| Похожие рефераты | Скачать .docx |
Реферат: Линейный множественный регрессивный анализ
ФЕДЕРАЛЬНОЕ АГЕНТСТВО ПО ОБРАЗОВАНИЮ
ГОСУДАРСТВЕННАЯ ТЕХНОЛОГИЧЕСКАЯ АКАДЕМИЯ
Кафедра ПМиИОЭ
Контрольная работа
по курсу
Эконометрика
(вариант 8)
Задача 1
В исходной таблице (вариант 8) представлены статистические данные о размерах жилой площади и стоимости квартир:
| Жилая площадь, х | Цена кв., у |
| 20 | 15,9 |
| 40,5 | 27 |
| 16 | 13,5 |
| 20 | 15,1 |
| 28 | 21,1 |
| 46,3 | 28,7 |
| 45,9 | 27,2 |
| 47,5 | 28,3 |
| 87,2 | 52,3 |
| 17,7 | 22 |
| 31,1 | 28 |
| 48,7 | 45 |
| 65,8 | 51 |
| 21,4 | 34,4 |
Требуется:
1. Построить поле корреляции и сформулировать гипотезу о виде уравнения регрессии (линейное, показательное, гиперболическое и т.п.).
2. Построить наиболее подходящее уравнение регрессии.
3. Оценить величину влияния фактора на исследуемый показатель с помощью коэффициента корреляции и детерминации.
4. Оценить качество построенной модели с точки зрения адекватности и точности. Для этого оценить математическое ожидание значений остаточного ряда, проверить случайность уровней остатков ряда, их независимость и соответствие нормальному закону. Для оценки точности использовать среднюю относительную ошибку аппроксимации.
5. С помощью коэффициента эластичности определить силу влияния фактора на результативный показатель.
6. Проверить значимость коэффициента регрессии и провести его интервальную оценку.
7. Рассчитать прогнозное значение результата, если прогнозное значение фактора увеличилось на 10 % от среднего уровня. Определить доверительный интервал прогноза для уровня значимости ![]() .
.
8. Сделать выводы по полученным результатам.
Решение:
Для удобства вычислений в ходе решения будем достраивать исходную таблицу данных до вспомогательной (см. Приложение 1), округляя и занося в расчетную таблицу промежуточные результаты.
1. Построим поле корреляции:
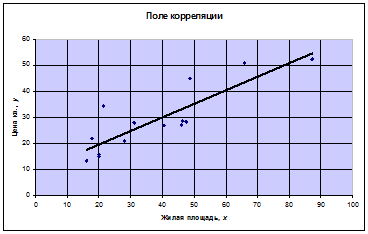
Визуальный анализ полученного графика показывает, что точки поля корреляции располагаются вдоль некоторой воображаемой прямой линии, но не очень плотно, рассеиваясь около неё. Поэтому делаем предположение о линейном виде уравнения регрессии. Нельзя сказать, что прослеживается тесная зависимость, но заметно, что с увеличением размера жилой площади х наблюдается тенденция к увеличению стоимости квартир у. Можно предположить, что связь размера жилой площади и ее стоимости положительная, не очень тесная, и на цену квартир оказывают влияние и другие факторы (район места ее расположения, этаж, наличие коммуникаций, состояние квартиры и т.п.).
2. Построим в соответствии с выбранным линейным видом уравнение регрессии:
![]()
Чтобы определить параметры линейной модели с помощью метода наименьших квадратов, решим систему уравнений на основе исходных и расчетных данных:
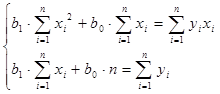
Рассчитав на основе исходных данных необходимые значения (графы 3, 5 таблицы Приложения 1), получаем систему:
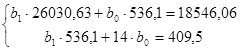
Решив полученную систему уравнений при помощи надстройки «Поиск решения» приложения MSExcel, находим:
b0 = 9,308595
b1 = 0,52076
Составим уравнение парной линейной регрессии:
![]()
В декартовой системе координат ХОУ на поле корреляции строим график линии регрессии по найденному уравнению (рис.1).
3. Для оценки влияния фактора на исследуемый показатель вычислим линейный коэффициент корреляции и коэффициент детерминации.
Используя надстройку приложения MSExcel «Пакет анализа» - инструмент «Корреляция», находим величину линейного коэффициента корреляции.
| Столбец 1 | Столбец 2 | |
| Столбец 1 | 1 | |
| Столбец 2 | 0,8559571 | 1 |
По величине коэффициента корреляции ![]() , принадлежащей интервалу (0,7; 1), оценим качественную характеристику связи как сильную прямую.
, принадлежащей интервалу (0,7; 1), оценим качественную характеристику связи как сильную прямую.
Находим парный коэффициент детерминации:
![]()
Изменение У примерно на 74 % определяется вариацией фактора х, на 26 % - влиянием других факторов. То есть изменения величины стоимости жилой площади на 74% обусловлены колебаниями ее размеров, и на 26 % - колебаниями и изменениями других факторов и условий.
4. Оценим качество построенной модели
Производим расчеты данных для граф 6-10 вспомогательной таблицы (Приложение 1).
Оценим качество построенной модели с точки зрения адекватности. Для этого проверим выполнение следующих требований:
1) Уровни ряда остатков имеют случайный характер. Для проверки выполнения данного требования воспользуемся критерием поворотных точек (пиков).
| -3,829 | -3,4095 | -4,145 | -4,629 | -2,797 | -4,7313 | -6,0229 | -5,7565 | -2,4402 | 3,4693 | 2,4879 | 10,3183 | 7,4092 | 13,9416 |
| + | - | + | + | - | - | + | - | + | + | + | + |
Число поворотных точек р = 8
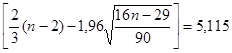
Поскольку р > 5, требование считаем выполненным.
2) Математическое ожидание уровня ряда остатков равно нулю.
![]()
Поскольку полученное значение близко к 0, требование считаем выполненным.
3) Дисперсия каждого отклонения одинакова для всех х. Для проверки выполнения данного требования используем критерий Гольдфельда-Квандта. Исходные значения х расположим в возрастающем порядке:
| Жилая площадь, х | Цена кв., у. |
| 16 | 13,5 |
| 17,7 | 22 |
| 20 | 15,9 |
| 20 | 15,1 |
| 21,4 | 34,4 |
| 28 | 21,1 |
| 31,1 | 28 |
| 40,5 | 27 |
| 45,9 | 27,2 |
| 46,3 | 28,7 |
| 47,5 | 28,3 |
| 48,7 | 45 |
| 65,8 | 51 |
| 87,2 | 52,3 |
Делим полученную таблицу на 2 равные части
| Жилая площадь, х | Цена кв., у | Жилая площадь, х | Цена кв., у |
| 16 | 13,5 | 40,5 | 27 |
| 17,7 | 22 | 45,9 | 27,2 |
| 20 | 15,9 | 46,3 | 28,7 |
| 20 | 15, | 47,5 | 28,3 |
| 21,4 | 34,4 | 48,7 | 45 |
| 28 | 21,1 | 65,8 | 51 |
| 31,1 | 28 | 87,2 | 52,3 |
По каждой группе строим уравнение регрессии:
| Жилая площадь, х | Цена кв., у | ||
| 16 | 13,5 | 256 | 216 |
| 17,7 | 22 | 313,29 | 389,4 |
| 20 | 15,9 | 400 | 318 |
| 20 | 15,1 | 400 | 302 |
| 21,4 | 34,4 | 457,96 | 736,16 |
| 28 | 21,1 | 784 | 590,8 |
| 31,1 | 28 | 967,21 | 870,8 |
| 154,2 | 150 | 3578,46 | 3423,16 |
Чтобы определить параметры линейной модели с помощью метода наименьших квадратов, решим систему уравнений:
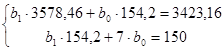
Решив полученную систему уравнений при помощи надстройки «Поиск решения» приложения MSExcel, находим:
b0 = 7,01310810173176
b1 = 0,65439846490193
Составим уравнение парной линейной регрессии:
![]()
На его основе найдем расчетные значения результативного показателя, а также ряд остатков и остаточные суммы квадратов для первой группы:
| Жилая площадь, х | Цена кв, у | ( |
||||
| 16 | 13,5 | 256 | 216 | 17,477 | -3,977 | 15,816529 |
| 17,7 | 22 | 313,29 | 389,4 | 18,5888 | 3,4112 | 11,636285 |
| 20 | 15,9 | 400 | 318 | 20,093 | -4,193 | 17,581249 |
| 20 | 15,1 | 400 | 302 | 20,093 | -4,993 | 24,930049 |
| 21,4 | 34,4 | 457,96 | 736,16 | 21,0086 | 13,3914 | 179,3296 |
| 28 | 21,1 | 784 | 590,8 | 25,325 | -4,225 | 17,850625 |
| 31,1 | 28 | 967,21 | 870,8 | 27,3524 | 0,6476 | 0,4193858 |
| 154,2 | 150 | 3578,46 | 3423,16 | 176,0978 | 0,0622 | 267,5637 |
![]()
Рассчитаем аналогичные параметры для второй группы данных:
| Жилая площадь, х | Цена кв, у | ( |
||||
| 40,5 | 27 | 1640,25 | 1093,5 | 28,6765 | -1,6765 | 2,81065225 |
| 45,9 | 27,2 | 2106,81 | 1248,48 | 31,9003 | -4,7003 | 22,0928201 |
| 46,3 | 28,7 | 2143,69 | 1328,81 | 32,1391 | -3,4391 | 11,8274088 |
| 47,5 | 28,3 | 2256,25 | 1344,25 | 32,8555 | -4,5555 | 20,7525803 |
| 48,7 | 45 | 2371,69 | 2191,5 | 33,5719 | 11,4281 | 130,60147 |
| 65,8 | 51 | 4329,64 | 3355,8 | 43,7806 | 7,2194 | 52,1197364 |
| 87,2 | 52,3 | 7603,84 | 4560,56 | 56,5564 | -4,2564 | 18,116941 |
| 381,9 | 259,5 | 22452,17 | 15122,9 | 259,480 | 0,0197 | 258,3216 |
Решив полученную систему уравнений
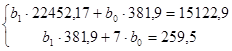
при помощи надстройки «Поиск решения» приложения MSExcel, находим:
b0 = 4,49765806824428
b1 = 0,59705785159018
Составим уравнение парной линейной регрессии:
![]()
![]()
По критерию Гольдфельда-Квандта найдем расчетное значение
![]()
![]()
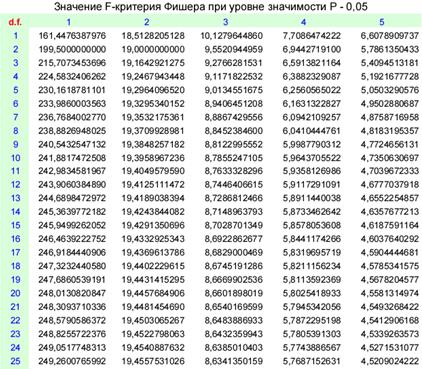
(табличные значения критерия Фишера – в Приложении 5).
Поскольку ![]() <
<![]() , то условие гомоскедастичности выполнено.
, то условие гомоскедастичности выполнено.
4) Значения уровней ряда остатков независимы друг от друга. Проверку на отсутствие автокорреляции осуществим с помощью d-критерия Дарбина-Уотсона:
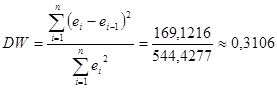
Поскольку d< d1 0,31<1,08 (табличные значения критерия – в Приложении 2), то гипотеза об отсутствии автокорреляции отвергается, и имеется значительная автокорреляция.
5) Уровни ряда остатков распределены по нормальному закону. Проверку выполнения требования проведем по RS-критерию:
![]()
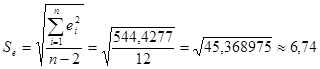
Для объема генеральной совокупности, равного 14, и уровня вероятности ошибки в 5 %, табличные значения нижней и верхней границ RS-критерия равны соответственно 2,92 и 4,09 (табличные значения критерия – в Приложении 3). Поскольку рассчитанное значение критерия не попадает в интервал табличных значений, гипотеза о нормальном распределении отвергается.
Оценим качество построенной модели с точки зрения точности. Для этого используем среднюю относительную ошибку аппроксимации, рассчитав данные для графы 11 вспомогательной таблицы (Приложение 1).
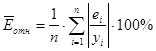
![]()
В среднем смоделированные значения стоимости квартир отклоняются от фактических на 19,8 %. Подбор модели к фактическим данным можно оценить как не очень точный, отклонения фактических значений от теоретических заметные.
5. С помощью коэффициента эластичности определим силу влияния фактора на результативный показатель.
Рассчитаем средние значения фактора и результативного показателя:
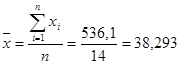
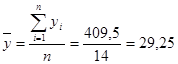
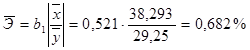
Средний коэффициент эластичности показывает, что в среднем при повышении размера жилой площади на 1% от своего среднего значения ее стоимость увеличивается на 0,682% от своего среднего значения.
6. Проверим значимость коэффициента регрессии и проведем его интервальную оценку.
Значимость коэффициента b1 определим с помощью t-критерия Стьюдента (табличные значения критерия приведены в Приложении 4). Рассчитаем опытное значение критерия:
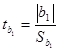
При этом среднеквадратическое отклонение коэффициента b1 найдем по формуле:
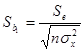 ,
,
где остаточное среднеквадратическое отклонение найдем:
![]()
![]()
![]()
Поскольку ![]() , то
, то ![]() и коэффициент b1
, как и все уравнение регрессии, является значимым.
и коэффициент b1
, как и все уравнение регрессии, является значимым.
Таким образом, можно считать, что предполагаемая зависимость стоимости квартиры от ее размера подтвердилась и статистически установлена.
Проверим значимость выбранного коэффициента с помощью критерия Фишера:
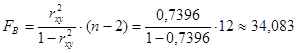
![]()
Наблюдаемое значение F–критерия превышает табличное: 34,083 >
4,75, т.е. выполнено неравенство ![]() , а значит, в 95 % случаев уравнение регрессии статистически значимо и отражает существенную зависимость между размером цены квартиры от ее жилой площади. Уравнение можно признать надежным и значимым, доказывающим наличие исследуемой зависимости.
, а значит, в 95 % случаев уравнение регрессии статистически значимо и отражает существенную зависимость между размером цены квартиры от ее жилой площади. Уравнение можно признать надежным и значимым, доказывающим наличие исследуемой зависимости.
Доверительный интервал для ![]() рассчитывается по формуле:
рассчитывается по формуле:
![]()
При выбранной надежности g=0,95 получим:
![]() , откуда
, откуда ![]() .
.
Таким образом, с надежностью 95% можно утверждать, что истинное значение параметра b1 будет заключено в пределах от 0,3227 до 0,7193.
7. Рассчитаем прогнозное значение результата, если прогнозное значение фактора увеличится на 10% от среднего уровня.
Полученные оценки уравнения регрессии позволяют использовать его для прогноза численных значений стоимости жилой площади. Но как уже говорилось, точность модели невысока.
В случае увеличения фактора на 10 % от своего среднего значения размер данного увеличения составит:
![]()
Прогнозное значение фактора при этом составит:
![]()
Точечный прогноз:
![]()
Т.е. по модели предсказываем, что если жилая площадь квартиры, увеличившись на 10 % от своего среднего значения, составит 42,12 условных единиц, то ожидаемая (прогнозная) величина ее стоимости составит 31,25 условных единиц.
Доверительный интервал для среднего размера стоимости квартиры при условии, что ее жилая площадь составляет х = 42,12 условных единиц с надежностью g=0,95:
![]()
![]()
где стандартная ошибка для средних значений:
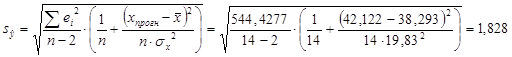
Т.е. средний размер стоимости жилой площади размером 42,1223 условные единицы находится в границах от 27,2719 до 35,2375 условные единицы.
Доверительный интервал для индивидуальных значений размера стоимости квартир с жилой площадью 42,1223 условные единицы с надежностью g=0,95:
![]()
![]() ,
,
где стандартная ошибка для индивидуальных значений:
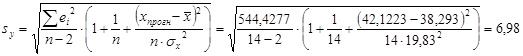
Таким образом, если размер жилой площади будет находиться на уровне 42,1223 условные единицы, то возможный размер ее стоимости в 95% случаев может находиться внутри интервала от 16.046 до 46.463 условные единицы. Этот интервал определяет границы, за пределами которых могут оказаться не более 5% значений стоимости квартир, которые могли быть зафиксированы при размере их жилой площади в 42,1223 условные единицы.
Выводы, сделанные ранее подтвердились. Интервальный прогноз не отличается высокой точностью, но вполне пригоден для практического использования.
8. Полученные результаты позволяют сделать следующие выводы:
Статистически значимый коэффициент регрессии b1 и коэффициент корреляции rух свидетельствуют о наличии сильной зависимости стоимости квартиры от размера ее жилой площади. Можно считать, что наличие этой зависимости статистически доказано, направление и общая тенденция отражена уравнением регрессии верно и согласуется с экономической теорией. Высокое значение коэффициента детерминации R2 указывает, что на формирование стоимости квартир существенное влияние оказывает именно размер их жилой площади и в значительно меньшей мере (порядка 26 %) - другие экономические факторы.
С другой стороны, относительная ошибка аппроксимации свидетельствует, что модель подобрана не точно: в среднем теоретические (смоделированные данные) отличаются от фактических на 19,8 %. В целом применение полученного уравнения регрессии возможно в случае повышения его прогностической силы и практической ценности за счет увеличения объема выборки.
Задача 2
В исходной таблице (вариант 8) представлены статистические данные о различных параметрах уровня жизни населения в 2004 г.:
| № | Страны | Х1 | Х3 | Х6 | Х8 | Х9 | У |
| 1 | Россия | 55 | 30 | 20,4 | 28 | 124 | 84,98 |
| 2 | Австралия | 100 | 47 | 71,4 | 121 | 87 | 30,56 |
| 3 | Австрия | 93 | 37 | 78,7 | 146 | 74 | 38,42 |
| 4 | Азербайджан | 20 | 12,4 | 12,1 | 52 | 141 | 60,34 |
| 5 | Армения | 20 | 4,3 | 10,9 | 72 | 134 | 60,22 |
| 6 | Белоруссия | 72 | 28 | 20,4 | 38 | 120 | 60,79 |
| 7 | Бельгия | 85 | 48 | 79,7 | 83 | 72 | 29,82 |
| 8 | Болгария | 65 | 18 | 17,3 | 92 | 156 | 70,57 |
| 9 | Великобритания | 67 | 39 | 69,7 | 91 | 91 | 34,51 |
| 10 | Венгрия | 73 | 40 | 24,5 | 73 | 106 | 64,73 |
| 11 | Германия | 88 | 35 | 76,2 | 138 | 73 | 36,63 |
| 12 | Греция | 83 | 24 | 44,4 | 99 | 108 | 32,84 |
| 13 | Грузия | 21 | 36 | 11,3 | 55 | 140 | 62,64 |
| 14 | Дания | 98 | 38 | 79,2 | 89 | 77 | 34,07 |
| 15 | Ирландия | 99 | 31 | 57 | 87 | 102 | 39,27 |
| 16 | Испания | 89 | 26 | 54,8 | 103 | 72 | 28,46 |
| 17 | Италия | 84 | 27 | 72,1 | 169 | 118 | 30,27 |
| 18 | Казахстан | 61 | 19,2 | 13,4 | 10 | 191 | 69,04 |
| 19 | Канада | 98 | 44 | 79,9 | 123 | 77 | 25,42 |
| 20 | Киргизия | 46 | 23,5 | 11,2 | 20 | 134 | 53,13 |
| 21 | Нидерланды | 86 | 37 | 72,4 | 176 | 59 | 28,00 |
| 22 | Португалия | 73 | 27 | 48,6 | 150 | 83 | 38,79 |
| 23 | США | 115 | 29 | 100 | 99 | 103 | 32,04 |
| 24 | Финляндия | 62 | 36 | 63,9 | 82 | 94 | 38,58 |
| 25 | Франция | 91 | 36 | 77,5 | 84 | 85 | 18,51 |
| 26 | Чехия | 82 | 45 | 34,7 | 65 | 114 | 57,62 |
| 27 | Япония | 40 | 20 | 83,5 | 60 | 119 | 20,80 |
| ∑ | 1966 | 837,4 | 1385,2 | 2405 | 2854 | 1181,05 | |
| 72,81 | 31,01 | 51,3 | 89,07 | 105,7 | 43,74 |
Х1 - потребление мяса и мясопродуктов на душу населения (кг),
Х3 - потребление сахара на душу населения (кг),
Х6 - оценка ВВП по паритету покупательной способности в 1994 г. на душу населения (в % к США),
Х8 - потребление фруктов и ягод на душу населения (кг),
Х9 - потребление хлебных продуктов на душу населения (кг),
У – смертность населения по причине болезни органов кровообращения на 100000 населения.
Требуется:
1) Рассчитать параметры линейного уравнения множественной регрессии.
2) Определить сравнительную оценку влияния факторов на результативный показатель с помощью коэффициентов эластичности.
3) Оценить статистическую значимость параметров регрессионной модели с помощью t-критерия. Адекватность модели проверить с помощью F-критерия.
4) Оценить качество построенного уравнения с помощью средней ошибки аппроксимации.
5) Используя метод многошагового регрессионного анализа, построить регрессионную модель только со значимыми факторами и оценить ее параметры.
6) Определить прогнозное значение результата, если прогнозные значения факторов составляют 80 % от их максимальных значений.
7) Рассчитать ошибки и доверительный интервал прогноза для уровня значимости ![]() и
и ![]() .
.
8) Сделать выводы по полученным результатам.
Решение:
1. Рассчитаем параметры линейного уравнения множественной регрессии
Для удобства в ходе решения будем достраивать исходную таблицу данных до вспомогательной (см. Приложение 6), округляя и занося в ее промежуточные результаты. Уравнение множественной линейной регрессии для нашего случая имеет общий вид:
![]()
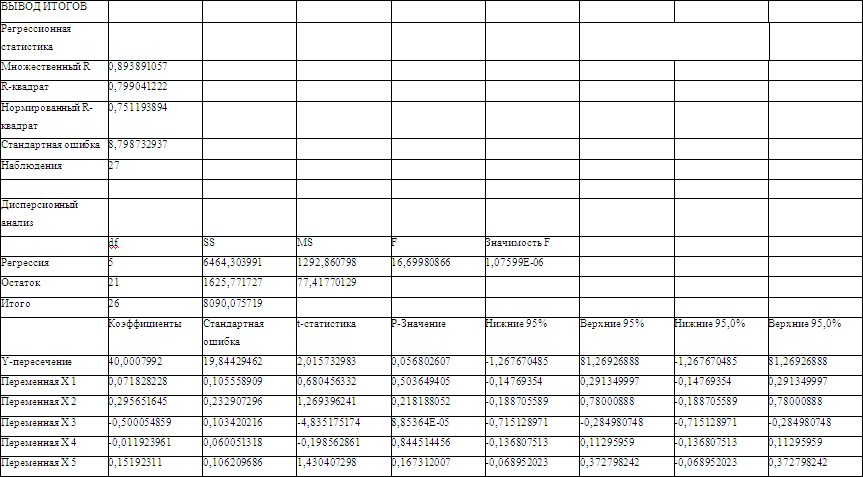
Параметры данного уравнения найдем с помощью инструмента «Регрессия» надстройки «Анализ данных» приложения MS Excel (результаты вычисления – в Приложении 7):
b0 = 40,0007992
b1 = 0,071828228
b2 = 0,295651645
b3 = -0,500054859
b4 = -0,500054859
b5 = 0,15192311
Получаем уравнение линейной множественной регрессии:
![]()
2. Определим сравнительную оценку влияния факторов на результативный показатель с помощью коэффициентов эластичности.
Т.к. факторы имеют различную природу и размерность, непосредственная оценка их влияния затруднена. Поэтому для каждого из них необходимо рассчитать свой коэффициент эластичности.
Для расчета коэффициентов найдем средние значения факторов и результативного показателя:
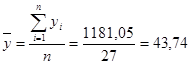
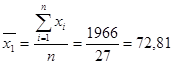
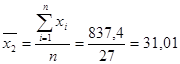
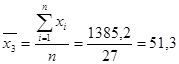
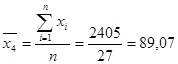
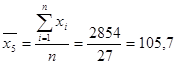
Подставим полученные значения в формулу:
![]()
![]()
![]()
![]()
![]()
![]()
Таким образом, смертность населения по причине болезни органов кровообращения на 100000 населения увеличивается примерно на 0,12 % при увеличении потребления мяса и мясопродуктов на душу населения на 1 %, на 0,21% при увеличении на 1% потребления сахара на душу населения и на 0,37% при увеличении потребления хлебных продуктов на душу населения на 1%.
А при увеличении оценки ВВП по паритету покупательной способности в 1994 г. на душу населения на 1% результативный показатель, наоборот, уменьшится на 0,59%. Увеличение же потребления фруктов и ягод на душу населения на 1% повлечет снижение смертности примерно на 1,02%.
3. Оценим статистическую значимость параметров регрессионной модели с помощью t -критерия.
Расчетные значения критерия для пяти заданных параметров получили с помощью инструмента «Регрессия» надстройки «Анализ данных» приложения MS Excel (результаты вычисления – в Приложении 7):
![]()
![]()
![]()
![]()
![]()
Поскольку ![]() , то коэффициенты b1
, b2
, b3
, b4
, b5
не являются значимыми для построенной модели.
, то коэффициенты b1
, b2
, b3
, b4
, b5
не являются значимыми для построенной модели.
Адекватность модели проверим с помощью F -критерия.
![]()
Величина множественного коэффициента детерминации R2 =0,799, также рассчитана с помощью инструмента «Регрессия» надстройки «Анализ данных» приложения MS Excel (результаты вычисления – в Приложении 7). Построенную модель на основе этого параметра можно признать достаточно качественной. А изменение результативного показателя примерно на 80 % обусловлено влиянием факторов, включенных в модель.
![]()
![]()
Наблюдаемое значение F–критерия превышает табличное: 16,65 >
4,52, т.е. выполнено неравенство ![]() , а значит, в 95 % случаев уравнение регрессии статистически значимо и отражает существенную зависимость между факторами и результативным показателем.
, а значит, в 95 % случаев уравнение регрессии статистически значимо и отражает существенную зависимость между факторами и результативным показателем.
Уравнение можно признать надежным и значимым, доказывающим наличие исследуемой зависимости.
4. Оценим качество построенного уравнения с помощью средней ошибки аппроксимации.
Проведем необходимые дополнительные расчеты с вспомогательной таблицей (графа 11 Приложения 6). На основе полученных данных найдем значение средней ошибки аппроксимации:
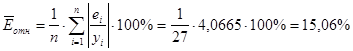
Полученное значение средней ошибки аппроксимации подтверждает удовлетворительную точность построенной модели.
5. Используя метод многошагового регрессионного анализа, построим регрессионную модель только со значимыми факторами и оценим ее параметры.
Поскольку модель со всеми заданными факторами уже построена, и значимость каждого фактора рассчитана, можем перейти к следующему шагу анализа, исключив из модели самый незначимый фактор.
![]()
Исключаем фактор Х6 - оценка ВВП по паритету покупательной способности в 1994 г. на душу населения (в % к США). Строим новую модель с оставшимися факторами:
![]()
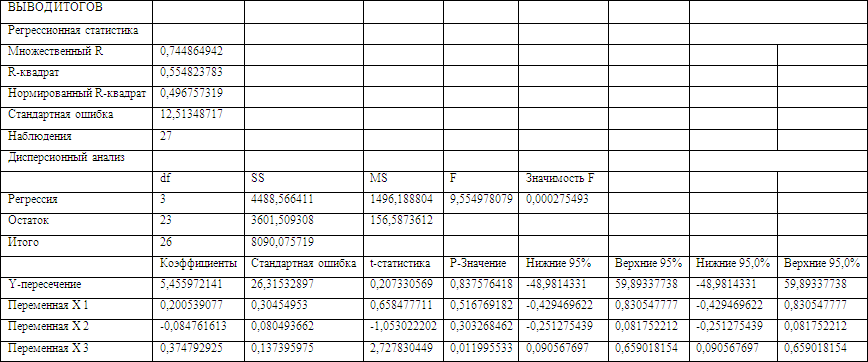
Параметры данного уравнения найдем с помощью инструмента «Регрессия» надстройки «Анализ данных» приложения MS Excel (результаты вычисления – в Приложении 8):
b0 =11,3789103724081
b1 = -0,140477614195711
b2 = 0,334073328849854
b4 = -0,0590948468841696
b5 = 0,354719169807746
Получаем уравнение линейной множественной регрессии:
![]()
Расчетные значения критерия для заданных параметров получили с помощью инструмента «Регрессия» надстройки «Анализ данных» приложения MS Excel (результаты вычисления – в Приложении 8):
![]()
![]()
![]()
![]()
Поскольку ![]() , то коэффициенты b1
, b2
, b4
не являются значимыми для построенной модели. Исключаем самый незначимый фактор:
, то коэффициенты b1
, b2
, b4
не являются значимыми для построенной модели. Исключаем самый незначимый фактор:
![]()
Исключаем фактор Х1 - потребление мяса и мясопродуктов на душу населения (кг).
Строим новую модель с оставшимися факторами:
![]()
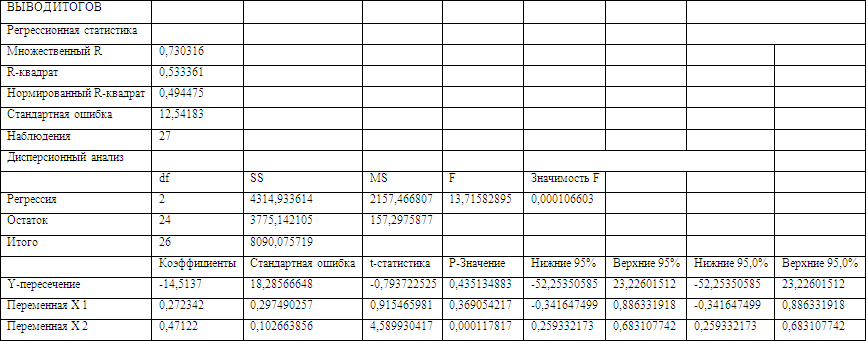
Параметры данного уравнения найдем с помощью инструмента «Регрессия» надстройки «Анализ данных» приложения MS Excel (результаты вычисления – в Приложении 9):
b0 = 5,45597214112287
b2 = 0,200539077387593
b4 = -0,0847616134509301
b5 = 0,374792925415136
Получаем уравнение линейной множественной регрессии:
![]()
Расчетные значения критерия для заданных параметров получили с помощью инструмента «Регрессия» надстройки «Анализ данных» приложения MS Excel (результаты вычисления – в Приложении 8):
![]()
![]()
![]()
Поскольку ![]() , то коэффициенты b2
, b4
не являются значимыми для построенной модели. Исключаем самый незначимый фактор:
, то коэффициенты b2
, b4
не являются значимыми для построенной модели. Исключаем самый незначимый фактор:
![]()
Исключаем фактор Х8 - потребление фруктов и ягод на душу населения (кг). Строим новую модель с оставшимися факторами:
![]()
Параметры данного уравнения найдем с помощью инструмента «Регрессия» надстройки «Анализ данных» приложения MS Excel (результаты вычисления – в Приложении 10):
b0 = -14,5137453627595
b2 = 0,272342209805998
b5 = 0,471219957359132
Получаем уравнение линейной множественной регрессии:
![]()
Расчетные значения критерия для заданных параметров получили с помощью инструмента «Регрессия» надстройки «Анализ данных» приложения MS Excel (результаты вычисления – в Приложении 10):
![]()
![]()
Поскольку
![]() ,
,
то коэффициент b2 не является значимым для построенной модели. Исключаем незначимый фактор:
![]()
Исключаем фактор Х3 - потребление сахара на душу населения (кг). Строим новую модель с оставшимся фактором:
![]()
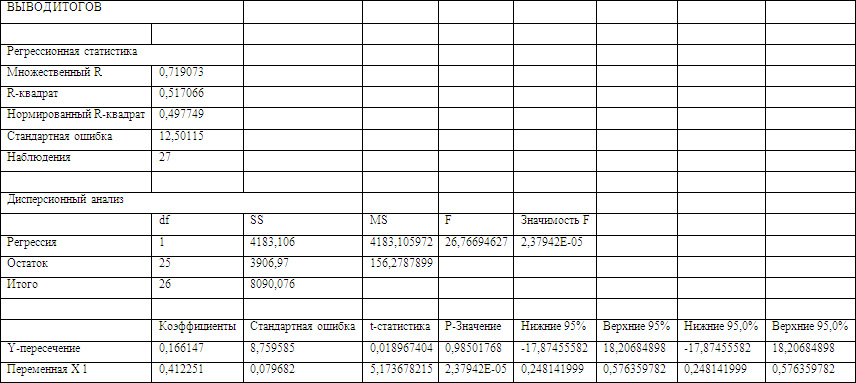
Параметры данного уравнения найдем с помощью инструмента «Регрессия» надстройки «Анализ данных» приложения MS Excel (результаты вычисления – в Приложении 11):
b0 = 0,166147
b5 = 0,412251
Получаем уравнение линейной парной регрессии:
![]()
Расчетное значение критерия для параметра b5 получили с помощью инструмента «Регрессия» надстройки «Анализ данных» приложения MS Excel (результаты вычисления – в Приложении 11):
![]()
Поскольку
![]() ,
,
то коэффициент b5 является значимым для построенной модели. Таким образом, посредством пошагового регрессионного анализа, осуществленного методом исключения факторов, получили модель, содержащую только один значимый фактор Х9 - потребление хлебных продуктов на душу населения (кг).
6. Определим прогнозное значение результата, если прогнозные значения факторов составляют 80 % от их максимальных значений.
Поскольку в уравнении регрессии остался лишь один значимый фактор, именно на основе данных о потреблении хлебных продуктов на душу населения будем рассчитывать прогнозное значение результативного показателя.
![]()
Если прогнозное значение фактора составит 80% от своего максимального значения
![]() ,
,
тогда точечное прогнозное значение результативного показателя составит
![]()
Т.е. еслипотребление хлебных продуктов на душу населения составит 152,8 кг, то прогнозное значение смертности населения по причине болезни органов кровообращения на 100000 населения составит примерно 63.
7. Рассчитаем ошибки и доверительный интервал прогноза для уровня значимости ![]() и
и ![]() .
.
![]()
Доверительный интервал для среднего размера смертности населения по причине болезни органов кровообращения на 100000 населения при условии, что потребление хлебных продуктов составляет х = 152,8 кг с надежностью g=0,95:
![]()
![]()
где стандартная ошибка для средних значений:
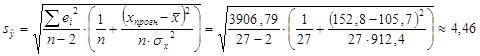
Т.е. средний размер смертности населения по причине болезни органов кровообращения на 100000 населения при условии, что потребление хлебных продуктов составляет х = 152,8 кг, находится в интервале от 53 до 72 человек. Доверительный интервал для индивидуальных значений размера смертности населения по причине болезни органов кровообращения на 100000 населения при условии, что потребление хлебных продуктов составляет х = 152,8 кг с надежностью g=0,95:
![]()
![]() ,
,
где стандартная ошибка для индивидуальных значений:
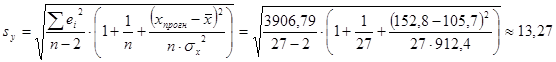
Таким образом, если потребление хлебных продуктов будет находиться на уровне 152,8 кг, то возможный размер смертности населения по причине болезни органов кровообращения на 100000 населения в 95% случаев может находиться внутри интервала от 35 до 90 человек.
Рассчитаем те же показатели для уровня значимости
![]()
Доверительный интервал для среднего размера смертности населения по причине болезни органов кровообращения на 100000 населения при условии, что потребление хлебных продуктов составляет х = 152,8 кг с надежностью g=0,90:
![]()
![]()
Т.е. средний размер смертности населения по причине болезни органов кровообращения на 100000 населения при условии, что потребление хлебных продуктов составляет х = 152,8 кг, находится в интервале от 55 до 70 человек.
Доверительный интервал для индивидуальных значений размера смертности населения по причине болезни органов кровообращения на 100000 населения при условии, что потребление хлебных продуктов составляет х = 152,8 кг с надежностью g=0,90:
![]()
![]()
Таким образом, если потребление хлебных продуктов будет находиться на уровне 152,8 кг, то возможный размер смертности населения по причине болезни органов кровообращения на 100000 населения в 90% случаев может находиться внутри интервала от 40 до 85 человек.
8. Полученные результаты позволяют сделать следующие выводы:
На основе сравнительной оценки влияния факторов на результативный показатель посредством расчета коэффициентов эластичности удалось установить, что смертность населения по причине болезни органов кровообращения на 100000 населения увеличивается примерно на 0,12 % при увеличении потребления мяса и мясопродуктов на душу населения на 1 %, на 0,21% при увеличении на 1% потребления сахара на душу населения и на 0,37% при увеличении потребления хлебных продуктов на душу населения на 1%.
А при увеличении оценки ВВП по паритету покупательной способности в 1994 г. на душу населения на 1% результативный показатель, наоборот, уменьшится на 0,59%. Увеличение же потребления фруктов и ягод на душу населения на 1% повлечет снижение смертности примерно на 1,02%.
Величина множественного коэффициента детерминации R2 =0,799 свидетельствует о том, что изменение результативного показателя примерно на 80% обусловлено влиянием факторов, включенных в модель. Оценка качества построенного уравнения с помощью средней ошибки аппроксимации подтверждает удовлетворительную точность построенной модели.
Оценка адекватности построенной модели с помощью F-Критерия Фишера подтвердила, что в 95 % случаев уравнение регрессии статистически значимо и отражает существенную зависимость между факторами и результативным показателем. А значит, уравнение можно признать надежным и значимым, доказывающим наличие исследуемой зависимости.
Посредством пошагового регрессионного анализа, осуществленного методом исключения факторов, получили модель, содержащую только один значимый фактор - потребление хлебных продуктов на душу населения. С его использованием построили новое уравнение регрессии, с помощью которого рассчитали прогнозное точечное значение результативного показателя и доверительный интервал для уровня значимости ![]() и
и ![]() .
.
Задача 3
В исходной таблице (графы 2 и 3 Приложения 13) представлены статистические данные об объеме продаж продовольственных товаров с 1 января 1990 г. в относительных единицах.
Требуется:
1. Представить временной ряд графически, провести его сглаживание методом простой скользящей средней, оценить наличие тренда.
2. Построить уравнение неслучайной составляющей (тренда) временного ряда, проверить значимость построенного уравнения по F-критерию при уровне значимости ![]() .
.
3. Дать точечную, интервальную оценки прогноза среднего и индивидуального значений с надежностью ![]() на 1 и 2 шага вперед.
на 1 и 2 шага вперед.
4. Построить авторегрессионную модель временного ряда, дать точечный, интервальный прогноз среднего и индивидуального значений с надежностью ![]() на 1 и 2 шага вперед.
на 1 и 2 шага вперед.
5. Сделать выводы по полученным результатам.
Решение:
1. Представим временной ряд графически:
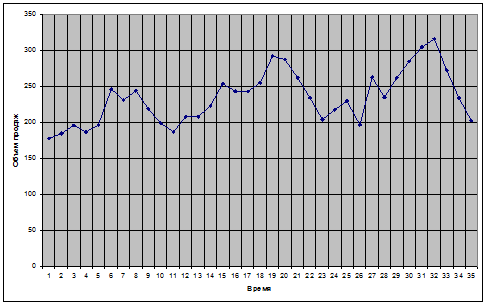
Проведем его сглаживание методом простой скользящей средней. Выбрав величину скользящей средней, равную 3, доработаем исходную таблицу данных – найдем средние значения для каждых трех исходных (графа 4 Приложения 13).
На основе средних значений строим диаграмму сглаженных данных:
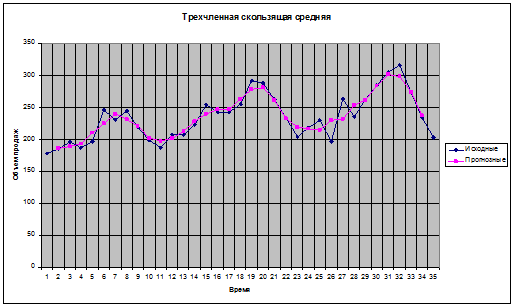
По графику можно сделать предположение о наличии тренда линейного типа. Для наглядности еще более сгладим исходные данные, построив с помощью инструмента «Скользящее среднее» надстройки «Анализ данных» приложения MS Excel график пятичленной скользящей средней.
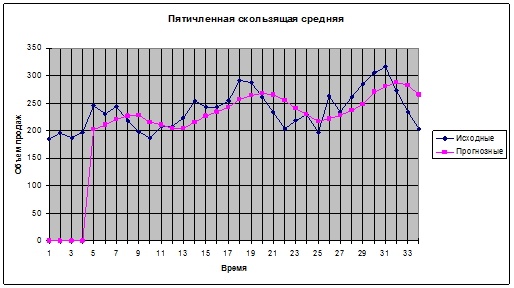
Предположение о наличии тренда подтверждается, очевидно, также имеет место сезонная компонента.
2. Построим уравнение неслучайной составляющей (тренда) временного ряда
Для определения параметров модели временного ряда из линейного уравнения
![]()
воспользуемся инструментом «Регрессия» надстройки «Анализ данных» приложения MS Excel (результаты вычислений – в Приложении 14).
Получаем уравнение тренда временного ряда следующего вида:
![]()
Проверим значимость построенного уравнения по
F
-критерию при уровне значимости ![]()
![]()
Величина коэффициента детерминации R2 =0,324 также рассчитана с помощью инструмента «Регрессия» надстройки «Анализ данных» приложения MS Excel (результаты вычисления – в Приложении 14). Судя по этому параметру, изменение результативного показателя примерно на 32 % обусловлено влиянием временного фактора. Построенную модель на основе парного коэффициента корреляции =0,57 можно признать умеренно качественной.
![]()
![]()
Наблюдаемое значение F–критерия меньше табличного: 250,476 >
16,2, т.е. выполнено неравенство ![]() , а значит, в 95 % случаев уравнение регрессии статистически незначимо и не отражает зависимости между временем и объемом продаж продовольственных товаров, что подтверждается экономической теорией.
, а значит, в 95 % случаев уравнение регрессии статистически незначимо и не отражает зависимости между временем и объемом продаж продовольственных товаров, что подтверждается экономической теорией.
3.
Дать точечную, интервальную оценки прогноза среднего и индивидуального значений с надежностью ![]() на 1 и 2 шага вперед.
на 1 и 2 шага вперед.
Чтобы сделать точечный прогноз на 1 и 2 шага вперед, подставим соответствующие значения фактора в полученное уравнение регрессии:
![]()
Доверительный интервал для среднего размера объема продаж продовольственных товаров на 01.12.1995 г. (t=36) с надежностью g=0,95:
![]()
![]()
где стандартная ошибка для средних значений:
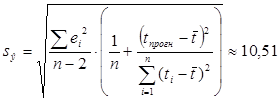 ,
,
![]()
Т.е. средний размер объема продаж продовольственных товаров на 01.12.1995 г. (t=36) примерно находится в интервале от 249 до 292 относительных единиц.
Доверительный интервал для индивидуальных значений размера объема продаж продовольственных товаров на 01.12.1995 г. (t=36) с надежностью g=0,95:
![]()
![]()
где стандартная ошибка для индивидуальных значений:
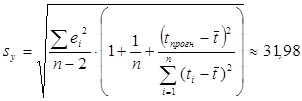
Таким образом, размер объема продаж продовольственных товаров на 01.12.1995 г. (t=36) в 95% случаев может находиться внутри интервала примерно от 205 до 335 относительных единиц.
Для прогноза на 2 шага вперед:
![]()
Доверительный интервал для среднего размера объема продаж продовольственных товаров на 01.01.1996 г. (t=37) с надежностью g=0,95:
![]()
![]()
где стандартная ошибка для средних значений:
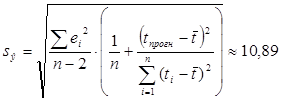 ,
,
![]()
Т.е. средний размер объема продаж продовольственных товаров на 01.01.1996 г. (t=37) примерно находится в интервале от 250 до 294 относительных единиц.
Доверительный интервал для индивидуальных значений размера объема продаж продовольственных товаров на 01.01.1996 г. (t=37) с надежностью g=0,95:
![]()
![]()
где стандартная ошибка для индивидуальных значений:
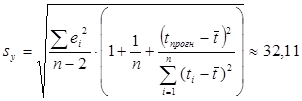
Таким образом, размер объема продаж продовольственных товаров на 01.01.1996 г. (t=37) в 95% случаев может находиться внутри интервала примерно от 207 до 304 относительных единиц.
4. Построим авторегрессионную модель временного ряда.
Для построения авторегрессионной модели 1-го порядка вида
![]()
Определим ее параметры с помощью МНК из системы уравнений:
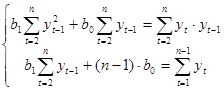
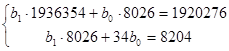
Воспользовавшись надстройкой «Поиск решения» приложения MSExcel, находим коэффициенты модели:
![]()
Получаем модель:
![]()
Дадим точечный прогноз по полученной авторегрессионной модели на 1 и 2 шага вперед:
![]()
![]()
Дадим интервальный прогноз среднего и индивидуального значений по полученной авторегрессионной модели с надежностью ![]() на 1 и 2 шага вперед.
на 1 и 2 шага вперед.
Доверительный интервал для среднего размера объема продаж продовольственных товаров по полученной авторегрессионной модели на 01.12.1995 г. (t=36) с надежностью g=0,95:
![]()
![]()
где стандартная ошибка для средних значений:
![]() ,
, ![]()
Доверительный интервал для индивидуальных значений размера объема продаж продовольственных товаров по полученной авторегрессионной модели на 01.12.1995 г. (t=36) с надежностью g=0,95:
![]()
![]()
где стандартная ошибка для индивидуальных значений:
![]()
Итак, с надежностью 0,95 среднее значение объема продаж продовольственных товаров на момент t=36 будет заключено в пределах от 233,17 до 275,99 относительных единиц, а его индивидуальное значение — от 189,44 до 319,72 относительных единиц.
Для прогноза на 2 шага вперед:
![]()
Доверительный интервал для среднего размера объема продаж продовольственных товаров по полученной авторегрессионной модели на 01.12.1995 г. (t=37) с надежностью g=0,95:
![]()
![]()
где стандартная ошибка для средних значений
![]()
Доверительный интервал для индивидуальных значений размера объема продаж продовольственных товаров по полученной авторегрессионной модели на 01.01.1996 г. (t=37) с надежностью g=0,95:
![]()
![]()
где стандартная ошибка для индивидуальных значений: ![]()
Итак, с надежностью 0,95 среднее значение объема продаж продовольственных товаров на момент t=37 будет заключено в пределах от 212,28 до 254,64 относительных единиц, а его индивидуальное значение — от 169,06 до 299,86 относительных единиц.
5. Выводы по полученным результатам:
Проведя сглаживание временного ряда методом простой скользящей средней, по графику сделали предположение о наличии тренда линейного типа. Вычислив параметры модели, получаем уравнение тренда
![]()
Величина коэффициента детерминации R2 =0,324 свидетельствует о том, что изменение У на 32% обусловлено влиянием времени. Построенную модель на основе коэффициента корреляции можно признать умеренно качественной.
Проверив значимость построенного уравнения по F-критерию, приходим к выводу, что в 95% случаев уравнение регрессии статистически незначимо и не отражает зависимости между временем и объемом продаж продовольственных товаров, что подтверждается экономической теорией.
Точечный прогноз на 1 шаг вперед на основе полученной модели примет значение
![]()
Интервальный прогноз позволяет установить, что размер объема продаж на 01.12.1995 г. в 95% случаев может находиться в интервале от 205 до 335 относительных единиц, а средний размер объема продаж - в интервале от 249 до 292 относительных единиц.
Точечный прогноз на 2 шага вперед на основе полученной модели примет значение
![]()
Интервальный прогноз позволяет установить, что размер объема продаж на 01.01.1996 г. в 95% случаев может находиться внутри интервала примерно от 207 до 304 относительных единиц, а средний размер объема продаж – внутри интервала от 207 до 304 относительных единиц.
Поскольку построенное ранее уравнение линейного тренда не является значимым, для прогнозирования значений временного ряда построили авторегрессионную модель
![]()
Даем точечный прогноз на 1 шаг вперед
![]()
и интервальный на уровне значимости 0,05 для среднего и индивидуального значений –
![]()
и ![]()
А такжеточечный прогноз на 2 шага вперед
![]() ,
,
и интервальный на уровне значимости 0,05 для среднего и индивидуального значений –
![]() и
и ![]() .
.
линейный множественный регрессия модель
Приложение 1
Жилая пло щадь, x |
Цена квартиры,у | ( |
( |
|||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 20 | 15,9 | 400 | 252,81 | 318 | 19,729 | -3,829 | 14,66124 | - | - | -0,241 |
| 40,5 | 27 | 1640,25 | 729 | 1093,5 | 30,4095 | -3,4095 | 11,62469 | 0,4195 | 0,175980 | -0,126 |
| 16 | 13,5 | 256 | 182,25 | 216 | 17,645 | -4,145 | 17,18103 | -0,7355 | 0,540960 | -0,307 |
| 20 | 15,1 | 400 | 228,01 | 302 | 19,729 | -4,629 | 21,42764 | -0,484 | 0,234256 | -0,307 |
| 28 | 21,1 | 784 | 445,21 | 590,8 | 23,897 | -2,797 | 7,823209 | 1,832 | 3,356224 | -0,133 |
| 46,3 | 28,7 | 2143,69 | 823,69 | 1328,81 | 33,4313 | -4,7313 | 22,3852 | -1,9343 | 3,741517 | -0,165 |
| 45,9 | 27,2 | 2106,81 | 739,84 | 1248,48 | 33,2229 | -6,0229 | 36,27532 | -1,2916 | 1,668231 | -0,221 |
| 47,5 | 28,3 | 2256,25 | 800,89 | 1344,25 | 34,0565 | -5,7565 | 33,13729 | 0,2664 | 0,070969 | -0,203 |
| 87,2 | 52,3 | 7603,84 | 2735,29 | 4560,56 | 54,7402 | -2,4402 | 5,954576 | 3,3163 | 10,99785 | -0,047 |
| 17,7 | 22 | 313,29 | 484 | 389,4 | 18,5307 | 3,4693 | 12,03604 | 5,9095 | 34,92219 | 0,158 |
| 31,1 | 28 | 967,21 | 784 | 870,8 | 25,5121 | 2,4879 | 6,189646 | -0,9814 | 0,963146 | 0,089 |
| 48,7 | 45 | 2371,69 | 2025 | 2191,5 | 34,6817 | 10,318 | 106,4673 | 7,8304 | 61,31516 | 0,229 |
| 65,8 | 51 | 4329,64 | 2601 | 3355,8 | 43,5908 | 7,4092 | 54,89625 | -2,9091 | 8,462863 | 0,145 |
| 21,4 | 34,4 | 457,96 | 1183,36 | 736,16 | 20,4584 | 13,942 | 194,3682 | 6,5324 | 42,67225 | 0,405 |
| ∑ 536,1 | 409,5 | 26030,63 | 14014,35 | 18546,06 | 409,6341 | -0,1341 | 544,4277 | 17,7706 | 169,1216 | |2,776| |
Приложение 2
В таблице приведены значения критерия Дарбина-Уотсона для уровня значимости 5% (m - число независимых переменных уравнения регрессии).
| Число наблюдений (n) | m = 1 | m = 2 | m = 3 | m = 4 | m = 5 | ||||||||
| d1 | d2 | d1 | d2 | d1 | d2 | d1 | d2 | d1 | d2 | ||||
| 15203050100 | 1,081,201,351,501,65 | 1,361,411,491,591,69 | 0,951,101,281,461,63 | 1,541,541,571,631,72 | 0,821,001,211,421,61 | 1,751,681,651,671,74 | 0,690,901,141,381,59 | 1,971,831,741,721,76 | 0,560,791,071,341,57 | 2,211,991,831,471,78 | |||
Приложение 3
Критические границы отношения R/S
| Объем выборки (n) | Нижние границы | Верхние границы | ||||||||||
| Вероятность ошибки | ||||||||||||
| 0,000 | 0,005 | 0,01 | 0,025 | 0,05 | 0,10 | 0,10 | 0,05 | 0,025 | 0,01 | 0,005 | 0,000 | |
| 34567891011121314151617181920 | 1,7321,7321,8261,8261,8211,8211,8971,8971,9151,9151,9271,9271,9361,9361,9441,9441,9491,949 | 1,7351,831,982,112,222,312,392,462,532,592,642,702,742,792,832,872,902,94 | 1,7371,872,022,152,262,352,442,512,582,642,702,752,802,842,882,922,962,99 | 1,7451,932,092,222,332,432,512,592,662,722,782,832,882,932,973,013,053,09 | 1,7581,982,152,282,402,502,592,672,742,802,862,922,973,013,063,103,143,18 | 1,7822,042,222,372,492,592,682,762,842,902,963,023,073,123,173,213,253,29 | 1,9972,4092,7122,9493,1433,3083,4493,573,683,783,873,954,024,094,154,214,274,32 | 1,9992,4292,7533,0123,2223,3993,5523,6853,803,914,004,094,174,244,314,374,434,49 | 2,0002,4392,7823,0563,2823,4713,6343,7773,9034,024,124,214,294,374,444,514,574,63 | 2,0002,4452,8033,0953,3383,5433,7203,8754,0124,1344,2444,344,444,524,604,674,744,80 | 2,0002,4472,8133,1153,3693,5853,7723,9354,0794,2084,3254,4314,534,624,704,784,854,91 | 2,0002,4492,8283,1624,4653,7424,0002,2434,4724,6904,8995,0995,2925,4775,6575,8316,0006,164 |
Приложение 4
Таблица значений функции распределения Стьюдента (для интервальных оценок)
| Значение доверительной вероятности | |||||||||||
| 0.9 | 0.91 | 0.92 | 0.93 | 0.94 | 0.95 | 0.96 | 0.97 | 0.98 | 0.99 | ||
Степени свободы |
1 | 6.314 | 7.026 | 7.916 | 9.058 | 10.579 | 12.706 | 15.894 | 21.205 | 31.821 | 63.656 |
| 2 | 2.920 | 3.104 | 3.320 | 3.578 | 3.896 | 4.303 | 4.849 | 5.643 | 6.965 | 9.925 | |
| 3 | 2.353 | 2.471 | 2.605 | 2.763 | 2.951 | 3.182 | 3.482 | 3.896 | 4.541 | 5.841 | |
| 4 | 2.132 | 2.226 | 2.333 | 2.456 | 2.601 | 2.776 | 2.999 | 3.298 | 3.747 | 4.604 | |
| 5 | 2.015 | 2.098 | 2.191 | 2.297 | 2.422 | 2.571 | 2.757 | 3.003 | 3.365 | 4.032 | |
| 6 | 1.943 | 2.019 | 2.104 | 2.201 | 2.313 | 2.447 | 2.612 | 2.829 | 3.143 | 3.707 | |
| 7 | 1.895 | 1.966 | 2.046 | 2.136 | 2.241 | 2.365 | 2.517 | 2.715 | 2.998 | 3.499 | |
| 8 | 1.860 | 1.928 | 2.004 | 2.090 | 2.189 | 2.306 | 2.449 | 2.634 | 2.896 | 3.355 | |
| 9 | 1.833 | 1.899 | 1.973 | 2.055 | 2.150 | 2.262 | 2.398 | 2.574 | 2.821 | 3.250 | |
| 10 | 1.812 | 1.877 | 1.948 | 2.028 | 2.120 | 2.228 | 2.359 | 2.527 | 2.764 | 3.169 | |
| 11 | 1.796 | 1.859 | 1.928 | 2.007 | 2.096 | 2.201 | 2.328 | 2.491 | 2.718 | 3.106 | |
| 12 | 1.782 | 1.844 | 1.912 | 1.989 | 2.076 | 2.179 | 2.303 | 2.461 | 2.681 | 3.055 | |
| 13 | 1.771 | 1.832 | 1.899 | 1.974 | 2.060 | 2.160 | 2.282 | 2.436 | 2.650 | 3.012 | |
| 14 | 1.761 | 1.821 | 1.887 | 1.962 | 2.046 | 2.145 | 2.264 | 2.415 | 2.624 | 2.977 | |
| 15 | 1.753 | 1.812 | 1.878 | 1.951 | 2.034 | 2.131 | 2.249 | 2.397 | 2.602 | 2.947 | |
| 16 | 1.746 | 1.805 | 1.869 | 1.942 | 2.024 | 2.120 | 2.235 | 2.382 | 2.583 | 2.921 | |
| 17 | 1.740 | 1.798 | 1.862 | 1.934 | 2.015 | 2.110 | 2.224 | 2.368 | 2.567 | 2.898 | |
| 18 | 1.734 | 1.792 | 1.855 | 1.926 | 2.007 | 2.101 | 2.214 | 2.356 | 2.552 | 2.878 | |
| 19 | 1.729 | 1.786 | 1.850 | 1.920 | 2.000 | 2.093 | 2.205 | 2.346 | 2.539 | 2.861 | |
| 20 | 1.725 | 1.782 | 1.844 | 1.914 | 1.994 | 2.086 | 2.197 | 2.336 | 2.528 | 2.845 | |
| 21 | 1.721 | 1.777 | 1.840 | 1.909 | 1.988 | 2.080 | 2.189 | 2.328 | 2.518 | 2.831 | |
Приложение 5
Приложение 6
| № | Страны | Х1 | Х3 | Х6 | Х8 | Х9 | У | |||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 1 | Россия | 55 | 30 | 20,4 | 28 | 124 | 84,98 | 61,1244 | 23,8556 | 0,2807 |
| 2 | Австралия | 100 | 47 | 71,4 | 121 | 87 | 30,56 | 37,1498 | -6,5898 | -0,2156 |
| 3 | Австрия | 93 | 37 | 78,7 | 146 | 74 | 38,42 | 27,7670 | 10,653 | 0,2773 |
| 4 | Азербайджан | 20 | 12,4 | 12,1 | 52 | 141 | 60,34 | 59,8539 | 0,4861 | 0,0081 |
| 5 | Армения | 20 | 4,3 | 10,9 | 72 | 134 | 60,22 | 56,7572 | 3,4628 | 0,0575 |
| 6 | Белоруссия | 72 | 28 | 20,4 | 38 | 120 | 60,79 | 61,0272 | -0,2372 | -0,0039 |
| 7 | Бельгия | 85 | 48 | 79,7 | 83 | 72 | 29,82 | 30,3919 | -0,5719 | -0,0192 |
| 8 | Болгария | 65 | 18 | 17,3 | 92 | 156 | 70,57 | 63,9434 | 6,6266 | 0,0939 |
| 9 | Великобритания | 67 | 39 | 69,7 | 91 | 91 | 34,51 | 34,2298 | 0,2802 | 0,0081 |
| 10 | Венгрия | 73 | 40 | 24,5 | 73 | 106 | 64,73 | 60,0524 | 4,6776 | 0,0723 |
| 11 | Германия | 88 | 35 | 76,2 | 138 | 73 | 36,63 | 28,0102 | 8,6198 | 0,2353 |
| 12 | Греция | 83 | 24 | 44,4 | 99 | 108 | 32,84 | 46,083 | -13,243 | -0,4033 |
| 13 | Грузия | 21 | 36 | 11,3 | 55 | 140 | 62,64 | 67,1154 | -4,4754 | -0,0714 |
| 14 | Дания | 98 | 38 | 79,2 | 89 | 77 | 34,07 | 29,3072 | 4,76277 | 0,1398 |
| 15 | Ирландия | 99 | 31 | 57 | 87 | 102 | 39,27 | 42,2326 | -2,9626 | -0,0754 |
| 16 | Испания | 89 | 26 | 54,8 | 103 | 72 | 28,46 | 36,3877 | -7,9277 | -0,2786 |
| 17 | Италия | 84 | 27 | 72,1 | 169 | 118 | 30,27 | 33,8748 | -3,6048 | -0,1191 |
| 18 | Казахстан | 61 | 19,2 | 13,4 | 10 | 191 | 69,04 | 72,2562 | -3,2162 | -0,0466 |
| 19 | Канада | 98 | 44 | 79,9 | 123 | 77 | 25,42 | 30,3257 | -4,9057 | -0,193 |
| 20 | Киргизия | 46 | 23,5 | 11,2 | 20 | 134 | 53,13 | 64,7713 | -11,6413 | -0,2191 |
| 21 | Нидерланды | 86 | 37 | 72,4 | 176 | 59 | 28,00 | 27,7780 | 0,222 | 0,0079 |
| 22 | Португалия | 73 | 27 | 48,6 | 150 | 83 | 38,79 | 39,7452 | -0,9552 | -0,0246 |
| 23 | США | 115 | 29 | 100 | 99 | 103 | 32,04 | 21,2971 | 10,7429 | 0,3353 |
| 24 | Финляндия | 62 | 36 | 63,9 | 82 | 94 | 38,58 | 36,4471 | 2,1329 | 0,0553 |
| 25 | Франция | 91 | 36 | 77,5 | 84 | 85 | 18,51 | 30,3382 | -11,8282 | -0,639 |
| 26 | Чехия | 82 | 45 | 34,7 | 65 | 114 | 57,62 | 58,3873 | -0,7673 | -0,0133 |
| 27 | Япония | 40 | 20 | 83,5 | 60 | 119 | 20,80 | 24,3958 | -3,5958 | -0,1729 |
| ∑ | 1966 | 837,4 | 1385,2 | 2405 | 2854 | 1181,05 | 1181,05 | 0 | |4,0665| | |
| 72,81 | 31,01 | 51,3 | 89,07 | 105,7 | 43,74 |
Приложение 7
| ВЫВОД ОСТАТКА | |||
| Наблюдение | Предсказанное Y | Остатки | Стандартные остатки |
| 1 | 61,12437668 | 23,85562332 | 3,016807918 |
| 2 | 37,14984362 | -6,589843625 | -0,83335875 |
| 3 | 27,76702963 | 10,65297037 | 1,347186151 |
| 4 | 59,85389286 | 0,486107145 | 0,061473635 |
| 5 | 56,75723936 | 3,46276064 | 0,437904455 |
| 6 | 61,02722122 | -0,237221218 | -0,029999252 |
| 7 | 30,3918804 | -0,571880402 | -0,072320614 |
| 8 | 63,94341526 | 6,626584737 | 0,838005071 |
| 9 | 34,22980347 | 0,280196529 | 0,035433956 |
| 10 | 60,05238208 | 4,67761792 | 0,59153662 |
| 11 | 28,01019093 | 8,619809067 | 1,090070375 |
| 12 | 46,08296956 | -13,24296956 | -1,674720249 |
| 13 | 67,11544881 | -4,47544881 | -0,565970095 |
| 14 | 29,30723012 | 4,762769875 | 0,602305028 |
| 15 | 42,23264038 | -2,962640379 | -0,374658706 |
| 16 | 36,38774388 | -7,927743882 | -1,002551063 |
| 17 | 33,87478691 | -3,604786915 | -0,455865251 |
| 18 | 72,25617196 | -3,216171959 | -0,406720583 |
| 19 | 30,32568691 | -4,905686906 | -0,62037847 |
| 20 | 64,77131443 | -11,64131443 | -1,472173209 |
| 21 | 27,77801216 | 0,22198784 | 0,028072822 |
| 22 | 39,74521202 | -0,955212022 | -0,120797145 |
| 23 | 21,29706536 | 10,74293464 | 1,35856313 |
| 24 | 36,44711056 | 2,13288944 | 0,269727505 |
| 25 | 30,33822718 | -11,82822718 | -1,495810398 |
| 26 | 58,38731137 | -0,767311368 | -0,097035025 |
| 27 | 24,39579286 | -3,595792864 | -0,454727853 |
Приложение 8
| ВЫВОД ИТОГОВ | ||||||||
| Регрессионная статистика | ||||||||
| Множественный R | 0,758496844 | |||||||
| R-квадрат | 0,575317462 | |||||||
| Нормированный R-квадрат | 0,498102455 | |||||||
| Стандартная ошибка | 12,49675211 | |||||||
| Наблюдения | 27 | |||||||
| Дисперсионный анализ | ||||||||
| df | SS | MS | F | Значимость F | ||||
| Регрессия | 4 | 4654,361827 | 1163,590457 | 7,450850349 | 0,000593913 | |||
| Остаток | 22 | 3435,713892 | 156,1688133 | |||||
| Итого | 26 | 8090,075719 | ||||||
| Коэффи-циенты | Стандартная ошибка | t-статистика | P-Значение | Нижние 95% | Верхние 95% | Нижние 95,0% | Верхние 95,0% | |
| Y-пересечение | 11,37891037 | 26,90148347 | 0,422984494 | 0,676412608 | -44,41135143 | 67,16917217 | -44,41135143 | 67,16917217 |
| Переменная X 1 | -0,140477614 | 0,136338345 | -1,03036027 | 0,314036187 | -0,423226035 | 0,142270807 | -0,423226035 | 0,142270807 |
| Переменная X 2 | 0,334073329 | 0,330603312 | 1,010496014 | 0,323243144 | -0,351555972 | 1,01970263 | -0,351555972 | 1,01970263 |
| Переменная X 3 | -0,059094847 | 0,084157252 | -0,702195542 | 0,489920557 | -0,233626304 | 0,11543661 | -0,233626304 | 0,11543661 |
| Переменная X 4 | 0,35471917 | 0,138588434 | 2,559514953 | 0,017874673 | 0,06730435 | 0,64213399 | 0,06730435 | 0,64213399 |
Приложение 9
Приложение 10
Приложение 11
Приложение 12
| № | Страны | Х9 | Х92 | У | ||||
| 1 | Россия | 124 | 15376 | 84,98 | 51,28526 | 33,69474 | 1135,016 | 0,3965 |
| 2 | Австралия | 87 | 7569 | 30,56 | 36,03197 | -5,47197 | 29,9209 | -0,179 |
| 3 | Австрия | 74 | 5476 | 38,42 | 30,67271 | 7,747288 | 60,0625 | 0,202 |
| 4 | Азербайджан | 141 | 19881 | 60,34 | 58,29352 | 2,046478 | 4,2025 | 0,334 |
| 5 | Армения | 134 | 17956 | 60,22 | 55,40777 | 4,812234 | 23,1361 | 0,08 |
| 6 | Белоруссия | 120 | 14400 | 60,79 | 49,63625 | 11,15375 | 124,3225 | 0,1835 |
| 7 | Бельгия | 72 | 5184 | 29,82 | 29,84821 | -0,02821 | 0,0009 | -0,001 |
| 8 | Болгария | 156 | 24336 | 70,57 | 64,47729 | 6,092714 | 37,0881 | 0,0863 |
| 9 | Великобритания | 91 | 8281 | 34,51 | 37,68098 | -3,17098 | 10,0489 | -0,092 |
| 10 | Венгрия | 106 | 11236 | 64,73 | 43,86474 | 20,86526 | 435,5569 | 0,322 |
| 11 | Германия | 73 | 5329 | 36,63 | 30,26046 | 6,369538 | 40,5769 | 0,1739 |
| 12 | Греция | 108 | 11664 | 32,84 | 44,68924 | -11,8492 | 140,4035 | -0,361 |
| 13 | Грузия | 140 | 19600 | 62,64 | 57,88127 | 4,758729 | 22,6576 | 0,076 |
| 14 | Дания | 77 | 5929 | 34,07 | 31,90947 | 2,160535 | 4,6656 | 0,0634 |
| 15 | Ирландия | 102 | 10404 | 39,27 | 42,21574 | -2,94574 | 8,7025 | -0,075 |
| 16 | Испания | 72 | 5184 | 28,46 | 29,84821 | -1,38821 | 1,9321 | -0,049 |
| 17 | Италия | 118 | 13924 | 30,27 | 48,81175 | -18,5418 | 343,7316 | -0,613 |
| 18 | Казахстан | 191 | 36481 | 69,04 | 78,90607 | -9,86607 | 97,4169 | -0,143 |
| 19 | Канада | 77 | 5929 | 25,42 | 31,90947 | -6,48947 | 42,1201 | -0,255 |
| 20 | Киргизия | 134 | 17956 | 53,13 | 55,40777 | -2,27777 | 5,1984 | -0,043 |
| 21 | Нидерланды | 59 | 3481 | 28 | 24,48895 | 3,511051 | 12,3201 | 0,1254 |
| 22 | Португалия | 83 | 6889 | 38,79 | 34,38297 | 4,407029 | 19,4481 | 0,1136 |
| 23 | США | 103 | 10609 | 32,04 | 42,62799 | -10,588 | 112,1481 | -0,33 |
| 24 | Финляндия | 94 | 8836 | 38,58 | 38,91773 | -0,33773 | 0,1156 | -0,009 |
| 25 | Франция | 85 | 7225 | 18,51 | 35,20747 | -16,6975 | 278,89 | -0,902 |
| 26 | Чехия | 114 | 12996 | 57,62 | 47,16275 | 10,45725 | 109,4116 | 0,1815 |
| 27 | Япония | 119 | 14161 | 20,8 | 49,224 | -28,424 | 807,6964 | -1,367 |
| 326292 | 39,0679 | |6,76| |
Приложение 13
| № | Дата, t |
Объем продаж, |
( |
|||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 1 | 1/1/93 | 178 | 31684 | - | - | -17 | 289 | 200,0143 | -22,0143 | 484,4401 |
| 2 | 1/2/93 | 185 | 34225 | 32930 | 186 | -16 | 256 | 202,037 | -17,037 | 290,3616 |
| 3 | 1/3/93 | 196 | 38416 | 36260 | 189 | -15 | 225 | 204,0597 | -8,05966 | 64,9636 |
| 4 | 1/4/93 | 187 | 34969 | 36652 | 193 | -14 | 196 | 206,0824 | -19,0824 | 364,0464 |
| 5 | 1/5/93 | 197 | 38809 | 36839 | 210 | -13 | 169 | 208,105 | -11,105 | 123,4321 |
| 6 | 1/6/93 | 246 | 60516 | 48462 | 225 | -12 | 144 | 210,1277 | 35,87227 | 1286,6569 |
| 7 | 1/7/93 | 231 | 53361 | 56826 | 240 | -11 | 121 | 212,1504 | 18,84958 | 355,3225 |
| 8 | 1/8/93 | 244 | 59536 | 56364 | 231 | -10 | 100 | 214,1731 | 29,82689 | 889,8289 |
| 9 | 1/9/93 | 219 | 47961 | 53436 | 221 | -9 | 81 | 216,1958 | 2,804202 | 7,84 |
| 10 | 1/10/93 | 199 | 39601 | 43581 | 202 | -8 | 64 | 218,2185 | -19,2185 | 369,4084 |
| 11 | 1/11/93 | 187 | 34969 | 37213 | 198 | -7 | 49 | 220,2412 | -33,2412 | 1104,8976 |
| 12 | 1/12/93 | 208 | 43264 | 38896 | 201 | -6 | 36 | 222,2639 | -14,2639 | 203,3476 |
| 13 | 1/1/94 | 208 | 43264 | 43264 | 213 | -5 | 25 | 224,2866 | -16,2866 | 265,3641 |
| 14 | 1/2/94 | 223 | 49729 | 46384 | 228 | -4 | 16 | 226,3092 | -3,30924 | 10,9561 |
| 15 | 1/3/94 | 254 | 64516 | 56642 | 240 | -3 | 9 | 228,3319 | 25,66807 | 658,9489 |
| 16 | 1/4/94 | 243 | 59049 | 61722 | 247 | -2 | 4 | 230,3546 | 12,64538 | 160,0225 |
| 17 | 1/5/94 | 243 | 59049 | 59049 | 247 | -1 | 1 | 232,3773 | 10,62269 | 112,7844 |
| 18 | 1/6/94 | 255 | 65025 | 61965 | 263 | 0 | 0 | 234,4 | 20,6 | 424,36 |
| 19 | 1/7/94 | 292 | 85264 | 74460 | 278 | 1 | 1 | 236,4227 | 55,57731 | 3089,1364 |
| 20 | 1/8/94 | 288 | 82944 | 84096 | 281 | 2 | 4 | 238,4454 | 49,55462 | 2455,2025 |
| 21 | 1/9/94 | 262 | 68644 | 75456 | 261 | 3 | 9 | 240,4681 | 21,53193 | 463,5409 |
| 22 | 1/10/94 | 234 | 54756 | 61308 | 233 | 4 | 16 | 242,4908 | -8,49076 | 72,0801 |
| 23 | 1/11/94 | 204 | 41616 | 47736 | 219 | 5 | 25 | 244,5134 | -40,5134 | 1641,0601 |
| 24 | 1/12/94 | 218 | 47524 | 44472 | 217 | 6 | 36 | 246,5361 | -28,5361 | 814,5316 |
| 25 | 1/1/95 | 230 | 52900 | 50140 | 215 | 7 | 49 | 248,5588 | -18,5588 | 344,4736 |
| 26 | 1/2/95 | 197 | 38809 | 45310 | 230 | 8 | 64 | 250,5815 | -53,5815 | 2870,8164 |
| 27 | 1/3/95 | 263 | 69169 | 51811 | 232 | 9 | 81 | 252,6042 | 10,3958 | 108,16 |
| 28 | 1/4/95 | 235 | 55225 | 61805 | 253 | 10 | 100 | 254,6269 | -19,6269 | 385,3369 |
| 29 | 1/5/95 | 262 | 68644 | 61570 | 261 | 11 | 121 | 256,6496 | 5,35042 | 28,6225 |
| 30 | 1/6/95 | 285 | 81225 | 74670 | 284 | 12 | 144 | 258,6723 | 26,32773 | 693,2689 |
| 31 | 1/7/95 | 305 | 93025 | 86925 | 302 | 13 | 169 | 260,695 | 44,30504 | 1962,49 |
| 32 | 1/8/95 | 316 | 99856 | 96380 | 298 | 14 | 196 | 262,7176 | 53,28235 | 2838,7584 |
| 33 | 1/9/95 | 273 | 74529 | 86268 | 274 | 15 | 225 | 264,7403 | 8,259664 | 68,2276 |
| 34 | 1/10/95 | 234 | 54756 | 63882 | 237 | 16 | 256 | 266,763 | -32,763 | 1073,2176 |
| 35 | 1/11/95 | 203 | 41209 | 47502 | - | 17 | 289 | 268,7857 | -65,7857 | 4328,3241 |
| 630 | 8204 | 1920276 | 3570 | 8204 | 0 | 30414,23 |
Приложение 14
| ВЫВОД ИТОГОВ | ||||||||
| Регрессионная статистика | ||||||||
| Множественный R | 0,569585 | |||||||
| R-квадрат | 0,324427 | |||||||
| Нормированный R-квадрат | 0,303955 | |||||||
| Стандартная ошибка | 30,35875 | |||||||
| Наблюдения | 35 | |||||||
| Дисперсионный анализ | ||||||||
| df | SS | MS | F | Значимость F | ||||
| Регрессия | 1 | 14605,84 | 14605,84 | 15,84743 | 0,000355 | |||
| Остаток | 33 | 30414,56 | 921,6534 | |||||
| Итого | 34 | 45020,4 | ||||||
| Коэффициенты | Стандартная ошибка | t-статистика | P-Значение | Нижние 95% | Верхние 95% | Нижние 95,0% | Верхние 95,0% | |
| Y-пересечение | 197,9916 | 10,48708 | 18,87958 | 2,96E-19 | 176,6555 | 219,3277 | 176,6555 | 219,3277 |
| Переменная X 1 | 2,022689 | 0,508101 | 3,980883 | 0,000355 | 0,988951 | 3,056428 | 0,988951 | 3,056428 |
| ВЫВОД ОСТАТКА | ||||||||
| Наблюдение | ПредсказанноеY | Остатки | ||||||
| 1 | 200,0143 | -22,0143 | ||||||
| 2 | 202,037 | -17,037 | ||||||
| 3 | 204,0597 | -8,05966 | ||||||
| 4 | 206,0824 | -19,0824 | ||||||
| 5 | 208,105 | -11,105 | ||||||
| 6 | 210,1277 | 35,87227 | ||||||
| 7 | 212,1504 | 18,84958 | ||||||
| 8 | 214,1731 | 29,82689 | ||||||
| 9 | 216,1958 | 2,804202 | ||||||
| 10 | 218,2185 | -19,2185 | ||||||
| 11 | 220,2412 | -33,2412 | ||||||
| 12 | 222,2639 | -14,2639 | ||||||
| 13 | 224,2866 | -16,2866 | ||||||
| 14 | 226,3092 | -3,30924 | ||||||
| 15 | 228,3319 | 25,66807 | ||||||
| 16 | 230,3546 | 12,64538 | ||||||
| 17 | 232,3773 | 10,62269 | ||||||
| 18 | 234,4 | 20,6 | ||||||
| 19 | 236,4227 | 55,57731 | ||||||
| 20 | 238,4454 | 49,55462 | ||||||
| 21 | 240,4681 | 21,53193 | ||||||
| 22 | 242,4908 | -8,49076 | ||||||
| 23 | 244,5134 | -40,5134 | ||||||
| 24 | 246,5361 | -28,5361 | ||||||
| 25 | 248,5588 | -18,5588 | ||||||
| 26 | 250,5815 | -53,5815 | ||||||
| 27 | 252,6042 | 10,3958 | ||||||
| 28 | 254,6269 | -19,6269 | ||||||
| 29 | 256,6496 | 5,35042 | ||||||
| 30 | 258,6723 | 26,32773 | ||||||
| 31 | 260,695 | 44,30504 | ||||||
| 32 | 262,7176 | 53,28235 | ||||||
| 33 | 264,7403 | 8,259664 | ||||||
| 34 | 266,763 | -32,763 | ||||||
| 35 | 268,7857 | -65,7857 | ||||||
Похожие рефераты:
Автоматизированный априорный анализ статистической совокупности в среде MS Excel
Статистические методы изучения цен и инфляции
Статистический пакет STATISTIKA
Экономическое планирование методами математической статистики
Демографическая ситуация в Республике Бурятия
Анализ и обобщение статистических данных экономики Республики Калмыкия
Билеты на государственный аттестационный экзамен по специальности Информационные Системы
Использование возможностей Microsoft Excel в решении производственных задач