| Похожие рефераты | Скачать .docx |
Реферат: Компьютерный анализ текста
Федеральное государственное автономное образовательное учреждение
высшего профессионального образования
"Уральский федеральный университет
имени первого Президента России Б. Н. Ельцина"
Секция информатизации библиотечного дела
Реферат на тему:
Компьютерный анализ текста
Исполнитель: Жданова Юлия Сергеевна,
студентка группы ИТ-47021
Научный руководитель: Гришина С. М., доцент.
Екатеринбург2010
Оглавление
Введение
Глава 1. Анализ текста
Глава 2. Компьютерный анализ текста
2.1 Понятие компьютерного анализа. История развития
2.2 Проблемы компьютерного анализа текста
2.3 Извлечение информации
2.4 Обработка естественного языка
Глава 3. Программы для компьютерного анализа текста
3.1 Машинный перевод
3.2 Лингвистическое программное обеспечение
3.3 Программы для компьютерного анализа текста
Заключение
Библиографический список и сайтография
Введение
Компьютерный анализ текста на естественном языке активно развивается в последние годы многими коллективами. Доступные сегодня вычислительные мощности позволяют применять для обработки больших массивов документов широкий класс математических методов, способствующих эффективному решению задач поиска, классификации, кластерного анализа, выявления скрытых закономерностей в данных и др.
К сожалению, внедрение математических методов в обработку текста происходит в то время, когда собственно лингвистическая составляющая алгоритмов представлена явно недостаточно, и это не позволяет достичь высокого качества работы прикладных систем. Устойчивый уклон в область статистических методов анализа привел к тому, что компьютерная лингвистика оказалась невостребованной. В самом деле, во всех известных русскоязычных системах подобного класса из лингвистического обеспечения используется лишь морфологический словарь, позволяющий отождествлять различные словоформы, тогда как алгоритмы синтаксического анализа реализованы исключительно в автоматических переводчиках и вызывают множество нареканий в связи с невысокой точностью.
Цель , которую поставила перед собой автор данной работы – это выяснить, что такое компьютерный анализ текста.
При этом необходимо решить следующие задачи :
- ознакомиться с понятием анализ текста;
- рассмотреть, что понимается под компьютерным анализом текста;
- ознакомиться с историей развития компьютерного анализа текста;
- выявить проблемы компьютерного анализа текста;
- привести некоторые программы, используемые при компьютерном анализе текста.
Глава 1. Анализ текста
Анализ (греч. "analysis" – разложение) – метод научного исследования (познания) явлений и процессов, в основе которого лежит изучение составных частей, элементов изучаемой системы.
Аналитические методы широко распространены в социуме, поэтому термин "Анализ" часто воспринимается как синоним исследования вообще и особенно при решении познавательных задач. Анализа является составной частью любого научного исследования, образуя, как правило, его первую стадию, когда исследователь выявляет в описании изучаемого объекта его строение, состав, свойства, признаки и т.п. Он используется как метод получения новых результатов в процессе мыслительной деятельности человека.
Мыслительный анализ совершается с помощью понятий и суждений, выражаемых в естественных или искусственных языках. Такой анализ ориентирован на выявление структуры целого, предполагая фиксацию его частей и установление отношений между ними.
В современном обществе важным средством оформления, фиксации, сохранения, передачи информации и обмена ею являются документы.
Анализ документов – это метод сбора первичных данных, при котором документы используются в качестве главного источника информации; это также совокупность методических приёмов и процедур, применяемых для извлечения информации из документальных источников при изучении процессов и явлений в целях решения определённых задач.
Анализ текста - процесс получения высококачественной информации из текста на естественном языке. Как правило, для этого применяется статистическое обучение на основе шаблонов: входной текст разделяется с помощью шаблонов, затем производится обработка полученных данных.
Анализ текста – это процесс получения на естественном языке высококачественной информации из этого текста. Такой анализ осуществляет практически каждый человек не задумываясь, что он делает именно это. Например, любой читатель книги анализирует содержание, читая её по частям. В общем случае всем, особенно трудоспособному населению, постоянно приходится работать с текстовыми и иными видами документов, явно или неявно анализируя их содержание и другие компоненты, например, качество изготовление, форму, размер и т.д. Таким образом, важной задачей практически любых индивидов является нахождение (получение) нужных им документов, а также анализ их содержания на предмет подготовки различных документов (рефератов, аннотаций, справок, отчётов, учебных работ, производственных заданий и др.). При этом нередко возникают ситуации, когда в течение незначительного периода времени необходимо подготовить некоторый (как правило, аналитический) материал. Анализ текстов на естественном языке (ЕЯ) был актуальным практически с момента их появления. При таком анализе необходимо определить правила, с помощью которых, по мнению специалистов, "формальная система (набор структурных элементов текста) преобразуется в систему содержательную (осмысленное сообщение". Анализ текста использовался и продолжает использоваться для классификации текстов, содержащихся в них слов и словосочетаний (например, для определения частоты встречаемости тех или иных терминов в определённых текстах), аннотирования и реферирования текстов, проведения семантически ориентированного поиска текстов по заданным концептам, определения авторского права претендента на соответствующий текст и др.
Считается, что в реальной жизни правила чтения текстов не формализуются. Человек постигает их годами, активно работая в определённой сфере деятельности и предметной области. Специалисты отмечают, что разные контексты порождают различные правила их прочтения, которые со временем меняются, поэтому трудно научить таким правилам компьютер, а значит автоматически учитывать содержательные аспекты обрабатываемого текста.
Глава 2. Компьютерный анализ текста
2.1 Понятие компьютерного анализа текста. История развития
Создание ЭВМ в середине 20-го века и быстрое развитие кибернетических идей стимулировали появление новых наук, которые ранее просто невозможно было представить. Как правило, они возникали на стыке наук, часто не связанных друг с другом. Так, на стыке биологии и инженерных наук возникла бионика, на стыке психологии и лингвистики - психолингвистика, а на стыке вычислительной техники и лингвистики родилась наука, о которой и пойдет речь дальше.
Новая наука несколько раз меняла название: сначала она называлась математической лингвистикой, потом структурной лингвистикой и вычислительной лингвистикой. Наконец за ней прочно укрепилось ее современное название - компьютерная лингвистика.
Две причины обусловили появление новой науки. Во-первых, исследователи-лингвисты надеялись, что современные точные науки (и, прежде всего, математика) помогут лингвистике обрести недостающую ей точность. Появление ЭВМ укрепило эти надежды, так как многим языковедам с самого начала было ясно, что компьютеры - это не только "быстро работающие арифмометры", но и мощное средство для автоматизации работы с текстами. Появилась возможность автоматизировать многие трудоемкие процессы, например, статистическую обработку текстов, ведение разнообразных словарных и лексических картотек.
Во-вторых, с появлением компьютеров почти сразу же возникла проблема общения с ними неподготовленных пользователей. Бесспорно, наилучшей формой для таких пользователей мог быть привычный естественный язык.
К началу 70-х гг. компьютерная лингвистика получила "права гражданства": стали выходить специальные сборники и журналы по компьютерной лингвистике, создавались соответствующие лекции на лингвистических конференциях и конференциях по искусственному интеллекту и, наконец, стали созываться всемирные форумы, посвященные исключительно проблемам этой науки. В большинстве развитых стран начался процесс подготовки специалистов в области компьютерной лингвистики.
В настоящее время в компьютерной лингвистике выделяются несколько основных направлений. Например, анализ текстов на естественном языке.
Лингвисты давно изучают, как устроен текст, и, прежде всего предложение, играющее роль кирпичика, из совокупности которых складывается текст. Но лишь с появлением компьютеров эти исследования приобрели новое направление. Группа американских лингвистов выдвинула дерзкую идею, получившую название Джорджтаунский проект, - автоматизировать процесс перевода текстов с одного языка на другой, используя для этого ЭВМ. Идея заинтересовала лингвистов многих стран и активизировала работы в области анализа текстов. В ходе этих работ надо было ответить на вопрос: "Существуют ли строгие формальные правила, по которым строится структура предложения и структура текста?". Если о структуре предложения лингвисты накопили много материала, то структура текста ими не изучалась.
В результате проведенных исследований стало ясно, что за каждым текстом (в том числе и за отдельным предложением, являющимся своего рода мини-текстом) скрывается не одна, а несколько формальных структур, которые можно разделить на три уровня.
Первый уровень - это поверхностная синтаксическая структура. В этой структуре каждое предложение текста рассматривается изолированно от других и для каждого проводится что-то вроде разбора предложения по его членам, как все мы делали в школе. Но этой структуры для анализа оказывается мало.
Следующий шаг - построение глубинной синтаксической структуры (второй уровень). Идея существования глубинной синтаксической структуры связана с пониманием того, что различные естественные языки, отличаясь друг от друга многими внешними синтаксическими особенностями, передают весь спектр взаимосвязей между объектами, явлениями, их свойствами и протекающими с их участием процессами, характерными для окружающего мира. Рассмотрим как пример две фразы: "Мальчик сорвал цветок" и "Цветок, сорванный мальчиком". Остановимся на уровне синтаксиса. В первом предложении субъект действия "сорвал" - это "мальчик". И это слово играет здесь роль подлежащего, о чем свидетельствует именительный падеж. Во втором же предложении роль подлежащего играет слово "цветок", а слово "мальчик" стоит в творительном падеже. Но субъектом действия "сорвал" и здесь остается все тот же "мальчик". А цветок в любом из двух приведенных предложений играет роль объекта действия. Понимание ситуации, описываемой любым из этих предложений, заключается, в частности, в том, что мы выделяем в тексте некоторое действие, а также его субъект и объект.
Синтаксическая структура, построенная на основе глубинных падежей, позволяет перейти от синтаксического уровня предложения к его семантическому уровню. На этом уровне для анализа привлекаются дополнительные данные, связанные с наличием у лексических единиц языка определенных значений. В семантических структурах (третий уровень формальных структур) также можно выделить поверхностный и глубинный уровни, в чем-то похожие на соответствующие уровни в синтаксических структурах. Например, анализируя фразу: "Женщина пришла домой из магазина очень расстроенная", на поверхностном семантическом уровне мы фиксируем лишь сам факт состояния женщины. На глубинном же семантическом уровне мы сможем высказать предположение о причинах ее состояния - пустые полки магазинов, очереди, отнимающие массу времени и сил. Структуры наиболее "глубокого" уровня, возникающие при анализе предложений, могут быть названы прагматическими. Из них следует понимание того, к чему обязывает или призывает данное предложение. Прагматические структуры устанавливают связь между предложениями в текстах, связывают текст в единое целое, а также побуждают нас делать те или иные действия в реальном мире (как, например, надпись: "Стой! Проход запрещен!"). Чтобы выделить необходимые структуры при автоматическом анализе, надо пройти несколько последовательных этапов:
1) Исходный текст
2) Преданализ
3) морфологический анализ
4) поверхностный синтаксический анализ
5) глубинный синтаксический анализ
6) поверхностный семантический анализ
7) глубинный семантический анализ
8) прагматический анализ
9) выявление текстовых структур.
Указанные этапы охватывают всю задачу анализа текстов на естественном языке. Необходимость в исполнении тех или иных этапов при анализе конкретного текста зависит от тех целей, для которых тот анализ осуществляется.
В компьютерной лингвистике проблемы синтеза текстов сейчас находятся в центре внимания исследователей, и нет сомнений, что в ближайшее время будут найдены эффективные средства для создания текстов на заданную тему.
Это одно из самых молодых направлений в компьютерной лингвистике - это оживление текста. Своим появлением оно обязано персональным компьютерам, которые впервые дали возможность организовать общение с пользователем не только путем обмена текстами, но и посредством зрительных образов на экране дисплея. Одной из особенностей мышления человека (едва ли не основной для возможности самого мышления) является его разномодальность. Психологи пользуются этим термином, чтобы подчеркнуть, что наши представления об окружающем мире и о нас самих могут иметь различную природу (различную модальность). Можно "мыслить словами", но можно представлять себе какие-то зрительные картинки, как часто бывает во снах. Есть люди, для которых многие воспоминания состоят из запахов или вкусовых впечатлений. Словом, все наши органы чувств дают свою модальность в мышлении. Но две модальности: символьная (текстовая) и зрительная - являются для человека основными. Легко проверить, что между этими модальностями имеется весьма тесная связь. Обычно называние чего-то или текстовое описание некоторой ситуации тут же вызывает зрительные представления об этих объектах и ситуациях. И наоборот, стоит нам увидеть нечто, как мы тут же готовы описать увиденное с помощью нашего родного языка. Так текст и сопутствующая ему зрительная картина оказываются объединенными в нашем сознании и интегрированными в некоторое единство. Текст как бы "живет" в виде некоторого образного представления. И изучение того, как происходит эта интеграция и как по одной составляющей представления появляется вторая, - одна из увлекательных задач, стоящих перед специалистами в области компьютерной лингвистики и их коллегами - создателями интеллектуальных систем. Уже найдены некоторые важные законы интеграции текстов и зрительных образов. Созданы первые экспериментальные модели этого процесса и первые интеллектуальные системы, способные описывать в виде текста предъявляемую им картинку (например, пейзаж), а также воссоздавать одну из возможных картин, соответствующих введенному в систему тексту.
2.2 Проблемы компьютерного анализа текста
Компьютерный анализ текста на естественном языке активно развивается в последние годы многими коллективами. Доступные сегодня вычислительные мощности позволяют применять для обработки больших массивов документов широкий класс математических методов, способствующих эффективному решению задач поиска, классификации, кластерного анализа, выявления скрытых закономерностей в данных.
К сожалению, внедрение математических методов в обработку текста происходит в то время, когда собственно лингвистическая составляющая алгоритмов представлена явно недостаточно, и это не позволяет достичь высокого качества работы прикладных систем. Устойчивый уклон в область статистических методов анализа привел к тому, что компьютерная лингвистика оказалась невостребованной. В самом деле, во всех известных русскоязычных системах подобного класса из лингвистического обеспечения используется лишь морфологический словарь, позволяющий отождествлять различные словоформы, тогда как алгоритмы синтаксического анализа реализованы исключительно в автоматических переводчиках и вызывают множество нареканий в связи с невысокой точностью.
Поговорим о проблемах компьютерной лингвистики, касающихся, прежде всего грамматического разбора текста на естественном языке. Создание качественного синтаксического анализатора позволяет надеяться на эффективное решение задачи поиска в информации на естественном языке.
Сложность практической реализации приемлемого анализатора текста обусловлена наличием тесной связи между синтаксисом и надъязыковой семантикой. Для решения проблем (называемых синтаксической омонимией) необходимо создание специального толково-комбинаторного словаря, включающего в себя синтаксическую и семантическую информацию о сочетаемости слов.
Формально целью синтаксического разбора является построение дерева зависимостей между словами во фразе. В случае удачи предложение сворачивается в полносвязное дерево с единственной корневой вершиной. Поскольку одна словоформа может соответствовать нескольким грамматическим формам слова, в том числе для различных слов (например, "стали" у существительного "сталь" и глагола "стать"), в ходе анализа необходимо производить свертку предложения для всех возможных вариантов. Те же из них, которые приводят к максимальной свертке фразы (с минимальным числом висячих вершин), предлагается считать наиболее достоверными при разборе предложения.
Порядок применения правил разбора управляется его алгоритмом, который на каждом шаге проверяет возможность применения следующего правила к очередному фрагменту фразы (двум-трем словам, знакам препинания). В случае удачи фрагмент сворачивается. Обычно это приводит к его замене одним главным словом, т. е. удалением подчиненных слов. После чего разбор продолжается. Если дальнейшее применение правил невозможно, на любом из шагов совершается откат. При этом последний свернутый фрагмент восстанавливается, и предпринимается попытка применить другие правила. Окончательным вариантом разбора следует считать такую последовательность применения правил, которая приводит к максимальной свертке предложения.
Так как процессу разбора соответствует целое дерево вариантов свертки фразы, то производительность алгоритма падает экспоненциально с ростом числа используемых правил и количества слов в предложении. Сложные предложения могут порождать тысячи вариантов разбора, ввиду чего на практике приходится ограничивать допустимое число рассматриваемых вариантов.
Наиболее просто решается проблема выделения в тексте именных групп - устойчивых словосочетаний, состоящих из существительных и связанных с ними прилагательных, например "развитие сельского хозяйства". Такие группы характеризуют содержание текста и служат для тематического индексирования, автоматической рубрикации, уточнения запроса при поиске.
В ходе полного синтаксического разбора фразы возможно установление синтаксических ролей именных групп в предложении. Это позволяет ранжировать их по степени значимости для автора, что соответствует пониманию ключевых идей текста. Наиболее важными являются слова из группы подлежащего, затем сказуемого, прямого дополнения, косвенного дополнения, обстоятельства - таковы особенности русского языка.
Смысловая связь между понятиями предложения в общем случае может быть описана глаголом-предикатом, аргументами которого выступают данные понятия. Установление таких синтактико-семантических связей позволяет сформировать логическую схему ситуации, описываемой во фразе.
Однако для этого требуется словарь моделей управления глаголов. В таком словаре для всех глаголов (около 20 тыс. в русском языке) должно быть указано, какими падежами и с какими предлогами производится это управление.
Вершиной компьютерного анализа текста является автоматическое реферирование. Наличие семантической сети понятий, соединенных глаголами, позволяет сформулировать основные идеи текста документа, отраженные в часто встречающихся понятиях и связях, в виде простых предложений.
Словарь моделей управления и семантической сети с дифференцированными связями значительно облегчает подобный синтез. Отдельной проблемой является выбор оптимального порядка фраз. Возможно, при этом будет полезно знание коммуникативной структуры текста - иерархии тем и рем, которая отражает логику изложения автором материала. Задача тема-рематического анализа решается в ходе синтаксического разбора фразы: понятия из группы подлежащего представляют темы; понятия-дополнения глагола - ремы, которые могут стать темами последующих фраз; обстоятельства - лишь некий фон, на котором развертываются описываемые события.
Общая схема подобного анализа текста приведена на рисунке.
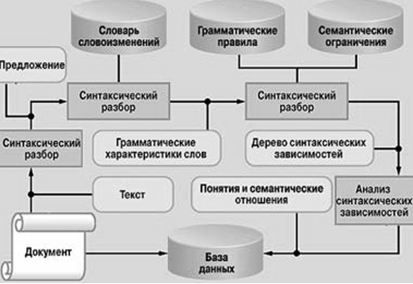
Общая схема синтаксического анализа текста в информационно-поисковой системе
В заключение хотелось бы отметить, что, несмотря на ограниченность синтаксических анализаторов, работающих пока без привлечения семантики, их применение уже сейчас открывает качественно новые возможности для систем компьютерного анализа текста. Синтаксический анализатор русского языка, реализующий выделение именных групп и снятие омонимии, уже внедряется в поисковые системы.
2.3 Извлечение информации
Извлечение информации (англ. information extraction ) - в области обработки естественного языка, это разновидность информационного поиска, при которой из неструктурированного машинно-читаемого текста (то есть электронных документов) выделяется некая структурированная информация, то есть категоризированные, семантически значимые данные по какой-либо проблеме или вопросу. Примером извлечения информации может послужить выискивание случаев деловых визитов - формально это записывается так: Нанесли Визит (Компания-Кто, Компания-Кому, Дата Визита), - из новостных лент, таких как: "Вчера, 1 апреля 2007 года, представители корпорации Пепелац Интернэшнл посетили офис компании Гравицап Продакшнз". Главная цель такого преобразования - возможность анализа изначально "хаотичной" информации с помощью стандартных методов обработки данных. Более узкой целью может служить, например, задача выявить логические закономерности в описанных в тексте событиях.
В современных информационных технологиях роль такой процедуры, как извлечение информации, всё больше возрастает - из-за стремительного увеличения количества неструктурированной (без метаданных) информации, в частности, в Интернете. Эта информация может быть сделана более структурированной посредством преобразования в реляционную форму или добавлением XML разметки. При мониторинге новостных лент с помощью интеллектуальных агентов как раз и потребуются методы извлечения информации и преобразования её в такую форму, с которой будет удобнее работать позже.
· Типичная задача извлечения информации: просканировать набор документов, написанных на естественном языке, и наполнить базу данных выделенной полезной информацией. Современные подходы извлечения информации используют методы обработки естественного языка , направленные лишь на очень ограниченный набор тем (вопросов, проблем) - часто только на одну тему.
Тексты на естественном языке могут потребовать некоего предварительного упрощения, для создания текста, который будет лучше "пониматься" компьютером.
Типичные подзадачи извлечения информации:
· Распознавание именованных элементов: распознавание имён людей, названий организаций, мест, временных обозначений и некоторых типов численных выражений.
· Ссылки: выделение словесных оборотов, ссылающихся на один и тот же объект. Типичный случай таких ссылок - анафора и использование местоимений.
· Выделение терминологии: нахождение для данного текста ключевых слов.
2.4 Обработка естественного языка
Обработка естественного языка - общее направление искусственного интеллекта и математической лингвистики. Оно изучает проблемы компьютерного анализа и синтеза естественных языков. Применительно к искусственному интеллекту анализ означает понимание языка, а синтез - генерацию грамотного текста. Решение этих проблем будет означать создание более удобной формы взаимодействия компьютера и человека.
Задачи и ограничения.
Теоретически, построение естественно-языкового интерфейса для компьютеров - очень привлекательная цель. Ранние системы, такие как SHRDLU, работая с ограниченным "миром кубиков" и используя ограниченный словарный запас, выглядели чрезвычайно хорошо, вдохновляя этим своих создателей. Однако оптимизм быстро иссяк, когда эти системы столкнулись со сложностью и неоднозначностью реального мира.
Понимание естественного языка иногда считают AI-полной задачей, потому как распознавание живого языка требует огромных знаний системы об окружающем мире и возможности с ним взаимодействовать. Само определение смысла слова "понимать" - одна из главных задач искусственного интеллекта.
Сложности понимания.
Качество понимания зависит от множества факторов: от языка, от национальной культуры, от самого собеседника. Вот некоторые примеры сложностей, с которыми сталкиваются системы понимания текстов.
· Предложения "Мы отдали бананы обезьянам, потому что они были голодные" и "Мы отдали бананы обезьянам, потому что они были перезрелыми" похожи по синтаксической структуре. В одном из них местоимение они относится к обезьянам, а в другом - к бананам. Правильное понимание зависит от знаний компьютера, какими могут быть бананы и обезьяны. По нормам русского языка второе предложение некорректно, потому что в нем местоимение ссылается не на последнее подходящее слово, однако в живой речи такое предложение очень даже может встретиться.
· Свободный порядок слов может привести к совершенно иному толкованию фразы: "Бытие определяет сознание" - кто кого определяет?
· В русском языке свободный порядок компенсируется развитой морфологией, служебными словами и знаками препинания, но в большинстве случаев для компьютера это представляет дополнительную проблему.
· В речи могут встретиться неологизмы, например, глагол "Пятидесятирублируй" - то есть высылай 50 рублей. Система должна уметь отличать такие случаи от опечаток и правильно их понимать.
· Правильное понимание омонимов - ещё одна проблема. При распознавании речи, помимо прочих, возникает проблема фонетических омонимов. Во фразе "Серый волк в глухом лесу встретил рыжую лису " выделенные слова слышатся одинаково, и без знания, кто глухой, а кто рыжий, не обойтись (Кроме того, что лиса, может быть, рыжей, а лес - глухим, лес также может быть рыжим (преобладание цвета листвы в лесу), в то время как лиса может быть глухой, что порождает дополнительную проблему, вытекающую из предыдущей).
Глава 3. Программы для компьютерного анализа текста
3.1 Машинный перевод
Машинный перевод - процесс перевода текстов (письменных, а в идеале и устных) с одного естественного языка на другой с помощью специальной компьютерной программы.
Хотелось бы отметить, что вместо "машинного перевода" иногда употребляется слово автоматический, что не влияет на смысл. Однако термин автоматизированный перевод имеет совсем другое значение - при нём программа просто помогает человеку переводить тексты. Автоматизированный перевод предполагает такие формы взаимодействия как:
1) Частично автоматизированный перевод: например, использование переводчиком-человеком компьютерных словарей.
2) Системы с разделением труда: компьютер обучен переводить только фразы жёстко заданной структуры (но делает это так, чтобы исправлять за ним не требовалось), а всё, не уложившееся в схему, отдаёт человеку.
В англоязычной терминологии также различаются термины англ. machine translation, MT (полностью автоматический перевод) и англ. machine-aided или англ. machine-assisted translation (MAT) (автоматизированный); если же надо обозначить и то, и другое, пишут M(A)T.
Если же говорить о качестве перевода, то оно зависит от тематики и стиля исходного текста, а также грамматической, синтаксической и лексической родственности языков, между которыми производится перевод. Машинный перевод художественных текстов практически всегда оказывается неудовлетворительного качества. Тем не менее, для технических документов при наличии специализированных машинных словарей и некоторой настройке системы на особенности того или иного типа текстов возможно получение перевода приемлемого качества, который нуждается лишь в небольшой редакторской корректировке. Чем более формализован стиль исходного документа, тем большего качества перевода можно ожидать. Самых лучших результатов при использовании машинного перевода можно достичь для текстов, написанных в техническом (различные описания и руководства) и официально-деловом стиле.
Применение машинного перевода без настройки на тематику (или с намеренно неверной настройкой) служит предметом многочисленных бродящих по Интернету шуток. Из пространных примеров наиболее известен текст "Гуртовщики Мыши" (перевод компьютерной документации программой Poliglossum на основе медицинского, коммерческого и юридического словарей); из кратких - фраза "My cat has given birth to four kittens, two yellow, one white and one black", которую переводчик компании ПРОМТ превращает в "Моя кошка родила четырёх котят, два желтых цвета, одного белого и одного афроамериканца". Главной причиной того, почему программа перевела именно так, было то, что после слова black нужно было добавить kitten, тогда программа переведёт правильно: "Моя кошка родила четырёх котят: двух жёлтых, одного белого и одного чёрного котёнка".
Чаще всего подобные шутки связаны с тем, что программа не распознаёт контекст фразы и переводит термины дословно, к тому же не отличая собственных имён от обычных слов. Тот же переводчик ПРОМТ превращает "bra-ket notation" в "примечание Кети лифчика", "Lie algebra" - в "алгебру Лжи", "eccentricity vector" - в "вектор оригинальности", "Shawnee Smith" в "индеец племени шони Смит".
Рассказав о качестве перевода, необходимо затронуть и статистический перевод.
Статистический машинный перевод - это разновидность машинного перевода текста, основанная на сравнении больших объёмов языковых пар. Языковые пары - тексты, содержащие предложения на одном языке и соответствующие им предложения на втором, могут быть как вариантами написания двух предложений человеком - носителем двух языков, так и набором предложений и их переводов, выполненных человеком. Таким образом, статистический машинный перевод обладает свойством "самообучения". Чем больше в распоряжении имеется языковых пар, и чем точнее они соответствуют друг другу, тем лучше результат статистического машинного перевода. Под понятием "статистического машинного перевода" подразумевается общий подход к решению проблемы перевода, который основан на поиске наиболее вероятного перевода предложения с использованием данных, полученных из двуязычной совокупности текстов. В качестве примера двуязычной совокупности текстов можно назвать парламентские отчеты, которые представляют собой протоколы дебатов в парламенте. Двуязычные парламентские отчеты издаются в Канаде, Гонконге и других странах; официальные документы Европейского экономического сообщества издаются на 11 языках; а Организация объединенных наций публикует документы на нескольких языках. Как оказалось, эти материалы представляют собой бесценные ресурсы для статистического машинного перевода.
3.2 Лингвистическое программное обеспечение
Лингвистическое программное обеспечение (англ. lingware = linguistic + software) - компьютерные программы и данные, обеспечивающие анализ, обработку, хранение и поиск аудиоданных, рисунков (OCR) и текстов на естественном языке.
Можно выделить следующие виды лингвистического программного обеспечения:
1) Обработка текста на естественном языке:
- Электронныесловари: Викисловарь, Multitrans, GoldenDict, Stardict, dict, ForceMem, ABBYY Lingvo.
- Орфокорректоры (илиспеллчекеры): MS Word, ispell, aspell, myspell.
- Поисковые системы
- Системы машинного перевода: PROMT, Socrat.
- Системы автоматизированного перевода, в т.ч. программы управления памятью переводов - OmegaT, Trados.
2) Системы распознавания символов OCR: Finereader, CuneiForm, Tesseract, OCRopus.
3) Речевые системы:
- Системы анализа речи: Dragon, IBM via voice.
- Системы синтеза речи: Агафон.
- Системы голосового перевода (распознавание и синтез): Speereo.
3.3 Программы для компьютерного анализа текста
1) Обработка текста на естественном языке :
1. 1. Электронные словари :
А) Викисловарь – свободно пополняемый многофункциональный многоязычный словарь и тезаурус, основанный на вики-движке.
В словаре содержатся грамматические описания, толкования и переводы слов. Кроме того, в статьях может отражаться информация об этимологии, фонетических свойствах и семантических связях слов. Таким образом, Викисловарь - попытка объединить в одном продукте грамматический, толковый, этимологический и многоязычный словари, а также тезаурус.
Б) GoldenDict - свободная оболочка для электронных словарей с открытым исходным кодом, поддерживающая многие форматы словарей ABBYY Lingvo, StarDict, Babylon, Dictd, а также произвольных словарных веб-сайтов (Википедия, Викисловарь).
Особенности:
1. Вывод отформатированных статей с ссылками и картинками с помощью движка WebKit.
2. При поиске слов с ошибками используется система морфологии на основе свободной программы для проверки орфографии Hunspell.
3. Индексирование директорий со звуковыми файлами для формирования словарей с произношением слов.
4. При поиске перевода пробелы, знаки пунктуации, диакритические знаки и регистр символов в поисковой фразе не играют роли.
5. При выделении текста появляется всплывающее окно перевода.
На сайте программы можно сразу же получить удобный русско-английский и англо-русский словарь, а также словарь произношений английских слов.
Аналоги: Мультитран, ПРОМТ, ABBYY Lingvo, Atlantida, Apertium, Babylon, Context, Dicto, Google Translate, Lingoes, LiteDict, MultiLex, Pragma, ProLing Office, StarDict, SYSTRAN, TransLite, WiseDict.
В) Stardict - свободная оболочка для электронных словарей с открытым исходным кодом, способная, кроме собственно вывода статей, осуществлять перевод, озвучивать слова, использовать нечёткие запросы и шаблоны, поиск в онлайновых словарях. Разрабатывается на языке C++, с использованием графической библиотеки GTK 2 и кодировки UTF-8.
Возможности. Функция программы сканирование выделенного и отображение результата в всплывающих окнах:
1. Поиск по шаблону. Можно вводить слова, содержащие "*" и "?" как шаблоны.
2. Нечеткий запрос. Можно воспользоваться "нечётким запросом". Он использует алгоритм Левенштейна для подсчёта похожести двух слов, и выдаёт слова, которые наиболее подходят введённому запросу. Для использования этой возможности запрос должен начинаться с "/".
3. Полнотекстовой поиск предназначен для поиска слова в словаре без помощи индекса. Более медленный поиск, но позволяет искать совпадения в текстах статей.
4. Cканирование выделенного. При выделении слова и, в зависимости от настроек, при нажатии клавиш его перевод отображается в всплывающем окне.
5. Управление словарями. Выключение ненужных словарей, а также установка порядок их использования при запросе.
6. Поиск в интернете для различных он-лайн словарей.
7. Произношение слов. При наличии звуковых записей словарь может выполнять произношение слов.
8. Перевод полных текстов, используя интернет-сервисы.
1. 2. Орфокорректоры (или спеллчекеры) :
А) MS Word - Microsoft Word (часто - MS Word, WinWord или просто Word) - это текстовый процессор, предназначенный для создания, просмотра и редактирования текстовых документов, с локальным применением простейших форм таблично-матричных алгоритмов. Текстовый процессор, выпускается корпорацией Microsoft в составе пакета Microsoft Office. Первая версия была написана Ричардом Броди (Richard Brodie) для IBM PC, использующих DOS, в 1983 году. Позднее выпускались версии для Apple Macintosh (1984), SCO UNIX и Microsoft Windows (1989).
Б) aspell - GNU Aspell (или просто Aspell) - свободная программа для проверки орфографии, разработанная для замены Ispell. Это стандартная программа проверки орфографии для системы GNU. Она также компилируется под другие Unix-подобные операционные системы и Microsoft Windows. Основная программа лицензируется на условиях GNU LGPL, а документация - на условиях GNU FDL. Словари для неё доступны примерно на 70 языках. Основной разработчик - Кевин Аткинсон (Kevin Atkinson).
1. 3. Системы автоматизированного перевода, в т.ч. программы управления памятью переводов :
А) OmegaT - система автоматизированного перевода, поддерживающая память переводов, написана на языке Java. Возможности продукта включают сегментацию исходного текста на основе регулярных выражений, использование точных (англ. exact ) и неточных (англ. fuzzy ) соответствий с уже переведенными фрагментами, использование словарей, поиск контекстов в базах данных переводов и работу с ключевыми словами.
Начиная с версии 2.04 OmegaT также может переводить текущий абзац текста через Google Translate.
Для работы OmegaT требуется версия Java 1.4, которая доступна для ОС GNU/Linux, Mac OS X и Microsoft Windows, Windows NT. Может работать с OpenJDK.
OmegaT поддерживает разнообразные форматы исходных документов: текстовые файлы (включая Unicode), файлы HTML/XHTML, StarOffice, OpenOffice.org и OpenDocument (ODF), а также файлы DocBook, MediaWiki, Microsoft OOXML, файлы .po (portable object) для библиотеки интернационализации gettext, XLIFF и текстовые файлы со структурой "Ключ=Значение". С файлами старых проприетарных форматов Microsoft Office (Word, Excel и PowerPoint) OmegaT не может работать непосредственно, их необходимо перевести в формат OpenDocument (например, с помощью OpenOffice.org) или OOXML с помощью Microsoft Office 2007.
Б) Trados - система автоматизированного перевода, первоначально (с 1992 года) разработанная немецкой компанией Trados GmbH. Является одним из мировых лидеров в классе систем Translation Memory (TM, Память переводов).
Система Trados состоит из модулей, предназначенных для перевода текстов различного формата: документов Microsoft Word, презентаций PowerPoint, текстов в формате HTML и других метаданных, документов FrameMaker, InterLeaf и др., а также для ведения терминологических баз данных (модуль MultiTerm). Последняя версия системы, выпущенная независимой компанией Trados - 7.0. Последняя версия Trados на сегодняшний день - SDL Trados Studio 2009.
Принцип работы. Концепция Translation Memory предполагает выявление в переводимом тексте фрагментов, переводы которых уже имеются в базе данных переводов, и за счет этого сокращение объема работы переводчика. Фрагменты, оставшиеся непереведёнными, передаются дальше для ручной обработки переводчику или системе машинного перевода (Machine Translation, MT). Переводчик на этом этапе может выделить вновь переведённые фрагменты и занести новые пары параллельных текстов на двух языках в базу данных. Такая схема наилучшим образом работает в случае однотипных текстов, где повторяемость словосочетаний достаточно высока, т. е. в случае разного рода инструкций для пользователей, технических описаний.
2) Системы распознавания символов OCR :
А) Finereader - система оптического распознавания символов разработанная российской компанией ABBYY.
Возможности. Поддерживает распознавание текста на 186 языках и имеет встроенную проверку орфографии для 38 из них. По некоторым данным, после некоторого обучения системы она может начать распознавать рукописный текст, но его нужно будет учить под почерк пользователя.
Б) CuneiForm - свободно распространяемая открытая система оптического распознавания текстов российской компании Cognitive Technologies.
Первоначально система CuneiForm была разработана компанией Cognitive Technologies как коммерческий продукт. CuneiForm поставлялся с некоторыми моделями сканеров. Однако после нескольких лет перерыва разработки, 12 декабря 2007 года анонсировано открытие исходных текстов программы, которое состоялось 2 апреля 2008 года.
Особенности. CuneiForm позиционируется как система преобразования электронных копий бумажных документов и графических файлов в редактируемый вид с возможностью сохранения структуры и гарнитуры шрифтов оригинального документа в автоматическом или полуавтоматическом режиме. Система включает в себя две программы для одиночной и пакетной обработки электронных документов. CuneiForm - Шрифтонезависимая система.
В) Tesseract - свободная программа для распознавания текстов, разрабатывавшаяся Hewlett-Packard с середины 1980-х по середину 1990-х, а затем 10 лет "пролежавшая на полке". Не так давно (в августе 2006 г) Google купил её и открыл исходные тексты под лицензией Apache 2.0 для продолжения разработки. В настоящий момент программа уже работает с UTF-8, поддержка языков (включая, русский с версии 3.0) осуществляется с помощью дополнительных модулей.
Г) OCRopus - OCR-система на базе не так давно открытого распознающего ядра — tesseract Программный пакет для распознавания текста, развивающийся по принципам Open Source и распространяющееся под Apache License 2.0. По задумке разработчиков, с помощью OCRopus станет возможным определять текстовое содержимое на цифровых изображениях и переводить его в обычный текстовый формат для дальнейшего редактирования. Помимо печатного текста, программа сможет распознавать и рукописные материалы. По состоянию на альфа-релиз, OCRopus использует язык моделирования код из другого проекта поддерживаемого Google OpenFST. OCRopus в настоящее время доступна только для GNU/Linux, но существуют сборки и для Debian GNU/Hurd и Debian GNU/kFreeBSD.
Использование. В настоящее время OCRopus использует только интерфейс командной строки, принимая указания на входные изображения с текстом, и выводя данные в формате hOCR (открытый формат на основе HTML). Если необходим более точный контроль, можно указать в командной строке команды для выполнения конкретных операций (например, распознание одной строки).
Заключение
Подводя итоги можно сказать, что компьютерный анализ текста является значимым приемом изучения специфики текстового воплощения концептуальной картины мира, позволяющим постичь особенности стиля.
В ходе работы были получены следующие результаты:
1. Выявлено, что тема компьютерного анализа текста не весьма изучена, так как нет конкретного определения.
2. Из главы 2, подглавы 2.2 "Проблемы компьютерного анализа текста" видно, что проблем в разработке компьютерного анализа весьма много. Они, конечно, решаются, но не все и в замедленном темпе.
3. Из главы 3 "Программы для компьютерного анализа текста" также видно, каково разнообразие компьютерных программ, которые считывают информацию и позволяют осуществить анализ текста на компьютере.
Полученные данные являются относительно новыми в сфере исследования анализа текстов на компьютерном языке, т.к. представляют собой попытку структурировать имеющиеся знания в данной сфере и синтезировать их с новыми. Преимущества компьютерного анализа перед аналогичным исследованием тестов в ручную, на мой взгляд, очевидны. Он позволяет сэкономить время на структурировании результатов, оформлении их в таблицах, графиках, определениях.
Таким образом, тема "Компьютерный анализ текста" весьма интересна при изучении, и не до конца рассмотрена авторами многих работ. Нет определенного понятия компьютерному анализу текста, нет единого документа, где был бы собран, структурирован материал по заданной теме. Трудности были в том, чтобы отобрать необходимые данные, выделить в них главные особенности, а также сделать отобранный материал доступным, понятным для пользователя.
компьютерный текст орфография перевод
Библиографический список и сайтография
1. Анализ документов [Электронный ресурс]. – Режим доступа: http://inforaz.narod.ru/analiz–2.html (дата обращения: 12.09.2010).
2. Анализ текста [Электронный ресурс]. – Режим доступа: http://ru.wikipedia.org/wiki/%D0%90%D0%BD%D0%B0%D0%BB%D0%B8%D0%B7_%D1%82%D0%B5%D0%BA%D1%81%D1%82%D0%B0 (дата обращения: 16.09.2010).
3. Анисимов Анатолий. Компьютерная лингвистика для всех: мифы. Алгоритмы. Язык [Электронный ресурс] / Анатолий Анисимов. – Режим доступа: http://lib.ru/CULTURE/ANISIMOW/lingw.txt (дата обращения: 20.09.2010).
4. Валгина, Н. С. Теория текста [Текст] : учеб. пособие / Н. С. Валгина. – М. : Логос, 2003. – 280 с.
5. Веб–аналитика [Электронный ресурс]. – Режим доступа: http://ru.wikipedia.org/wiki/%D0%92%D0%B5%D0%B1_%D0%B0%D0%BD%D0%B0%D0%BB%D0%B8%D1%82%D0%B8%D0%BA%D0%B0 (дата обращения: 12.09.2010).
6. Воронько Владимир, Костинский Александр. Компьютерный анализ текстов [Электронный ресурс] / В. Воронько, А. Костинский. – Режим доступа: http://archive.svoboda.org/programs/sc/2001/sc.062601.asp (дата обращения: 19.09.2010).
7. Ермаков, А. Е. Компьютерная лингвистика и анализ текста [Текст] / А. Е. Ермаков // Мир ПК. – 2002. – N9. – С.86-88.
8. Ермаков, А. Е. Компьютерная лингвистика и анализ текста [Электронный ресурс] / А. Е. Ермаков. – Режим доступа: http://www.osp.ru/pcworld/2002/09/163968/ (дата обращения: 11.09.2010).
9. Ермаков, А. Е., Плешко, В. В. Компьютерный анализ текста при сборе информации к досье из открытых источников [Электронный ресурс] / А. Е. Ермаков, В. В. Плешко. – Режим доступа: http://www.rco.ru/article.asp?ob_no=1562 (дата обращения: 29.09.2010).
10. Каневский, Е. А., Саганенко, Г. И. Концептуальное обоснование компьютерного анализа массивов с текстами [Электронный ресурс] / Е. А. Каневский, Г. И. Саганенко. – Режим доступа: http://www.isras.ru/files/File/4M/9/Saganenko,%20Kanaevskij.pdf (дата обращения: 20.09.2010).
11. Компьютерная лингвистика [Электронный ресурс]. – Режим доступа: http://elanina.narod.ru/lanina/index.files/intell/lingvistik.htm (дата обращения: 16.09.2010).
12. Компьютерная лингвистика [Электронный ресурс]. – Режим доступа:http://www.krugosvet.ru/enc/gumanitarnye_nauki/lingvistika/KOMPYUTERNAYA_LINGVISTIKA.html (дата обращения: 06.10.2010).
13. Компьютерный анализ генетических текстов [Электронный ресурс]. – Режим доступа: http://gen–inj.narod.ru/44.htm (дата обращения: 14.09.2010).
14. Николина, Наталия Анатольевна. Филологический анализ текста [Текст] : учеб. пособие для студентов вузов, обучающихся по специальности "Рус. яз. и лит." / Н. А. Николина. – 2–е изд., испр. и доп. – Москва : Академия, 2007. – 272 с.
15. Орлова, О. В. Компьютерный анализ поэтического текста и моделирование ассоциативно–смыслового поля ключевого концепта творчества автора [Электронный ресурс] / О. В. Орлова. – Режим доступа: http://huminf.tsu.ru/e–jurnal/magazine/1/orlova.htm (дата обращения: 11.09.2010).
16. Петров, А. Н. Компьютерный анализ текста [Электронный ресурс] : историография метода / А. Н. Петров. – Режим доступа: http://kleio.asu.ru/aik/krug/3/20.shtml (дата обращения: 19.09.2010).
17. Пятницкая, Анастасия Сергеевна. Программа для поиска фактов в тексте RCO Fact Extractor 1.0 [Электронный ресурс] / А. С. Пятницкая. – Режим доступа: http://www.ko.ru/ru/samizdats/?id=4073 (дата обращения: 29.09.2010).
18. Романова, Т. В. О содержании понятия концептуальный анализ текста [Текст] / Т. В. Романова // Вестник Оренбургского государственного университета. – 2004. – N 1. – С. 20-24.
Похожие рефераты:
Построение систем распознавания образов
Машины, которые говорят и слушают
Электронные словари и их применимость для традиционного машинного перевода
Приемы перевода технической сопроводительной документации
Перевод английской устной речи на русский язык (на примере художественных фильмов)
Способы перевода терминов с английского языка на русский (на материале экономических текстов)
Основы перевода сложных предложений в английском языке
Дидактические подходы к тематическому принципу при обучении переводу
Особенности перевода неологизмов
Особенности перевода научно–технических текстов
Специфика художественного перевода
Дискурсивный анализ как основа перевода художественных текстов