| Скачать .docx |
Реферат: Метод Монте-Карло
ПЛАН
1. Теоретическая часть
Метод Монте-Карло
2. Практическая часть
Задача 2
Задача 3
1. Теоретическая часть
Метод Монте-Карло
Датой рождения метода Монте-Карло принято считать 1949 г., когда американские ученые Н.Метрополис и С.Улам опубликовали статью «Метод Монте-Карло», в которой систематически его изложили. Название метода связано с названием города Монте-Карло, где в игорных домах (казино) играют в рулетку — одно из простейших устройств для получения случайных чисел, на использовании которых основан этот метод.
Специальный метод изучения поведения заданной статистики при проведении многократных повторных выборок, существенно использующий вычислительные возможности современных компьютеров. При проведении анализа по методу Монте-Карло компьютер использует процедуру генерации псевдослучайных чисел для имитации данных из изучаемой генеральной совокупности. Процедура анализа по методу Монте-Карло модуля Моделирование структурными уравнениями строит выборки из генеральной совокупности в соответствии с указаниями пользователя, а затем производит следующие действия:
Для каждого повторения по методу Монте-Карло :
1. Имитирует случайную выборку из генеральной совокупности,
2. Проводит анализ выборки,
3. Сохраняет результаты.
После большого числа повторений, сохраненные результаты хорошо имитирует реальное распределение выборочной статистики. Метод Монте-Карло позволяет получить информацию о выборочном распределении в случаях, когда обычная теория выборочных распределений оказывается бессильной.
ЭВМ позволяют легко получать так называемые псевдослучайные числа (при решении задач их применяют вместо случайных чисел); это привело к широкому внедрению метода во многие области науки и техники (статистическая физика, теория массового обслуживания, теория игр и др.). Метод Монте-Карло используют для вычисления интегралов, в особенности многомерных, для решения систем алгебраических уравнений высокого порядка, для исследования различного рода сложных систем (автоматического управления, экономических, биологических и т.д.).
Сущность метода Монте-Карло состоит в следующем: требуется найти значение а некоторой изучаемой величины. Для этого выбирают такую случайную величину X , математическое ожидание которой а:
![]() (1)
(1)
Практически же поступают так: производят п испытаний; в результате которых получают п возможных значений X , вычисляют их среднее арифметическое
![]() (2)
(2)
и принимают х в качестве оценки (приближенного значения) а * искомого числа а:
![]() (3)
(3)
Поскольку метод Монте-Карло требует проведения большого числа испытаний, его часто называют методом статистических испытаний. Теория этого метода указывает, как наиболее целесообразно выбрать случайную величину X , как найти ее возможные значения. В частности, разрабатываются способы уменьшения дисперсии используемых случайных величин, в результате чего уменьшается ошибка, допускаемая при замене искомого математического ожидания а его оценкой а *.
Отыскание возможных значений случайной величины Х (моделирование) называют «разыгрыванием случайной величины». Изложим лишь некоторые способы разыгрывания случайных величин и укажем, как оценить допускаемую при этом ошибку.
Оценка погрешности метода Монте-Карло
Пусть для получения оценки а *
математического ожидания а
случайной величины Х
было произведено п
независимых испытаний (разыграно п
возможных значений Х) и по ним была найдена выборочная средняя  ,
которая принята в качестве искомой оценки: а*
=
.
Ясно, что если повторить опыт, то будут получены другие возможные значения X
,
следовательно, другая средняя, а значит, и другая оценка а*. Уже отсюда следует, что получить точную оценку математического ожидания невозможно. Естественно, возникает вопрос о величине допускаемой ошибки. Ограничимся отысканием лишь верхней границы допускаемой ошибки с заданной вероятностью (надежностью)
,
которая принята в качестве искомой оценки: а*
=
.
Ясно, что если повторить опыт, то будут получены другие возможные значения X
,
следовательно, другая средняя, а значит, и другая оценка а*. Уже отсюда следует, что получить точную оценку математического ожидания невозможно. Естественно, возникает вопрос о величине допускаемой ошибки. Ограничимся отысканием лишь верхней границы допускаемой ошибки с заданной вероятностью (надежностью)  :
:
![]() (4)
(4)
Интересующая нас верхняя граница ошибки  есть не что иное, как «точность оценки» математического ожидания по выборочной средней при помощи доверительных интервалов. Поэтому воспользуемся результатами, полученными ранее, и рассмотрим следующие три случая.
есть не что иное, как «точность оценки» математического ожидания по выборочной средней при помощи доверительных интервалов. Поэтому воспользуемся результатами, полученными ранее, и рассмотрим следующие три случая.
1. Случайная величина Х
распределена нормально и ее среднее квадратическое отклонение  -
известно. В этом случае с надежностью у
верхняя граница ошибки
-
известно. В этом случае с надежностью у
верхняя граница ошибки
![]() (5)
(5)
где п
— число испытаний (разыгранных значений X
);
t
—
значение аргумента функции Лапласа, при котором Ф(t) ==  /2,
/2,  — известное среднее квадратическое отклонение X
.
— известное среднее квадратическое отклонение X
.
2. Случайная величина Х
распределена нормально, причем ее среднее квадратическое отклонение  неизвестно. В этом случае с надежностью
неизвестно. В этом случае с надежностью  верхняя граница ошибки
верхняя граница ошибки
![]() (6)
(6)
где п —
число испытаний; s
—
«исправленное» среднее квадратическое отклонение, t
находят по таблице значений ty
== t
{
 ,
n
}.
,
n
}.
3.
Случайная величина Х
распределена по закону, отличному от нормального. В этом случае при достаточно большом числе испытаний (n > 30) с надежностью, приближенно равной  , верхняя граница ошибки может быть вычислена по формуле (5), если среднее квадратическое отклонение
, верхняя граница ошибки может быть вычислена по формуле (5), если среднее квадратическое отклонение  случайной величины Х
известно; если же
-неизвестно, то можно подставить в формулу (5) его оценку s
—
«исправленное» среднее квадратическое отклонение либо воспользоваться формулой (6). Заметим, что чем больше п,
тем меньше различие между результатами, которые дают обе формулы. Это объясняется тем, что при п
—>
случайной величины Х
известно; если же
-неизвестно, то можно подставить в формулу (5) его оценку s
—
«исправленное» среднее квадратическое отклонение либо воспользоваться формулой (6). Заметим, что чем больше п,
тем меньше различие между результатами, которые дают обе формулы. Это объясняется тем, что при п
—>  распределение Стьюдента стремится к нормальному. В частности, при п=--100,
распределение Стьюдента стремится к нормальному. В частности, при п=--100,  =0,95 верхняя граница ошибки равна 0,098 по формуле (5) и 0,099 по формуле (6). Как видим, результаты различаются незначительно.
=0,95 верхняя граница ошибки равна 0,098 по формуле (5) и 0,099 по формуле (6). Как видим, результаты различаются незначительно.
Замечание.
Для того чтобы найти наименьшее число испытаний, которые обеспечат наперед заданную верхнюю границу ошибки  ,
надо выразить п
из формул (5) и (6):
,
надо выразить п
из формул (5) и (6):
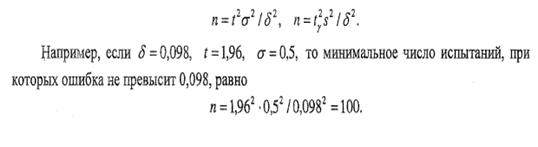
2. Практическая часть
Задача 2
Исходя из статистических данных о деятельности торгового предприятия, с помощью регрессионной зависимости вида
Y = a *Х + b
установить связь между потерями на рекламу (X) и объемом реализации (Y).
2.1. Вычислить параметры зависимости a и b методом наименьших квадратов.
2.2. Оценить соответствие построенной зависимости статистическим данным.
| Вариант 7 |
x |
109 |
107 |
108 |
111 |
106 |
105 |
104 |
| y |
234 |
235 |
236 |
237 |
238 |
239 |
240 |
Выполнение задания
Для выполнения заданий используем пакет электронных таблиц Excel.
2.1 Блок исходных данных формируется в первых двух столбцах (A3:B9 ).
2.2
Вводится гипотеза, что между фактором Х и показателем Y
существует линейная стохастическая зависимость ![]() = a · X +b
= a · X +b
Оценки параметров a и b парной регрессии вычисляются по формулам
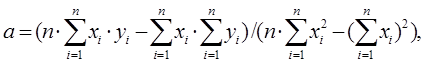
![]()
За блоком исходных данных находится блок промежуточных расчетов.
Для нахождения произведения ![]() в ячейку C3
вводится формула =A3·B3
.
Далее копируем полученную формулу в другие ячейки столбца C
. Значения
в ячейку C3
вводится формула =A3·B3
.
Далее копируем полученную формулу в другие ячейки столбца C
. Значения ![]() вычисляем в столбце D.
вычисляем в столбце D.
Для определения сумм столбцов используем кнопку автосуммирования на панели инструментов ∑. После установления курсора на ячейку A10 нажимаем ∑ на панели инструментов, выделяем диапазон ячеек А3:А9, нажимаем Enter. Введенная формула копируется в необходимые ячейки 10-ой строки. Средние значения X , Y вычисляются в ячейках D11, D12 с использованием встроенной статистической функции СРЗНАЧ ():
=СРЗНАЧ(A3:A9) и =СРЗНАЧ(B3:B9).
В ячейки В12, В13 вводятся формулы для определения оценок параметров соответственно a и b .
=(B11*C10-B10*A10)/(B11*D10-A10^2) – для параметра а ;
=D12-B12*D11 – для параметра b .
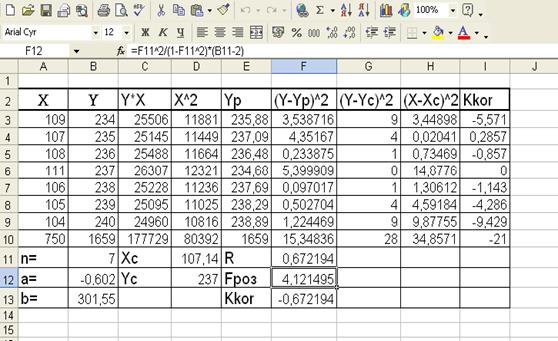
а=-0,602, b=301,55,
уравнение регрессии:
Y = -0,602× Х + 301,55
2.3.
Для вычисления расчетных значений ![]() (і
=
(і
=![]() ) в ячейку E3
вводим формулу
) в ячейку E3
вводим формулу ![]() с абсолютными ссылками координат-параметров a
и относительной ссылкой координаты
с абсолютными ссылками координат-параметров a
и относительной ссылкой координаты ![]() . Полученную формулу в ячейке E3
копируем в блок E4:E9
В ячейке E10
будет находиться сумма блока E3:E9
. Поскольку математическое ожидание отклонения фактических данных от расчетных равняется нулю, то при правильном выполнении расчетов значения ячеек B
10
и E10
будут совпадать.
. Полученную формулу в ячейке E3
копируем в блок E4:E9
В ячейке E10
будет находиться сумма блока E3:E9
. Поскольку математическое ожидание отклонения фактических данных от расчетных равняется нулю, то при правильном выполнении расчетов значения ячеек B
10
и E10
будут совпадать.
Для определения адекватности принятой эконометрической модели экспериментальным данным воспользуемся F-критерием Фишера. Расчетное значение критерия Фишера определяется по формуле:
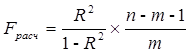
Значение ![]() вычисляем соответственно в блоках F3:F9, G3:G9, H3:H9,
а их суммы в блоке F10:H10.
вычисляем соответственно в блоках F3:F9, G3:G9, H3:H9,
а их суммы в блоке F10:H10.
Значения коэффициента детерминации 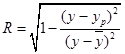 вычисляется в ячейке F11
с использованием встроенной математической функции КОРЕНЬ
.
вычисляется в ячейке F11
с использованием встроенной математической функции КОРЕНЬ
.
Для оценки коэффициента корреляции
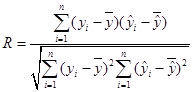
в ячейку I
3
вводим формулу для вычисления значения ![]() и копируется в блок I
4:
I
9.
Сумма блока I
3:
I
9
вычисляется в ячейке I
10.
и копируется в блок I
4:
I
9.
Сумма блока I
3:
I
9
вычисляется в ячейке I
10.
Значения коэффициента корреляции вычисляется в ячейке F13.
Kkor =-0,672194
Расчетное значение критерия Фишера: Fроз = 4,121495
Табличное значение F-критерия для вероятностей P=0,95 и числа степеней свободы
K1 = m = 1,
K2 = n – m – 1 = n – 2 = 7 – 2 = 5 равняется: F(0.95;1;5)= 5,99
Поскольку ![]() , то с надежностью P=0,95 эконометрическую модель можно считать неадекватной экспериментальным данным
. Об этом также говорит невысокое значение коэффициента корреляции Kkor
=-0,672194
, то с надежностью P=0,95 эконометрическую модель можно считать неадекватной экспериментальным данным
. Об этом также говорит невысокое значение коэффициента корреляции Kkor
=-0,672194
Таблица с расчетными данными:
Задача 3
Предприятие имеет 7 филиалов по реализации продукции. Руководству предприятия необходимо, исходя из статистических данных об их деятельность оценить силу зависимости товарооборота (Y) от факторов: объема торговой площади (S), интенсивности потока покупателей (N) и стоимости основных фондов (F). С помощью линейной регрессионной модели вида
![]() ,
,
установить связь между товарооборотом и двумя наиболее существенными факторами.
3.1. Вычислить коэффициенты корреляции между результативным признаком Y и факторами: S, N и F.
3.2. Определить два фактора, которые наиболее влияют на товарооборот Y.
3.3. Вычислить параметры регрессионной модели а , b , с методом наименьших квадратов.
3.4. Оценить соответствие построенной зависимости статистическим данным.
| Вариант 7 |
S, кв.м. |
15 |
23 |
18 |
18 |
19 |
17 |
23 |
| N, чел. |
567 |
568 |
569 |
345 |
234 |
453 |
345 |
|
| F,тис.грн. |
10 |
7 |
11 |
28 |
15 |
10 |
57 |
|
| Y,млн.грн |
0,25 |
0,24 |
0,23 |
0,28 |
0,23 |
0,27 |
0,27 |
Выполнение задания
3.1. Исходные данные факторов размещаем в блоке B 2: D 18 , а показатели в столбце E 2: E 8 .
3.2. В блоке A 13: C 14 используя встроенную функции Excel =КОРРЕЛ() находим коэффициенты корреляции между показателем Y и факторами Х1, Х2, Х3
| Корф. кор.-ции |
||
| Y - X1 |
Y - X2 |
Y - X3 |
| 0,208604 |
-0,60362 |
-0,04747 |
3.3. Как видно из корреляционной матрицы для регрессионной модели можно выбрать две переменные – Х1 и Х2, так как для них значения коэффициента корреляции с показателем близки к 1 и равны 0,208604и -0,60362 соответственно.
3.4.
Допустим, что между показателем Y
и факторами Х1
, Х2
существует линейная зависимость ![]() . Найдем оценки параметров, используя метод наименьших квадратов (в матричных операциях). Запишем систему нормальных уравнений в матричной форме
. Найдем оценки параметров, используя метод наименьших квадратов (в матричных операциях). Запишем систему нормальных уравнений в матричной форме
![]() , где
, где 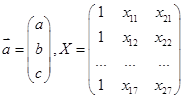
Если помножить матричное уравнение слева на матрицу ![]() , то для оценки параметров вектора
, то для оценки параметров вектора ![]() получим формулу
получим формулу
![]() .
.
Нахождение оценок параметров регрессии :
1. Находим транспонированную матрицу ![]() в блоке E
13:
K
15
по отношению к матрице
в блоке E
13:
K
15
по отношению к матрице ![]() в блоке A
2:
C
8
, используя в категории "Ссылки и массивы" встроенную функцию ТРАНСП
(A
2:
C
8
).
в блоке A
2:
C
8
, используя в категории "Ссылки и массивы" встроенную функцию ТРАНСП
(A
2:
C
8
).
2. Находим произведение матриц ![]() в блоке A
18:
C
20
, используя встроенную математическую функцию МУМНОЖ
(блок данных первой матрицы A
18:
C
20
; блок данных второй матрицы A
2:
C
8
).
в блоке A
18:
C
20
, используя встроенную математическую функцию МУМНОЖ
(блок данных первой матрицы A
18:
C
20
; блок данных второй матрицы A
2:
C
8
).
3. Обратную матрицу ![]() находим в блоке D
18:
F
20
, используя встроенную математическую функцию =МОБР(
A
18:
C
20)
.
находим в блоке D
18:
F
20
, используя встроенную математическую функцию =МОБР(
A
18:
C
20)
.
4. Произведение матриц ![]() находим в блоке H
18:
H
20
, встроенную математическую функцию =МУМНОЖ(E13:K15;E2:E8).
находим в блоке H
18:
H
20
, встроенную математическую функцию =МУМНОЖ(E13:K15;E2:E8).
5. Оценки вектора находим в блоке J 39: J 41 , встроенную математическую функцию =МУМНОЖ(D18:F20;H18:H20).
| [XT ][X]-1 [XT ]Y |
| 0,32512 |
| 0,00040 |
| -0,00005 |
a= 0,00040, b= -0,00005, c= 0,32512.
Уравнение регрессии:
Y = 0,00040X1 + -0,00005X2 + 0,32512
3.5. Проверим адекватность принятой модели экспериментальным данным с помощью критерия Фишера. Расчетные значения Yрасч считаем в столбце F по формуле Yрасч =0,00040Х 1 +-0,00005Х2 +0,32512..
Рассчитываем F-статистику Фишера с m и (n- m- 1) степенями свободы:
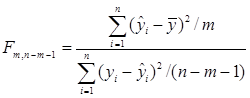
где m — количество факторов, которые вошли в модель; m=2
n – общее количество наблюдений; n=7
В ячейках F 2: F 10 находятся расчетные значения показателя, а в ячейках G 2: G 10 квадраты их отклонений от экспериментальных значений.
В ячейках H 2: H 10 квадраты отклонений от среднего значения.
Расчетное значение Fрасч = 1,19895497
По F- таблице Фишера находим критическое значение Fкр с m и (n-m-1) степенями свободы: Fкрит (0,95;2;4)= 6,94
Расчетное значение критерия 1,19895497 меньше критического, значит с надежностью ![]() можно считать, что принятая математическая модель неадекватна по экспериментальным данным
.
можно считать, что принятая математическая модель неадекватна по экспериментальным данным
.
Таблица с расчетными данными: