| Скачать .docx |
Реферат: Кластерный анализ в портфельном инвестировании
Ульяновский Государственный Технический Университет
Институт авиационных технологий и управления
Кафедра экономики, управления и информатики
Кунец Николай Львович
КЛАСТЕРНЫЙ АНАЛИЗ В ПОРТФЕЛЬНОМ ИНВЕСТИРОВАНИИ
(Курсовая работа)
Специальность: 061100 “Менеджмент”
Предмет: “Инвестирование”
Группа: АМд - 52
Руководитель: Богданова Л.С.
Допущен к, экзамену:
Оценка:
Ульяновск 2003
и ОГЛАВЛЕНИЕ
ВВЕДЕНИЕ………………………………………………………………………..3
1. Понятие кластерного анализа………………………………………………….5
2. Кластерный анализ в портфельном инвестировании………………………...8
3. Алгоритм оптимизации портфеля с применением кластерного анализа….15
4. Кластеризация «голубых фишек» российского фондового рынка………...22
ЗАКЛЮЧЕНИЕ………………………………………………………………….25
СПИСОК ЛИТЕРАТУРЫ……………………………………………………….27
ВВЕДЕНИЕ
Огромное множество инвестиционных инструментов, предоставляемых современным финансовым рынком, заставляет корпоративных инвесторов с каждым днем анализировать все большее количество финансовой информации. Подчас успех инвестирования зависит от объема анализируемых финансовых данных, времени, затраченного на анализ, и вида, в котором представлены результаты. Больше, быстрее, удобнее - вот основные требования, предъявляемые постоянно меняющимся финансовым рынком к методам анализа финансовых данных.
При составлении больших диверсифицированных портфелей необходимо анализировать сотни финансовых инструментов по десяткам показателей за несколько прошлых лет. Это миллионы чисел, между которыми нужно выявить взаимосвязь и которые надо расположить в определенном порядке.
Ситуация на финансовом рынке меняется настолько быстро, что для поддержания оптимального соотношения доходность-риск анализ финансовых активов приходится проводить по несколько раз в день. При этом счет может идти если не на секунды, то на минуты.
Результаты финансового анализа, представленные в виде больших массивов чисел, не сильно упрощают процесс принятия решений. Можно сгруппировать результаты в таком виде, чтобы процесс принятия решений стал более эффективным. Можно визуализировать данные и результаты анализа так, чтобы аналитик разом мог охватить их взглядом.
Процедура кластеризации решает вопрос о сходстве финансовых активов, характеризуемых значениями многих параметров, на основе формальных математических критериев. Это позволяет заменить длительный и трудоемкий процесс изучения и сравнения активов более быстрым вычислительным алгоритмом. Кроме того, будучи средством анализа многомерных данных, кластеризация позволяет выделить активы с близкими значениями всех параметров.
Объектом исследования данной курсовой работы являются РАО ЕЭС (EESR), Мосэнерго (MSNG), Сургутнефтегаз (SNGS), Газпром (GSPBEX) и Татнефть (TATN), Сибнефть (SIBN) и Ростелеком (RTKM), а предметом исследования определение наиболее ликвидных акций российского рынка.
Целью данной курсовой является исследование акций российского рынка.
Для достижения цели в работе решаются следующие задачи: анализ акций и выбор наиболее надёжного кластера.
Для решения поставленных задач в работе используются следующие методы: аналитические, графические, сравнительные.
1. Понятие кластерного анализа
При анализе и прогнозировании социально-экономических явлений исследователь довольно часто сталкивается с многомерностью их описания. Это происходит при решении задачи сегментирования рынка, построении типологии стран по достаточно большому числу показателей, прогнозирования конъюнктуры рынка отдельных товаров, изучении и прогнозировании экономической депрессии и многих других проблем.
Первое применение кластерный анализ нашел в социологии. Название кластерный анализ происходит от английского слова cluster – гроздь, скопление. Впервые в 1939 был определен предмет кластерного анализа и сделано его описание исследователем Трионом. Главное назначение кластерного анализа – разбиение множества исследуемых объектов и признаков на однородные в соответствующем понимании группы или кластеры. Это означает, что решается задача классификации данных и выявления соответствующей структуры в ней. Методы кластерного анализа можно применять в самых различных случаях, даже в тех случаях, когда речь идет о простой группировке, в которой все сводится к образованию групп по количественному сходству.
Большое достоинство кластерного анализа в том, что он позволяет производить разбиение объектов не по одному параметру, а по целому набору признаков. Кроме того, кластерный анализ в отличие от большинства математико-статистических методов не накладывает никаких ограничений на вид рассматриваемых объектов, и позволяет рассматривать множество исходных данных практически произвольной природы. Это имеет большое значение, например, для прогнозирования конъюнктуры, когда показатели имеют разнообразный вид, затрудняющий применение традиционных эконометрических подходов.
Кластерный анализ позволяет рассматривать достаточно большой объем информации и резко сокращать, сжимать большие массивы социально-экономической информации, делать их компактными и наглядными.
Важное значение кластерный анализ имеет применительно к совокупностям временных рядов, характеризующих экономическое развитие (например, общехозяйственной и товарной конъюнктуры). Здесь можно выделять периоды, когда значения соответствующих показателей были достаточно близкими, а также определять группы временных рядов, динамика которых наиболее схожа.
Кластерный анализ можно использовать циклически. В этом случае исследование производится до тех пор, пока не будут достигнуты необходимые результаты. При этом каждый цикл здесь может давать информацию, которая способна сильно изменить направленность и подходы дальнейшего применения кластерного анализа. Этот процесс можно представить системой с обратной связью.
В задачах социально-экономического прогнозирования весьма перспективно сочетание кластерного анализа с другими количественными методами (например, с регрессионным анализом).
Вывод: как и любой другой метод, кластерный анализ имеет определенные недостатки и ограничения: В частности, состав и количество кластеров зависит от выбираемых критериев разбиения. При сведении исходного массива данных к более компактному виду могут возникать определенные искажения, а также могут теряться индивидуальные черты отдельных объектов за счет замены их характеристиками обобщенных значений параметров кластера. При проведении классификации объектов игнорируется очень часто возможность отсутствия в рассматриваемой совокупности каких-либо значений кластеров.
В кластерном анализе считается, что:
а) выбранные характеристики допускают в принципе желательное разбиение на кластеры;
б) единицы измерения (масштаб) выбраны правильно.
Выбор масштаба играет большую роль. Как правило, данные нормализуют вычитанием среднего и делением на стандартное отклонение, так что дисперсия оказывается равной единице.
2. Кластерный анализ в портфельном инвестировании
Общеизвестно, что изменение курсовой стоимости и дивидендов различных ценных бумаг не только в России, но и во всем мире зависит от ряда внутренних и международных факторов экономического и неэкономического характера. Эти факторы могут быть взаимосвязаны в различной степени, а тенденции изменения их динамики способны отличаться друг от друга в достаточно сильной степени. Следовательно, изменение стоимости инвестиционного портфеля в результате сложения различных тенденций с большой вероятностью оказывается достаточно сложной и практически непредсказуемой, если использовать обычный регрессионный анализ. Основные факторы воздействия влияют на различные ценные бумаги не только с разной эффективностью, но зачастую и в прямо противоположных направлениях. К примеру, повышение цен на нефть может благоприятно сказаться на ценных бумагах нефтяных корпораций, негативно отразившись на автомобилестроительном секторе.
В свете вышесказанного, перед инвесторами возникают следующие проблемы:
1) Определение с максимальной степенью точности существенных факторов и их влияние на курс ценных бумаг;
2) Составление научно-обоснованного прогноза динамики поведения этих ценных бумаг, основываясь на изучении данных факторов;
3) Составление на основе полученных сведений о фондовом рынке оптимального инвестиционного портфеля, позволяющего максимизировать прибыль от вложений при заданной степени риска.
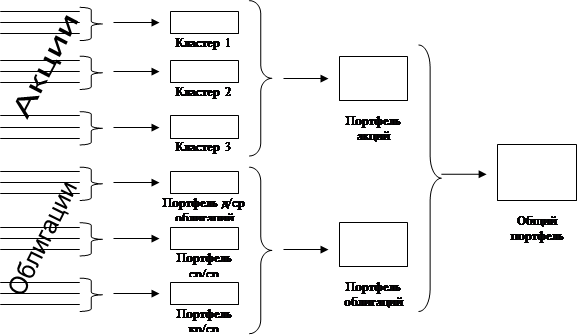 Рис.1 Группировка ценных бумаг со сходными тенденциями
Рис.1 Группировка ценных бумаг со сходными тенденциями
Как теоретики, так и практики, занимающиеся оптимизацией портфеля ценных бумаг, регулярно сталкиваются с трудностями, когда перед ними возникает практически неизбежная задача разбиения множества существующих ценных бумаг на различные группы с относительно однородной структурой. Краеугольным камнем проблемы является вопрос подбора и согласования выбранных факторов так, чтобы их представление в многомерной системе координат достаточно точно производило разбиение на кластеры, характеризующиеся максимально схожими тенденциями. При этом нужно учитывать, что даже если бы и удалось подобрать точные коэффициенты для существующих количественных факторов, всегда найдутся не менее важные качественные показатели, выразить которые в количественной форме практически невозможно. В связи с этим принято группирование ценных бумаг на основе существующих индустриальных и прочих классификаций, а также отталкиваясь от априорной доходности (ex ante).
Разбиение множества ценных бумаг на отдельные кластеры в зависимости от динамики доходности осуществляется следующим образом: данные по доходности ценных бумаг на протяжении базы прогноза компонуются в общую матрицу вида:
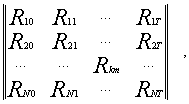 [1,стр.143]
[1,стр.143]
где Rkm – доходность по k -й ценной бумаге за m -й период,
![]()
Далее, разбиение на кластеры происходит через вычисление евклидова расстояния между ценными бумагами p и q по формуле
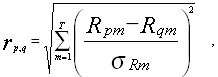 [1,стр.144]
[1,стр.144]
где m – номер периода,
s Rm – среднеквадратическое отклонение доходности за период m .
Критическая величина разбиения предполагается равной квадратному корню из количества периодов T , то есть средней величине евклидового расстояния:
![]() [1,стр.144]
[1,стр.144]
Преимущество данной методики заключается, во-первых, в том, что она позволяет с крайне высокой степенью точности группировать ценные бумаги со сходными тенденциями в изменении доходности на протяжении всего периода, определяющего базу прогноза, что дает основания рассчитывать на сохранение подобной тенденции и в дальнейшем.
Вторым ее преимуществом является возможность полной автоматизации, что значительно облегчает работу, позволяя использовать современные вычислительные средства, а также обрабатывать однородную информацию, получаемую из электронных баз данных. Поэтому она может быть без особых затруднений внедрена не только в компьютерных системах отдельных фирм, занимающихся инвестированием, но также и на соответствующих ресурсах сети интернет.
Пожалуй, наиболее острой проблемой, возникающей перед специалистами по факторному анализу, является подбор четких и ясных критериев, позволяющих отсеять малозначимые факторы, повышающие размерность модели без увеличения ее точности, и при этом правильно определить вес для остальных факторов. Доказательством важности этого вопроса, а также отсутствия однозначно оптимальных решений, является изобилие всевозможных критериев отбора значимых компонент. Достаточно назвать такие известные методы, как расчет варимакс-критерия, n-критерий, отбор при помощи t-критерия Стьюдента и т.п.
Очевидно, что вводить в модель очередной фактор целесообразно только в том случае, если он в достаточной степени понижает уровень энтропии, а, следовательно, увеличивает значение R -квадрат. Каким образом численно выразить прирост данной величины в зависимости от количества вводимых факторов? Рассмотрим эту проблему в свете коэффициентов последовательной детерминации.
Пусть имеются N факторов X1 ...XN , предположительно влияющих на доходность инвестиционного портфеля. При вводе в уравнение регрессии фактора Xi показатель R -квадрат принимает некоторое определенное значение. Выберем фактор, при котором оно будет наибольшим:
![]() [1,стр.145]
[1,стр.145]
где P1 2 - коэффициент последовательной детерминации для данного фактора,
ryx1 - парный коэффициент корреляции между доходностью и этим фактором.
Теперь вводится в полученное уравнение регрессии второй фактор таким образом, чтобы значение R-квадрат снова оказалось максимально возможным, и затем рассчитываем второй коэффициент последовательной детерминации:
![]() [1,стр.147]
[1,стр.147]
Аналогичным образом рассчитываем следующие коэффициенты:
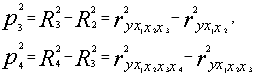 и т.д. [1,стр.147]
и т.д. [1,стр.147]
Базовый отбор факторов продолжается до тех пор, пока величина получаемых коэффициентов последовательной детерминации не станет меньше некоторого критического значения. Учитывая, что в механизм расчета скорректированной величины R-квадрат входит поправка на возрастание энтропии при вводе новых факторов, ее прирост на каждой итерации алгоритма должен быть положительным и, следовательно, критическое значение p должно быть больше нуля.
Данный метод позволяет отобрать из всех имеющихся факторов именно те, которые оказывают наибольшее влияние на доходность рассматриваемых ценных бумаг. Это позволяет существенно понизить размерность модели, создаваемой на основе методики, ускорить вычисления и при этом отбросить данные, не имеющие большого влияния на интересующие нас показатели. Как правило, от выявленных главных компонент зависит не менее 85% общей дисперсии, что лишний раз показывает эффективность выбранного метода анализа.
Теперь, когда определены методы отбора факторов и технология разбиения множества ценных бумаг на отдельные кластеры, можно приступать непосредственно к построению методики оптимизации инвестиционного портфеля. Учитывая, что в настоящее время внедрение любой экономической методики немыслимо без автоматизации, существует алгоритм, по которому надлежит производить операции для получения искомого результата: оптимизированного набора ценных бумаг, позволяющих получить максимальную прибыль при заданном уровне риска.
На первом этапе определяются исходные массивы данных, которые подлежат математической обработке.
В начале имеются следующими исходными данными: S1 , S2 , ..., SN – рассматриваемое множество ценных бумаг;
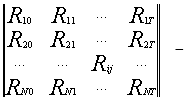 [1,стр.149]
[1,стр.149]
матрица доходности ценных бумаг S1 -SN за периоды [0 ; T ],
где Rij – доходность по ценной бумаге i за j -й период;
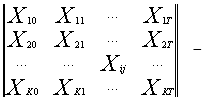 [1,стр.151]
[1,стр.151]
матрица факторов X1 -XK за периоды [0 ; T ],
где Xij – значение фактора Xi за j -й период;
s п – оценка риска предполагаемого портфеля ценных бумаг.
Теперь необходимо определить доли m1 , ..., mN имеющихся в инвестиционном портфеле ценных бумаг с целью максимизации доходности в следующем периоде при заданном уровне риска:
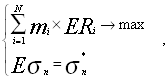 [1,стр.153]
[1,стр.153]
где уровень доходности Ri вычисляется как отношение ожидаемой в отчетный период стоимости ценной бумаги Si к курсовой стоимости в момент формирования портфеля за вычетом единицы.
Так, доходность за месяц в момент времени t =1 вычисляется следующим образом:
![]() [1,стр.155]
[1,стр.155]
В случае, когда инвестор не имеет возможностей продавать ценные бумаги без покрытия, вводится дополнительное условие: my >0 , где y – номер соответствующей ценной бумаги.
Вывод: принято группирование ценных бумаг на основе существующих индустриальных и прочих классификаций.
3. Алгоритм оптимизации портфеля с применением кластерного анализа
Предлагаемый алгоритм можно условно разбить на четыре основные стадии:
1) Разбиение множества ценных бумаг на отдельные кластеры;
2) Определение факторов, влияющих на доходность составляющих каждого кластера. Расчет факторных весов. Построение уравнения регрессии;
3) Прогнозирование динамики выбранных факторов;
4) Вычисление ожидаемой доходности и степени риска для каждой ценной бумаги;
5) Определение оптимального набора ценных бумаг и их долевого веса в инвестиционном портфеле для обеспечения максимизации доходности.
Теперь можно рассмотреть эти стадии подробнее:
1. Разбиение множества ценных бумаг на отдельные кластеры.
Эта стадия начинается с формирования таблицы эвклидовых расстояний между имеющимися ценными бумагами:
Таблица 1 – Таблица эвклидовых расстояний
| Ценные бумаги: | S1 | S2 | …Sj … | SN |
| S1 | - | r1,2 | r1,j | r1,N |
| S2 | - | r2,j | r2,N | |
| …Si … | ri,j | ri,N | ||
| SN | - |
Расстояния вычисляются по формуле
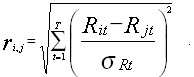 [2,стр.223]
[2,стр.223]
Две ценные бумаги с наименьшим расстоянием объединяются в кластер, доходность которого вычисляется как средняя арифметическая доходностей этих ценных бумаг, после чего процедура расчета повторяется. Процесс объединения в кластеры прекращается, когда минимальное расстояние между группами превысит критическое значение:
![]() [2,стр.224]
[2,стр.224]
В результате описанной процедуры, вместо случайного множества ценных бумаг, мы получаем набор упорядоченных кластеров, объединенных на основе общих тенденций в динамике доходности. При этом достигаются сразу две важные цели: во-первых, значительно сокращается количество переменных, что в заметной степени упрощает вычисления, а во-вторых, уменьшается доля воздействия случайных факторов, которые могут в отдельные моменты коррелировать с доходностью отдельных ценных бумаг. В рамках кластера за счет произведенной диверсификации вероятность случайных совпадений уменьшается во много раз, что дает возможность гораздо более ясно определить факторы, реально воздействующие на доходность.
2. Определение факторов, влияющих на доходность составляющих каждого кластера. Расчет факторных весов. Построение уравнения регрессии.
Для того, чтобы вычислить величину влияния каждого фактора на соответствующий кластер ценных бумаг, представим доходность по кластерам в следующем виде:
![]() [2,стр.231]
[2,стр.231]
где Fi – коэффициент фактора Xi в уравнении множественной регрессии,
Et – ошибка в период времени t . При этом величина T должна значительно (не менее чем в пять раз) превышать количество факторов k .
Значимые факторы отбираются при помощи описанного выше метода с применением коэффициентов последовательной детерминации. Факторы отбираются последовательно, а выбор определяется путем максимизации коэффициента
![]() [2,стр.232]
[2,стр.232]
Процесс добавления факторов продолжается до тех пор, пока максимальный скорректированный коэффициент последовательной детерминации не окажется отрицательной величиной. Для любого выбранного количества факторов коэффициенты F1 , F2 ,...,Fk рассчитываются таким образом, чтобы минимизировать сумму квадратов ошибок регрессии за период базы прогноза:
![]() [2,стр.236]
[2,стр.236]
Этой цели можно достигнуть путем математических преобразований матрицы факторных весов. В настоящее время существует ряд программных пакетов, позволяющих производить данные расчеты с высокой скоростью и за короткое время.
Исследование, проведенное Е.А. Дорофеевым в работе "Влияние колебаний экономических факторов на динамику российского фондового рынка", выявило значительную зависимость курсов акций отечественных компаний от величины ВВП и индекса CPI.
3. Прогнозирование динамики выбранных факторов
Результатом вышеуказанных вычислений является получение формул множественной регрессии для каждого кластера, с помощью которых, опираясь на статистические данные о динамике факторов, можно получить прогноз развития доходности кластеров на последующий период и оценить величину существующего риска. Преимущество прогнозирования факторов по сравнению с прогнозированием курсов отдельных ценных бумаг состоит в наличии значительно большего количества авторитетных исследований по движению макроэкономических факторов, а также статистических сводок органов государственного регулирования.
Четвертый этап будет посвящен переходу от изучения общих кластерных тенденций к расчету индивидуальных уравнений регрессии для каждой из имеющихся ценных бумаг.
4. Вычисление ожидаемой доходности и степени риска для каждой ценной бумаги.
В большинстве моделей, опирающихся на CAPM, для ценных бумаг рассчитывается бета-коэффициент, отражающий взаимосвязь между динамикой доходности изучаемой ценной бумаги и существующими рыночными тенденциями. Простая линейная регрессия по отношению к рыночной динамике может оказаться слишком неточной, так как не позволяет учитывать специфические факторы, оказывающие на данную ценную бумагу влияние весомее, чем на фондовый рынок в целом. Поэтому для более подробного изучения прибегают к более эффективным средствам, в частности: к факторному анализу. Без сопоставления с существующими тенденциями велик риск усиления влияния случайных факторов. Таким образом, для получения достоверного результата методика анализа рынка ценных бумаг должна совмещать оба вышеописанных подхода.
Достаточно высокая эффективность прогнозирования, основанная на использовании бета-коэффициента показывает, что между отдельными ценными бумагами и состоянием фондового рынка в целом наблюдается существенная зависимость, которую можно использовать для проведения оценки будущей доходности. При этом корреляция доходности ценных бумаг со средней доходностью по кластеру значительно выше, чем с рынком в целом. Поэтому в данной методике бета-коэффициент каждой отдельной ценной бумаги рассчитывается, опираясь на не рыночный индекс, а относительно кластера:
![]() [2,стр.240]
[2,стр.240]
где ric – коэффициент корреляции между доходностью ценной бумаги и средней доходностью кластера, к которому она принадлежит,
s i и s с – соответственно их среднеквадратические отклонения.
После расчета бета-коэффициента доходность каждой из исследуемых ценных бумаг можно будет выразить при помощи следующего уравнения регрессии:
![]() [2,стр.245]
[2,стр.245]
а ожидаемая в следующем периоде доходность будет равна
![]() [2,стр.249]
[2,стр.249]
При этом коэффициент неопределенности для каждой ценной бумаги равняется
![]() [2,стр.251]
[2,стр.251]
а величина риска -
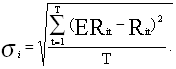 [2,стр.253]
[2,стр.253]
5.Определение оптимального набора ценных бумаг и их долевого весам в инвестиционном портфеле для максимизации доходности.
После всех проведенных преобразований получена для каждой ценной бумаги величину ожидаемой доходности и оценку имеющегося риска. Теперь задача сводится к тому, чтобы определить долевой вес этих ценных бумаг в инвестиционном портфеле с целью максимизации прибыли при заданном уровне риска s п .
Как известно, множество эффективных портфелей расположено на так называемой эффективной границе, не ниже точки минимизации риска. Следовательно, в случае наличия определенности относительно желаемого уровня риска оптимальная точка для заданного набора ценных бумаг может быть определена однозначно:
Основываясь на данных, полученных на трех предыдущих этапах, исходные формулы выглядят следующим образом:
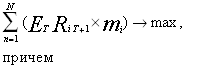
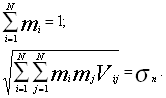 [2,стр.260]
[2,стр.260]
Как уже отмечалось, в случае необходимости добавляется условие не отрицательности долей mi .
Вывод: полученная задача легко решается как при помощи стандартно используемых вычислительных методов, так и большинством математических и экономических программных пакетов (MathCAD, SAS, Solver for MS Excel и т.д.).
4. Кластеризация «голубых фишек» российского фондового рынка
В данном разделе проведен анализ наличия кластеров наиболее ликвидных акций российского рынка. Результаты кластеризации отражены на рис. 2.
Т.к. данный анализ построен на корреляции переменных, то мы видим, что наиболее близкие друг другу переменные это РАО ЕЭС (EESR), Мосэнерго (MSNG), Сургутнефтегаз (SNGS), Газпром (GSPBEX) и Татнефть (TATN). То есть на протяжении больше чем одного года, котировки данных акций кореллировали друг с другом, причем очень сильно. Учитывая, что это происходило в прошлом, скорее всего так будет и в будущем.
Следующий кластер - Сибнефть (SIBN) и Ростелеком (RTKM).Также очень зависимы друг от друга.
Рис. 2 «Результаты кластеризации».
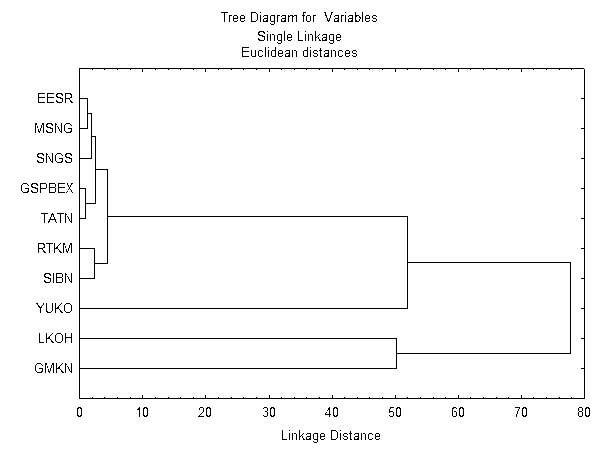
Остальные два кластера имеют большое расстояние в Евклидовом пространстве, т.е. котировки этих акций не кореллируют между собой.
Для оценки надежности данных высказываний используем метод корелляции Спирмена непараметрической статистики.
Таблица 2 – Насколько надежен первый кластер.
| Сравниваемые эмитенты | Коэффициент корреляции Спирмена R |
Уровень значимости p-level |
| EESR & GSPBEX | 0,806077 | 0,000000 |
| EESR & TATN | 0,785205 | 0,000000 |
| EESR & MSNG | 0,943979 | 0,000000 |
| EESR & SNGS | 0,903574 | 0,000000 |
| SNGS & EESR | 0,903574 | 0,000000 |
| SNGS & MSNG | 0,863814 | 0,000000 |
| TATN & GSPBEX | 0,779617 | 0,000000 |
| TATN & MSNG | 0,753098 | 0,000000 |
| TATN & SNGS | 0,874308 | 0,000000 |
Корелляция достаточно сильная, с уровнем значимости менее 0.05. Вывод : Кластер надежен
Таблица 2 – Насколько надежен второй кластер (Сибнефть и Ростелеком)
| Сравниваемые эмитенты | Коэффициент корелляции Спирмена R |
Уровень значимости p-level |
| RTKM & SIBN | 0,946897 | 0,00 |
Вывод : Кластер надежен, корелляция достаточно высокая, с уровнем значимости менее 0.05
Таким образом, при оптимизации структуры портфеля, можно объединить некоторые акции в отдельные кластеры, что при большом количестве активов существенно упрощает расчеты.
ЗАКЛЮЧЕНИЕ
Кластерный анализ включает в себя набор различных алгоритмов классификации. Общий вопрос, задаваемый исследователями во многих областях, состоит в том, как организовать наблюдаемые данные в наглядные структуры. В общем, всякий раз, когда необходимо классифицировать "горы" информации к пригодным для дальнейшей обработки группам, кластерный анализ оказывается весьма полезным и эффективным. Кластерный анализ необходим для классификации информации, с его помощью можно определенным образом структурировать переменные и узнать, какие переменные объединяются в первую очередь, а какие следует рассматривать отдельно.
Большое достоинство кластерного анализа в том, что он позволяет производить разбиение объектов не по одному параметру, а по целому набору признаков. Кроме того, кластерный анализ в отличие от большинства математико-статистических методов не накладывает никаких ограничений на вид рассматриваемых объектов, и позволяет рассматривать множество исходных данных практически произвольной природы. Это имеет большое значение, например, для прогнозирования конъюнктуры, когда показатели имеют разнообразный вид, затрудняющий применение традиционных эконометрических подходов.
Как и любой другой метод, кластерный анализ имеет определенные недостатки и ограничения: В частности, состав и количество кластеров зависит от выбираемых критериев разбиения. При сведении исходного массива данных к более компактному виду могут возникать определенные искажения, а также могут теряться индивидуальные черты отдельных объектов за счет замены их характеристиками обобщенных значений параметров кластера. При проведении классификации объектов игнорируется очень часто возможность отсутствия в рассматриваемой совокупности каких-либо значений кластеров. Первоначально неизвестно число кластеров, на которое необходимо разбить исходную совокупность элементов, и визуальные наблюдения в многомерном случае просто не приводят к успеху.
Описанная методика позволяет оптимально решить сразу две важнейшие проблемы: разбиение множества ценных бумаг на отдельные однородные группы, а также выявление факторов воздействия внешней среды, влияющих на данные группы с последующим нахождением факторных весов. Это позволяет избежать искусственной дискретности, возникающей при жестком выборе факторов внешней среды и сортировке компаний исключительно по отраслям (например, с использованием сектор-факторов).
Технология портфельной оптимизации позволяет формировать инвестиционный портфель на основе выбранного инвестором степени риска и прогнозов изменения макроэкономических факторов, выполненных экспертами инвестиционной компании или государственными органами регулирования экономики. Не меньший практический интерес представляет сравнение имеющегося инвестиционного портфеля с эталонным портфелем в разрезе выбранных факторов, что позволяет выявить и оценить преимущества и недостатки исследуемого набора ценных бумаг, имея при этом количественные критерии.
СПИСОК ЛИТЕРАТУРЫ
1. А. Витин, "Мобилизация финансовых ресурсов для инвестиций", Вопросы Экономики, № 7. 1994.
2. Бажилина Э. Инвестициям - новые цели // Экономика и жизнь. - 1998. - № 13.
3. В. Фельзенбаум, "Иностранные инвестиции в России", Вопросы Экономики, № 8. – 1994.
4. В. Филатов, "Проблемы инвестиционной политики в индустриальной экономике переходного типа", Вопросы Экономики, № 7. - 1994.
5. Вардуль Н. Предварительный диагноз — асфиксия // Коммерсантъ. 24 октября 1995.
6. Витин А. Мобилизация финансовых ресурсов для инвестиций // Вопросы экономики. 1994. № 7.
7. Воскресенский Г. Российский рынок глазами иностранцев // Инвестиции в России. - 1998. - № 2.
8. Е. Кондратенко. “Инвестиционные ресурсы - проблемы аккумуляции” М., Ж. “Экономист”, № 7. 1997.
9. Еще один способ привлечения иностранных инвестиций // Коммерсантъ. 24 октября 1995.
10. Зубакин В. Инвестиции в приватизированные предприятия // Вопросы экономики. 1994. № 7.
11. Касаткин Г. Инвестиционный климат в России: лучше не стало // Рынок ценных бумаг. 1995. № 12.
12. Кошкин В. К эффективной приватизационно-инвестиционной модели // Российский экономический журнал. 1995. № 1.
13. Красавина Л. Н. Международные валютно-кредитные и финансовые отношения. М. 1994. Гл. 9.
14. Лавровский Б., Рыбакова Т. О пределах спада в российской экономике (хроника инвестиционного процесса) // Вопросы экономики. 1994. № 7.
15. Мартынов А. “Активизация инвестиционной политики” М., Ж. “Экономист”, № 9, 1997.
16. Миловидов В. Иностранные инвестиционные фонды в России: первые итоги деятельности // Рынок ценных бумаг. 1995. № 13.
17. Милюков А. Сначала туда, где есть деньги, идут товары. За ними - иностранный инвестор // Деловое Поволжье. -1997. - № 44.
18. Минеев А. Активизация притока иностранных инвестиций в регионы РФ // Инвестиции в России. - 1998. - № 1.
19. Мухетдинова Н. Иностранные инвестиции в России // Российский экономический журнал. 1994. № 2.
20. Основы внешнеэкономических знаний. М. 1994. Гл. 24.
21. П. Самуэльсон. “Экономика”, 1 т., М., 1992.
22. Пичугин Б. Иностранные частные инвестиции в России // Мировая экономика и международные отношения. 1994. № 11.
23. Россия: внешнеэкономические связи в условиях перехода к рынку. М. 1993. Гл. 16.
24. С. Глазьев. “Стабилизация и экономический рост” М., Ж. “Вопросы экономики”, № 1,1997.
25. С. Фишер. “Экономика”, M., 1997.
26. Сейфульмулюков И. Иностранные инвестиции в добывающих отраслях // Российский экономический журнал. 1992. № 11.
27. Смородинская Н., Капустин А. Свободные экономические зоны: мировой опыт и российские перспективы // Вопросы экономики. 1994. № 12.
28. Фадеев А., Рукин А. Инвестиционные портфели // Рынок ценных бумаг. 1995. № 14.
29. Филатов В. Проблемы инвестиционной политики в индустриальной экономике переходного типа // Вопросы экономики. 1994. № 7.
30. Цакунов С. Привлечение иностранных инвестиций в экономику России: новые ориентиры // Рынок ценных бумаг. 1995. № 9.
31. Цветков Н. На мировом рынке инвестиционных капиталов// Инвестиции в России. -1997. - № 11-12.
32. Я. Уринсон. “О мерах по оживлению инвестиционного процесса в России” М., Ж. “Вопросы экономики”, №1, 1997.