| Похожие рефераты | Скачать .docx |
Реферат: Перспективные интерфейсы оперативной памяти
Федеральное агентство железнодорожного транспорта
Омский государственный университет путей сообщения
Кафедра «Автоматика и системы управления»
Тематический реферат
по дисциплине «Интерфейсы ИС»
ПЕРСПЕКТИВНЫЕ ИНТЕРФЕЙСЫ ОПЕРАТИВНОЙ ПАМЯТИ
Студент гр. ИС
Д.Ю. Гордиенко
Руководитель:
доцент кафедры АиСУ,
к. т. н. Е.А. Альтман
Омск 2011
Содержание
Введение
1. Современная оперативная память
1.1 SDRAM
1.2 DDR/DDR2 SDRAM
1.3 DDR3 SDRAM
1.4 RAMBUS (RDRAM)
2. Перспективы развития оперативной памяти
2.1 MRAM. Голографическая память
2.2 Память на основе графеновой наноленты
2.3 Оперативная память на нанотрубках
Заключение
Библиографический список
Введение
Оперативная память (ОЗУ,RAM) - это одна из частей памяти компьютера (ЭВМ). Она служит поддержкой процессору компьютера (CPU). В оперативной памяти временно сохраняются данные и команды, необходимые процессору для выполнения им операций. Оперативная память передаёт процессору данные непосредственно, либо через кэш-память. Каждая ячейка оперативной памяти имеет свой индивидуальный адрес.
В современных вычислительных устройствах, оперативная память выполнена по технологии динамической памяти с произвольным доступом (англ. dynamic random access memory, DRAM). Понятие памяти с произвольным доступом предполагает, что текущее обращение к памяти не учитывает порядок предыдущих операций и расположения данных в ней. ОЗУ может изготавливаться как отдельный блок (например, модули памяти дляIBM-PCсовместимых компьютеров), или входить в конструкцию однокристальной ЭВМ или микроконтроллера.
Так какIBM-PCсовместимые компьютеры преобладают и в России, и в мире, то рассмотрим их оперативную память. Изначально объём оперативной памяти был равен 640 килобайтам. Это так называемая "основная область памяти" (англ. conventional memory). Чуть позже в ОЗУ появились дополнительные 384 килобайта "верхней области памяти", названные Upper Memory Area (UMA), и общий объём оперативной памяти компьютера вырос до 1 мегабайта.
В основную память загружается таблица векторов прерываний, различные данные из BIOS, а также могут загружаться некоторые 16-битные программы DOS. Верхняя память используется для размещения информации об аппаратной части компьютера. Она условно делится на три области по 128 Кбайт:
а) для видеопамяти;
б) для BIOS адаптеров;
в) для системной BIOS (обычно не более 64 килобайт).
Остальное адресное пространство из верхней области с помощью специальных драйверов (например, EMM386.EXE) использовалось для доступа к расширенной памяти через спецификацию расширенной памяти (англ. Expanded Memory Specification, EMS). EMS использовалась преимущественно в компьютерах с размером оперативной памяти менее 1 Мбайт и практически не используется в современных компьютерах.
То есть, в современных компьютерах так же есть основная область памяти и верхняя область памяти. Их объём остался прежним: 640 и 384 килобайт, соответственно. Вы уже поняли, что всё, что сверх этой ёмкости - это дополнительная память (англ. eXtended Memory Specification, XMS). Дополнительная память начинается с адресов выше первого мегабайта и её объём зависит от общего объёма оперативной памяти, установленной на компьютере.
Стоит сказать и о High Memory Area (HMA) - это область дополнительной памяти за первым мегабайтом размером 64 Кбайт минус 16 байт. Её появление было обусловлено ошибкой в процессоре 80286, в котором не отключалась 21-я линия адреса (а всего их в этом процессоре 24), в результате при обращении по адресам выше FFFF:000F обращение шло ко второму мегабайту памяти вместо начала первого мегабайта.
Теперь поговорим о различных типах оперативной памяти. Сегодня распространённым типом модулей ОЗУ являютсяDDRиDDR2. Всё ещё встречаются модулиSD-RAM(DIMM). А в некоторых типах устройств используются и модулиDDR3. Что они из себя представляют и в чём их различия?
1. Современная оперативная память
1.1 SDRAM
Аббревиатура SDRAMрасшифровывается как SynchronousDynamicRandomAccessMemory— синхронная динамическая память с произвольным доступом. Остановимся подробнее на каждом из этих определений. Под «синхронностью» обычно понимается строгая привязка управляющих сигналов и временных диаграмм функционирования памяти к частоте системной шины. Вообще говоря, в настоящее время изначальный смысл понятия синхронности становится несколько условным. Во-первых, частота шины памяти может отличаться от частоты системной шины (в качестве примера можно привести уже сравнительно давно существующий «асинхронный» режим работы памяти DDR SDRAM на платформах AMD K7 с чипсетами VIA KT333/400, в которых частоты системной шины процессора и шины памяти могут соотноситься как 133/166 или 166/200 МГц). Во-вторых, ныне существуют системы, в которых само понятие «системной шины» становится условным — речь идет о платформах класса AMD Athlon 64 с интегрированным в процессор контроллером памяти. Частота «системной шины» (под которой в данном случае понимается не шина HyperTransport для обмена данными с периферией, а непосредственно «шина» тактового генератора) в этих платформах является лишь опорной частотой, которую процессор умножает на заданный коэффициент для получения собственной частоты. При этом контроллер памяти всегда функционирует на той же частоте, что и сам процессор, а частота шины памяти задается целым делителем, который может не совпадать с первоначальным коэффициентом умножения частоты «системной шины». Так, например, режиму DDR-333 на процессоре AMD Athlon 64 3200+ будут соответствовать множитель частоты «системной шины» 10 (частота процессора и контроллера памяти 2000 МГц) и делитель частоты памяти 12 (частота шины памяти 166.7 МГц). Таким образом, под «синхронной» операцией SDRAM в настоящее время следует понимать строгую привязку временны х интервалов отправки команд и данных по соответствующим интерфейсам устройства памяти к частоте шины памяти (проще говоря, все операции в ОЗУ совершаются строго по фронту/срезу синхросигнала интерфейса памяти). Так, отправка команд и чтение/запись данных может осуществляться на каждом такте шины памяти (по положительному перепаду «фронту» синхросигнала; в случае памяти DDR/DDR2 передача данных происходит как по «фронту», так и по отрицательному перепаду — «срезу» синхросигнала), но не по произвольным временны м интервалам (как это осуществлялось в асинхронной DRAM).
Понятие «динамической» памяти, DRAM, относится ко всем типам оперативной памяти, начиная с самой древней, «обычной» асинхронной динамической памяти и заканчивая современной DDR2. Этот термин вводится в противоположность понятия «статической» памяти (SRAM) и означает, что содержимое каждой ячейки памяти периодически необходимо обновлять (ввиду особенности ее конструкции, продиктованной экономическими соображениями). В то же время, статическая память, характеризующаяся более сложной и более дорогой конструкцией ячейки и применяемая в качестве кэш-памяти в процессорах (а ранее — и на материнских платах), свободна от циклов регенерации, т.к. в ее основе лежит не емкость (динамическая составляющая), а триггер (статическая составляющая).
Наконец, стоит также упомянуть о «памяти с произвольным доступом» Random Access Memory, RAM. Традиционно, это понятие противопоставляется устройствам «памяти только на чтение» — Read-Only Memory, ROM. Тем не менее, противопоставление это не совсем верно, т.к. из него можно сделать вывод, что память типа ROM не является памятью с произвольным доступом. Это неверно, потому как доступ к устройствам ROM может осуществляться в произвольном, а не строго последовательном порядке. И на самом деле, наименование «RAM» изначально противопоставлялось ранним типам памяти, в которых операции чтения/записи могли осуществляться только в последовательном порядке. В связи с этим, более правильно назначение и принцип работы оперативной памяти отражает аббревиатура «RWM» (Read-Write Memory), которая, тем не менее, встречается намного реже. Заметим, что русскоязычным сокращениям RAM и ROM — ОЗУ (оперативное запоминающее устройство) и ПЗУ (постоянное запоминающее устройство), соответственно, подобная путаница не присуща.
1.2 DDR/DDR2 SDRAM
Начнем с рассмотрения микросхем DDR SDRAM. По большей части они оказываются похожими на микросхемы SDR SDRAM — так, оба типа микросхем, как правило, имеют одинаковую логическую организацию (при одинаковой емкости), включая 4-банковую организацию массива памяти, и одинаковый командно-адресный интерфейс. Фундаментальные различия между SDR и DDR лежат в организации логического слоя интерфейса данных. По интерфейсу данных памяти типа SDR SDRAM данные передаются только по положительному перепаду («фронту») синхросигнала. При этом внутренняя частота функционирования микросхем SDRAM совпадает с частотой внешней шины данных, а ширина внутренней шины данных SDR SDRAM (от непосредственно ячеек до буферов ввода-вывода) совпадает с шириной внешней шины данных. В то же время, по интерфейсу данных памяти типа DDR (а также DDR2) данные передаются дважды за один такт шины данных — как по положительному перепаду синхросигнала («фронту»), так и по отрицательному («срезу»).
Возникает вопрос — как можно организовать удвоенную скорость передачи данных по отношению к частоте шины памяти? Напрашиваются два решения — можно либо увеличить в 2 раза внутреннюю частоту функционирования микросхем памяти (по сравнению с частотой внешней шины), либо увеличить в 2 раза внутреннюю ширину шины данных (по сравнению с шириной внешней шины). Достаточно наивно было бы полагать, что в реализации стандарта DDR было применено первое решение, но и ошибиться в эту сторону довольно легко, учитывая «чисто маркетинговый» подход к маркировке модулей памяти типа DDR, якобы функционирующих на удвоенной частоте (так, модули памяти DDR с реальной частотой шины 200 МГц именуются «DDR-400»). Тем не менее, гораздо более простым и эффективным — исходя как из технологических, так и экономических соображений — является второе решение, которое и применяется в устройствах типа DDR SDRAM. Такая архитектура, применяемая в DDR SDRAM, называется архитектурой «2n-предвыборки» (2n-prefetch). В этой архитектуре доступ к данным осуществляется «попарно» — каждая одиночная команда чтения данных приводит к отправке по внешней шине данных двух элементов (разрядность которых, как и в SDR SDRAM, равна разрядности внешней шины данных). Аналогично, каждая команда записи данных ожидает поступления двух элементов по внешней шине данных. Именно это обстоятельство объясняет, почему величина «длины пакета» (Burst Length, BL) при передаче данных в устройствах DDR SDRAM не может быть меньше 2.
Устройства типа DDR2 SDRAM являются логическим продолжением развития архитектуры «2n-prefetch», применяемой в устройствах DDR SDRAM. Вполне естественно ожидать, что архитектура устройств DDR2 SDRAM именуется «4n-prefetch» и подразумевает, что ширина внутренней шины данных оказывается уже не в два, а в четыре раза больше по сравнению с шириной внешней шины данных. Однако речь здесь идет не о дальнейшем увеличении количества единиц данных, передаваемых за такт внешней шины данных — иначе такие устройства уже не именовались бы устройствами «Double Data Rate 2-го поколения». Вместо этого, дальнейшее «уширение» внутренней шины данных позволяет снизить внутреннюю частоту функционирования микросхем DDR2 SDRAM в два раза по сравнению с частотой функционирования микросхем DDR SDRAM, обладающих равной теоретической пропускной способностью. С одной стороны, снижение внутренней частоты функционирования микросхем, наряду со снижением номинального питающего напряжения с 2.5 до 1.8 V (вследствие применения нового 90-нм технологического процесса), позволяет ощутимо снизить мощность, потребляемую устройствами памяти. С другой стороны, архитектура 4n-prefetch микросхем DDR2 позволяет достичь вдвое большую частоту внешней шины данных по сравнению с частотой внешней шины данных микросхем DDR — при равной внутренней частоте функционирования самих микросхем. Именно это и наблюдается в настоящее время — модули памяти стандартной скоростной категории DDR2-800 (частота шины данных 400 МГц) на сегодняшний день достаточно распространены на рынке памяти, тогда как последний официальный стандарт DDR ограничен скоростной категорией DDR-400 (частота шины данных 200 МГц).
DDR2 — это «все та же DDR», мы по-прежнему имеем удвоенную скорость передачи данных за один такт внешней шины данных — иными словами, на каждом такте внешней шины данных мы ожидаем получить не менее двух элементов данных (как всегда, разрядностью, равной разрядности внешней шины данных) при чтении, и обязаны предоставить микросхеме не менее двух элементов данных при записи. В то же время, вспоминаем, что внутренняя частота функционирования микросхем DDR2 составляет половину от частоты ее внешнего интерфейса. Таким образом, на один «внутренний» такт микросхемы памяти приходится два «внешних» такта, на каждый из которых, в свою очередь, приходится считывание/запись двух элементов. Следовательно, на каждый «внутренний» такт микросхемы памяти приходится считывание/запись сразу четырех элементов данных (отсюда и название — 4n-prefetch), т.е. все операции внутри микросхемы памяти осуществляются на уровне «4-элементных» блоков данных. Отсюда получаем, что минимальная величина длины пакета (BL) должна равняться 4. Можно доказать, что, в общем случае, архитектуре «2n n-prefetch» всегда соответствует минимальная величина Burst Length, равная 2n (n = 1 соответствует DDR; n = 2 — DDR2; n = 3 —DDR3).
1.3 DDR3 SDRAM
Стандарт DDR3 на сегодняшний день еще не принят JEDEC, его принятие ожидается ближе к середине текущего года (предположительно, он будет носить имя JESD79-3). Поэтому представленная ниже информация о микросхемах и модулях памяти DDR3 пока что носит предварительный характер.
Начнем с микросхем памяти DDR3, первые прототипы которых были объявлены еще в 2005 году. Доступные сегодня образцы микросхем DDR3 основаны на 90-нм технологическом процессе и характеризуются уровнем питающего напряжения 1.5 В, что само по себе вносит примерно 30% вклад в снижение мощности, рассеиваемой этими микросхемами памяти по сравнению с микросхемами DDR2 (имеющими стандартное питающее напряжение 1.8 В). Полное снижение энергопотребления по сравнению с равночастотной DDR2 достигает примерно 40%, что особенно важно для мобильных систем. Емкости компонентов, предусмотренные предварительными спецификациями JEDEC, варьируются от 512 Мбит до 8 Гбит, тогда как типичные выпускаемые на сегодня микросхемы имеют емкость от 1 до 4 Гбит. Теоретическая пропускная способность микросхем DDR3 вдвое выше по сравнению с DDR2 благодаря использованию рассмотренной выше схемы 8n-prefetch (против 4n-prefetch в DDR2). Количество логических банков в микросхемах DDR3 также увеличено вдвое по сравнению с типичным значением для DDR2 (4 банка) и составляет 8 банков, что теоретически позволяет увеличить «параллелизм» при обращении к данным по схеме чередования логических банков и скрыть задержки, связанные с обращением к одной и той же строке памяти (tRP ). Микросхемы DDR3 корпусируются в FBGA-упаковку, обладающую рядом улучшений по сравнению с DDR2, а именно (рисунок 1.1):
- большим количеством контактов питания и «земли»;
- усовершенствованным распределением питающих и сигнальных контактов, позволяющим достичь лучшее качество электрического сигнала (необходимое для более устойчивого функционирования при высоких частотах);
- полным «заселением» массива, что увеличивает механическую прочность компонента.
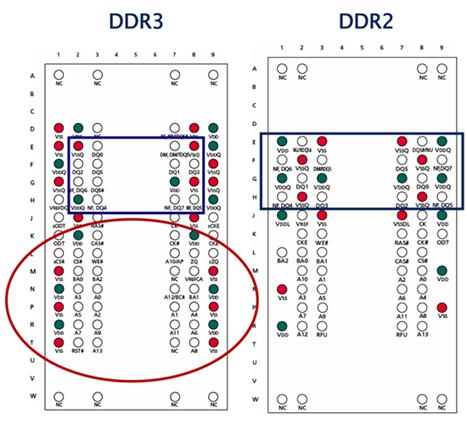
Рисунок 1.1 - Корпусировка микросхем DDR3 и DDR2
Отличительной особенностью схемотехнического дизайна модулей памяти DDR3 является применение «сквозной», или «пролетной» (fly-by) архитектуры передачи адресов и команд, а также сигналов управления и тактовой частоты отдельным микросхемам модуля памяти с применением внешнего терминирования сигналов (резистором, расположенным на модуле памяти). Схематически эта архитектура представлена на рис. 6. Она позволяет добиться увеличения качества передачи сигналов, что необходимо при функционировании компонентов при высоких частотах, типичных для памяти DDR3 и не требуется для компонентов памяти стандарта DDR2.
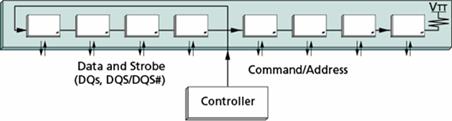
Рисунок 1.2 - «Пролетная» (fly-by) архитектура передачи сигналов в модулях памяти DDR3
Различие между способом подачи адресов и команд, сигналов управления и тактовой частоты в модулях памяти DDR2 и DDR3 (на примере модулей, физический банк которых составлен из 8 микросхем разрядностью x8) представлено на рис. 7.
В модулях памяти DDR2 подача адресов и команд осуществляется параллельно на все микросхемы модуля, в связи с чем, например, при считывании данных, все восемь 8-битных элементов данных окажутся доступными в один и тот же момент времени (после подачи соответствующих команд и истечения соответствующих задержек) и контроллер памяти сможет одновременно прочитать все 64 бита данных.
В то же время, в модулях памяти DDR3 вследствие применения «пролетной» архитектуры подачи адресов и команд каждая из микросхем модуля получает команды и адреса с определенным отставанием относительно предыдущей микросхемы, поэтому элементы данных, соответствующие определенной микросхеме, также окажутся доступными с некоторым отставанием относительно элементов данных, соответствующих предыдущей микросхеме в ряду, составляющем физический банк модуля памяти. В связи с этим, с целью минимизации задержек, в модулях памяти DDR3, по сравнению с модулями DDR2, реализован несколько иной подход ко взаимодействию контроллера памяти с шиной данных модуля памяти. Он называется «регулировкой уровня чтения/записи» (read/write leveling) и позволяет контроллеру памяти использовать определенное смещение по времени при приеме/передачи данных, соответствующее «запаздыванию» поступления адресов и команд (а, следовательно, и данных) в определенную микросхему модуля. Этим достигается одновременность считывания (записи) данных из микросхем (в микросхемы) модуля памяти.
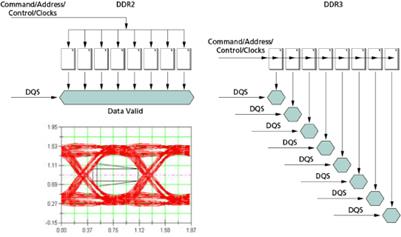
Рисунок 1.3 - Регулировка уровня чтения/записи (read/write leveling) в модулях памяти DDR3
Предположительно, модули памяти DDR3 будут предлагаться в вариантах от DDR3-800 до DDR3-1600 включительно, далее не исключено появление и более высокоскоростных модулей категории DDR3-1866. Рейтинг производительности модулей памяти DDR3 имеет значение вида «PC3-X», где X означает пропускную способность модуля в одноканальном режиме, выраженную в МБ/с (если быть точным — млн. байт/с). Поскольку модули памяти DDR3 имеют ту же разрядность, что и модули памяти DDR2 — 64 бита, численные значения рейтингов равночастотных модулей памяти DDR2 и DDR3 совпадают (например, PC2-6400 для DDR2-800 и PC3-6400 для DDR3-800).
Типичные схемы таймингов, предполагаемые в настоящее время для модулей памяти DDR3, выглядят весьма «внушительно» (например, 9-9-9 для DDR3-1600), однако не стоит забывать, что столь большие относительные значения таймингов, будучи переведенными в абсолютные значения (в наносекундах), учитывая все меньшее время цикла (обратно пропорциональное частоте шины памяти), становятся вполне приемлемыми. Так, например, задержка сигнала CAS# (tCL ) для модулей памяти DDR3-800 со схемой таймингов 6-6-6 составляет 15 нс, что, конечно, несколько великовато по сравнению с «типичными» DDR2-800 со схемой таймингов 5-5-5, для которых tCL составляет 12.5 нс. В то же время, память типа DDR3-1600 со схемой таймингов 9-9-9 уже характеризуются величиной задержки tCL всего 11.25 нс, что находится на уровне DDR2-533 с достаточно низкими задержками (схемой таймингов 3-3-3). Таким образом, даже при предполагаемом на данный момент «раскладе» схем таймингов модулей памяти DDR3 можно ожидать постепенное снижение реально наблюдаемых задержек при доступе в память, вплоть до значений, типичных для нынешнего поколения модулей памяти DDR2. К тому же, не стоит забывать и о дальнейшем снижении задержек (и снижении таймингов) по мере развития технологии.
1.4 RAMBUS (RDRAM)
На данный момент существует только один способ повышения пропускной способности (BW — BandWidth) любой подсистемы — это увеличение либо частоты коммутации шины, либо ее "ширины" (разрядности). Совместное увеличение этих параметров довольно проблематично и имеет быстрое "насыщение", поскольку влияние электромагнитной интерференции (ЭМИ) и частотных эмиссий в этом случае возрастает нелинейно — EMI=kIAf2 . Это обстоятельство вынуждает разработчиков идти на компромиссы. В противовес технологииSDRAM, где используется 64bit магистраль и частоты до 133MHz, Rambus DRAM предоставляет 16bit шину и результирующую частоту обмена до 800MHz, используя технологию DDR, передавая/принимая данные по фронту/срезу синхросигнала. Узкая шина и сверхвысокая частота значительно повышают эффективность использования и загрузку канала, максимально освобождая протокол от временных задержек. Итак, детально рассмотрим технологию Rambus DRAM.
Вообще, существует три разновидности памятиRDRAM, представляющие собой некую эволюцию развития технологии: Base (BRDRAM), Concurrent (CRDRAM) и Direct (DRDRAM). Отличие первого и второго совсем небольшие, а вот изменения последнего просто революционны. Причем, технологии Base и Concurrent настолько сильно переплетаются, что, в принципе, это одно и тоже.
Таблица 1.1
Характеристики различных видов памяти RDRAM
| Основные типы технологии RDRAM | |||
| Параметр | Base RDRAM | Concurrent RDRAM | Direct RDRAM |
| Частота синхронизации | 250-300 MГц | 300-350 MГц | 400 MГц |
| Результирующая частота (с учетом DDR) | 500-600 MГц | 600-700 MГц | 800 MГц |
| Пиковая пропускная способность | 500-600 Mбайт/с | 600-700 Mбайт/с | 1.6 Гбайт/с |
| Шина данных (базовая/ECC) | 8/9 бит | 8/9 бит | 16/18 бит |
| Загрузка 32bit протокола | 60% | 80% | 97-100 % |
| Интерфейс общего питания (CMOS) | 3.3 В | 3.3 В | 2.5 В |
| Размах активных уровней сигналов | 1.0 В | 1.0 В | 0.8 В |
| Диапазон напряжений "точка-точка" (RSL) | 1.5-2.5 В | 1.5-2.5 В | 1.0-1.8 В |
| Опорное напряжение | 2.0 В | 2.0 В | 1.4 В |
| Число высокоскоростных сигналов RSL | 13 | 13 | 30 |
| Число выводов для каждого из каналов | 32 | 32 | 72 |
| Тип корпуса микросхемы RDRAM | SHP/SVP | SHP/SVP | CSP (EBD/CBD) |
Технология DirectRambusDRAM, разработанная компанией Rambus, представляет собой высокоскоростную замкнутую систему функционирования, которая имеет свою адаптированную логику управления и точно рассчитанные параметры. DRDRAM позволяет достичь очень больших пиковых скоростей передачи данных: до 1.6 Гбайт/с на один канал и до 6.4 Гбайт/с при четырех каналах. Вся подсистема состоит из следующих компонентов: основной контроллер (RMC — Rambus Memory Controller), канал (RC — Rambus Channel), разъем для модулей (RRC - Rambus RIMM Connector), модуль памяти (RIMM — Rambus In-line Memory Module), генератор дифференциальных синхроимпульсов (DRCG — Direct Rambus Clock Generator) и сами микросхемы памяти (RDRAM — Rambus DRAM). Физические, электрические и логические принципы и согласования, применяемые в системе, определены компанией Rambus и должны строго выполняться всеми производителями для соблюдения абсолютной совместимости ее частей, так она функционирует на очень большой частоте 600/711/800 МГц, синхронизируясь сигналом 300/350/400 MГц соответственно.
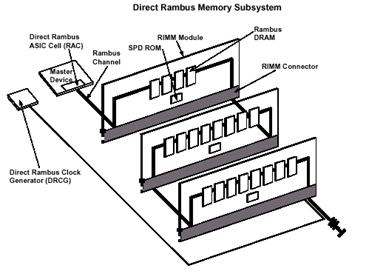
Рисунок 1.4 – Схематическое изображение подсистемы памяти DirectRambus
Сигнальный протокол DirectRambusоснован на новом электрическом интерфейсеRSL (Rambus Signaling Levels), дающем возможность при помощи технологии удвоенной передачи данных (DDR — Double Data Rate) получить результирующую частоту 600/711/800 MГц и использовать стандартный CMOS-интерфейс (см.схему1исхему2) сигналовуправленияядраASIC (Application Specific Integrated Circuit). Высокоскоростной протокол сигналов RSL использует низковольтный размах (Swing) номинальных напряжений логического "0" (VOH =1.8 В) и логической "1" (VOL =1.0 В) с разностью 0.8 В (VCOS =VOH -VOL ).
За счет внешнего опорного напряжения (VREF =1.4 В) стандартного CMOS-интерфейса, генерирующегося при помощи резистивного делителя, логические значения "0" и "1" представляются как 2.5 В (VOH,CMOS ) и 1.7 В (VOL,CMOS ) соответственно, т.е. разрядность составляет все те же 800 мВ, чтобы сохранить совместимость дискретизации уровней.
Меры частотного "разнесения" сигнальных групп вынужденные, и направлены на разделение стандартных сигналов питания/контроля (CMOS), и высокоскоростных (RSL) командных сигналов и интерфейса приема/передачи данных для уменьшения паразитноговоздействия ЭМИ и ВЧ-шумовкоммутаций шины.
Тактовый генератор вырабатывает импульсы с частотой 267-400 MГц, которые распространяются от крайней точки канала к контроллеру (CTM — Clock To Master), где разворачиваются и по другой линии идут в обратном направлении (CFM — Clock From Master), после чего попадают на терминатор (нагрузку, VTERM =1.8 В). Четкое согласование становиться возможным благодаря двум блокам автоподстройки длительности задержки в библиотечном макроядре (RAC —RambusASIC Cell), которые производят синхронизацию исходящих и входящих сигналов: блок передачи (TDLL — Transmit Delay Locked Loop) и блок приема (RDLL — Receive Delay Locked Loop). Передача команд и данных (блок TDLL) основана на эффекте точной 180° квадратурной фазы, выполняемой в цикле CFM. Все сигналы, распространяющиеся по направлению к контроллеру, синхронизируются входящими тактовыми импульсами, а сигналы, исходящие из контроллера — импульсами, идущими по направлению к нагрузке (функции блока RDLL). В процессе работы каждый блок DLL периодически осуществляет частотную ре-калибровку, учитывая условия функционирования, температуру (документ JESD63), возможные девиации напряжения и частоты. Ре-синхронизация (Re-Sync) всех узлов подсистемы, включая физические интерфейсы типа сдвига уровня напряжения и восстановления синхросигналов, представляется отдельным особенным комплексом мер, поскольку с увеличением частоты, длина волны сигнала становиться более короткой относительно собственной сигнальной трассы. В этом случае полагаться на пассивные элементы задержки (например, RC-цепь), помогающие восстановить "плывущий" протокол синхронизации, довольно опасно, учитывая влияние температуры, напряжения и 3s-вариаций (зависимость сечения рассеяния электромагнитной волны от ее частоты).
Непосредственно сам генератор представляет собой отдельную микросхему с внешним интерфейсом 24pin 150mil SSOP, и обеспечивает "гибкий синхронизм" управления по дифференциальному импульсу с минимальным периодом следования импульсов 50ps: вырабатывает синхросигналы, необходимые для функционирования отдельных компонентов памяти, синхронизирует частоту каналов с внешней системой или синхроимпульсами системного процессора, обеспечивает независимое тактирование отдельных каналов. Кроме чего формирователь обеспечивает независимое тактирование отдельных каналов, если это предусмотрено его внутренней схемотехникой, для чего применяется специализированная версия DRCG-D (Dual DirectRambusClock Generator) интерфейса 28pin 170mil TSSOP, поскольку обычно используется правило «один генератор на один канал». Помимо этого DRCG поддерживает коэффициенты умножения частоты 8x, 6x, 4x, 8/3x идва расширенных режима функционирования: режим Clk Stop ("clock off" — прекращение подачи на внешние цепи каналов синхроимпульсов, позволяющее осуществлять быстрые транзакции между периодами clock-off/clock-on и действующее совместно с режимом "дремоты" NAP интерфейсаRDRAM/RAC) и режим Power DowN (переход системы в состояние пониженного энергопотребления для минимизации рассеивания мощности, который действует совместно с режимом деактивации PDN интерфейса RDRAM/RAC). Генератор DRCG-D поддерживает коэффициенты умножения 8, 6, 4, 8/3, 9/2 и 16/3, и частоту синхронизации канала 267-533 MHz. Сигнальный интерфейс генератора предусматривает 20 сигнальных групп (здесь и далее в аналогичном контексте имеется в виду число групп отдельных сигналов без учета разрядности отдельной сигнальной шины).
Внутренние блоки DRCGпредусматривают наличие транзитного (BypassMux), тест (TestMux) и основного (MainMUX) мультиплексоров, дифференциального выходного буфера (DOB— DifferentialOutputBuffer), фазового детектора (fD— PhaseDetector), блока выравнивания фазы сигнала (PhaseAligner) и двух делителей (A/B) во входной цепи внутрикристального блока фазовой автоподстройки частоты (PLL— PhaseLockedLoop), который введен с целью создания петли обратной связи для стабилизации частоты на выходе.
Специальная "усеченная" версия тактового генератора (DRCG-Lite), пакующегося в корпус типа 16pin 225mil TSSOP, рассчитана на применение в системах с "низкочастотным" входом: внешний интерфейс DRCG-Lite содержит опорный вход от внешнего кварцевого резонатора (сигнал XIN), где нижний порог значения входной частоты составляет 14.0625 МГц, а типичный — 18.75 MГц. Также предусмотрен "низкочастотный" опорный выход (сигнал XOUT) для создания петли обратной связи в цепи внешнего резонатора, контролирующую девиации опорной частоты. Кроме этого имеется второй LVCMOS-выход (сигнал LCLK), реализованный по схеме частотного делителя, дающего половину опорной частоты и применяющийся для синхронизации остальных компонентов системы. Lite-генератор примененяется в "изолированных" системах с замкнутым циклом синхронизации (например, в видеоадаптерах), с использованием памяти, работающей в частотном диапазоне 300-400 MГц, и поддерживает коэффициенты умножения частоты 16x и 64/3x.
В составблок-схемы DRCG-Liteвходят: блок формированияисходящих синхроимпульсов (OSC — Output Signal Clocks), умножитель (Multipler), блок ФАПЧ (PLL), делитель выходного OSC-синхросигнала (/2) и два дифференциальных выходных буфера (DOB).
Активная мощность генераторов составляет менее 350 мВт при опорном напряжении (VDD ) 3.3 В. Как дополнение, введен специальный режим спектральной модуляции тактового импульса (SSC — Spread Spectrum Clock) в диапазоне 30-33 КГц для минимизации паразитного воздействия электромагнитной интерференции.
Поскольку DRCG является задающим устройством согласования внешних и внутренних цепей Rambus DRAM, рассмотрим детально схему синхронизации всей подсистемы. Входной сигнал REFCLK подается на преобразователь В, находящийся во входном каскаде ФАПЧ. Делитель А, находящийся в цепи обратной связи ФАПЧ, генерирует промежуточную частотуPLLClk=RefClk*(A/B), где RefClk=PClk*4N/(M*X). Важен также параметрY=4N/(M*X)=RefClk/PClk, характеризующий степень зависимости опорной частоты (RefClk) от частоты синхронизации с внешней системой (PClk). Выводы MULT[1:0], подающие сигнал на вход делителя А, задают коэффициент умножения ФАПЧ:X=A/B.
Частоты PClk и SynClk различаются, однако передаточная логика, входящая в состав контроллера RMC, должна выбрать подходящий делитель M или N таким образом, чтобы выполнялось обязательное условие эквивалентности: PClk/M=SynClk/N. Например, рассмотрим стандартный случай, когда CTM=400 MГц, PClk=133MHz и SynClk=100MHz: получим коэффициенты M=4, N=3 и имеем частотную зависимость PClk/M=SynClk/N=33 МГц. Параметр f@PD характеризует частоту на фазовом детекторе относительно действующей частоты (PClk/SynClk) на делителе (M/N). Фактически, f@PD=PClk/M=SynClk/N.
Блок приложений (Application Unit), входящий в состав RMC.d1, управляет сигналами по линиям M2m1[2:0] (шина соединения блока приложений и блока механизмов, являющаяся входной линией передаточной логики, и определяющая степень значимости коэффициента M), N2m1[2:0] (шина соединения блока приложений и блока механизмов, являющаяся входной линией передаточной логики, и определяющая степень значимости коэффициента N) и MULT[1:0] (шина передачи от блока приложений к DRCG, использующая параметр Х, определяющий степень отношения между PClk и RefClk), передавая их в передаточную логику и компоненты DRCG. Сами входы напрямую связанычастотными отношениями между PClk, SynClk (SClk) и CTM/CTMN (CTMN выступает как негативный "двойник" CTM — особенность дифференциального протокола) через коэффициенты M и N следующими зависимостями: M2m1=(M/2)-1 и N2m1=(N/2)-1.
1.5 FB DIMM (Fully Buffered DIMM)
Необходимость в изменении технологии серверной памяти возникла вот в связи с чем. Чем дальше, тем выше частоты модулей, используемых в серверах. Но с ростом их частоты возникает большое число проблем, связанных с такими физическими эффектами, как всевозможные наводки и перекрестные помехи. Чем выше частота работы памяти, тем сложнее с ними бороться. И в результате имеем следующую ситуацию: чем выше частота работы памяти, тем выше электрическая нагрузка на контроллер памяти, и тем меньше модулей у нас может работать одновременно. Поскольку для серверов большой объем поддерживаемой памяти есть одно из ключевых требований, необходимо как-то выкарабкиваться из этого тупика. Одним из вариантов такого выхода является технология FB DIMM.

Рисунок 1.2 – модули памяти FBDIMM
Суть FB DIMM вполне описывается словом «сериализация». А сама идеология находится вполне в современном духе перехода к последовательным шинам везде, где только можно. В частности, оказалось, что можно и в технологиях, связанных с памятью.
Идея FB DIMM состоит в том, что от общей шины памяти, на которой сидят модули памяти, мы уходим. Поэтому избыточная электрическая нагрузка, которую модули создают на контроллер, перестает быть проблемой. Вместо этого есть две шины (одна на чтение, другая – на запись) на которых сидят не сами массивы ячеек, а только управляющие буферы модуля (AMB в терминологии FB DIMM). Таким образом, питание массивов ячеек контроллером памяти более не осуществляется. Массивы ячеек основаны на технологии DDR2, здесь FB DIMM вполне пересекается с текущими технологиями. Благодаря этому, производителям памяти будет проще перейти на технологию FB DIMM.
Кроме того, все передачи контроллер памяти ведет только в буферы AMB, все данные получает оттуда же.
Все это происходит, повторюсь, по узким высокочастотным шинам. Поскольку технология ECC является присущей абсолютно всем пересылкам данных между AMB и контроллером, появляются дополнительные преимущества типа защиты команд ЕСС кодом. В этом плане FB DIMM меньше подвержены ошибкам, поскольку содержат более развитые технологии контроля ошибок и восстановления данных.
Кроме того, поскольку модуль FB DIMM фактически связан с контроллером только буфером AMB, для такой памяти гораздо проще достигнуть пропускной способности, максимально близкой к теоретической. Например, если у нас в наличии два модуля FB DIMM, мы вполне можем одновременно писать в один и читать из другого.
Кроме всего прочего, использование буфера AMB позволяет полностью скрывать от контроллера такую служебную операцию, как восстановление содержимого ячейки, refresh. Можно скрывать и некоторые другие операции. Более того, команды в модуле FB DIMM конвейеризированы, и можно отдавать следующую команду на фоне выполнения предыдущей.
К достоинствам отнесем и заметно меньшее число контактов, которые нужно разводить: в частности, в презентации от Intel (см. ссылку ниже) приводят пример 69 контактов у FB DIMM модуля против 240 у модуля DDR2. Поэтому вместо двух каналов DDR2 вполне можно разводить четыре канала, и при этом у них разводка будет занимать меньшее число контактов (276 против 480), и к ней предъявляются менее жесткие требования. Ну а результат сравнения пропускной способности двух конкурирующих типов вполне предсказуем: два канала DD2-400 имеют теоретический максимум 6.4GB/sec, а четыре канала FB DIMM способны выдать порядка 17GB/sec.
память голографический молекулярный графеновый
2. Перспективы развития оперативной памяти
2.1 MRAM
MRAM(Magneto-Resistive RAM — «Магниторезистивная RAM» или «Магниторезистивное ОЗУ») — однокристальная полупроводниковаяоперативная память, при производстве которой используются магнитный материал (часто применяемый в магнитных считывающих головках) и переход с магнитным туннелированием — MTJ (Magnetic Tunnel Junction). В основу современной конструкции MRAM положена концепция, разработанная немецким физиком Андреасом Нейем (Andreas Ney) и его коллегами из Института твердотельной электроники им. Пауля Друде, которая была опубликована в октябрьском номере 2003 журнала Nature. Авторы предложили использовать так называемые «программируемые логические элементы» на основе MRAM-памяти. Вычислительное устройство состоит из логических элементов «и», «или», «и-не» и «или-не». Устройство памяти состоит из элементов, у каждого из которых есть два независимых входа и возможны четыре начальные состояния. Элемент MRAM-памяти содержит два разделенных промежутком магнитных слоя. Если магнитные моменты обоих слоев параллельны, электрическое сопротивление всего элемента небольшое, это отвечает состоянию «1». Если антипараллельны — сопротивление велико и это соответствует состоянию «0». Направления магнитных моментов можно менять на противоположные, пропуская электрический ток по каждой из линий. Независимость входов для каждого из магнитных слоев дает возможность иметь четыре начальных состояния: «00», «01», «10» и «11», гдe «00» отвечает состоянию с отрицательной величиной тока через оба магнитных слоя, а «01» — отрицательному току через слой А и положительному через слой В и т.д. Этим можно осуществлять логические операции «и» и «или». Если добавить еще один вход по току, то появится возможность выполнения логических операций «и-не» и «или-не».
Производительность MRAM зависит от структуры и состава MTJ. Исследования, проведенные Renesas Technology Corp. совместно с Mitsubishi Electric, заключались в изучении зависимости величины магниторезистивного соотношения от резистивной поверхности перехода. Продемонстрированные в 2004 прототипы MRAM имеют микроархитектуру 1T-1MTJ (1 транзистор и 1 переход на ячейку памяти); размер магниторезистивного туннеля одного элемента — TMRE (Tunnel Magneto-Resistance Element) тогда составлял 0,26x0,44 µм²; размер ячейки памяти — 0,81 µм².
В 2003 японская компанияNECпредставила на конференции IEEE в Сан-Франциско экспериментальную микросхему MRAM, изготовленной по 0,25-мкм КМОП-технологии и 0,6-мкм технологии MRAM. Структура ячейки памяти включала числовую шину (word line), разрядную шину (bit line) и магнитный туннельный переход (MTJ). Благодаря особой конструкции массива ячеек памяти инженерам NEC удалось добиться заметного снижения паразитных шумов, что привело к улучшению соотношения сигнал/шум во время операции чтения данных и одновременно позволило уменьшить размеры чипа на 20%.
В 2004 компания Renesas Technology продемонстрировала прототип чипа 1 Мбит MRAM, выполненного с использованием 0,13-мкм CMOS технологического процесса. Его характеристики: тактовая частота — 143 МГц при напряжении питания 1,2 В; кол-во циклов перезаписи — свыше 1 трлн (при Т = 150°С без ухудшения характеристик); время чтения данных из ячейки — 5,2 нс.
В последние годы компании Toshiba и NEC разрабатывают MRAM совместно. Согласно опубликованным в феврале 2006 данным, им удалось создать новое изделие, в котором объединены максимальная плотность и наилучшие скоростные показатели операций чтения и записи, достигнутые для MRAM на данный момент. Ее характеристики: объем памяти — 16 Мбит; скорость чтения и записи — 200 Мбит/с (время цикла — 34 нс); напряжение питания — 1,8 В, что делает ее пригодной для мобильных устройств с батарейным питанием. Основная трудность, с которой столкнулись разработчики, была связана с повышением скорости чтения. Цепь, генерирующая магнитное поле для записи, замедляла операцию чтения из ячейки памяти. Решение было найдено в разделении цепей чтения и записи. Помимо увеличения скорости работы, такой прием позволил снизить эквивалентное сопротивление на 38% за счет "разветвления" тока записи.
В июле 2006 компания Freescale Semicondactor (до 2004 была подразделением корпорации Motorola) представила первые промышленные образцы 4 Мбитных чипов MRAM — MR2A16A, обогнав таких гигантов ИТ-индустрии, как HP и IBM, которые планировали начать их выпуск еще в 2004. Начато их промышленное производство на фабрике в Аризоне. Себестоимость производства (~$25) пока еще очень велика, что, тем не менее, считается быстро преодолимым.
Основными достоинствами MRAM, наряду с достигнутым самым высоким быстродействием, являются: практически неограниченное число допускаемых циклов записи/считывания (например, флэш-накопители имеют ограничения в этом плане) и сохранение записей при отключении питания. Это позволяет ей претендовать на роль универсальной памяти, объединяющей свойства DRAM, SDRAM и флэш-памяти. Поэтому предполагается, что MRAM в перспективе смогут заменить не только современные устройства оперативной памяти, но и жесткие диски, в результате чего архитектура ПК существенно упростится.
2.2 Память на основе графеновой наноленты
Инженеры изИнститута физики твёрдого тела им. Макса Планка(Германия) иМиланского технического университета(Италия) сконструировали микроскопические ячейки памяти на основе графеновых нанолент.
Для того чтобы изготовить узкие — шириной менее 20 нм — ленты, авторы расположили на однослойном графене нановолокнаоксида ванадияV2 O5 . Заготовки поместили под пучок ионов аргона, который удалил графен с неприкрытых участков; затем образцы обрабатывались водой для смыва нановолокон. Оставшиеся наноленты имели аккуратные края, что положительно сказывалось на их характеристиках.
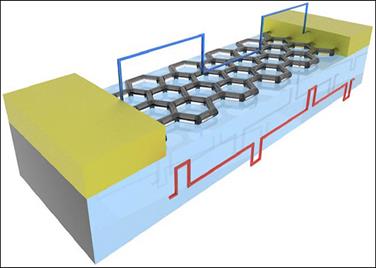
Рисунок 2.1 - ячейки памяти на основе графеновых нанолент
Дальнейшие эксперименты показали, что такие ленты позволяют создавать надёжные ячейки памяти, довольно быстро совершающие переход между двумя состояниями с разной проводимостью. «Эффект памяти, вероятно, связан с влиянием зарядов, захваченных расположенными вокруг нанолент молекулами воды, которые адсорбируются на подложке из диоксида кремния, используемой в наших устройствах», — рассуждает один из авторов Роман Сордан (Roman Sordan).
В опытах переключение между двумя состояниями выполнялось с помощью следовавших с частотой до 1 кГц импульсов длительностью до 500 нс, причём устройства успешно выдержали более 107 циклов переключения. Ячейки памяти на нанолентах также имеют очень небольшие размеры, что учёные считают важным преимуществом своей разработки. «Такие ячейки можно использовать для создания как статической оперативной памяти с произвольным доступом (SRAM), так и энергонезависимой памяти», — отмечает г-н Сордан.
В будущем исследователи намерены приспособить наноленты для изготовления логических вентилей. «Мы уже конструировали графеновые вентили, но наноленты, пожалуй, подходят лучше», — комментирует профессор Сордан.
2.3 Оперативная память на нанотрубках
КомпанияNanteroобъявила о том, что ею ведется разработка нового типа памяти по технологии углеродных нанотрубок (carbon nanotube, CNT). Благодаря такому решению, заявляет производитель, компьютер будет загружаться практически мгновенно, потребляя при этом меньше электроэнергии и выделяя существенно меньше тепла.
Технологии CNT уделяется всё большее внимание со стороны ведущих производителей - компания Motorola работает над топливными элементами, изготовленными с её использованием, Fujitsu планируетохлаждать полупроводникипри помощи нанотрубок, Infineon и Intel ведут разработки, в области задействующих нанотрубки транзисторов, жидкокристаллические дисплеи будущеготакже будут использовать CNT.
Nantero, впрочем, стала первой компанией, которая объявила о том, что выпустит готовую продукцию, произведенную с использованием CNT, которую можно будет купить уже в 2007 году. Президент компании, Грэг Шмергель (Greg Schmergel) сказал, что первым продуктом этой области будет память, объединяющая скорость SRAM со способностью сохранять данные при отключенном питании флэш-памяти. Жизненный цикл памяти такого типа будет многократно превышать то количество циклов записи/стирания, которое свойственно флэш-накопителям. Принцип работы такой памяти заключается в следующем: углеродные нанотрубки находятся в виде суспензии над электродами. Электрические заряды изменяют позицию нанотрубок в двух положениях, каждое из которых определяет значение бита информации, записанной в память. После отключения питания трубки останутся в заданном положении, удерживаемые на молекулярном уровне.
К сожалению, не было приведено точных данных о плотности и скоростных характеристиках чипов CNT-памяти, однако было заявлено о 2 млрд. циклов чтения/записи в секунду. При этом обещается полная совместимость с существующими материнскими платами.
Заметим, что непосредственно Nantero не имеет своего производства, а лишь намерена закупать нанотрубки у сторонних производителей, занимаясь только их упаковкой в чипы. В настоящий момент компания уже имеет рабочие образцы, проходящие испытания. Что же касается цены на принципиально новые модули памяти, то здесь Шмергель также воздержался от конкретики, сказав, что она будет немногим выше, чем на традиционные решения.
Заключение
Сегодня на большинстве компьютеров используется DDR3 SDRAM, однако Intel не успокоилась и принялась за стандарт DDR4, который уже в этом году был реализован. Наученная горьким опытом с Rambus, Intel уже не делает ставку только на DDR4, новые чипы по-прежнему будут поддерживать обычную DDR3. DDR4 также ничего революционно нового не принесла. Однако модули DDR4 несколько отличаются по конструкции и требуют меньшее питание. И снова DDR4 пришел к нам из видеокарт, где появился раньше. AMD и VIA пока что не планируют переход к новой памяти и продолжают использовать DDR3.
Заглядывая дальше в будущее, можно предсказать переход к DDR5, которая уже сейчас используется в видеокартах.
Библиографический список
1. Что такое "оперативная память"? Виды оперативной памяти [Электронный ресурс] / Режим доступа: http://www.vorcuta.ru/computers-articles_ram.htm
2. Современная оперативная память [Электронный ресурс] / Режим доступа: http://www.ixbt.com/mainboard/ram-faq-2006.shtml#pt1_ddr
3. Типы и характеристики оперативной памяти [Электронный ресурс] / Режим доступа: http://www.whatis.ru/hard/mem11.shtml
4. Обзор и практическое тестирование оперативной памяти стандарта DDR3 [Электронный ресурс] / Режим доступа: http://www.rusdoc.ru/articles/16048
5. Изучаем новое поколение памяти DDR SDRAM, теоретически и практически [Электронный ресурс] / Режим доступа: http://www.ixbt.com/mainboard/ddr3-rmma.shtml
6. Технология RAMBUS: теория функционирования [Электронный ресурс] / Режим доступа: http://www.ixbt.com/mainboard/rdram.shtml
Похожие рефераты:
Работа и устройство процессоров
Подбор видеокарты для дизайнерского моделирования
Электронный документооборот страхового общества
Техническая диагностика средств вычислительной техники
Подсистема памяти современных компьютеров
Устройство и назначение системы BIOS ЭВМ
Архитектура и производительность серверных ЦП
Управление оперативной памятью
Базовая система ввода-вывода BIOS
Оперативное запоминающее устройство
Исследование архитектуры современных микропроцессоров и вычислительных систем