы. Реализация сетевым протоколом LONWORKS функций управления конфигурацией сети, предоставляет возможность вынесения задач управления локальной сетью на отдельный уровень, обеспечиваемый, независимыми от особенностей построения отдельных узлов, аппаратно-программными средствами.
Прикладная часть программного обеспечения строится разработчиком узла и определяет набор задач по обслуживанию связанных с функционированием узла процедур регистрации данных и управления исполнительными устройствами. На нижнем уровне систем автоматизации, построенных по стандарту LONWORKS, определяется набор входных и выходных сетевых переменных, необходимых для функционирования конкретного узла и реализации его сетевых функций. При проектировании прикладного программного обеспечения, описание сетевых переменных отдельного узла определяется либо непосредственно в самодокументированной секции энергонезависимой памяти микроконтроллера, либо описание их мнемонических имен, типов и разрядности записывается в специальный внешний файл описания интерфейса проектируемого узла. Описание сетевых интерфейсных функций узла применяется на этапе построения связей сетевых переменных.
При использовании в качестве микроконтроллера узла модели NEURON3150 и внешней памяти программ типа FLASH, допускается загрузка прикладной части программного обеспечения узла по сети LONWORKS. Данная функция предоставляет возможность гибкого управления узлом без его демонтажа из системы.
Разработка прикладного уровня программного обеспечения производится с применением специального языка программирования NEURON-C (специальной реализации языка C). C уровня прикладного программного обеспечения допускается использование (вызовов) всех функций, предоставляемых системной частью программного обеспечения.
Для разработки узлов, построенных на базе NEURON, применяются специальные аппаратно-программные отладочные комплексы LONBUILDER и NODEBUILDER, производимые фирмой Echelon.
LONBUILDER, представляет собой крейт, содержащий в себе блок питания, интерфейс для связи с компьютером и имеющий 7 слотов для установки эмуляционных модулей. LONBUILDER позволяет с помощью устанавливаемых в него модулей производить отладку:
1. прикладного программного обеспечения модулей разработанных пользователем на основе различных NEURON-контроллеров,
2. объединять несколько эмуляционных модулей в сеть Echelon .для отладки сетевых взаимодействий,
3. с помощью роутер-модуля осуществлять объединение действующей и проектируемой сетей,
4. объединять узлы ECHELON в сети различных типов,
а также LONBUILDER может быть использован, в качестве шлюза-маршрутизатора сети ECHELON, с возможностью каскадирования отдельных крейтов LONBUILDER. Таким образом, LONBUILDER является мощнейшим средством отладки не только непосредственно прикладного программного обеспечения конкретного модуля, но и полноценным эмулятором сети ECHELON, а учитывая его широкие возможности при построении реальной сети его цена перестает быть столь пугающе высокой (от 24 тысяч долларов США в базовой поставке, состоящей из LONBUILDER, 2-х эмуляторов NEURON 3150, служебного модуля LONBUILDER, роутера, РС-карты, программного обеспечения и комплекта проводов).
Уровень сопряжения узлов нижнего уровня системы автоматизации с устройствами верхнего уровня предполагает использование специализированного программного обеспечения для организации взаимодействия узлов микроконтроллерной сети. Как правило, устройство управления локальной сетью организуется на базе персонального компьютера, содержащего устройство сопряжения с сетью в стандарте LONWORKS. С уровня подобного компьютера возможно обеспечить управление связыванием выходных и входных переменных отдельных узлов нижнего локальной сети и осуществлять общие функции управления сетью, предусматривающие идентификацию узлов, определение и управление их статусом в локальной сети, тестирование сетевых переменных каждого из узлов.
Структура связей сетевых переменных узлов локальной сети, и определенное при конфигурации сети состояние каждого из узлов, записывается как в энергонезависимую память узлов, так и в базу данных компьютера-конфигуратора сети.
Необходимо отметить, что протокол LONWORKS предусматривает специальные функции по защите данных и их кодированию при передаче между узлами сети. Эти функции обеспечивают надежность передачи информации и невозможность несанкционированной замены узлов локальной сети.
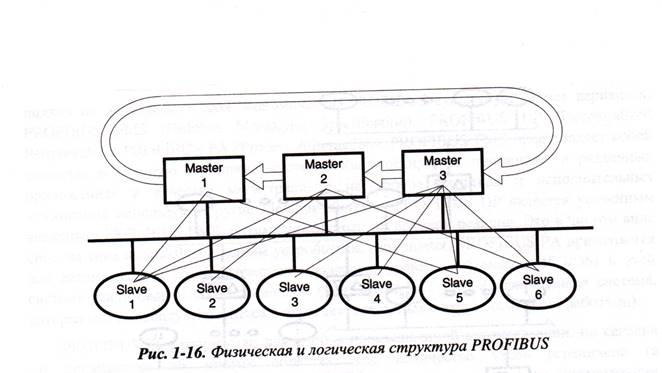
На рисунке 1-16 указана структура обмена данными между нейрочипами типа SLAVEA и MASTERA. На данном рисунке изображены три нейрочипа MASTERA, но для обработки в нашем случае достаточно и одного.
Для сопряжения нижнего уровня локальной сети, построенной на базе стандарта LONWORKS, c уровнем компьютерных станций могут быть применены платы и автономные устройства, промышленно выпускаемые фирмами, поддерживающими данный стандарт. Так фирма IEC (США) производит автономный сервер данных (Datalogger), реализованный на базе PC-104 и оснащенный интерфейсной платой для взаимодействия с сетью, выполненной на базе микроконтроллера NEURON.
При организации работы станций верхнего уровня систем автоматизации, базируемых на стандарте LONWORKS, может применяться как коммерческое, например, производимое фирмой IEC, так или же специализированное программное обеспечение разработанное отдельными пользователями для решения конкретных задач (например, MIMS, разработанное Sandia National Laboratories).
1. Постановка задачи
1.1. Обзор литературы и предлагаемые методы решения.
В связи с тем, что первый нейрочип был произведен в середине 1999 года, то количество литературы описывающей работу нейрочипа ограничено. Отечественных книг еще не написано, используются только переводы зарубежных авторов. Так наиболее подходящей книгой для реализации данного задания является книга немецкого автора Дитрих – Лой – Швайнцер «Lon технология». В этой книге есть как структурная, функциональная, так и программная реализация работы нейрочипа. Внутренней, электрической схемы нейрон чипа найдено не было по ранее описанным обстоятельствам и в связи авторским патентом выданным в США (USApatent № DC1233 -10 1999) о авторских правах на реализацию нейрочипа. Поэтому приведенная в приложении №1 схема является лишь примерной функциональной - электрической схемой, т.е. изображены внешние выводы микросхем, но а внутренней структуре умалчивается.
Методов реализации поставленной задачи в нашем случае может быть довольно много. Это обусловлено тем, что элементная база достаточно разнообразна и постоянно усовершенствуется. Так, например, на данный момент существует порядка 15 видов нейрочипов, со встроенной и внешней памятью, работающих на разных частотах, различным количеством выводов и разной формой, размером микросхем.
По заданию необходимо реализовать сеть на основе нейрочипа для обработки данных поступающих с аэродинамических датчиков подсчета скорости ветра. Т.к. данная сеть должна состоять из двух основных частей: разветвленной сети датчиков (каждый элемент состоит датчика + обрабатывающий нейрочип) и центрального процессора ( пороговый нейрочип + шина передачи данных в компьютер ), то тип нейрочипов и внешних устройств выбран оптимально из условия обеспечения их следующими компонентами:
1) напряжение питания : +(5-12)В
2) место размещения : объемом 30х20х7 (см3 )
3) вибрационная устойчивость
Исходя из данных требований был выбран следующий тип нейрочипов, преобразующих устройств и устройств сопряжения: нейрон чип SLAVEAMC143120 32-LEDSOG , нейрон чип MASTERAMC143120 32-LEDSOG, преобразующее устройство MS555, устройство сопряжения MC145407.
1.2. Анализ задания.
В соответствии с заданием необходимо обработка информации поступающей с аэродинамических датчиков (датчики анализа скорости ветра) и передача поступающей информации по сети в ЭВМ, сеть реализовать на основе нейрочипа. Исходя из этого наше устройство будет состоять из двух глобальных частей: часть относящаяся к датчику SLAVEABLOCK, и часть относящаяся к ЭВМ MASTERABLOCK. Первый блок будет состоять из преобразующего чипа «555», который преобразовывает аналоговый электрический сигнал в прямоугольный импульсный сигнал. Далее сигнал поступает на вход NCSLAVEA, где производится подсчет количества импульсов в определенный промежуток времени, т.о. частота импульсов соответствует скорости ветра. После подсчета данные вместе с номером нейрочипа (каждый чип имеет свой индивидуальный номер, который зашивается в нем при производстве) попадают в устройство сопряжения NC с линией передачи. Затем через линию связи, в нашем случае это RS232C, преобразовавшись снова в устройстве сопряжения информация поступает в NCMASTERA, в котором она обрабатывается и если скорость ветра содержащаяся в данном пакете информации превышает допустимый порог в 50м/с, то пакет дополняется данными ( время получения пакета нейрочипом MASTERA : часы, минуты), и снова через устройство сопряжения передается в центральную ЭВМ по линии связи RS232C. Т.о. в ЭВМ будет получен пакет содержащий данные о скорости ветра, местоположении датчика ( которое будет определено по номеру нейрочипа), и времени получения данной информации. Обновление информации происходит каждые 100мкС ( причем данный параметр является установочным, т.е. его можно изменить при перепрограммировании нейрочипа MASTERA.
В нашем случае используется линия передачи RS232C, это не самый лучший, но самый простой вариант реализации передачи данных между датчиком и ЭВМ. Интерфейс RS232C накладывает серьезные ограничения на расстояния между датчиком и центральной ЭВМ. Оно не может превышать 300 м, т.к. расстояние между SLAVEABLOCK и MASTERABLOCK может составлять порядка 150м и расстояние между MASTERABLOCK и центральной ЭВМ может составлять 150м, в сумме 300м. Как было сказано выше это не самый лучший вариант, т.к. взлетное поле большого аэродрома может тянуться на 15-20км, то передачу информации нужно будет производить с помощью повторителей. Но используя трансиверы MC145407 возможно сопряжение не только с RS232C, но и другими интерфейсами RS…, т.к. возможна передача за счет инфракрасного излучения и радио сигналов. Все эти методы передачи данных позволяют значительно увеличить расстояния между датчиками и центральной ЭВМ, но они являются более дорогостоящими и могут внести помехи в работу бортовых радиолокационных станций самолетов и РЛС терминала аэропорта. Поэтому в нашем случае целесообразно использовать интерфейсы типа RS.
1.3. Описание алгоритма.
Описанная выше структура передачи сигнала ведет к формированию определенного алгоритма работы программы. Исходя из данной структуры программа была разбита на две части:
1-ая часть является счетчиком которая считает количество импульсов подаваемых на 5 вход микросхемы NCSLAVEA. Это производится путем подсчета чередования нулей и единиц на данном входе за определенный промежуток времени.
2-ая часть является анализатором, т.е. анализируется поступающая информация с большого количества датчиков (+нейрочип). Данные считываются каждые 100мкС. Если доходя до условия превышения порога в 50 импульсов, что соответствует скорости ветра в 50м/с, эти данные выделяются и после дополнения к ним времени передаются в линию передачи RS232C.
Есть так же дополнительная часть для программирования NC в SLAVEAmode. Т.е. для того, чтобы не было нарушений в работе нейрочипов необходимо определить приоритеты в их работе, т.е. SLAVEA имеет приоритет ниже, чем
Выводы.
Таким образом мы имеем конкретную задачу и способ ее решения. В главе 2 будет рассмотрена ее реализация на языке NEURONC.
2. Разработка программы.
2.1. Структура программы с описанием
При анализе устройства была выбрана такая структура при которой схема была разделена на две части программирование которых ведется отдельно через выводы CP0…CP4 каждого из нейрочипов, данная структура позволила не только уменьшить размер программ для программирования нейрочипов, но и упростить сам непосредственный процесс программирования и уменьшить затрат времени на тестирование чипа и объема его ПЗУ. Для этого вся программа была разбита на отдельные модули, каждый из которых определяет свою область работы, первая выполняет стандартную загрузку нейрочипа в SLAVEAmode, вторая загружается в данный чип и выполняет пересчет импульсов поступающих на его вход и передачу данных в интерфейс RS485 и третья часть(основная) выполняет обработку сигнала поступающего со всех нейрочипов типа SLAVEA включенных в LonWorks протокол .
1-ая часть стандартным методом переводит нейрочип в SLAVEAmode. Это необходимо для уменьшения уровня его приоритета, чтобы информация поступающая со всех нейрочипов данного вида не вступала в конфликт при выходе из интефейса RS 485, т.к. это приведет к ошибкам при пересылке данных и неправильной работе обрабатывающего нейрочипа.
2-ая часть является счетчиком которая считает количество импульсов подаваемых на 5 вход микросхемы NCSLAVEA. Это производится путем подсчета чередования нулей и единиц на данном входе за определенный промежуток времени.
3-ая часть является анализатором, т.е. анализируется поступающая информация с большого количества датчиков (+нейрочип). Данные считываются каждые 100мкС. Если доходя до условия превышения порога в 50 импульсов, что соответствует скорости ветра в 50м/с, эти данные выделяются и после дополнения к ним времени передаются в линию передачи RS232C.
2.2. Структура модулей.
1-ый модуль состоит из процедуры стандартных команд в ходящих в пакет поставки нейрочипа фирмы Motorola.
2-ой модуль состоит из процедуры pragmaenable_io_pull-ups которая является счетчиком по входу 5 через каждые 100мкС данные выводятся в линию связи.
3-ый модуль состоит из следующих процедур :
а) pragma scheduler_reset // процедурасброса
б) pragmaenable_io_pull-ups // процедура подчета импульсов (описана выше)
в) pragmanum_addr_table_entries 1 //процедура добавления временных данных к уже имеющимся
г) pragmaone_domain // главная процедура ( объединение всех остальных)
д) pragma app_buf_out_priority_count 0 // процедураобнулениябуфера
е) pragma net_buf_out_priority_count 0 // процедураобнулениясчетчика
.
2.3. Описание интерфейса
2.3.1. Человеко–машинный интерфейс
Человеко-машинный интерфейс можно считать «историей, не имеющей конца». Это – модель, которая будет совершенствоваться вместе с ростом знаний человека о своем собственном поведении, восприимчивости и ответных реакциях. Fieldbus –система- это система датчиков и исполнительных механизмов. Для того чтобы люди, обслуживающие устройства, машины и т.д., могли быстрее, лучше, эффективнее работать с ними, придется «прощупать многие каналы». В будущем интерфейсе человек-машина основные задачи возьмут на себя, наряду с клавиатурой и возможными камерами, микрофоны, датчики вкуса, запаха и температуры, молниеносно реагирующие на любые действия человека.
2.3.2. Обработка ошибок
Обработка ошибок происходит посредствам внутренней защиты NC. Перепады напряжения определяются блоком MC33164, который приостанавливает работу NC. Запуск происходит через интервал установленный
Выводы
Таким образом мы имеем готовые программы на языке NEURONC. В следующей главе будут описаны результаты тестирования и работы программы.
3. Результативная часть
3.1. Тестирование программы.
3.1.1. Выбор методики тестирования.
Выбор методики тестирования сложная задача, которая ставится перед программистом и может повлиять на дальнейшее развитие программного продукта, его усовершенствование. Цель тестирования выявить ошибки программы еще на начальном этапе, до его распространения. Для этого были разработаны специальные методы тестирования : восходящее и нисходящее тестирование, V –тестирование, тестирование по принципу черного и белого ящика.
Каждый из данных методов имеет свою специфику и направлен на устранение определенных видов ошибок, но каждый метод отличается по принципу своей реализации. Так, например, V-тестирование проводится с редактированием программы, так как в данном тестировании блокируются определенные блоки программы , а остальные тестируются. В методе тестирования по принципу черного или белого ящика программа не претерпевает ни каких изменений, но возможно, что это тестирование может привести к зависанию компьютера или другим сбоям в системе, т.к. принцип действия этого метода заключается в максимальной загрузке программы, заполнения всех полей, ввод неверных данных не зная, что и куда попадет , как бы в темноте ( черный ящик) или открыто (белый ящик). Восходящее и нисходящее тестирование очень похоже на V-тестирование, только в отличии от него выбирается конкретное направление тестирования, от большого ( основного блока к меньшим ( процедуры, функции) или наоборот, от меньших к большим . При этом одни блоки заменяются заглушками, а другие тестируются. В нашем случае провести какой-то из данных методов возможно только по отношению к программе, для тестирования же устройства необходимо тестировать его производительность или имитировать данное устройство.
3.1.2. Описание методики тестирования.
Для проведения анализа производительности систем, еще не реализованных в виде конкретных устройств, решающее значение имеет метод имитации. Под имитацией понимается создание модели, воспроизводящей работу Fieldbus-системы, анализ которой производятся с учетом реальных событий, но в отрыве от реального масштаба времени. Имитация имеет ряд преимуществ: гибкое изменение параметров, влияющих на работу системы, возможность проиграть наихудший вариант и т.д.
Произведя примерную имитацию выполнения данным устройством своих функций были сделаны следующие выводы:
1) Программы выполняет заданный минимум функций.
2) Программы обладает рядом добавочных функций, облегчающих работу с ней.
3) Программа легко модифицируется.
4) Программа полностью защищена от ошибок связанных с непрофессионализмом пользователя.
5) Программа не защищена от ошибок системы и сознательных действий противоречащих цели программы.
6) Устройство выполняет необходимые функции
3.1.3. Результаты.
В результате тестирования(имитации) программы и устройства были получены необходимые данные, не было выявлено никаких ошибок выходящих за рамки ограничения на программу.
3.2. Ограничение на разработку.
Данное программное обеспечение будет работать только на микросхемах указанных выше. Напряжение питания необходимо подавать раздельно на оба блока схемы.
1) Шина земля должна быть раздельной, во избежания помех.
2) напряжение питания : +(5-12)В
3) место размещения : объемом 30х20х7 (см3 )
4) вибрационная устойчивость
3.3. Инструкция пользователю.
При использовании данного устройства необходимо соблюдать условия определенные в пункте 3.2 . Кроме указанных требований необходимо соблюдать меры предосторожности при подключении устройства к питанию, т.к. неправильное подключение приведет к выходу из строя нейрочипов. Программирование нейрочипов проводить через выводы CP0…CP4 указанные на схеме. При необходимости можно разработать интерфейсную программу которая простым опрашиванием COM-порта будет выдавать данные о скорости ветра в том или ином месте аэродрома с указанием времени поступления данных.
Выводы
Теперь видно, что реализованное устройство выполняет поставленную задачу и не содержит ошибок, что позволяет без опасений работать с программой и устройством.
Заключение.
В результате проведенной работы была организована структурная схема распределенных датчиков для измерения скорости ветра. Из данной схемы и определения производительности полученной имитируемой системы были сделаны выводы о пригодности нейрочипов для данной области их использования. В результате использование датчиков на основе нейрочипов на небольших аэродромах не имеет под собой экономической основы, т.к. стоимость нейрочипа значительно больше имеющихся на данный момент аналогов, а производительность их при небольшом количестве не значительно выше других процессоров. Поэтому данное устройство нужно использовать при большом количестве датчиков, больше нескольких тысяч, тогда производительность датчиков с нейрочипами и приемо-передающих устройств на их основе значительно выше, чем при том же количестве датчиков с использованием других процессоров. Отсюда видны следующие преимущества и недостатки данного метода.
Преимущества:
· не большая стоимость компонентов для реализации отдельного прикладного узла,
- очень простая конфигурация узла нижнего уровня,
- большая номенклатура устройств и приборов, выпускаемых промышленно в странах ЕЭС и США и имеющих встроенные узлы LONWORKS для работы в составе сетей ECHELON (большая распространенность стандарта в мире),
- большое количество готовых процедур по адаптации типовой периферии в стандартной библиотеке NEURON,
- простота разработки прикладного программного обеспечения узлов.
Недостатки:
· чрезвычайно большая стоимость, хотя и весьма эффективных и удобных, отладочных средств,
- отсутствие узлов WDT, узла автоматического сброса при включении питания (требует использования внешнего супервизора) и возможности работы в “спящем режиме” у микроконтроллеров NEURON,
- крайне слабая поддержка данного стандарта дилерскими фирмами в России.
Программа полностью соответствует техническому заданию и выполняет поставленное задание.
Из-за большой стоимости пакета разработки, компиляции и компановки программ написанных на NEURONC проверить работоспособность программы является невозможным, поэтому приходится довольствоваться лишь примерным теоретическим результатам и результатам имитационного и математического моделирования.
Хотя на данный момент нейрочипы являются дорогостоящим продуктом, но
за ним будущее, т.к. в наше время главным фактором является скорость, а скорость нейрочипа пока не видит ограничений.
Список литературы.
1. Дитрих-Лой-Швайнцер. «LON -технология».ПГТУ .395с. 1999
2. Журнал «Радио и связь» №4 1999г.
3. Войкова А.П. «Нейронные сети и нейрочипы», Москва, 280с., 2000г.
8. Приложения.
8.1. Текст программы.
8.1.1 Подготовка нейрон чипов
************************************************************************
* Эта программа на NeuronCустанавливаетNeuronChip в slaveA
* mode.
************************************************************************
IO_0 parallel slave s_bus;
#defineDATA_SIZE 255 //максимально разрешенное поле данных
struct parallel_io_interface
{
unsigned int length; //length of data field
unsigned int data[DATA_SIZE];
}piofc
when (io_in_ready(s_bus))1 //готовность приема информации
{
piofc.length = DATA_SIZE; //максимальное число в байтах
to read
io_in(s_bus,&piofc); //получить 10 байт
incoming data
}
when (io_out_ready(s_bus)) //готовность передать 10 байт
{
piofc.length = 10; //кол-во байт
io_out(s_bus,&piofc); //передать 10 байт из буфера
}
when (...) //условие по которому будет отправлено сообщение о заполнении буфера
{
io_out_request(s_bus); } request
8.1.2. Программа обработки
************************************************************************
* Эта программа на NeuronCзадаетNeuronChip в slaveA
* подсчет импульсов поступающих с нейрочипа.
************************************************************************
#pragma enable_io_pullups
////////////////////Параматры для подсчета (определяются пользователем)////////////
#definelower_limit 0 //нижний предел подсчета
#defineupper_limit 100 //верхний предел подсчета
#defineshaft_direction 1 //направление счета (т.е.,
0=лево,1=право)
/////////////////// Программа //////////////////////
IO_5 input pulsecount analog_input;
IO_5 input quadrature shaft_encoder; //импульсыпоступаютна 5 входнейрочипа
signed long count;
signed long increment;
when (io_update_occurs(shaft_encoder){
if (shaft_direction) count += input_value;
elsecount -= input_value; //вывод полученных данных
/////////////////// Проверка//////////////////////
if (count<lower_limit) count=lower_limit;
if (count>upper_limit) count=upper_limit; //Проверкапереполненияoverflow
}
when (reset)// Сброс
{
count = 0;
}
************************************************************************
* Эта программа на NeuronCзадаетNeuronChip в masterA
* принимает информацию со всех нейрочипов типа slaveA и в случае превышения порогового уровня в 50 импульсов, что * соответствует ветру 50м/с передает информацию в центральную ЭВМ с указанием номера того датчика с которого поступила * данная информация и времени ее поступления
************************************************************************
#pragma scheduler_reset // процедурасброса
#pragmaenable_io_pull-ups // процедура подчета импульсов (описана выше)
#pragma num_addr_table_entries 1
#pragma one_domain
#pragma app_buf_out_priority_count 0
#pragma net_buf_out_priority_count 0
#definetimerl 100 // таймер производит опрос по входам на наличие информации каждые 100мкС
#definemax_char_from_PC 30 //максимально разрешенное кол-во символов принимаемых нейрочипом
#defineporog 50 //установочный порог
{
unsignedintspeed; //данные о скорости
unsignedintnumber; // данные о номере датчика
};
#definemax_packet_size 60 // максимально разрешенный пакет отсылаемый в ЭВМ
{
unsignedintspeed; //данные о скорости
unsignedintminutes; //время принятия сообщения
unsigned int hours;
unsigned int number // номердатчика
};
/******************************** Дополнительные файлы ************************************/
#include <control.h>
/********************************* Определение I/O ****************************************/
IO_5 output bit RTS;
IO_2 output bit СTS;
IO_4 output serial baud(4800) RXD; // read data from PC
IO_10 output serial baud(4800) TXD; // send data to PC
IO_8 input bit R/W;
IO_5 input bit CS;
IO_9 input bit HS;
/****************************** Сетевыеданные *************************************/
network input struct temp_time pctobc_speed_in; // speed
network input struct temp_time pctobc_number_in; // number
network input struct time NV_time_in; // BC time
network input boolean NVfan_state_in // TRUE: fan is flashing
network input boolean NVcomp_state_in; // TRUE: compressor is on
network output struct temp_time bind_info(unackd) NV_timesetpt_out;
//************************************ Глобальные ***************************************/
char input_but[max_packet_size]; // пакетотсылаемыйвЭВМ
char input_buf1[max_char_from_PC]; // Input from PC (1st time)
char input_buf2[max_char_from_PC]; // Input from PC (2nd time)
char * buf_ptr; // указатель в буфере
boolean packet_found = FALSE; // пакетненайден.
boolean compress_state = FALSE; // датчикнеисправен
intlast_num_chars; // количество принятых символов
int speed;
char out_char[1];
struct bcd digits; // holds BCD data to be sent to PC
// digits.d1 most significant nibble in ms byte
// digits.d2 least significant nibble in ms byte
// digits.d3 most significant nibble
// digits.d4 least significant nibble
// digits.d5 most significant nibble in ls byte
// digits.d6 least significant nibble in ls byte
struct { // data from bc
unsigned int speed;
unsigned int number;
} bc_data;
struct speed_time bc_number;
/************************************ Timers ******************************************/
mtimer repeating check_CTS;
mtimer repeating get_data_from_bc; // every 100 ms poll bc
// then send to PC
/*********************************** Functions ****************************************/
boolean append_packet( )
description: assert CTS, append data to input_buf[ ] if any
and return append_packet = TRUE if 1st char. = ‘D’
and last char. is a CR.
{
boolean packet;
int i;
int num_chars1;
int num_chars2;
packet = FALSE;
num_chars1 = 0;
num_chars2 = 0;
io_out( CTS, 0 ); // enable cts
num_chars1 = io_in( RXD, input_buf1, max_char_from_PC );
io_out( CTS, 1 ); // disable cts
when (io_puls_up io_5 > porog )
{
num_chars2 = io_in( RXD, input_buf2, max_char_from_PC );
// append data over to where final packet goes
if ( num_chars1 != 0 )
{ // if data append it to input_buf
for ( i = last_num_chars; i < last_num_chars + num_chars1; i++ )
{
input_buf[i] = input_buf1[ i - last_num_chars ]; // append
}
last_num_chars = last_num_chars + num_chars1;
}
if ( num_chars2 != 0 )
{ // if data append it to input_buf
for ( i = last_num_chars; i < last_num_chars + num_chars2; i++ )
{
input_buf[i] = input_buf2[ i - last_num_chars ]; // append
}
last_num_chars = last_num_chars + num_chars2;
}
if ( last_num_chars > 0 ) { // something there
if ( input_buf[0] != ‘D’ )
{ // A packet is started and packet is invalid
last_num_chars = 0; // reset count of total characters read
packet = FALSE;
}
else if ( input_buf[ last_num_chars - 1 ] == ‘/r’ ) {
// 1st char. a ‘D’ and last char. a carriage return
packet = TRUE;
}
} // something there
return( packet );
}
// This function converts a hex character to 2 ASCII characters
// and sends the characters to out the TXC port to the PC
//
void putch_hex(unsigned int hex_char)
{
out_char[0] = ( hex_char >> 4 ) & 0x0f; // keep lower nibble
if( out_char > 9 )
out_char[0] += 0x37;
else
out_char[0] += 0x30;
io_out( TXD, out_char, 1 ); // output 1 char. out the 232 port to the PC
out_char[0] = hex_char & 0x0f;
if(out_char > 9)
out_char[0] += 0x37;
else
out_char[0] += 0x30;
io_out( TXD, out_char, 1 ); // output 1 char. out the 232 port to the PC
}
//
// This function converts two ascii characters to a decimal digit
//
unsigned char to_dec(unsigned char msb,unsigned char lsb)
{
return( (msb - 48) * 10 + (lsb - 48) );
}
/************************************* Reset *****************************************
when (reset) {
bc_data.hours = 0;
bc_data.minutes = 0;
bc_data.speed = 0;
bc_data.number = 0;
check_CTS = timer1; // repeating timer when to assert CTS
// to check for PC data
get_data_from_bc = 100; // every 100 ms poll bc and then send to PC
when (io_puls_up io_5 >50 )
{
when ( timer_expires(check_CTS) { // go get next character(s)
packet_found = append_packet( ); // append more data if any
// to input_buf[].
// also returns true if
// when finds what looks like a good packet.
check_CTS = timer1;
}
when ( packet_found ) { // process packet
// packet format: <D><command><data>
switch( input_buf[1] ) { // select from type of packet byte
case ‘1’:// set time <D><1><xxxx><CR>
if ( last_num_chars == 7 ) {
NV_timesetpt_out.temp = 255; // code for do not use
// convert ASCII HHMM in input_buf[2-5] to unsigned int.
bc_data.hours = NV_timesetpt_out.hours =
to_dec(input_buf[2], input_buf[3]);
bc_data.minutes = NV_timesetpt_out.minutes =
to_dec(input_buf[4], input_buf[5]);
}
break;
case ‘2’: // set number <D><2><xx><CR>
if ( last_num_chars == 5 ) {
// convert ASCII set point in input_buf[2-3] to unsigned int.
bc_data.number = NV_timesetpt_out.speed =
to_dec(input_buf[2], input_buf[3]);
NV_timesetpt_out.hours = 255; // code for do not use
NV_timesetpt_out.minutes = 255; // code for do not use
}
break;
default: // bad packet
break;
}
packet_found = FALSE; // finished last packet
last_num_chars = 0; // reset # of bytes collected in packet
for ( temp = 0; temp < max_packet_size; temp++ ) { // not needed but helps in d
input_buf[temp] = 0;
}
}
when ( nv_update_fails ) {
}
when ( nv_update_occurs(NV_time_in) ) { // BC to PC time (HHMM)
bc_data.hours = NV_time_in.hours; // HH time
bc_data.minutes = NV_time_in.minutes; // MM time
}
when ( nv_update_occurs(pctobc_temp_in) ) { // BC to PC speed
bc_data.speed = pctobc_temp_in.temp; // BC speed
}
when ( nv_update_occurs(pctobc_setpt_in) ) { // BC to PC number
bc_data.setpoint = pctobc_setpt_in.temp; // BC number
}
when ( nv_update_occurs(NVcomp_state_in) ) {
if (NVcomp_state_in == TRUE) {
compress_state = TRUE;
}
else {
compress_state = FALSE;
}
}
when ( nv_update_occurs(NVfan_state_in) ) {
if (NVfan_state_in == TRUE;
fan_state = TRUE;
}
else {
fan_state = FALSE;
}
}
when ( nv_update_fails(NVcomp_state_in) ) { // datchik not responding
compress_state = FALSE; // assume off
}
when( timer_expires(get_data_from_bc) ) {
// every 100 ms send data to PC and poll fan and compressor for status
poll(NVcomp_state_in); // compressor state
get_data_from_bc = 100; // 100 ms repetitive timer
// packet consists of: <start><time><temperature><setpt><compressor><fan><CR>
out_char[0] = ‘B’; // Beginning of packet character
io_out(TXD, out_char, 1); // send out 232 port
// output time (hours only)
bin2bcd( (long) bc_data.hours, &digits);
out_char[0] = digits.d5 + 0x30; // high time BCD digit converted to ASCII
io_out( TXD, out_char, 1);
out_char[0] = digits.d6 + 0x30; // low time BCD digit converted to ASCII
io_out( TXD, out_char, 1);
// output time (minutes only)
bin2bcd( (long) bc_data.minutes, &digits);
out_char[0] = digits.d5 + 0x30; // high time BDC digit converted to ASCII
io_out( TXD, out_char, 1);
out_char[0] = digits.d6 + 0x30; // low time BCD digit converted to ASCII
io_out( TXD, out_char, 1);
// output time (speed)
bin2bcd( (long) bc_data.speed, &digits);
out_char[0] = digits.d5 + 0x30; // high speed. BCD digit converted to ASCII
io_out( TXD, out_char, 1);
out_char[0] = digits.d5 + 0x30; // low speed. BCD digit converted to ASCII
io_out( TXD, out_char, 1);
// output time (number)
bin2bcd( (long) bc_data.number, &digits);
out_char[0] = digits.d5 + 0x30; // high stpt BCD digit converted to ASCII
io_out( TXD, out_char, 1);
out_char[0] = digits.d6 + 0x30; // low stpt BCD digit converted to ASCII
io_out( TXD, out_char, 1);
// output datchik on/off
if ( compress_state == TRUE ) { // datchik is on
// (i.e. LEDs scrolling)
io_out(TXD, “1”, 1); // output to PC datchik is on
}
else {// datchik is off (i.e. LEDs not flashing)
io_out(TXD, “0”, 1); // output to PC datchik is off
}
// a <CR> ends the packet
io_out(TXD, “\r”, 1); // <CR>
}
Министерство общего и специального образования РФ
Московский Энергетический Институт
(Технический Университет)
Филиал в городе Смоленске
Кафедра вычислительной техники
Техническое задание
к курсовой работе по дисциплине
"Сети ЭВМ и средства коммуникации"
на тему
“Сеть на основе нейрочипа”
гр. ВМ1-97 студент: Вальков К.Г. преподаватели: Аверченков О.Е. |
г. Смоленск 2000 г.
1. Область применения.
Данное устройство и программное обеспечение может и использоваться на аэродромах большой площади с разветвленной сетью датчиков для определения скорости ветра в различных направлениях и областях взлетной полосы. И дальнейшей передачи на центральную ЭВМ.
2. Цель и назначение
Освоить принципы построения сетей с использованием нейрочипов. Изучить структуру и программный язык NEURONC. Определить применима ли данная сеть для различных аэродромов (малой, средней и большой протяженности). Разработать электрическую схему устройства коммуникации датчик - центральная ЭВМ с внутренним устройством обработки.
3. Технические требования.
Требования к аппаратуре: для полноценной работы данного устройства необходимо напряжение питание +(5-12)В. Среда передачи данных : интерфейс RS232C (25 контактный разъем). Отклонение от приведенных в спецификации характеристик элементов ±2%.
Требования к надежности: устройство должно работать в любом положении (вертикальное, горизонтальное ), в любых погодных условиях полноценно выполнять свою задачу и обрабатывать внештатные ситуации, возникающие при работе, связанные с недостаточной квалификацией оператора.
4.Задание
Разработать устройство и программное обеспечение к нему выполняющему следующую функцию : обработка информации поступающей с аэродинамических датчиков (датчики анализа скорости ветра) и передача поступающей информации по сети в ЭВМ, сеть реализовать на основе нейрочипа
11. Оглавление
Аннотация.__________________________________________________________ 2
1. Введение.__________________________________________________________3
1.1. Причины и последствия объединения компьютеров в сеть. ______________3
1.2. Управление техническими процессами ______________________________4
1.2.1. Классический подход _________________________________________ 4
1.2.2. Децентрализованный подход ___________________________________5
1.3. Информационный обмен как основа распределенных систем ___________7
1.3.1. Иерархия систем _____________________________________________7
1.3.2. Семиуровневая модель ISO/OSI ________________________________8
1.4. Топологии _____________________________________________________11
1.5. Инструментарий ________________________________________________15
1.5.1. Основные характеристики микроконтроллеров NEURON Chip _____17
2. Постановка задачи ._______________________________________________ 24
2.1. Обзор литературы и предлагаемых методов решения.________________ 24
2.2. Анализ задачи. ________________________________________________ 25
2.3. Описание алгоритма____________________________________________27
3. Разработка программы_____________________________________________28
3.1. Структура программы с описанием._______________________________28
3.2. Структура модулей._____________________________________________29
3.3.Описание интерфейса.___________________________________________30
3.4.1. Человеко-машинный интерфейс ______________________________30
3.4.2. Обработка ошибок _________________________________________30
4. Результативная часть.______________________________________________31
4.1. Тестирование.___________________________________________________31
4.1.1. Выбор методики тестирования ______________________________31
4.1.2. Описание методики _______________________________________32
4.1.3. Результаты ______________________________________________32
4.2. Ограничения на программу.______________________________________33
4.3. Инструкция пользователю _______________________________________33
Заключение._______________________________________________________34
Список литературы._________________________________________________36
Приложения._______________________________________________________37
1. Документированный текст программы.______________________________38
2.Техническое задание . ____________________________________________ 43
3. Схема принципиальная -электрическая._____________________________П1
Оглавление.________________________________________________________46