| Похожие рефераты | Скачать .docx |
Курсовая работа: Методы Data Mining
Содержание
Что такое Data Mining
Классификация задач Data Mining
Задача классификации и регрессии
Задача поиска ассоциативных правил
Задача кластеризации
Возможности Data Miner вStatistica 8
Средстваанализа STATISTICA Data Miner
Пример работы в Data Minin
Создание отчетов и итогов
Сортировка информации
Анализ цен жилищных участков
Анализ предикторов выживания
Заключение
Что такое Data Mining
Современный компьютерный термин Data Mining переводится как «извлечение информации» или «добыча данных». Нередко наряду с Data Mining встречаются термины Knowledge Discovery («обнаружение знаний») и Data Warehouse («хранилище данных»). Возникновение указанных терминов, которые являются неотъемлемой частью Data Mining, связано с новым витком в развитии средств и методов обработки и хранения данных. Итак, цель Data Mining состоит в выявлении скрытых правил и закономерностей в больших (очень больших) объемах данных.
Дело в том, что человеческий разум сам по себе не приспособлен для восприятия огромных массивов разнородной информации. В среднем человек, за исключением некоторых индивидуумов, не способен улавливать более двух-трех взаимосвязей даже в небольших выборках. Но и традиционная статистика, долгое время претендовавшая на роль основного инструмента анализа данных, так же нередко пасует при решении задач из реальной жизни. Она оперирует усредненными характеристиками выборки, которые часто являются фиктивными величинами (средней платежеспособностью клиента, когда в зависимости от функции риска или функции потерь вам необходимо уметь прогнозировать состоятельность и намерения клиента; средней интенсивностью сигнала, тогда как вам интересны характерные особенности и предпосылки пиков сигнала и т. д.).
Поэтому методы математической статистики оказываются полезными главным образом для проверки заранее сформулированных гипотез, тогда как определение гипотезы иногда бывает достаточно сложной и трудоемкой задачей. Современные технологии Data Mining перерабатывают информацию с целью автоматического поиска шаблонов (паттернов), характерных для каких-либо фрагментов неоднородных многомерных данных. В отличие от оперативной аналитической обработки данных (OLAP) в Data Mining бремя формулировки гипотез и выявления необычных (unexpected) шаблонов переложено с человека на компьютер. Data Mining — это не один, а совокупность большого числа различных методов обнаружения знаний. Выбор метода часто зависит от типа имеющихся данных и от того, какую информацию вы пытаетесь получить. Вот, например, некоторые методы: ассоциация (объединение), классификация, кластеризация, анализ временных рядов и прогнозирование, нейронные сети и т. д.
Рассмотрим свойства обнаруживаемых знаний, данные в определении, более подробно.
Знания должны быть новые, ранее неизвестные. Затраченные усилия на открытие знаний, которые уже известны пользователю, не окупаются. Поэтому ценность представляют именно новые, ранее неизвестные знания.
Знания должны быть нетривиальны. Результаты анализа должны отражать неочевидные, неожиданные закономерности в данных, составляющие так называемые скрытые знания. Результаты, которые могли бы быть получены более простыми способами (например, визуальным просмотром), не оправдывают привлечение мощных методов Data Mining.
Знания должны быть практически полезны. Найденные знания должны быть применимы, в том числе и на новых данных, с достаточно высокой степенью достоверности. Полезность заключается в том, чтобы эти знания могли принести определенную выгоду при их применении.
Знания должны быть доступны для понимания человеку. Найденные закономерности должны быть логически объяснимы, в противном случае существует вероятность, что они являются случайными. Кроме того, обнаруженные знания должны быть представлены в понятном для человека виде.
В Data Mining для представления полученных знаний служат модели. Виды моделей зависят от методов их создания. Наиболее распространенными являются: правила, деревья решений, кластеры и математические функции.
Сфера применения Data Mining ничем не ограничена - Data Mining нужен везде, где имеются какие-либо данные. Опыт многих таких предприятий показывает, что отдача от использования Data Mining может достигать 1000%. Например, известны сообщения об экономическом эффекте, в 10-70 раз превысившем первоначальные затраты от 350 до 750 тыс. дол. Приводятся сведения о проекте в 20 млн. дол., который окупился всего за 4 месяца. Другой пример - годовая экономия 700 тыс. дол. за счет внедрения Data Mining в сети универсамов в Великобритании. Data Mining представляют большую ценность для руководителей и аналитиков в их повседневной деятельности. Деловые люди осознали, что с помощью методов Data Mining они могут получить ощутимые преимущества в конкурентной борьбе.
Классификация задач DataMining
Методы DataMining позволяют решить многие задачи, с которыми сталкивается аналитик. Из них основными являются: классификация, регрессия, поиск ассоциативных правил и кластеризация. Ниже приведено краткое описание основных задач анализа данных.
1) Задача классификации сводится к определению класса объекта по его характеристикам. Необходимо заметить, что в этой задаче множество классов, к которым может быть отнесен объект, заранее известно.
2) Задача регрессии, подобно задаче классификации, позволяет определить по известным характеристикам объекта значение некоторого его параметра. В отличие от задачи классификации значением параметра является не конечное множество классов, а множество действительных чисел.
3) Задача ассоциации. При поиске ассоциативных правил целью является нахождение частых зависимостей (или ассоциаций) между объектами или событиями. Найденные зависимости представляются в виде правил и могут быть использованы как для лучшего понимания природы анализируемых данных, так и для предсказания появления событий.
4) Задача кластеризации заключается в поиске независимых групп (кластеров) и их характеристик во всем множестве анализируемых данных. Решение этой задачи помогает лучше понять данные. Кроме того, группировка однородных объектов позволяет сократить их число, а следовательно, и облегчить анализ.
5) Последовательные шаблоны – установление закономерностей между связанными во времени событиями, т.е. обнаружение зависимости, что если произойдет событие X, то спустя заданное время произойдет событие Y.
6) Анализ отклонений – выявление наиболее нехарактерных шаблонов.
Перечисленные задачи по назначению делятся на описательные и предсказательные.
Описательные (descriptive) задачи уделяют внимание улучшению понимания анализируемых данных. Ключевой момент в таких моделях — легкость и прозрачность результатов для восприятия человеком. Возможно, обнаруженные закономерности будут специфической чертой именно конкретных исследуемых данных и больше нигде не встретятся, но это все равно может быть полезно и потому должно быть известно. К такому виду задач относятся кластеризация и поиск ассоциативных правил.
Решение предсказательных (predictive) задач разбивается на два этапа. На первом этапе на основании набора данных с известными результатами строится модель. На втором этапе она используется для предсказания результатов на основании новых наборов данных. При этом, естественно, требуется, чтобы построенные модели работали максимально точно. К данному виду задач относят задачи классификации и регрессии. Сюда можно отнести и задачу поиска ассоциативных правил, если результаты ее решения могут быть использованы для предсказания появления некоторых событий.
По способам решения задачи разделяют на supervised learning (обучение с учителем) и unsupervised learning (обучение без учителя). Такое название произошло от термина Machine Learning (машинное обучение), часто используемого в англоязычной литературе и обозначающего все технологии Data Mining.
В случае supervised learning задача анализа данных решается в несколько этапов. Сначала с помощью какого-либо алгоритма Data Mining строится модель анализируемых данных – классификатор. Затем классификатор подвергается обучению. Другими словами, проверяется качество его работы и, если оно неудовлетворительно, происходит дополнительное обучение классификатора. Так продолжается до тех пор, пока не будет достигнут требуемый уровень качества или не станет ясно, что выбранный алгоритм не работает корректно с данными, либо же сами данные не имеют структуры, которую можно выявить. К этому типу задач относят задачи классификации и регрессии.
Unsupervised learning объединяет задачи, выявляющие описательные модели, например закономерности в покупках, совершаемых клиентами большого магазина. Очевидно, что если эти закономерности есть, то модель должна их представить и неуместно говорить об ее обучении. Отсюда и название - unsupervised learning. Достоинством таких задач является возможность их решения без каких-либо предварительных знаний об анализируемых данных. К ним относятся кластеризация и поиск ассоциативных правил.
Задача классификации и регрессии
При анализе часто требуется определить, к какому из известных классов относятся исследуемые объекты, т. е. классифицировать их. Например, когда человек обращается в банк за предоставлением ему кредита, банковский служащий должен принять решение: кредитоспособен ли потенциальный клиент или нет. Очевидно, что такое решение принимается на основании данных об исследуемом объекте (в данном случае - человеке): его месте работы, размере заработной платы, возрасте, составе семьи и т. п. В результате анализа этой информации банковский служащий должен отнести человека к одному из двух известных классов "кредитоспособен" и "некредитоспособен".
Другим примером задачи классификации является фильтрация электронной почты. В этом случае программа фильтрации должна классифицировать входящее сообщение как спам (нежелательная электронная почта) или как письмо. Данное решение принимается на основании частоты появления в сообщении определенных слов (например, имени получателя, безличного обращения, слов и словосочетаний: приобрести, "заработать", "выгодное предложение" и т. п.).
В общем случае количество классов в задачах классификации может быть более двух. Например, в задаче распознавания образа цифр таких классов может быть 10 (по количеству цифр в десятичной системе счисления). В такой задаче объектом классификации является матрица пикселов, представляющая образ распознаваемой цифры. При этом цвет каждого пиксела является характеристикой анализируемого объекта.
В Data Mining задачу классификации рассматривают как задачу определения 'значения одного из параметров анализируемого объекта на основании значений других параметров. Определяемый параметр часто называют зависимой переменной, а параметры, участвующие в его определении - независимыми переменными. В рассмотренных примерах независимыми переменными являлись:
· зарплата, возраст, количество детей и т. д.;
· частота определенных слов;
· значения цвета пикселов матрицы.
Зависимыми переменными в этих же примерах являлись:
· кредитоспособность клиента (возможные значения этой переменной "да" и "нет");
· тип сообщения (возможные значения этой переменной "spam" и "mail");
· цифра образа (возможные значения этой переменной 0, 1,..., 9).
Необходимо обратить внимание, что во всех рассмотренных примерах независимая переменная принимала значение из конечного множества значений: {да, нет}, {spam, mail}, {0, 1,..., 9}. Если значениями независимых и зависимой переменных являются действительные числа, то задача называется задачей регрессии. Примером задачи регрессии может служить задача определения суммы кредита, которая может быть выдана банком клиенту.
Задача классификации и регрессии решается в два этапа. На первом выделяется обучающая выборка. В нее входят объекты, для которых известны значения как независимых, так и зависимых переменных. В описанных ранее примерах такими обучающими выборками могут быть:
· информация о клиентах, которым ранее выдавались кредиты на разные суммы, и информация об их погашении;
· сообщения, классифицированные вручную как спам или как письмо;
· распознанные ранее матрицы образов цифр.
На основании обучающей выборки строится модель определения значения зависимой переменной. Ее часто называют функцией классификации или регрессии. Для получения максимально точной функции к обучающей выборке предъявляются следующие основные требования:
· количество объектов, входящих в выборку, должно быть достаточно большим. Чем больше объектов, тем построенная на ее основе функция классификации или регрессии будет точнее;
· в выборку должны входить объекты, представляющие все возможные классы в случае задачи классификации или всю область значений в случае задачи регрессии;
· для каждого класса в задаче классификации или каждого интервала области значений в задаче регрессии выборка должна содержать достаточное количество объектов.
На втором этапе построенную модель применяют к анализируемым объектам (к объектам с неопределенным значением зависимой переменной).
Задача классификации и регрессии имеет геометрическую интерпретацию. Рассмотрим ее на примере с двумя независимыми переменными, что позволит представить ее в двумерном пространстве (рис. 2.1.1). Каждому объекту ставится в соответствие точка на плоскости. Символы "+" и "-" обозначают принадлежность объекта к одному из двух классов. Очевидно, что данные имеют четко выраженную структуру: все точки класса "+" сосредоточены в центральной области. Построение классификационной функции сводится к построению поверхности, которая обводит центральную область. Она определяется как функция, имеющая значения "+" внутри обведенной области и "-" - вне.
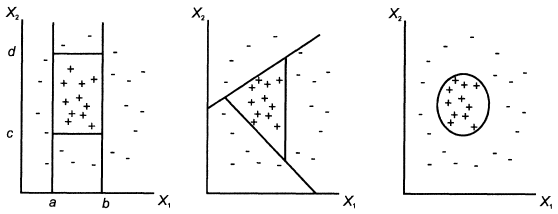
Рис. Классификация в двумерном пространстве
Как видно из рисунка, есть несколько возможностей для построения обводящей области. Вид функции зависит от применяемого алгоритма.
Основные проблемы, с которыми сталкиваются при решении задач классификации и регрессии, - это неудовлетворительное качество исходных данных, в которых встречаются как ошибочные данные, так и пропущенные значения, различные типы атрибутов - числовые и категорические, разная значимость атрибутов, а также так называемые проблемы overfitting и underfilling. Суть первой из них заключается в том, что классификационная функция при построении "слишком хорошо" адаптируется к данным, и встречающиеся в них ошибки и аномальные значения пытается интерпретировать как часть внутренней структуры данных. Очевидно, что такая модель будет некорректно работать в дальнейшем с другими данными, где характер ошибок будет несколько иной. Термином underfitting обозначают ситуацию, когда слишком велико количество ошибок при проверке классификатора на обучающем множестве. Это означает, что особых закономерностей в данных не было обнаружено и либо их нет вообще, либо необходимо выбрать иной метод их обнаружения.
Задача поиска ассоциативных правил
Поиск ассоциативных правил является одним из самых популярных приложений Data Mining. Суть задачи заключается в определении часто встречающихся наборов объектов в большом множестве таких наборов. Данная задача является частным случаем задачи классификации. Первоначально она решалась при анализе тенденций в поведении покупателей в супермаркетах. Анализу подвергались данные о совершаемых ими покупках, которые покупатели складывают в тележку (корзину). Это послужило причиной второго часто встречающегося названия — анализ рыночных корзин (Basket Analysis). При анализе этих данных интерес прежде всего представляет информация о том, какие товары покупаются вместе, в какой последовательности, какие категории потребителей, какие товары предпочитают, в какие периоды времени и т. п. Такая информация позволяет более эффективно планировать закупку товаров, проведение рекламной кампании и т. д.
Например, из набора покупок, совершаемых в магазине, можно выделить следующие наборы товаров, которые покупаются вместе:
· {чипсы, пиво};
· {вода, орехи}.
Следовательно, можно сделать вывод, что если покупаются чипсы или орехи, то, как правило, покупаются пиво или вода соответственно. Обладая такими знаниями, можно разместить эти товары рядом, объединить их в один пакет со скидкой или предпринять другие действия, стимулирующие покупателя приобрести товар.
Задача поиска ассоциативных правил актуальна не только в сфере торговли. Например, в сфере обслуживания интерес представляет, какими услугами клиенты предпочитают пользоваться в совокупности. Для получения этой информации задача решается применительно к данным об услугах, которыми пользуется один клиент в течение определенного времени (месяца, года). Это помогает определить, например, как наиболее выгодно составить пакеты услуг, предлагаемых клиенту.
В медицине анализу могут подвергаться симптомы и болезни, наблюдаемые у пациентов. В этом случае знания о том, какие сочетания болезней и симптомов встречаются наиболее часто, помогают в будущем правильно ставить диагноз.
При анализе часто вызывает интерес последовательность происходящих событий. При обнаружении закономерностей в таких последовательностях можно с некоторой долей вероятности предсказывать появление событий в будущем, что позволяет принимать более правильные решения. Такая задача является разновидностью задачи поиска ассоциативных правил и называется сиквенциалъным анализом.
Основным отличием задачи сиквенциального анализа от поиска ассоциативных правил является установление отношения порядка между исследуемыми наборами. Данное отношение может быть определено разными способами. При анализе последовательности событий, происходящих во времени, объектами таких наборов являются события, а отношение порядка соответствует хронологии их появления.
Сиквенциальный анализ широко используется, например в телекоммуникационных компаниях, для анализа данных об авариях на различных узлах сети. Информация о последовательности совершения аварий может помочь в обнаружении неполадок и предупреждении новых аварий. Например, если известна последовательность сбоев:
![]()
где ![]() — сбой с кодом i, то на основании факта появления сбоя
— сбой с кодом i, то на основании факта появления сбоя ![]() можно сделать вывод о скором появлении сбоя
можно сделать вывод о скором появлении сбоя ![]() . Зная это, можно предпринять профилактические меры, устраняющие причины возникновения сбоя. Если дополнительно обладать и знаниями о времени между сбоями, то можно предсказать не только факт его появления, но и время, что часто не менее важно.
. Зная это, можно предпринять профилактические меры, устраняющие причины возникновения сбоя. Если дополнительно обладать и знаниями о времени между сбоями, то можно предсказать не только факт его появления, но и время, что часто не менее важно.
Задача кластеризации
Задача кластеризации состоит в разделении исследуемого множества объектов на группы "похожих" объектов, называемых кластерами. Слово кластер английского происхождения (cluster), переводится как сгусток, пучок, группа. Родственные понятия, используемые в литературе, - класс, таксон, сгущение. Часто решение задачи разбиения множества элементов на кластеры называют кластерным анализом.
Кластеризация может применяться практически в любой области, где необходимо исследование экспериментальных или статистических данных. Рассмотрим пример из области маркетинга, в котором данная задача называется сегментацией.
Концептуально сегментирование основано на предпосылке, что все потребители - разные. У них разные потребности, разные требования к товару, они ведут себя по-разному: в процессе выбора товара, в процессе приобретения товара, в процессе использования товара, в процессе формирования реакции на товар. В связи с этим необходимо по-разному подходить к работе с потребителями: предлагать им различные по своим характеристикам товары, по-разному продвигать и продавать товары. Для того чтобы определить, чем отличаются потребители друг от друга и как эти отличия отражаются на требованиях к товару, и производится сегментирование потребителей.
В маркетинге критериями (характеристики) сегментации являются: географическое местоположение, социально-демографические характеристики, мотивы совершения покупки и т. п.
На основании результатов сегментации маркетолог может определить, например, такие характеристики сегментов рынка, как реальная и потенциальная емкость сегмента, группы потребителей, чьи потребности не удовлетворяются в полной мере ни одним производителем, работающим на данном сегменте рынка, и т. п. На основании этих параметров маркетолог может сделать вывод о привлекательности работы фирмы в каждом из выделенных сегментов рынка.
Для научных исследований изучение результатов кластеризации, а именно выяснение причин, по которым объекты объединяются в группы, способно открыть новые перспективные направления. Традиционным примером, который обычно приводят для этого случая, является периодическая таблица элементов. В 1869 г. Дмитрий Менделеев разделил 60 известных в то время элементов на кластеры или периоды. Элементы, попавшие в одну группу, обладали схожими характеристиками. Изучение причин, по которым элементы разбивались на явно выраженные кластеры, в значительной степени определило приоритеты научных изысканий на годы вперед. Но лишь спустя 50 лет квантовая физика дала убедительные объяснения периодической системы.
Кластеризация отличается от классификации тем, что для проведения анализа не требуется иметь выделенную зависимую переменную. С этой точки зрения она относится к классу unsupervised learning. Эта задача решается на начальных этапах исследования, когда о данных мало что известно. Ее решение помогает лучше понять данные, и с этой точки зрения задача кластеризации является описательной задачей.
Для задачи кластеризации характерно отсутствие каких-либо различий как между переменными, так и между объектами. Напротив, ищутся группы наиболее близких, похожих объектов. Методы автоматического разбиения на кластеры редко используются сами по себе, просто для получения групп схожих объектов. После определения кластеров применяются другие методы Data Mining, для того чтобы попытаться установить, а что означает такое разбиение, чем оно вызвано.
Кластерный анализ позволяет рассматривать достаточно большой объем информации и резко сокращать, сжимать большие массивы информации, делать их компактными и наглядными.
Отметим ряд особенностей, присущих задаче кластеризации.
Во-первых, решение сильно зависит от природы объектов данных (и их атрибутов). Так, с одной стороны, это могут быть однозначно определенные, четко количественно очерченные объекты, а с другой — объекты, имеющие вероятностное или нечеткое описание.
Во-вторых, решение значительно зависит также и от представления кластеров и предполагаемых отношений объектов данных и кластеров. Так, необходимо учитывать такие свойства, как возможность/невозможность принадлежности объектов нескольким кластерам. Необходимо определение самого понятия принадлежности кластеру: однозначная (принадлежит/не принадлежит), вероятностная (вероятность принадлежности), нечеткая (степень принадлежности).
Возможности Data Miner вStatistica 8
Компанией StatSoft была разработана система STATISTICA Data Miner, которая спроектирована и реализована как универсальное и всестороннее средство анализа данных - от взаимодействия с различными базами данных до создания готовых отчетов, реализующее так называемый графически - ориентированный подход. Чтобы описать все возможности данного пакета потребуется написать целую книгу, поэтому постараемся вкратце описать имеющиеся в данном пакете основные средства Data Mining.

· Наиболее полный пакет методов Data Mining на рынке программного обеспечения;
· Большой набор готовых решений;
· Удобный пользовательский интерфейс, полностью интегрированный с MS Office;
· Мощные средства разведочного анализа;
· Полностью оптимизированный пакет для работы с огромным объемом информации;
· Гибкий механизм управления;
· Многозадачность системы;
· Чрезвычайно быстрое и эффективное развертывание;
· Открытая COM архитектура, неограниченные возможности автоматизации и поддержки пользовательских приложений (использование промышленного стандарта Visual Basic (является встроенным языком), Java, C/C++).
Сердцем STATISTICA Data Miner является браузер процедур Data Mining, содержащий более 300 основных процедур, специально оптимизированных под задачи Data Mining, и средств логической связи между ними и управления потоками данных, позволяющий конструировать собственные аналитические методы.


Рабочее пространство STATISTICA Data Miner состоит из четырех основных частей:
· Data Acquisition - Сбор данных. В данной части пользователь идентифицирует источник данных для анализа, будь то файл данных или запрос из базы данных.
· Data Preparation, Cleaning, Transformation - Подготовка, преобразования и очистка данных. Здесь данные преобразуются, фильтруются, группируются и т.д.
· Data Analysis, Modeling, Classification, Forecasting - Анализ данных, моделирование, классификация, прогнозирование. Здесь пользователь может при помощи браузера или готовых моделей задать необходимые виды анализа данных таких как, прогнозирование, классификация, моделирование и т.д.
· Reports - Результаты. В данной части пользователь может просмотреть, задать вид и настроить результаты анализа (например, рабочая книга, отчет или электронная таблица).
Средства анализа STATISTICADataMiner
В пакете предлагается исчерпывающий набор процедур и методов визуализации.
Средства анализа STATISTICA Data Miner можно классифицировать на пять основных классов:
· ![]() General Slicer/Dicer and Drill-Down Explorer - Разметка/Разбиение и Углубленный анализ. Набор процедур позволяющий разбивать, группировать переменные, вычислять описательные статистики, строить исследовательские графики и т.д.
General Slicer/Dicer and Drill-Down Explorer - Разметка/Разбиение и Углубленный анализ. Набор процедур позволяющий разбивать, группировать переменные, вычислять описательные статистики, строить исследовательские графики и т.д.
· ![]() General Classifier - Классификация. STATISTICA Data Miner включает в себя полный пакет процедур классификации: обобщенные линейные модели, деревья классификации, регрессионные деревья, кластерный анализ и т.д.
General Classifier - Классификация. STATISTICA Data Miner включает в себя полный пакет процедур классификации: обобщенные линейные модели, деревья классификации, регрессионные деревья, кластерный анализ и т.д.
· ![]() General Modeler/Multivariate Explorer - Обобщенные линейные, нелинейные и регрессионные модели. Данный элемент содержит линейные, нелинейные, обобщенные регрессионные модели и элементы анализа деревьев классификации.
General Modeler/Multivariate Explorer - Обобщенные линейные, нелинейные и регрессионные модели. Данный элемент содержит линейные, нелинейные, обобщенные регрессионные модели и элементы анализа деревьев классификации.
· ![]() General Forecaster - Прогнозирование. Включает в себя модели АРПСС, сезонные модели АРПСС, экспоненциальное сглаживание, спектральный анализ Фурье, сезонная декомпозиция, прогнозирование при помощи нейронных сетей и т.д.
General Forecaster - Прогнозирование. Включает в себя модели АРПСС, сезонные модели АРПСС, экспоненциальное сглаживание, спектральный анализ Фурье, сезонная декомпозиция, прогнозирование при помощи нейронных сетей и т.д.
· ![]() General Neural Networks Explorer - Нейросетевой анализ. В данной части содержится наиболее полный пакет процедур нейросетевого анализа.
General Neural Networks Explorer - Нейросетевой анализ. В данной части содержится наиболее полный пакет процедур нейросетевого анализа.
Приведенные выше элементы являются комбинацией модулей других продуктов StatSoft, кроме них STATISTICA Data Miner содержит набор специализированных процедур Data Mining, которые дополняют линейку инструментов Data Mining

· Feature Selection and Variable Filtering (for very large data sets) - Специальная выборка и фильтрация данных (для больших объемов данных). Данный модуль автоматически выбирает подмножества переменных из заданного файла данных для последующего анализа. Например, модуль может обработать около миллиона входных переменных с целью определения предикторов для регрессии или классификации.
· Association Rules - Правила ассоциации. Модуль является реализацией так называемого априорного алгоритма обнаружения правил ассоциации например, результат работы этого алгоритма мог бы быть следующим: клиент после покупки продукт "А", в 95 случаях из 100, в течении следующих двух недель после этого заказывает продукт "B" или "С".
· Interactive Drill-Down Explorer - Интерактивный углубленный анализ. Представляет собой набор средств для гибкого исследования больших наборов данных. На первом шаге вы задаете набор переменных для углубленного анализа данных, на каждом последующем шаге вы выбираете необходимую подгруппу данных для последующего анализа.
· Generalized EM & k-Means Cluster Analysis - Обобщенный метод максимума среднего и кластеризация методом К средних. Данный модуль - это расширение методов кластерного анализа, предназначен для обработки больших наборов данных и позволяет кластеризовывать как непрерывные так и категориальные переменные, обеспечивает все необходимые функциональные возможности для распознавания образов.
· Generalized Additive Models (GAM) - Обобщенные аддитивная модели (GAM). Набор методов, разработанных и популяризованных Hastie и Tibshirani (1990); более детальное рассмотрение этих методов вы также может найти в работах Schimek (2000).
· General Classification and Regression Trees (GTrees) - Обобщенные классификационные и регрессионные деревья (GTrees). Модуль является полной реализацией методов разработанных Breiman, Friedman, Olshen, и Stone (1984). Кроме этого модуль содержит разного рода доработки и дополнения такие как, оптимизации алгоритмов для больших объемов данных и т.д. Модуль является набором методов обобщенной классификации и регрессионных деревьев.
· General CHAID (Chi-square Automatic Interaction Detection) Models - Обобщенные CHAID модели (Хи-квадрат автоматическое обнаружение взаимодействия). Подобно предыдущему элементу данный модуль является оптимизацией данной математической модели для больших объемов данных.
data miner statistica регрессия кластеризация

· Interactive Classification and Regression Trees - Интерактивная классификация и регрессионные деревья. В дополнение к модулям автоматического построения разного рода деревьев, STATISTICA Data Miner также включает средства для формирования таких деревьев в интерактивном режиме.
· Boosted Trees - Расширяемые простые деревья. Последние исследование аналитических алгоритмов показывают, что для некоторых задач построения "сложных" оценок, прогнозов и классификаций, использование последовательно увеличиваемых простых деревьев дает более точные результаты чем нейронные сети или сложные цельные деревья. Данный модуль реализует алгоритм построения простых увеличиваемых (расширяемых) деревьев.
· Multivariate Adaptive Regression Splines (Mar Splines) - Многомерные адаптивные регрессионные сплайны (Mar Splines). Данный модуль основан на реализации методики предложенной Friedman (1991; Multivariate Adaptive Regression Splines, Annals of Statistics, 19, 1-141); в STATISTICA Data Miner расширены опции MARSPLINES для того, чтобы приспособить задачи регрессии и классификации к непрерывными и категориальным предикторам.
· Goodness of Fit Computations - Критерии согласия. Данный модуль производит вычисления различных статистических критериев согласия как для непрерывных переменных, так и для категориальных.
· Rapid Deployment of Predictive Models - Быстрые прогнозирующие модели (для большого числа наблюдаемых значений). Модуль позволяет строить за короткое время классификационные и прогнозирующие модели для большого объема данных. Полученные результаты могут быть непосредственно сохранены во внешней базе данных.
Пример работы в DataMining
Создание отчетов и итогов
Открываем базу данных:
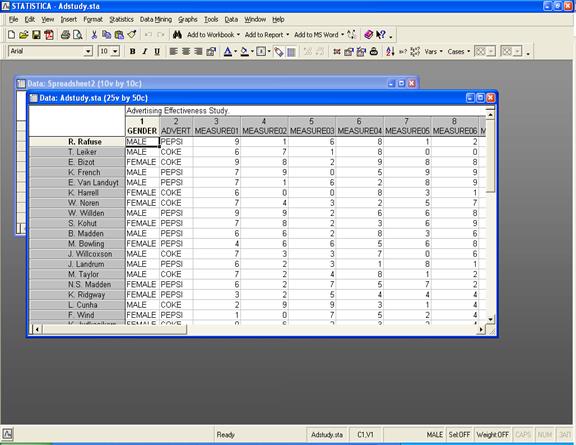
Таблица содержит имена менеджеров в различных ресторанных сетях. Первая колонка – пол менеджера, вторая – что поставляется от вашего ресторана менеджерам, колонки с 3 по 26 – информация о количестве закупок по 23 месяцам сделанных у вашей компании.
Необходимо определить какой из менеджеров купил больше всего продукции, поделенной по типам продукции.
ВыбираемсредуработывDataMining ->Workspaces->All Procedures.
Выбираем данные (базу данных) для работы:
Выбираем переменные:

Далее необходимо убрать все нули без потери данных для вычисления среднего числа:

Далее определяем параметры фильтрации:

После запуска проекта на выполнение:

Все нулевые значения убраны:

Далее посчитаем среднее число поставок за последние 3 и 6 месяцев:


Запускаем проект на выполнение.
Результат:


Сортировка информации
Отсортируем информацию по двум переменным, которые мы создали.




Для первой сортировки:
Для второй сортировки:

Запускаем проект на выполнение:

Результат первой сортировки:
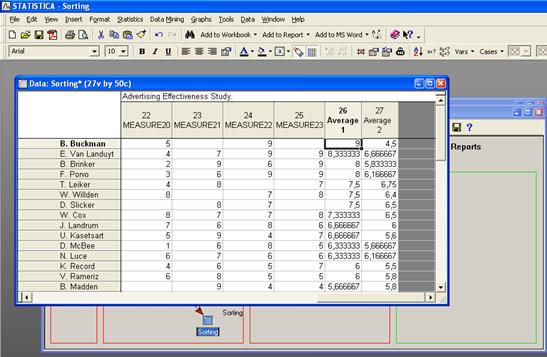
Построение графика:

Далее выбираем вид процедур:


Запускаем проект на выполнение:

Результаты:

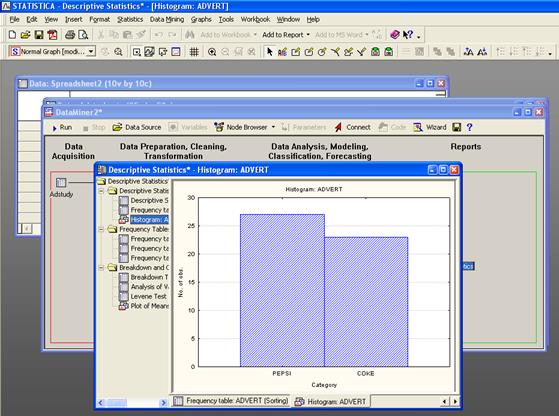
Анализ цен жилищных участков
Выбираем среду работы в DataMining ->Workspaces->AllProcedures.
Выбираем данные (базу данных) для работы:

В следующем примере анализируются данные о жилищном строительстве в Бостоне. Цена участка под застройку классифицируется как Низкая - Low, Средняя - Medium или Высокая - High в зависимости от значения зависимой переменной Price. Имеется один категориальный предиктор - Cat1 и 12 порядковых предикторов - Ord1-Ord12. Весь набор данных, состоящий из 1012 наблюдений, содержится в файле примеров Boston2.sta.
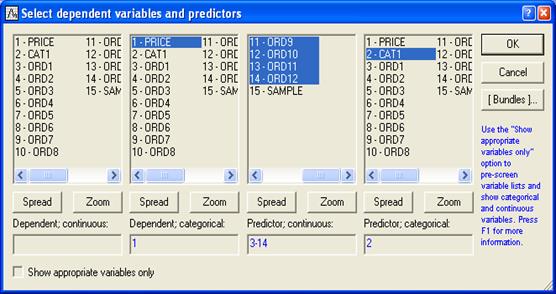
Далее выбираем переменные для анализа. STATISTICA различает категориальные и непрерывные переменные, а также зависимые и предикторы (независимые переменные). Категориальные переменные – те, которые содержат информацию о некотором дискретном количестве или характеристике, описывающей наблюдения в файле данных (например, Пол: Мужской, Женский); непрерывные переменные измерены в некотором непрерывном масштабе (например, Высота, Вес, Стоимость). Зависимые переменные – те, которые мы хотим предсказать; их также иногда называют переменными результата; предикторы (независимые) переменные – те, что мы хотим использовать для предсказания или классификации (категориальных исходящих).
После выбора файла появится окно диалога "Выберите зависимые переменные и предикторы"

Выбранные переменные для анализа:
После нажатия кнопки ОК данные заносятся в рабочее пространство.
Запускаем диспетчер узлов.
Далее открываем окно для выбора вида анализа или задания преобразования данных:

А также выбираем ещё такую процедуру:

Диспетчер узлов включает в себя все доступные процедуры для добычи данных. Всего доступно около 260 методов фильтрации и очистки данных, методов анализа. По умолчанию, процедуры помещены в папки и отсортированы в соответствии с типом анализа, который они выполняют. Однако пользователь имеет возможность создать собственную конфигурацию сортировки методов.
Для того чтобы выбрать необходимый анализ, необходимо выделить его на правой панели и нажать кнопку "вставить". В нижней части диалога дается описание выбираемых методов.
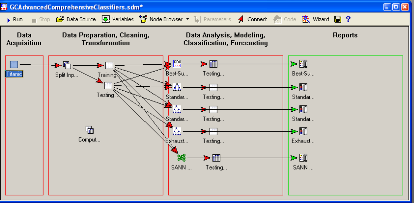
Выберем, для примера, Descriptive Statistics и Standard Classification Trees with Deployment (C And RT) . Окно Data Miner выглядит следующим образом.

Источник данных в рабочей области Data Miner автоматически будет соединен с узлами выбранных анализов. Операции создания/удаления связей можно производить и вручную.
Запускаем на выполнение проект “Run”.
Все узлы, соединенные с источниками данных активными стрелками, будут проведены:

Далее можно просмотреть результаты (в столбце отчетов). Подробные отчеты создаются по умолчанию для каждого вида анализа. Для рабочих книг результатов доступна полная функциональность системы STATISTICA.


Кроме того, в диспетчере узлов STATISTICA Data Miner содержатся разнообразные процедуры для классификации и Дискриминантного анализа, Регрессионных моделей и Многомерного анализа, а также Обобщенные временные ряды и прогнозирование. Все эти инструменты можно использовать для проведения сложного анализа в автоматическом режиме, а также для оценивания качества модели.
Анализ предикторов выживания
Данный пример базируется на данных о пассажирах корабля. Приведены пол, возраст, тип класса, и статус выживания для пассажиров плохо снаряженных суден.

Отображаются единичная точка входа для соединения с данными, а также различные точки для получения разных моделей из данной информации.
Данный монтируется с помощью Training sample, а затем оцениваются с помощью Testing sample.
В итоге Advanced Comprehensive Classifiers Project предоставит различные методы классификации проблемы, и автоматически сгенерирует развернутую информацию необходимую, чтоб классифицировать новые наблюдения, используя один из этих методов или комбинации этих методов.
Проанализируем предикторы выживания в случае катастрофы корабля.





Запускаем проект:

Результат:


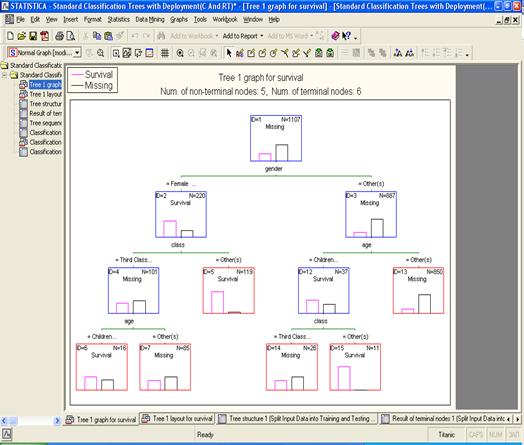
Если следовать этому дереву решений, вы увидите, что женщины в первом и втором классах имеют более высокий шанс выживания, чем дети мужского пола в первом и втором классах.
Заключение
Data Mining включает огромный набор различных аналитических процедур, что делает его недоступным для обычных пользователей, которые слабо разбираются в методах анализа данных. Компания StatSoft нашла выход и из этой ситуации, данный пакет Statistica могут использовать как профессионалы, так и обычные пользователи, обладающие небольшими опытом и знаниями в анализе данных и математической статистике. Для этого кроме общих методов анализа были встроены готовые законченные (сконструированные) модули анализа данных, предназначенные для решения наиболее важных и популярных задач: прогнозирования, классификации, создания правил ассоциации и т.д.
Похожие рефераты:
Моделирование сети кластеризации данных в MATLAB NEURAL NETWORK TOOL
Билеты на государственный аттестационный экзамен по специальности Информационные Системы
Статистический анализ банковской деятельности. Исследование моделей оценки кредитных рисков
Классификация сейсмических сигналов на основе нейросетевых технологий
Многомерный статистический анализ
Добыча знаний и управление ими
Современная технология обработки информационных данных Data Mining
Техническая диагностика средств вычислительной техники
Процесс выбора, поиска, сбора и анализа необходимой маркетинговой информации
Статистический пакет STATISTIKA
Кластеры как фактор инновационного развития предприятий и территориальных образований
Корпоративные базы данных экономических информационных систем
Исследование архитектуры современных микропроцессоров и вычислительных систем