| Похожие рефераты | Скачать .docx |
Реферат: Кодеры речи
Кодеры формы характеризуются способностью сохранять основную форму речевого сигнала. Кодеры формы не являются специфичными для речи в том смысле, что они с успехом работают с любой формой входного сигнала, и их применение ограничено только пределами амплитуды и шириной полосы. Сохраняя огибающую формы сигнала, подобные кодеры работают по принципу выборка-выборка, и их характеристики эффективно измеряются отношением сигнал/шум (ОСШ), так как квантование является основным источником искажений формы выходного сигнала.
ИКМ — первый мировой стандарт кодирования речи со скоростью 64 кбит/с с логарифмическим сжатием (по μ-закону для Северной Америки и А -закону для Европы). ИКМ-кодер является кодером формы и все еще широко используется в цифровых системах. ИКМ со скоростью 64 кбит/с в основном используется как предварительное звено низкоскоростных речевых кодеров, поскольку ее характеристики считаются очень высококачественными. Позже был разработан стандарт на адаптивную дифференциальную ИКМ (АДИКМ) со скоростью 32 кбит/с. Снижение скорости цифрового потока наполовину было достигнуто благодаря использованию адаптивного предсказания и адаптивных квантователей для устранения избыточности речи. Некоторые другие кодеры, например с дельта-модуляцией и плавно изменяющейся крутизной (CVSDM — Continuous Variable Slope Delta Modulation) на скорости 32 кбит/с, используются для решения специфичных задач. Хотя подобные высокоскоростные алгоритмы кодирования малоэффективны, они, тем не менее, остаются самыми эксплуатируемыми системами и, возможно, будут оставаться таковыми еще некоторое время.
Импульсно-кодовая модуляция ИКМ (РСМ – Pulse Code Modulation). Рекомендация G.711
При построении систем цифровой передачи непрерывных сообщений принципиальным моментом является определение полосы частот, требуемой для обеспечения заданного качества воспроизведения переданного сообщения. Вообще говоря, для высококачественной передачи речевого сообщения требуется полоса не менее 10 кГц.
Однако для достижения удовлетворительного уровня разборчивости при передаче речи по телефонным каналам достаточно передать спектр в полосе 300...3400 Гц. Именно такой спектр звуковых частот обычно передается в современных системах передачи речевой информации.
Как правило, максимальная частота передаваемого спектра аудиосигнала выбирается равной ![]() ,а частота дискретизации
,а частота дискретизации ![]() (например, рекомендации G.711, G.721), хотя в ряде случаев с целью повышения качества передачи используются и более высокие значения этих величин (например, рекомендация G.722).
(например, рекомендации G.711, G.721), хотя в ряде случаев с целью повышения качества передачи используются и более высокие значения этих величин (например, рекомендация G.722).
При использовании ИКМ дискретизированное сообщение подвергается квантованию по L
уровням (рис. 1.1), в результате чего каждому значению ![]() ставится в соответствие число
ставится в соответствие число ![]() ,
, ![]() , представленное n
-разрядной комбинацией двоичного кода.
, представленное n
-разрядной комбинацией двоичного кода.
Для достижения приемлемого качества восприятия восстановленного речевого сообщения при равномерном (простом) квантовании необходимо ![]() . Столь большое число
. Столь большое число ![]() уровней квантования при
уровней квантования при ![]() требует скорости передачи символов в канале не менее
требует скорости передачи символов в канале не менее ![]() .
.

Рисунок 1.1
Однако в связи с тем, что при восприятии речи человеческим ухом в области больших мгновенных значений ![]() оказываются допустимыми значительно большие искажения сообщения, чем в области малых мгновенных значений, требуемое число уровней квантования может быть существенно снижено путем использования неравномерного квантования, используя компрессию исходного сообщения по логарифмическому закону с последующим равномерным квантованием при сравнительно малом числе уровней (например, при
оказываются допустимыми значительно большие искажения сообщения, чем в области малых мгновенных значений, требуемое число уровней квантования может быть существенно снижено путем использования неравномерного квантования, используя компрессию исходного сообщения по логарифмическому закону с последующим равномерным квантованием при сравнительно малом числе уровней (например, при ![]() или путем соответствующего цифрового преобразования (цифровой компрессии) сообщения, предварительно преобразованного в цифровую форму при сравнительно большом исходном числе уровней квантования (например, при
или путем соответствующего цифрового преобразования (цифровой компрессии) сообщения, предварительно преобразованного в цифровую форму при сравнительно большом исходном числе уровней квантования (например, при ![]() ).
).
Оптимальный квантователь имеет преимущества, если динамический диапазон входного сигнала фиксирован и достаточно мал. Характеристики квантователя быстро ухудшаются, мощность сигнала изменяется относительно значения, на которое он был рассчитан. Хотя этим процессом можно управлять, нормализуя входной сигнал и приводя его к единому диапазону, для правильного определения масштаба амплитуды восстановленного после квантователя сигнала потребуется дополнительно несколько бит, необходимых для передачи динамического диапазона сигнала в определенные моменты времени.
Для обработки входных речевых сигналов с большим динамическим диапазоном используются два закона сжатия, называемые импульсно-кодовой модуляцией по закону ![]() (А
-ИКМ) и по закону μ (μ-ИКМ). В обеих схемах характеристика отношения сигнал/шум квантования (ОСШкв
) должна быть близка к характеристике для простого квантователя. Вместе с тем характеристики А
-ИКМ и μ-ИКМ существенно не изменяются и остаются сравнительно постоянными в большом диапазоне уровней входного сигнала. По сравнению с простыми квантователями (рис. 1.1) квантователи сжатия требуют меньше бит на входную выборку для определенного динамического диапазона сжатия и меньшего ОСШкв
. В квантователях сжатия уровни квантования находятся в области малых амплитуд, которые увеличиваются при увеличении диапазона входного сигнала. Благодаря этому при квантовании речевых сигналов, у которых максимум функции распределения вероятностей находится в начале координат, наиболее часто встречающиеся малые амплитуды квантуются с большей точностью, чем менее вероятные большие амплитуды, что приводит к значительно лучшим, Чем у простого квантователя, характеристикам.
(А
-ИКМ) и по закону μ (μ-ИКМ). В обеих схемах характеристика отношения сигнал/шум квантования (ОСШкв
) должна быть близка к характеристике для простого квантователя. Вместе с тем характеристики А
-ИКМ и μ-ИКМ существенно не изменяются и остаются сравнительно постоянными в большом диапазоне уровней входного сигнала. По сравнению с простыми квантователями (рис. 1.1) квантователи сжатия требуют меньше бит на входную выборку для определенного динамического диапазона сжатия и меньшего ОСШкв
. В квантователях сжатия уровни квантования находятся в области малых амплитуд, которые увеличиваются при увеличении диапазона входного сигнала. Благодаря этому при квантовании речевых сигналов, у которых максимум функции распределения вероятностей находится в начале координат, наиболее часто встречающиеся малые амплитуды квантуются с большей точностью, чем менее вероятные большие амплитуды, что приводит к значительно лучшим, Чем у простого квантователя, характеристикам.
Сжатие по А -закону определяется зависимостью:
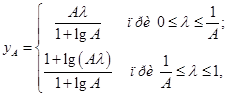 (1.1)
(1.1)
где A — параметр сжатия с типовыми значениями 86 (Северо-Американская ИКМ) и 87,56 (Европейская ИКМ) для семибитных речевых квантователей.
Сжатие по μ-закону определяется выражением
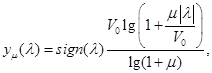 (1.2)
(1.2)
где V0
задается формулой ![]() , в которой L
– нагрузочный фактор, a
, в которой L
– нагрузочный фактор, a ![]() – среднеквадратическое значение входного речевого сигнала.
– среднеквадратическое значение входного речевого сигнала.
Типовое значение фактора сжатия μ равно 255. Выражение (1.1) показывает, что А -закон — это комбинация логарифмической кривой, используемой для больших амплитуд, и линейного участка, используемого на малых амплитудах. μ-закон не является в точности линейным или логарифмическим ни в одном диапазоне, однако является приблизительно линейным для малых амплитуд и приблизительно логарифмическим для больших амплитуд. Сравнение между квантователем по μ-закону и оптимальным квантователем показало, что оптимальный квантователь дает выигрыш 4 дБ, однако может иметь более высокий уровень фонового шума, когда канал свободен, и его динамический диапазон сведен к минимальному диапазону входного сигнала. Поэтому наиболее предпочтителен логарифмический квантователь.
Цифровое преобразование непрерывного речевого сообщения в соответствии с рекомендацией G.711 (рис. 1.2) используется наиболее часто.

Рисунок 1.2
При этом ![]() ; частота дискретизации
; частота дискретизации ![]() . После равномерного квантования при числе уровней
. После равномерного квантования при числе уровней ![]() и предварительного кодирования производится цифровая компрессия, в результате чего длина кодовой комбинации уменьшается до
и предварительного кодирования производится цифровая компрессия, в результате чего длина кодовой комбинации уменьшается до ![]() разрядов. Результатом преобразования является двоичная последовательность, передаваемая со скоростью 64 кбит/с.
разрядов. Результатом преобразования является двоичная последовательность, передаваемая со скоростью 64 кбит/с.
Из различных систем адаптивной ИКМ (АИКМ) наибольшее распространение получила система блочной ИКМ (БИКМ), оторую часто называют системой с почти мгновенным компандированием (NIC — Near Instantaneous Companding).
Отсчеты n -разрядного АЦП разбивают на блоки по N отсчетов. В каждом блоке находят отсчет с максимальным для данного блока уровнем. Этому уровню соответствует определенный номер старшего значащего разряда (j ), и все старшие разряды в комбинациях этого блока будут нулевыми. Записанный в двоичном коде номер этого разряда образует масштабную информацию, которая из-за своей важности, как правило, защищается помехоустойчивым кодом. В результате масштабная информация вместе с проверочными символами образует m -значную комбинацию, которую добавляют к основной информации.
Основная информация формируется выбором k разрядов из n исходных разрядов, причем первым (старшим) разрядом является разряд с номером, описанным в масштабной информации.
Основная информация для каждого из блоков объединяется с масштабной в единый цифровой поток. Результирующая скорость цифрового потока на выходе системы БИКМ ![]() . На практике, как правило, используют следующие параметры:
. На практике, как правило, используют следующие параметры: ![]() .
.
При одинаковых условиях передачи БИКМ дает лучшее качество, чем ИКМ. Поэтому можно снизить скорость передачи до 32.. .56 кбит/с.
Дифференциальная импульсно-кодовая модуляция ДИКМ (DPCM – Differencial Pulse Code Modulation)
Наряду с ИКМ применяются и более эффективные цифровые методы передачи речи. В частности, с целью снижения требований к пропускной способности канала можно использовать наличие корреляции между отчетными значениями передаваемого сообщения. Такой метод называется передачей с предсказанием. При этом последовательность значений ![]() поступает на один вход вычитающего устройства (рис. 1.3,а), в то время как на другой вход поступает предсказанное значение
поступает на один вход вычитающего устройства (рис. 1.3,а), в то время как на другой вход поступает предсказанное значение ![]() , полученное тем или иным методом в устройстве предсказания на основе анализа как предыдущих отсчетных значений сообщения, так и текущих передаваемых значений на входе вычитающего устройства.
, полученное тем или иным методом в устройстве предсказания на основе анализа как предыдущих отсчетных значений сообщения, так и текущих передаваемых значений на входе вычитающего устройства.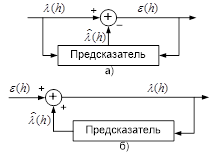
Рисунок 1.3
На приемном конце значения сообщения ![]() восстанавливаются путем добавления принятого сигнала ошибки предсказания
восстанавливаются путем добавления принятого сигнала ошибки предсказания ![]() к предсказываемому значению
к предсказываемому значению ![]() (рис. 1.3,б).
(рис. 1.3,б).
В системе с дифференциальной импульсно-кодовой модуляцией (ДИКМ) отсчетные значения ![]() ошибки предсказания подвергаются квантованию с переходом к значениям
ошибки предсказания подвергаются квантованию с переходом к значениям ![]() аналогично тому, как это делается при использовании обычной ИКМ, однако при существенно меньшем числе уровней квантования. Таким образом, при одинаковом качестве передачи речи метод ДИКМ позволяет использовать меньшее число разрядов n
в кодовых комбинациях по сравнению с ИКМ. При этом существует большое число различных вариантов реализации метода ДИКМ, наиболее типичный из которых представлен на рис. 1.4.
аналогично тому, как это делается при использовании обычной ИКМ, однако при существенно меньшем числе уровней квантования. Таким образом, при одинаковом качестве передачи речи метод ДИКМ позволяет использовать меньшее число разрядов n
в кодовых комбинациях по сравнению с ИКМ. При этом существует большое число различных вариантов реализации метода ДИКМ, наиболее типичный из которых представлен на рис. 1.4.
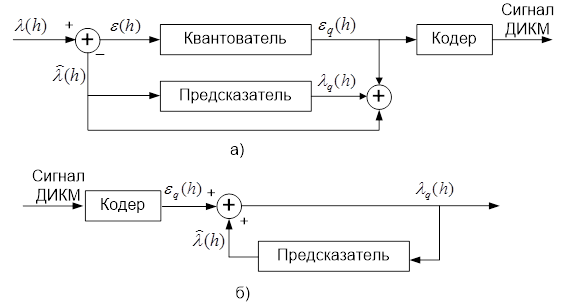
Рисунок 1.4
При этом имеют место соотношения:
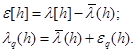 (1.3)
(1.3)
Классификационными признаками кодеров ДИКМ считаются наличие блока линейного предсказания авторегрессионных последовательностей (предсказателя) и использование многоуровневого (больше двух уровней) квантователя. Блок линейного предсказания может состоять из двух частей — долговременного и кратковременного предсказателей. В канал передается разность истинного и предсказанного значений сигнала (сигнал-остаток, он же – погрешность предсказания). Системы с ДИКМ обеспечивают такое качество восстановления сигнала, которое сопоставимо с предоставляемым ИКМ, и на порядок более высокую помехоустойчивость.
Эффективность метода ДИКМ может быть повышена путем пере хода к адаптивной дифференциальной импульсно-кодовой модуляции АДИКМ.
Адаптивная дифференциальная импульсно-кодовая модуляция (ADPCM — Adapti ve Differencial Pulse Code Modulation). Рекомендации G.721 и G.726
ADPCM – один из наиболее общепринятых и давно используемых алгоритмов сжатия речи, который регламентируется стандартом G.726, был принят в 1984 г. Этот алгоритм дает практически такое же качество воспроизведения речи, как и РСМ, однако для передачи информации при его использовании требуется всего 32 кбит/с. Метод основан на том, что в аналоговом сигнале, передающем речь, невозможны резкие скачки интенсивности. Поэтому, если кодировать не саму амплитуду сигнала, а ее изменение по сравнению с предыдущим значением, то можно обойтись меньшим числом разрядов. В ADPCM изменение уровня сигнала кодируется четырехразрядным числом, при этом частота измерения амплитуды сигнала сохраняется неизменной.
Все методы кодирования, основанные на определенных предположениях о форме сигнала, плохо работают в ситуации, когда сигнал может передаваться с резкими скачками амплитуды. Именно такой вид имеет аудиосигнал, генерируемый модемам или факсимильными аппаратами. Современные системы обмена информацией, поддерживающие цифровые линии связи, умеют распознавать факсимильный обмен и передают соответствующие сигналы непосредственно в цифровом виде, не преобразуя их в аудиосигнал.
Нелинейный 15-уровневый адаптивный квантователь используется для квантования разностного сигнала ![]() . Перед квантованием сигнал
. Перед квантованием сигнал ![]() логарифмируется по основанию 2 и масштабируются посредством коэффициента
логарифмируется по основанию 2 и масштабируются посредством коэффициента ![]() , который вычисляется с помощью блока адаптации масштабного коэффициента.
, который вычисляется с помощью блока адаптации масштабного коэффициента.
Для определения квантованного уровня ![]() используются четыре двоичных символа (три для амплитуды и один для знака). Четырехбитовый выход квантователя
используются четыре двоичных символа (три для амплитуды и один для знака). Четырехбитовый выход квантователя ![]() образует выходной цифровой сигнал со скоростью 32 кбит/с, который одновременно подается на инверсный адаптивный квантователь и блок управления скоростью адаптации масштабного коэффициента квантователя.
образует выходной цифровой сигнал со скоростью 32 кбит/с, который одновременно подается на инверсный адаптивный квантователь и блок управления скоростью адаптации масштабного коэффициента квантователя.
Квантованная версия разностного сигнала ![]() формируется путем масштабирования с использованием специальной величины
формируется путем масштабирования с использованием специальной величины ![]() , выделяемой из нормализованной характеристики квантователя, и дальнейшей трансформации результата из логарифмического представления.
, выделяемой из нормализованной характеристики квантователя, и дальнейшей трансформации результата из логарифмического представления.
Блок адаптации масштабного коэффициента квантователя вычисляет ![]() — масштабный коэффициент для квантователя и инверсного квантователя. На его входы подаются четырехбитовые выходные сигналы квантователя
— масштабный коэффициент для квантователя и инверсного квантователя. На его входы подаются четырехбитовые выходные сигналы квантователя ![]() и параметр управления скоростью адаптации
и параметр управления скоростью адаптации ![]() .
.
Основной принцип, реализуемый при масштабировании, заключается в бимодальной адаптации:
– быстрой – для сигналов (например, речевых), которые дают разностные сигналы с большими флуктуациями;
–медленной – для сигналов (например, данных в диапазоне тональных частот, тонов), которые дают разностные сигналы с малыми флуктуациями.
Управление скоростью адаптации производится с помощью комбинации быстрого и медленного масштабных коэффициентов.
Быстрый (нефиксированный) масштабный коэффициент ![]() вычисляется рекурсивно в логарифмическом представлении с основанием 2 из результирующего логарифмического масштабного коэффициента
вычисляется рекурсивно в логарифмическом представлении с основанием 2 из результирующего логарифмического масштабного коэффициента![]() :
:
![]() (1.6)
(1.6)
Как правило, ![]() лежит в пределах
лежит в пределах ![]() . Дискретная функция
. Дискретная функция ![]() определяется табличным образом. Множитель (1 – 2-5
) вводит ограниченную память в процесс адаптации таким образом, что состояния кодера и декодера сходятся при ошибках передачи.
определяется табличным образом. Множитель (1 – 2-5
) вводит ограниченную память в процесс адаптации таким образом, что состояния кодера и декодера сходятся при ошибках передачи.
Медленный (фиксированный) масштабный коэффициент ![]() получается из
получается из ![]() с помощью операции фильтрации нижних частот:
с помощью операции фильтрации нижних частот:
![]() (1.7)
(1.7)
Затем быстрый и медленный масштабные коэффициенты объединяются для получения результирующего масштабного коэффициента:
![]() (1.8)
(1.8)
где ![]() .
.
Управление скоростью адаптации. Предполагается, что управляющий параметр ![]() может принимать значения в диапазоне [0, 1]. Для речевых сигналов он стремится к единице, Для сигналов, данных в диапазоне тональных частот и одночастотных сигналов он стремится к нулю. Величина коэффициента определяется мерой скорости изменения величины разностного сигнала.
может принимать значения в диапазоне [0, 1]. Для речевых сигналов он стремится к единице, Для сигналов, данных в диапазоне тональных частот и одночастотных сигналов он стремится к нулю. Величина коэффициента определяется мерой скорости изменения величины разностного сигнала.
Адаптивный предсказатель и калькулятор восстановленного сигнала. Первоначальная функция адаптивного предсказателя заключается в вычислении оценки ![]() разностного сигнала
разностного сигнала ![]() . Используются две структуры адаптивного предсказателя – каскад первого порядка, моделирующий нули, и каскад второго порядка, моделирующий полюсы во входном сигнале.
. Используются две структуры адаптивного предсказателя – каскад первого порядка, моделирующий нули, и каскад второго порядка, моделирующий полюсы во входном сигнале.
Детектор тона и перехода. С целью улучшения рабочих характеристик для сигналов, поступающих с выходов модемов с частотной манипуляцией, работающих в режиме кодовых комбинаций, определен двухступенчатый процесс декодирования. Сначала производится детектирование сигнала с ограниченной полосой (например, тона), в результате чего квантователь может быть переведен в быстрый режим адаптации.
Упрощенная и развернутая структурные схемы декодера АДНКМ приведены на рис. 1.6,а и 1.7,б соответственно. Декодер включает схему, идентичную цепи обратной связи кодера, преобразователь линейной ИКМ в сигнал по законам А или μ и устройство установки синхронного кодирования.
Устройство установки синхронного кодирования предотвращает накопление искажений, имеющих место при синхронном последовательном кодировании (АДИКМ-ИКМ-АДИКМ, другие цифровые соединения). Установка синхронного кодирования достигается путем подстройки проходного кода ИКМ таким образом, чтобы попытаться устранить искажения квантования в следующем каскаде кодирования АДИКМ.
Функции основных блоков декодера и кодера совпадают и поэтому ниже не рассматриваются.
Вокодер (от английских слов voice – голос и coder – кодировщик) представляет собой устройство, осуществляющее параметрическое компандирование речевых сигналов. Компрессия речевых сигналов на передающем конце канала связи производится в анализаторе, выделяющем из речевого сигнала медленно меняющиеся составляющие, которые передаются по каналу связи в виде кодовых посылок. На приемном конце с помощью местных источников сигналов, управляемых принятыми параметрами, синтезируется речевой сигнал.
Работа вокодеров основана на моделировании человеческой речи с учетом ее характерных особенностей. Вместо непосредственного измерения амплитуды вокодер преобразует входной сигнал в некий другой, похожий на исходный. Причем измеряемые характеристики речевого сигнала используются для подгонки параметров в принятой модели речевого сигнала. Именно эти параметры и передаются приемнику, который по ним восстанавливает исходный речевой сигнал. По существу, речь идет о синтезе речи. Естественно, что измерение искажений отношения сигнал/шум бесполезно для вокодеров, и, следовательно, необходимы другие субъективные оценки, такие, как средняя экспертная оценка, диагностический рифмованный тест, диагностическая оценка приемлемости и др. Вокодеры можно разделить на два класса: речеэлементные и параметрические.
В речеэлементных вокодерах при передаче распознаются произнесенные элементы речи (например, фонемы) и передаются только их номера. На приеме эти элементы создаются по правилам речеобразования или берутся из памяти устройства. Область применения фонемных вокодеров – линии командной связи, речевое управление и говорящие автоматы информационно-справочной службы. Практически в таких вокодерах происходит автоматическое распознавание слуховых образов, а не определение параметров речи.
В параметрических вокодерах из речевого сигнала выделяют два типа параметров:
параметры, характеризующие огибающую спектра речевого сигнала, (фильтровую функцию);
параметры, характеризующие источник речевых колебаний (генераторную функцию), – частота основного тона, ее изменение во времени, моменты появления и исчезновения основного тона, шумового сигнала.
По этим параметрам на приеме синтезируют речь.
По принципу определения параметров фильтровой функции речи различают вокодеры:
• полосные канальные (channel);
• формантные;
• ортогональные;
• липредеры (с линейным предсказанием речи);
• гомоморфные.
В полосных вокодерах спектр речи делится на 7-20 полос (каналов) аналоговыми или цифровыми полосовыми фильтрами. Большее число каналов в вокодере дает большую натуральность и разборчивость. С каждого полосового фильтра сигнал поступает на детектор и фильтр низких частот с частотой среза Fcp . Таким образом, сигналы на выходе каждого канала изменяются с частотой менее Fcp . Их передача возможна в аналоговом или цифровом виде.
В формантных вокодерах огибающая спектра речи описывается комбинацией формант (резонансных частот голосового тракта). Основные параметры формант – центральная частота, амплитуда и ширина полосы частот.
В ортогональных вокодерах огибающая мгновенного спектра раскладывается в ряд по выбранной системе ортогональных базисных функций. Вычисленные коэффициенты этого разложения передаются на приемную сторону. Распространение получили гармонические вокодеры, использующие разложение в ряд Фурье.
Вокодеры с линейным предсказанием (LPC — Linear Prediction Coding, или липредеры, основаны на оригинальном математическом аппарате. Они получили наибольшее распространение и будут ниже рассмотрены более подробно.
Гомоморфная обработка позволяет разделить генераторную и фильтровую функции, образующие речевой сигнал.
Из-за сложности определения параметров генераторной функции появились полувокодеры (VE — Voice Excited Vocoder), в которых вместо сигналов основного тона и тон-шума используется полоса речевого сигнала. Полоса частот до 800. .. 1000 Гц кодируется АДИКМ, АДМ (адаптивная дельта модуляция) или с помощью линейного предсказания малого порядка, а в некоторых моделях передается в аналоговом виде. Известныразныетипыполувокодеров-липредеров: VELP — Voice Excite Linear Prediction; RELP — Residue Excited Linear Prediction.
Вокодеры VELP используют голосовое возбуждение и коэффициент линейного предсказания (КЛП). В вокодерах RELP по исходному сигнал также вычисляются КЛП. Так как КЛП описывает фильтровую функцию, то сигнал ошибки (остатка) предсказания содержит информацию о генераторной функции речи и передается на приемную сторону (возможно ее сжатие методами АДИКМ, АДМ или помощью линейного предсказания малого порядка).
Характеристики вокодеров. Качество речи вокодеров являет функцией скорости передачи, производительности и задержки обработки. Если вокодеры предназначены для телефонии по Интернет, разработчики продукции должны учитывать эти характеристики, между которыми существует строгая зависимость. Например, низкоскоростные вокодеры обычно имеют большую задержку и более низкое качество речи, чем высокоскоростные.
Скорость. Так как вокодер совместно использует канал связи и часто перегруженную сеть предприятия или Интернет с другими информационными потоками, максимальная скорость должна была бы быть как можно ниже, особенно для приложений малых офисов. В настоящее время большинство вокодеров работают на фиксированной скорости вне зависимости от характеристик входного сигнала, однако целью современных разработок являются вокодеры с переменной скоростью. Для приложений по одновременной передаче речи и данных компромиссом является создание алгоритмов сжатия пауз в качестве части стандарта кодирования. Общим решением является использование фиксированной скорости для речи и низкой скорости для фоновых шумов. Способ выполнения механизма сжатия пауз важен для повышения качества передачи речи, однако часто выигрыш от компрессии пауз не реализуется. Проблемой является то, что при больших фоновых шумах сложно провести различия между речью и шумом. Другая проблема заключается в том, что если механизм сжатия пауз неправильно выявил состояние речи, начало речи может быть «отрезано», что значительно ухудшает разборчивость кодированной речи.
| Алгоритм | Описание |
Детектор активности речи (VAD) |
Определяет, является ли входной сигнал речью или фоновым шумом. Если сигнал считается речью, он кодируется на полной фиксированной скорости; если сигнал считается шумом, он кодируется на более низкой скорости |
| Генерация комфортного шума | Механизм действует на стороне приемника для воссоздания основной характеристики фонового шума |
Способ генерации комфортного пума должен быть таким, чтобы кодер и декодер оставались синхронизированными, даже если в течение некоторого интервала времени передача данных не осуществляется. Это позволяет сгладить переходы между сегментами активной и неактивной речи.
Производительность алгоритмa. Вокодеры частот выполняются на основе цифровых сигнальных процессоров (ЦСП). В соответствии с компьютерной терминологией их производительность может быть измерена в млн. операций в секунду, объеме памяти с произвольным доступом ОЗУ и объеме ПЗУ. Производительность определяет стоимость вокодера, поэтому при определении типа вокодера для тех или иных приложений разработчик должен сделать соответствующий выбор. В случаях, когда вокодер совместно использует процессор с другими приложениями, разработчик должен решить, сколько ресурсов можно выделить для вокодера. Вокодеры, использующие менее 15 млн. операций/с, считаются низкопроизводительными. Использующие 30 или более млн. операций/с – высокопроизводительными.
Увеличение производительности приводит к увеличению стоимости и большим затратам энергии. Энергетические затраты важны для приложений в портативной аппаратуре, так как при больших затратах энергии сокращается время между подзарядками батарей или возникает необходимость использовать батареи большей емкости, что, в свою очередь, приводит к большей цене и весу.
При синтезе и исследовании полосных вокодеров и полосных вокодеров с ЛПК используются различные модели речевого процесса. Наиболее точная модель речи представляет собой нестационарный случайный процесс с медленно меняющейся дисперсией и спектральной плотностью. При использовании подобной модели можно получить наиболее точный результат оценки качества вокодера.
Ортогональные вокодеры
Речевой сигнал ![]() можно промоделировать откликом на возбуждающий сигнал линейной системы с импульсной характеристикой
можно промоделировать откликом на возбуждающий сигнал линейной системы с импульсной характеристикой ![]() с переменными параметрами, так что выходной сигнал
с переменными параметрами, так что выходной сигнал ![]() равен свертке возбуждающего сигнала и импульсного отклика голосового тракта при условии, что форма голосового тракта неизменна.
равен свертке возбуждающего сигнала и импульсного отклика голосового тракта при условии, что форма голосового тракта неизменна.
Все разнообразие звуков получается путем изменения формы голосового тракта. Если форма голосового тракта изменяется медленно, то на коротких временных интервалах аппроксимация выходного сигнала сверткой возбуждающего сигнала и импульсного отклика голосового тракта справедлива. Если на коротком отрезке времени входной сигнал является периодическим, с постоянной входной частотой, то выходной сигнал также является периодическим. Такая модель справедлива для описания звонких звуков. Аналогично временному, преобразование речи может быть описано в частотной области, поскольку преобразование Фурье речевого сигнала равно произведению преобразований Фурье возбуждающего сигнала и импульсного отклика голосового тракта.
Частотная характеристика голосового тракта является гладкой функцией частоты и характеризуется акустическими резонансами, называемыми формантными частотами.
Поскольку при изменении различных звуков форма голосового тракта изменяется, то с течением времени будет изменяться и огибающая спектра речевого сигнала. Так, в частности, при изменении периода сигнала, возбуждающего звонкие звуки, частотный разнос между гармониками спектра будет также изменяться.
Таким образом, для адекватного описания речевого сигнала надо не только знать вид его спектра, но и то, как он изменяется во времени.
Основным параметром речевого сигнала, возбуждающего звонкий звук, является разнос гармоник основного тона, а характеристики голосового тракта достаточно полно определяются частотами формант.
Изложенное позволяет сделать вывод об удобстве частотного метода описания и преобразования речевых процессов на основе кратковременного спектрального анализа.
Рассмотрим основные принципы, положенные в основу построения ортогональных вокодеров.
Запишем кратковременное преобразование Фурье ![]() дискретизированного речевого процесса
дискретизированного речевого процесса ![]() в виде
в виде
![]() (2.1)
(2.1)
Здесь ![]() весовая функция, сдвигаемая во времени.
весовая функция, сдвигаемая во времени.
Соотношение (2.1) может быть переписано в двух формах. Первая форма имеет вид свертки
![]() (2.2)
(2.2)
где ![]() – обозначает свертку.
– обозначает свертку.
Реализация (2.2) может быть представлена в виде рис. 2.2,а и означает, что спектр речевого процесса соответствует свертке весовой функции ![]() с сигналом
с сигналом ![]() , промодулированным колебанием
, промодулированным колебанием ![]() .
.
Другая форма записи (2.1) получается, если ее переписать в виде
![]() (2.3)
(2.3)
Система (2.3) может быть реализована в виде, представленном на рис. 2.2,б и означает преобразование речевого сигнала ![]() полосовым фильтром центральной частотой ω и импульсной характеристикой
полосовым фильтром центральной частотой ω и импульсной характеристикой ![]() .
.
Реализации, представленные на рис. 2.2,а,б, отличаются тем, что первом случае используется цифровой фильтр нижних частот с импульсной характеристикой ![]() , а во втором – полосовой фильтр, что удобно при параллельном измерении
, а во втором – полосовой фильтр, что удобно при параллельном измерении ![]() на нескольких частотах ω.
на нескольких частотах ω.
Используя алгоритмы БПФ, оценку кратковременного преобразования Фурье на равноотстоящих частотах ![]() можно записать в виде
можно записать в виде
![]() (2.4)
(2.4)
где ![]()
Формулу (2.4) можно преобразовать к виду
![]()
где
![]() (2.5)
(2.5)
можно рассматривать как характеристику комплексного ПФ с центральной частотой ![]() .
.
Исходный речевой сигнал ![]() можно восстановить, сложив сигналы
можно восстановить, сложив сигналы
на всех выходах гребенки ПФ так, что
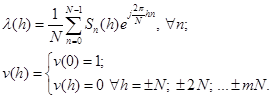 (2.6)
(2.6)
Формула (2.4) является основополагающим уравнением анализа с кратковременным преобразованием Фурье, а формула (2.6) – основным уравнением синтезатора.
Гомоморфные вокодеры
В основе гомоморфных вокодеров лежит метод нелинейной (гомоморфной) фильтрации. Общая структура гомоморфных систем, предназначенных для инверсной фильтрации речевых сообщений, представлена на рис. 2.4.
Свойства системы ![]() определяется соотношением
определяется соотношением ![]() , где
, где ![]() и
и![]() – Z-преобразования
– Z-преобразования ![]() и
и ![]() соответственно.
соответственно.
Сигнал на выходе системы ![]() обычно называют комплексным кепстром. Система
обычно называют комплексным кепстром. Система ![]() является линейной, а система
является линейной, а система ![]() – обратной к системе
– обратной к системе ![]() .
.
Удобства подобных преобразований для анализа и синтеза речевых процессов обусловлены рядом свойств комплексного кепстра. В частности: комплексный спектр последовательностей, имеющих Z-преобразование, в основном сосредоточен вблизи нуля; последовательность, состоящая из равноотстоящих импульсов, имеет комплексный кепстр того же вида; для вычисления комплексного кепстра последовательности с минимальной фазой можно обойтись логарифмом действительной, а не комплексной функции.
Выше было показано, что отрезки речевых сигналов могут быть представлены откликом линейной системы.
Так, в случае звонких звуков возбуждаемый сигнал имеет вид последовательности импульсов. В случае глухих звуков возбуждающий сигнал может быть смоделирован в виде шума.
Обычно предполагают, что передаточная функция линейной системы, имитирующей голосовой тракт, описывается рациональной функцией Z. В результате, согласно перечисленным выше свойствам кепстра, комплексный кепстр импульсного отклика голосового тракта сосредоточен вблизи нуля.
В случае звонкого звука комплексный кепстр возбуждающего сигнала состоит из импульсов, повторяющихся с периодом основного тона. То есть в случае звонкой речи комплексные кепстры возбуждающего сигнала и импульсного отклика голосового тракта занимают неперекрывающиеся временные сигналы и могут быть извлечены из общего кепстра с помощью линейной системы L.
Механизм восстановления речевого сигнала с помощью кепстров может быть пояснен следующим образом.
Поскольку спектр звонкого звука формируется умножением огибающей, характеризующей состояние голосового тракта, на функцию, описывающую тонкую структуру спектра возбуждающего сигнала, то логарифм спектра равен сумме логарифмов огибающей спектра и спектра возбуждающего сигнала.
Логарифм спектра возбуждающего сигнала изменяется с ростом частоты гораздо быстрее логарифма огибающей спектра. Кроме того, он периодичен. В результате обратное преобразование Фурье от логарифма огибающей спектра сконцентрировано по оси времени вблизи нуля, в то время как обратное преобразование от логарифма спектра возбуждающего сигнала является линейчатым, отражающим его периодичность в частотной области.
Для выделения логарифма огибающей спектра из полного спектра логарифма его «взвешивают» окном, открытым только в начальном участке кепстра (вблизи нуля). Эту процедуру называют «сглаживанием кепстра».
В системе анализа-синтеза, основанной на гомоморфной фильтрации, начальные значения кепстра служат параметрами, описывающими состояние голосового тракта или огибающую спектра речевого процесса.
Значения кепстра при больших значениях времени используются для оценки параметров возбуждающего сигнала.
Таким образом, основная идея гомоморфной обработки заключается в разделении или обратной свертке сегмента речевого сигнала с компонентами, представляющими собой импульсную характеристику и источник возбуждения. Это достигается путем линейной фильтрации обратного преобразования Фурье логарифма спектра сигнала (кепстра). Гомоморфные вокодеры, как и любые другие вокодеры, в которых осуществляется разделение параметров речи на сигнал возбуждения и параметры речевого тракта, позволяют достигнуть малой скорости передачи и дополнительной гибкости при обработке речи ценой усложнения алгоритмов преобразований.
Кодирование с линейным предсказанием (LPC — Linear Predictive Coding). Рекомендации G.728, G.729, G.723
При кодировании с линейным предсказанием моделируются различные параметры человеческой речи, которые передаются вместо отсчетов или их разности, требующих значительно большей пропускной способности канала. Следует заметить, что буферы, необходимые для хранения потоков данных, увеличивают задержку кодирования.
Первые реализации LPC, такие как LPC-вокодер, были предназначены ля передачи данных на низких скоростях – 2,4 и 4,8 кбит/с. На скорости 2,4 кбит/с обеспечивался приемлемый уровень разборчивости речи, однако качество, естественность и узнаваемость речи недостаточны. Поскольку этот метод сильно зависит от точного воспроизведения человеческой речи, его реализации, такие как LPC-вокодер, не подходят для сигналов неречевого происхождения, например сигналов модема.
Широко используемый в настоящее время метод кодирования с линейным предсказанием работает с блоками отсчетов, для каждого из которых вычисляется и передается частота основного тона, его амплитуда и информация о типе возбуждающего воздействия.
Структура синтезатора речи с линейным предсказанием показана на рис. 2.5. Здесь управляющий вход или сигнал возбуждения смоделирован в виде последовательности импульсов на частоте основного тона (для вокализованной речи) или случайный шум (для невокализированной речи).
Комбинированные спектральные составляющие потока от голосовых связок, голосового тракта и звукообразования за счет губ могут быть представлены цифровым фильтром с изменяющимися параметрами и передаточной функцией
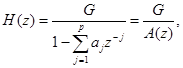 (2.7)
(2.7)
где ![]()
Параметрами, характеризующими голосовой тракт, являются коэффициенты знаменателя и масштабный множитель G.
Преобразуя уравнение (2.7) во временную область, можно получить разностное уравнение для импульсной характеристики ![]() , соответствующей
, соответствующей ![]() :
:
![]() (2.8)
(2.8)
Уравнение (2.8) называют разностным уравнением LPC. Оно устанавливает, что текущее значение выходного сигнала ![]() может быть определено суммированием взвешенного текущего входного значения и взвешенной суммы предыдущих выходных выборок. Следовательно, в LPC анализе проблема может быть сформулирована так: даны измерения сигнала
может быть определено суммированием взвешенного текущего входного значения и взвешенной суммы предыдущих выходных выборок. Следовательно, в LPC анализе проблема может быть сформулирована так: даны измерения сигнала![]() , требуется определить параметры передаточной функции системы
, требуется определить параметры передаточной функции системы ![]() .
.
Линейное предсказание при анализе речевых сигналов обычно используется в двух направлениях. Одно из них – проведение кратковременного спектрального анализа речи. Второе направление – построение систем анализа-синтеза.
Параметры, входящие в функцию предсказания, через формулу (2.7) определяют параметры передаточной функции голосового тракта. Может быть предложено несколько вариантов структуры анализатора, пригодных для построения синтезатора и реализующих передаточную функцию голосового тракта. Структуру прямой формы можно получить непосредственно по коэффициентам функции предсказания. С другой стороны, дробь (2.7) можно преобразовать в произведение и получить структуру каскадной формы.
Во всех случаях параметры синтезатора непрерывно обновляются при смене анализируемых кадров речи. Чтобы избежать эффектов, связанных со скачками значений параметров, необходимо плавно изменять параметры с помощью интерполяции при переходе от одного участка речи к другому. При прямой форме синтеза может возникать ситуация, соответствующая неустойчивому фильтру, хотя исходные значения относились к устойчивому фильтру. В каскадной структуре устойчивость обеспечивается проще.Определение параметров возбуждающего сигнала в системе анализа-синтеза с линейным предсказанием, как правило, основывается на исследовании сигнала ошибки, получаемого пропусканием исходного речевого сигнала через фильтр с характеристикой, обратной той характеристике, которая аппроксимирует передаточную функцию голосового тракта. Полученный сигнал ошибки является аппроксимацией сигнала, возбуждающего речевое колебание. Для определения параметров возбуждающего сигнала можно применить один из известных алгоритмов различения звонкой и глухой речи, а также оценки периода основного тона, например на основе рассмотренного выше корреляционного анализа сигналов во временной области.
Кодирование речи методами анализа через синтез (AbS)
При классификации методов кодирования речи на скоростях 4,8... ...16 кбит/с выделяют две основные группы — методы анализа и синтеза (AaS — Analysis-and-Synthesis) и методы анализа через синтез (AbS – Analysis-by-Synthesis). Хотя такие схемы AaS, как RELP, АРС, АТС и SBC успешно работают на скоростях 9,6... 16 кбит/с, при скоростях ниже 9,6 кбит/с они не могут обеспечивать хорошее качество речи. Это объясняется двумя причинами: 1) кодируемая речь не анализируется на предмет эффективности, т.е. не производится коррекция искажений в восстановленной речи; 2) ошибки, накопленные в предыдущих фреймах, не учитываются в момент анализа текущего фрейма и беспрепятственно переходят в следующие фреймы. В схемах AbS, особенно в AbS-LPC, эти факторы, как правило, учтены. В этих схемах используется процедура оптимизации типа «замкнутая петля» для нахождения возбуждающего сигнала, который при возбуждении моделирующего фильтра создает оптимальный речевой сигнал. Это позволяет схемам AbS более успешно работать на скоростях 4,8.. .9,6 кбит/с.
Методы AbS подходят не только для кодирования речи, но могут также использоваться для оценки и идентификации. Основная идея AbS такова. Во-первых, допускается, что сигнал можно исследовать и представить в какой-либо форме, например в виде временных или частотных доменов. Затем созданная модель сигнала подвергается оптимизации (подгонке), как показано на рис. 2.6.
Модель имеет несколько параметров, изменение которых приводит к изменению формы моделируемого сигнала. Для нахождения модели сигнала, которая имеет ту же форму, что и модель истинного сигнала, используют процедуры минимизации ошибки. Путем изменении параметров модели находят такой их набор, при котором синтезированный сигнал с минимальной погрешностью совпадает с реальным. Следовательно, когда достигнуто такое совпадение, параметры модели принимаются за параметры истинного сигнала.
Базовая структура системы кодирования AbS-LPC представлена на рис. 2.7. В этой модели есть три компонента, которые можно изменять, добиваясь максимального подобия синтезированного сигнала с исходным:
1) нестационарный фильтр;
2) возбуждающий сигнал;
3) процедура минимизации, основанная на восприятии.
Так как эта модель требует частого обновления параметров для получения хорошего совпадения с исходным сигналом, процедура анализа выполняется поблочно, т.е. входной речевой сигнал разбивается на блоки выборок. Длина анализируемых блоков (фреймов) и периодичность их обновления определяют скорость передачи (емкость) схемы кодирования. Алгоритм работы AbS-LPC следующий:
1. Инициализировать LPC и тональный фильтры (нестационарные фильтры), т.е. установить уровень нуля или минимального случайного шума;
2. Фрейм выборок речи заносится в буфер и на основании LPC-анализа вычисляется набор LPC-коэффициентов;
3. Используя вычисленные LPC-коэффициенты, формируется инверсный LPC-фильтр для вычисления первого восстановленного после квантования остатка. Если для поиска подходящего тона используется «замкнутая петля», надобность в этом шаге отпадает.
4. Так как LPC фрейм обычно слишком велик для эффективного анализа, при определении возбуждения фрейм разделяется на целое число подфреймов;
5. Для каждого подфрейма:
а) рассчитываются параметры тонального фильтра (долгосрочного предсказателя), такие, как задержка и связанный с ней коэффициент масштабирования;
б) тональный фильтра вместе с LPC-фильтром образуют каскадный фильтр, с помощью которого определяется наилучшее вторичное возбуждение, т.е. такое, которое минимизирует разницу между синтезированной и исходной речью.
6. Окончательно синтезированная речь получается при пропускании оптимального вторичного возбуждения через каскадный фильтр, параметры которого остались от синтеза предыдущего подфрейма.
7. Повторение шагов 2-6 для следующего фрейма последовательности.
Таким образом, и на стороне кодера, и на стороне декодера синтезируется речь, что необходимо для обновления содержимого памяти нестационарных фильтров. В результате и кодер, и декодер имеют идентичное содержание памяти. В противном случае для общей синхронности содержимое памяти пришлось бы передавать на декодер. Действительно, главный вопрос в схемах AbS-LPC — как сохранить это одинаковое состояние в кодере и декодере, когда средства передачи несовершенны, например, в системах подвижной радиосвязи, где очень высока доля ошибок.
Может показаться, что схема AbS-LPC не является полноценной схемой «анализа через синтез». Это связано с тем, что в действительности процедуры последовательны, т.е. сначала вычисляются параметры фильтра, которые фиксируются, и только затем следует вычисление методом «анализа через синтез» вторичного возбуждения. Хотя вторичное возбуждение выполняется по исходному сигналу, оно ограничено оптимальностью используемых фильтров. Поэтому, в идеале, требуется наилучшая комбинация как возбуждения, так и фильтров, которая означает одновременную оптимизацию всех параметров. Эта процедура очень сложна, насыщена вычислениями, поэтому ее обычно разбивают на последовательные этапы.
Главное отличие классических вокодеров от кодеров AbS-LPC состоит в том, что в классических вокодерах возбуждение разделяется на вокализованные (импульсное возбуждение) и невокализованные (возбуждение случайным шумом), что является первопричиной точности модели. В AbS-LPC такое деление не явно, и поэтому возбуждающий сигнал может носить любой характер — от псевдоимпульсного до шумоподобного, что позволяет синтезировать речь более высокого качества.
Векторное квантование и кодовые книги
Когда набор значений амплитуд, дискретизированных по времени, квантуется совместно как единичный вектор, такой процесс называется векторным квантованием (VQ – vector quantisation), известный также как блочное квантование.
Будем считать, что ![]() N
-мерный вектор с действительными значениями («т» означает транспонирование);
N
-мерный вектор с действительными значениями («т» означает транспонирование); ![]() – случайным образом меняющийся компонент с непрерывной амплитудой. При векторном квантовании вектору
– случайным образом меняющийся компонент с непрерывной амплитудой. При векторном квантовании вектору ![]() ставится в соответствие другой N
-размерный вектор
ставится в соответствие другой N
-размерный вектор ![]() , имеющий действительные значения и дискретную амплитуду. Таким образом,
, имеющий действительные значения и дискретную амплитуду. Таким образом, ![]() квантуется как
квантуется как ![]() . Другими словами,
. Другими словами, ![]() используется для представления
используется для представления ![]() .
.
Обычно ![]() выбирается из конечного набора значений
выбирается из конечного набора значений ![]() , где
, где ![]() – размер кодовой книги, а
– размер кодовой книги, а ![]() – набор векторов кодовой книги. Набор Y
называется кодовой книгой или шаблоном.
– набор векторов кодовой книги. Набор Y
называется кодовой книгой или шаблоном.
Размер кодовой книги можно считать равным числу уровней скалярных квантователей. Для создания подобной кодовой книги N-размерное пространство разделяется на L
областей или ячеек ![]() , и вектор
, и вектор ![]() однозначно связывается с ячейкой
однозначно связывается с ячейкой ![]() . Квантователь обозначается вектором кодовой книги
. Квантователь обозначается вектором кодовой книги ![]() , если
, если ![]() находится в
находится в ![]() :
:
![]() , если
, если ![]() .
.
Процесс создания кодовой книги известен также как «обучение» или «настройка» кодовой книги. В качестве примера на рис. 2.9 иллюстрируется разделение двумерного пространства (N = 2) для целей векторного квантования. Область, обведенная жирной линией, — ячейка ![]() . При векторном квантовании любой входной вектор
. При векторном квантовании любой входной вектор ![]() , лежащий в ячейке
, лежащий в ячейке ![]() , квантуется как
, квантуется как ![]() . Другие векторы кодовой книги, соответствующие другим ячейкам, показаны точками.
. Другие векторы кодовой книги, соответствующие другим ячейкам, показаны точками.
Если размер вектора ![]() , векторное квантование трансформируется в скалярное квантование. Скалярное квантование имеет особое свойство, заключающееся в том, что хотя ячейки могут иметь разные размеры (размеры ступеней), все они имеют одинаковую форму. Однако при векторном квантовании ячейки в двух измерениях могут иметь разные формы, что дает векторному квантованию преимущество над скалярным квантованием.
, векторное квантование трансформируется в скалярное квантование. Скалярное квантование имеет особое свойство, заключающееся в том, что хотя ячейки могут иметь разные размеры (размеры ступеней), все они имеют одинаковую форму. Однако при векторном квантовании ячейки в двух измерениях могут иметь разные формы, что дает векторному квантованию преимущество над скалярным квантованием.
Чтобы избавиться от недостатков кодеров формы и вокодеров, был разработан гибридный метод кодирования, объединяющий преимущества обоих методов. По виду анализа гибридные кодеры подразделяются на два класса: с частотным разделением и временным разделением.
Гибридные кодеры с частотным разбиением
Главная концепция кодирования с частотным разбиением состоит в разделении речевого спектра на частотные полосы или компоненты. Соответственно могут использоваться либо набор фильтров, либо блок-преобразователь. После кодирования и декодирования эти составляющие используются для точного воспроизведения модели входного сигнала путем суммирования сигналов, полученных на выходе фильтров, или инверсных значений, полученных после преобразования. Главное допущение при кодировании с частотным разбиением состоит в том, что сигнал, подвергаемый кодированию, очень медленно изменяется во времени и может быть описан мгновенным спектром. Это связано с тем, что в большинстве систем, а особенно в системах реального времени, в текущий момент доступен только кратковременный сегмент входного сигнала.
В случае использования набора фильтров частота ω фиксирована, так что ![]() , а сигнал частотного домена
, а сигнал частотного домена ![]() представляет собой сигнал на выходе постоянного во времени линейного фильтра с импульсной характеристикой
представляет собой сигнал на выходе постоянного во времени линейного фильтра с импульсной характеристикой ![]() , возбуждаемого модулированным сигналом
, возбуждаемого модулированным сигналом ![]() :
:
![]() (3.1)
(3.1)
где ![]() определяет ширину полосы речевого сигнала
определяет ширину полосы речевого сигнала ![]() вокруг центральной частоты
вокруг центральной частоты ![]() и является импульсной характеристикой анализирующего фильтра; знак
и является импульсной характеристикой анализирующего фильтра; знак ![]() означает свертку функций.
означает свертку функций.
При использовании блока, реализующего преобразование Фурье, временной индекс h
фиксируется на значении h = ho
, a ![]() представляет собой обычное преобразование Фурье взвешенной последовательности
представляет собой обычное преобразование Фурье взвешенной последовательности ![]() :
:
![]() (3.2)
(3.2)
где ![]() – преобразование Фурье.
– преобразование Фурье.
Здесь ![]() определяет отрезок времени анализа относительно момента времени h = ho
и является «окном анализа»
определяет отрезок времени анализа относительно момента времени h = ho
и является «окном анализа» ![]() .
.
Уравнение синтезирующего набора фильтров
![]() (3.3)
(3.3)
может быть представлено как интеграл (или сумма) компонентов – кратковременных спектров ![]() с несущими частотами
с несущими частотами ![]() .
.
Для синтеза с помощью блока преобразования уравнение выглядит следующим образом:
![]() (3.4)
(3.4)
Его можно интерпретировать как сумму инверсных преобразований Фурье, примененных к временным сигналам ![]() .
.
CELP (Code Excited Linear Prediction)
Метод кодирования CELP основан на линейной авторегрессионной модели процесса формирования и восприятия речи и входит в группу методов анализа через синтез, реализующих современные и эффективные алгоритмы информационного сжатия речевых сигналов. Алгоритмы данного класса занимают промежуточное положение между кодерами формы сигнала, в которых сохраняется форма колебания речевого сигнала в процессе его дискретизации и квантования, и параметрическими вокодерами, основанными на процедурах оценки и кодирования небольшого числа параметров речи, объединяя преимущества каждого из них.
Линейная авторегрессионная модель процесса формирования речевых сигналов с локально постоянными на интервалах 10. . .30 мс параметрами получила в настоящее время наибольшее распространение. Для этой модели
![]() (3.5)
(3.5)
где М
— порядок модели; ![]() – последовательность отсчетов речевого сигнала;
– последовательность отсчетов речевого сигнала; ![]() – коэффициенты линейного предсказания, характеризующие свойства голосового тракта;
– коэффициенты линейного предсказания, характеризующие свойства голосового тракта; ![]() – порождающая последовательность или сигнал возбуждения голосового тракта.
– порождающая последовательность или сигнал возбуждения голосового тракта.
Авторегрессионная модель речевого сигнала описывает его с достаточно высокой степенью точности и позволяет применять развитый математический аппарат линейного предсказания. При этом обеспечивается более высокое качество декодированной речи, устойчивость к входному акустическому шуму и ошибкам в канале связи по сравнению с системами с иными принципами кодирования.
В рамках данной модели наиболее перспективными методами кодирования считаются методы «анализа через синтез» с использованием многоимпульсного возбуждения. Новизна многоимпульсного возбуждения заключается в том, что в сигнале остатка линейного предсказания выбираются такие его значения, которые наиболее важны для повышения качества синтезированной речи. При этом используемая в процедуре анализа через синтез схема кодирования, помимо учета ошибок квантования, включает критерии субъективной оценки качества речевого сигнала, что обеспечивает естественное звучание синтезированной речи.
При многоимпульсном возбуждении сигнал остатка линейного предсказания представляется в виде последовательности импульсов с неравномерно распределенными интервалами и с различными амплитудами (около 8-10 импульсов за 10 мс). Амплитуды и положение этих импульсов определяются на покадровой основе (кадр за кадром). Основным преимуществом многоимпульсного возбуждения является то, что она определяется для любого речевого сегмента и при этом не требуется знаний ни о вокализованности данного сегмента, ни о периоде основного тона.
Методы анализа через синтез используют синтезатор (декодер) речевого сигнала как составную часть устройства кодирования. При этом задача анализа сводится к процедуре оценки передаваемых в канал связи параметров речи, проводимой в соответствии с некоторым критерием рассогласования между исходным и декодированным сигналами. Для учета специфики слухового восприятия в качестве критерия рассогласования обычно используется взвешенная по частоте квадратическая ошибка
![]() (3.6)
(3.6)
где ![]() и
и ![]() – преобразование Фурье исходного и синтезированного речевых сигналов;
– преобразование Фурье исходного и синтезированного речевых сигналов; ![]() – весовая функция. Принимая во внимание важность для восприятия речи не только формант, но и межформантных областей, для алгоритмов анализа речи через синтез в качестве эталонной была предложена весовая функция следующего вида:
– весовая функция. Принимая во внимание важность для восприятия речи не только формант, но и межформантных областей, для алгоритмов анализа речи через синтез в качестве эталонной была предложена весовая функция следующего вида:
![]() (3.7)
(3.7)
где ![]() – передаточная характеристика синтезирующего фильтра; γ – параметр, регулирующий энергию ошибки или шум квантования. Фактически при таком окне взвешивания подчеркивается ошибка в межформантных областях и тем самым обеспечивается более равномерное по частоте распределение отношения мощности полезного сигнала к мощности ошибки кодирования.
– передаточная характеристика синтезирующего фильтра; γ – параметр, регулирующий энергию ошибки или шум квантования. Фактически при таком окне взвешивания подчеркивается ошибка в межформантных областях и тем самым обеспечивается более равномерное по частоте распределение отношения мощности полезного сигнала к мощности ошибки кодирования.
В алгоритмах кодирования с «анализом через синтез» повышение эффективности информационного уплотнения речевых сигналов производится, преимущественно, за счет сокращения избыточности последовательности x(h)
, которая осуществляет возбуждение синтезирующего фильтра ![]() линейного предсказания, формирующего огибающую сигнала, с коэффициентом передачи
линейного предсказания, формирующего огибающую сигнала, с коэффициентом передачи
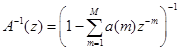 (3.8)
(3.8)
Для этой цели применяется также дополнительный фильтр с характеристикой
![]() (3.9)
(3.9)
с коэффициентом предсказания ![]() и задержкой на период основного тона T
. Фильтр выполняет функции генератора квазипериодических колебаний голосовых связок при произношении вокализованных звуков.
и задержкой на период основного тона T
. Фильтр выполняет функции генератора квазипериодических колебаний голосовых связок при произношении вокализованных звуков.
В зависимости от способа описания сигнала x(h) , поступающего на вход фильтра (3.9), можно выделить алгоритмы кодирования:
с возбуждением прореженной последовательности импульсов — MPLP (Multi Pulses Linear Prediction);
ссамовозбуждением — SELP (Self Excited Linear Prediction);
с кодовым возбуждением — CELP
Экспериментально установлено, что кодовое возбуждение обеспечивает наиболее высокое качество кодирования речевого сигнала, в том числе и при наличии входных акустических помех.
CELP наиболее эффективно применяется при передаче речевого сигала в диапазоне скоростей от 4 до 6 кбит/с.
По существу, в алгоритме CELP производится векторное квантование последовательности ![]() , т.е. позиции выборок и их амплитуды в сигнале многоимпульсного возбуждения оптимизируются одновременно. При том отрезок (сегмент) сигнала возбуждения выбирается из предварительно формированной постоянной совокупности – кодовой книги, содержащей достаточно большое количество реализаций, например, некоррелированного гауссовского шума. Выбранная реализация усиливается и подается на вход цепочки фильтров (3.9) и (3.8).
, т.е. позиции выборок и их амплитуды в сигнале многоимпульсного возбуждения оптимизируются одновременно. При том отрезок (сегмент) сигнала возбуждения выбирается из предварительно формированной постоянной совокупности – кодовой книги, содержащей достаточно большое количество реализаций, например, некоррелированного гауссовского шума. Выбранная реализация усиливается и подается на вход цепочки фильтров (3.9) и (3.8).
Поиск оптимальных значений ![]() и Т
синтезатора основного тона, коэффициента усиления и номера элемента кодовой книги осуществляется посредством «анализа через синтез». В канал связи передаются номер (индекс) элемента кодовой книги с соответствующим коэффициентом усиления, параметры синтезатора основного тона, а также коэффициенты линейного предсказания, характеризующие состояние голосового тракта.
и Т
синтезатора основного тона, коэффициента усиления и номера элемента кодовой книги осуществляется посредством «анализа через синтез». В канал связи передаются номер (индекс) элемента кодовой книги с соответствующим коэффициентом усиления, параметры синтезатора основного тона, а также коэффициенты линейного предсказания, характеризующие состояние голосового тракта.
Являясь одной из самых распространенных, схема с линейным предсказанием и возбуждением от кода CELP является лучшей схемой AbS-LPC для низких скоростей. В CELP имеется линейный фильтр с изменяющимися во времени параметрами для выделения грубой и точной спектральной информации. Возбуждение выполняется путем перебора всех векторов из возбуждающей кодовой книги. Векторная последовательность, обеспечивающая минимальную взвешенную ошибку, считается оптимальным возбуждением. Процедура AbS в CELP требует больших вычислительных ресурсов, а основная кодовая книга является результатом очень большой исследовательской работы. Хотя CELP является сложным методом, он способен синтезировать речь с высоким качеством даже на низких скоростях. Вариант кодирования CELP выбран для многих систем голосовой связи.
Хотя CELP, главным образом, ориентирован на низкие скорости, на нем базируются многие стандарты. Испытания показывают его приемлемость и для высоких скоростей. Стандарт для скорости 16 кбит/с с малой задержкой (LD-CELP — Low-Delay CELP) будет рассмотрен ниже.
Рекомендации G.723.1 и G.729
Рекомендация G.723.1 определяет кодовое представление, которое может использоваться на очень низких скоростях для компрессии речевых или других аудиосигналов в средствах мультимедиа. В кодере, реализующем рекомендации G.723.1, принципиальным приложением является низкоскоростная видеотелефония как часть общего семейства стандартов Н.324.
Кодер обеспечивает работу на двух скоростях — 5,3 и 6,3 кбит/с. Более высокая скорость обеспечивает лучшее качество. Тем не менее, и более низкая скорость обеспечивает хорошее качество и предоставляет разработчикам систем связи дополнительные возможности. И кодер и декодер должны обязательно поддерживать обе скорости. Существует возможность переключения скоростей. Возможно также изменение рабочей скорости с использованием прерывистой передачи и заполнение шумом пауз.
Кодер G.723.1 оптимизирован для сжатия речи с высоким качеством на установленной скорости при ограниченной полосе. Музыка и другие аудиосигналы также могут быть подвергнуты компрессии с использованием этого кодера, однако, не с таким же высоким качеством, как речь.
Кодер G .723.1 преобразует речь или другие аудиосигналы во фреймы длительностью 30 мс. Кроме того, существует возможность просмотра фреймов на скорости 7,5 мс, что приводит к общей алгоритмической задержке 37,5 мс. Дополнительные задержки возникают из-за:
времени, затрачиваемого на обработку данных в кодере и декодере;
времени передачи по линии связи;
дополнительной буферной задержки протокола мультиплексирования.
Кодер G.723.1 предназначен для работы с цифровыми сигналами после предварительной фильтрации полосы аналогового телефонного канала (рекомендации G.712), дискретизации с частотой 8 кГц и преобразования в 16-битную линейную ИКМ последовательность для передачи на вход кодера. Выходной сигнал декодера преобразуется обратно в аналоговый сигнал аналогичным образом. Другие характеристики входа/выхода такие же, как и определенные рекомендациями G.711 для 64-битной ИКМ. Перед кодированием данные должны быть преобразованы в 16-битную ИКМ последовательность или в соответствующий формат после декодирования из 16-битной ИКМ.
Кодер, основанный на принципах кодирования методом «анализ через синтез» с линейным предсказанием, минимизирует взвешенный сигнал ошибки, работает с блоками (фреймами) по 240 выборок каждый, что в частоте дискретизации 8 кГц эквивалентно длительности 30 мс. Каждый фрейм проходит через фильтр верхних частот для удаления постоянной составляющей, а затем разделяется на четыре субфрейма по 60 выборок в каждом. Для каждого субфрейма используется фильтр десятого порядка кодера с линейным предсказанием. Для последнего субфрейма коэффициенты LPC-фильтра квантуются с использованием прогнозирующего квантизатора вектора разбиения (PSVQ). Квантованные LPC-коэффициенты используются для создания кратковременного взвешивающего фильтра, который применяется для фильтрации всего фрейма и для получения взвешенной оценки речевого сигнала. На основе этой оценки для каждых двух субфреймов (120 выборок) вычисляется период основного тона ![]() . Оценка тона представляется блоками по 120 выборок. Период основного тона лежит в диапазоне от 18 до 142 выборок.
. Оценка тона представляется блоками по 120 выборок. Период основного тона лежит в диапазоне от 18 до 142 выборок.
С помощью вычисленной заранее оценки периода тона создается фильтр формы гармонического шума. Комбинация из фильтра синтеза LPC, фильтра взвешивания формант, фильтра формы гармонического шума используется для синтеза импульсной характеристики, необходимой для дальнейших вычислений.
Оценки периода основного тона ![]() и импульсного отклика используются при работе предсказателя тона пятого порядка. Период тона вычисляется как приращение относительной оценки периода основного тона. На декодер передаются тоновый период и разностные величины. На следующем этапе аппроксимируются непериодические составляющие возбуждения. Для высокой скорости используется многоимпульсное возбуждение с квантованием и алгоритмом максимального правдоподобия (MP-MLQ), а для низких скоростей – алгебраическое кодовое возбуждение.
и импульсного отклика используются при работе предсказателя тона пятого порядка. Период тона вычисляется как приращение относительной оценки периода основного тона. На декодер передаются тоновый период и разностные величины. На следующем этапе аппроксимируются непериодические составляющие возбуждения. Для высокой скорости используется многоимпульсное возбуждение с квантованием и алгоритмом максимального правдоподобия (MP-MLQ), а для низких скоростей – алгебраическое кодовое возбуждение.
Рекомендации ITU-T G.729 содержат описание алгоритма кодирования речевых сигналов на скорости 8 кбит/с с использованием алгебраического линейного предсказания с кодовым возбуждением с сопряженной структурой (CS-ACELP).
Подобный кодер создан для работы с цифровыми сигналами, полученными после предварительной обработки аналогового входного сигнала фильтром низкой частоты, дискретизации с частотой 8 кГц и дальнейшем преобразованием в линейную ИКМ для подачи на вход кодера. Выходной сигнал декодера конвертируется обратно в аналоговый сигнал подобным же образом. Другие характеристики входа/выхода определяются аналогично рекомендациями G.711 для ИКМ последовательностей со скоростью 64 кбит/с. После декодирования данные должны быть преобразованы из 16-битовой линейной ИКМ в требуемый формат.
Кодер CS-ACELP основан на модели с линейным предсказанием с кодовым возбуждением (CELP) и работает с фреймами речи по 10 мс, соответствующих 80 выборкам. Каждый фрейм речевого сигнала длительностью 10 мс анализируется для выделения параметров CELP-модели (коэффициенты фильтра линейного предсказания, индексы адаптивной и фиксированной кодовых книг и коэффициенты усиления). Эти параметры кодируются и передаются на приемную сторону. Распределение бит параметров кодера показано в табл. 3.1.
Таблица 3.1
Распределение бит для алгоритма CS-ACELP на скорости 8 кбит/с (фреймы по 10 мс)
| Параметр | Кодовое слово | Субфрейм 1 | Субфрейм 2 | В целом на фрейм |
| Пары линейного спектра | LU, L1, L2, L3 | |||
| Задержка адаптивной кодовой книги | P1, Р2 | 8 | 5 | 13 |
| Проверка задержки тона | Р0 | 1 | 1 | |
| Индекс фиксированной кодовой книги | CT, С2 | 13 | 13 | 26 |
| Запись фиксированной кодовой книги | S1, S2 | 4 | 4 | 8 |
| Усиления кодовой книги (этап 1) | GA1, GA2 | 3 | 3 | 6 |
| Усиления кодовой книги (этап 2) | GBl, GB2 | 4 | 4 | 8 |
| Всего | 80 |
На стороне декодера эти параметры используются для восстановления параметров возбуждения и фильтра синтеза. Как показано на рис. 3.3, речь восстанавливается при фильтрации этого возбуждения фильтром кратковременного синтеза, который основан на фильтре линейного предсказания десятого порядка. Долговременный фильтр (или фильтр синтеза тона) выполняется с использованием адаптивной кодовой книги. После синтеза речи происходит дополнительное сглаживание в постфильтре.
Входной сигнал поступает на фильтр высоких частот и масштабируется в блоке предварительной обработки, после чего подвергается последующему анализу. Анализ с линейным предсказанием (LP-анализ) выполняется один раз для фрейма длительностью 10 мс с целью вычисления коэффициентов фильтра линейного предсказания, которые затем преобразуются в пары линейного спектра (Line Spectrum Pairs, LSP) и квантуются (18 бит) с использованием двухэтапного векторного квантования с предсказанием.
Сигнал возбуждения выбирается с использованием поисковой процедуры «анализ через синтез», при которой ошибка между исходной и восстанавливаемой речью минимизируется в соответствии с измерением взвешенных искажений. Это выполняется путем фильтрации сигнала ошибки фильтром взвешивания, коэффициенты которого извлечены из неквантованного LP-фильтра.
Параметры возбуждения (параметры фиксированной и адаптивной кодовых книг) определены для субфрейма длительностью 5 мс (40 выборок). Коэффициенты квантованного и неквантованного фильтра с линейным предсказанием используются для второго субфрейма, в то время как в первом субфрейме используются интерполированные коэффициенты LP-фильтра.
Задержка основного тона оценивается один раз для фрейма длиной 10 мс на основе взвешенного речевого сигнала. Затем для каждого субфрейма повторяются следующие операции. Искомый сигнал ![]() вычисляется при фильтрации остаточного линейного предсказания во взвешивающем фильтре синтеза
вычисляется при фильтрации остаточного линейного предсказания во взвешивающем фильтре синтеза ![]() . При фильтрации ошибки начальные состояния этих фильтров обновляются. Это эквивалентно результату выделения нулевого входного отклика взвешивающего фильтра синтеза из взвешенного речевого сигнала. Вычисляется импульсная характеристика
. При фильтрации ошибки начальные состояния этих фильтров обновляются. Это эквивалентно результату выделения нулевого входного отклика взвешивающего фильтра синтеза из взвешенного речевого сигнала. Вычисляется импульсная характеристика ![]() взвешивающего фильтра синтеза, после чего выполняется анализ тона для нахождения задержки адаптивной кодовой книги путем анализа значения задержки вблизи основного тона с использованием искомого сигнала
взвешивающего фильтра синтеза, после чего выполняется анализ тона для нахождения задержки адаптивной кодовой книги путем анализа значения задержки вблизи основного тона с использованием искомого сигнала ![]() и импульсной характеристики
и импульсной характеристики ![]() . Задержка тона кодируется восемью битами в первом субфрейме и пятью битами во втором субфрейме. Искомый сигнал
. Задержка тона кодируется восемью битами в первом субфрейме и пятью битами во втором субфрейме. Искомый сигнал ![]() используется при поиске фиксированной кодовой книги для нахождения оптимального возбуждения. Семнадцатибитовая алгебраическая кодовая книга используется для возбуждения фиксированной кодовой книги. Коэффициенты усиления вкладов адаптивной и фиксированной кодовых книг — это векторы, квантованные семью битами.
используется при поиске фиксированной кодовой книги для нахождения оптимального возбуждения. Семнадцатибитовая алгебраическая кодовая книга используется для возбуждения фиксированной кодовой книги. Коэффициенты усиления вкладов адаптивной и фиксированной кодовых книг — это векторы, квантованные семью битами.
Индексы параметров кодовых книг выделяются из принятого потока бит и декодируются для получения следующих параметров кодера, соответствующих речевому фрейму длиной 10 мс: LP-коэффициенты (коэффициенты линейного предсказания), две частичные задержки тона, два вектора фиксированной кодовой книги и два набора коэффициентов адаптивной и фиксированной кодовых книг. Коэффициенты LSP интерполируются и преобразуются в коэффициенты LP-фильтра для каждого субфрейма. Для каждого субфрейма выполняются следующие шаги:
восстанавливается возбуждение путем добавления векторов адаптивной и фиксированной кодовых книг с соответствующими им коэффициентами усиления;
восстанавливается речь путем пропускания через фильтр LP-синтеза;
восстанавливаемый речевой сигнал пропускается через ступень постобработки, которая включает адаптивный постфильтр, состоящий из долговременного и кратковременного постфильтров синтеза, фильтр высоких частот и операцию масштабирования.
Кодер кодирует речь и другие аудиосигналы по фреймам длительностью 10 мс. В результате осуществляется задержка 5 мс, что приводит в результате к общей алгоритмической задержке 15 мс. Все дополнительные задержки при практическом исполнении такого кодера обусловлены следующими причинами:
временем обработки, необходимым для операции кодирования и декодирования;
временем передачи по линиям связи;
задержкой мультиплексирования, когда аудиоданные объединяются с другими данными.
Таким образом, рекомендация G.729 предусматривает фреймы возбуждения по 5 мс и формирует четыре импульса. Фрейм из 40 выборок разделяется на четыре части. Первые три имеют восемь возможных позиций для импульсов, четвертая — шестнадцать. Из каждой части выбирается по одному импульсу. В результате образуется четырехимпульсный ACELP возбуждения кодовой страницы (табл. 3.2).
Таблица 3.2
Параметры кодеров
| Параметры кодера | Кодер | ||
| G.729 | G.729A | G.723.1 | |
| Скорость бит, кбит/с | 8 | 8 | 5,3…6,3 |
| Размер фрейма, мс | 10 | 10 | 30 |
| Размер подфрейма, мс | 5 | 5 | 7,5 |
| Алгебраическая задержка, мс | 15 | 15 | 37,5 |
| Быстродействие, млн. оп./с | 20 | 10 | 14…20 |
| Объем ПЗУ, байт | 5,2 К | 4 К | 4,4 К |
| Качество | Хорошее | Хорошее | Хорошее |
Для режима 5,3 кбит/с рекомендация G.723.1 предусматривает фреймы возбуждения длительностью 7,5 мс и также использует четырехимпульсное ACELP-возбуждение кодовой страницы. Для скорости 6,3 кбит/с используется технология многоимпульсного возбуждения с квантованием и алгоритмом максимального правдоподобия (MP-MLQ). В этом случае позиции фреймов группируются в подгруппы с четными и нечетными номерами. Для определенного номера импульса из четной последовательности (пятый или шестой в зависимости от того, является ли сам фрейм четным или нечетным) используется последовательный многоимпульсный поиск. Похожий поиск повторяется для подфреймов с нечетными номерами. Для возбуждения выбирается группа с минимальными общими искажениями.
На стороне декодера информация кодера с линейным предсказанием (LPC) и информация адаптивной и фиксированной кодовой книг демультиплексируется и используется для реконструкции выходного сигнала. Для этих целей используется адаптивный постфильтр. В случае кодера G.723.1 сигнал возбуждения перед прохождением через фильтр синтеза LPC пропускается через LT (long-term — долговременный) постфильтр и ST (short-term — кратковременный) постфильтр.
LD-CELP (Long-Delay CELP). Рекомендация G.728
В Рекомендации содержится описание алгоритма кодирования речевых сигналов на скорости 16 кбит/с с помощью линейного предсказания с кодированием сигнала возбуждения с малой задержкой. Алгоритм LD-CELP описывает работу кодера и декодера.
В алгоритме LD-CELP сохранена суть метода CELP, представляющего собой метод «анализа через синтез» путем поиска сигналов в кодовой книге. Для получения алгоритмической задержки порядка 0,625 мс используется адаптация предсказателей и уровней сигнала возбуждения по выходу. Передается только индекс сигнала возбуждения, найденный в кодовой книге. Обновление коэффициентов предсказания производится с помощью LPC-анализа ранее квантованной речи. Уровень возбуждения обновляется с помощью информации, содержащейся в ранее квантованном сигнале возбуждения. Размер блока для адаптации вектора сигнала возбуждения и уровня составляет всего лишь пять отсчетов. Обновление взвешивающего фильтра, учитывающего восприятие, производится с помощью LPC-анализа неквантованной речи.
После выполнения преобразования сигнала ИКМ по закону А или μ в линейный ИКМ-сигнал входной сигнал делится на блоки по пять последовательных отсчетов. Для каждого входного блока кодер пропускает каждый из 1024 векторов кодовой книги (хранящихся в кодовой книге сигнала возбуждения) через устройство масштабирования уровня сигнала возбуждения и синтезирующий фильтр. Из полученных в результате пропускания всех 1024 векторов-кандидатов квантованного сигнала кодер определяет один, минимизирующий величину взвешенной по частоте среднеквадратической ошибки относительно вектора входного сигнала. 10-битовый индекс, соответствующий наилучшему вектору в кодовой книге, который соответствует наилучшему вектору-кандидату квантованного сигнала, передается в декодер. На следующем этапе для обновления памяти фильтра и подготовки к кодированию следующего вектора сигнала наилучший кодовый вектор проходит через устройство масштабирования уровня сигнала возбуждения и синтезирующий фильтр. Коэффициенты синтезирующего фильтра и уровень сигнала возбуждения периодически обновляются путем адаптации по выходу, базирующейся на квантованном сигнале, масштабированном по уровню, и сигнале возбуждения.
Индекс в книге векторного квантования (VQ) возбуждения представляет собой единственную информацию, которая в явной форме передается из кодера в декодер. Три других типа параметров: уровень сигналa возбуждения, коэффициенты синтезирующего фильтра и коэффициенты взвешивающего фильтра, учитывающего восприятие, обновляются периодически. Эти параметры получаются путем адаптации по выходу из сигналов, которые появляются до текущего вектора сигнала. Уровень сигнала возбуждения обновляется для каждого вектора, а коэффициенты взвешивающего фильтра, учитывающего восприятие, и коэффициенты синтезирующего фильтра обновляются для каждых четырех векторов (т.е. для каждых 20 отсчетов или для периода обновления длительностью 2,5 мс). Следует отметить, что хотя последовательность обработки в алгоритме имеет цикл адаптации, равный четырем векторам (20 отсчетов), емкость основного буфера составляет только один вектор (пять отсчетов). Такая малая емкость буфера позволяет получить задержку при передаче в одном направлении менее 2 мс.
Многополосное кодирование и кодирование с адаптивным преобразованием
Среди методов кодирования с частотным разбиением известны две технологии: многополосное кодирование — SBC (Sub-Band Coding) и кодирование с адаптивным преобразованием — АТС (Adaptive Transform Coding). Основной принцип обеих схем — разделение спектра входного на несколько частотных поддиапазонов (полос), которые затем кодируются отдельно. В SBC набор фильтров выполнен так, что разбивает входной речевой сигнал обычно на 4-16 широких частотных поддиапазонов (широкополосный анализ). В АТС для обеспечения более точных частотных показателей число поддиапазонов увеличено до 128-256 (узкополосный анализ).
Многополосное кодирование обычно рассматривается как метод кодирования формы сигнала, который использует широкополосный кратковременный анализ и синтез. После разделения речевого спектра на несколько поддиапазонов низшая частота каждого из них приводится к нулю, затем поддиапазон дискретизируется в соответствии с частотой Найквиста (минимальной частотой дискретизации), квантуется, кодируется, мультиплексируется и передается. В приемнике поддиапазоны демультиплексируются, декодируются и переводятся обратно в их частотные позиции. Результирующие сигналы поддиапазонов затем складываются для получения аппроксимированного исходного речевого сигнала.
Глава 2 IP-телефония
Основные стандарты кодирования речи, применяемые в 1Р-телефонии, приведены в табл. 4.1.
Таблица 4.1
Стандарты ITU-T по кодированию речи, применяемые в IP-телефонии
| Стандарт | Описание |
G.711 |
Импульсно-кодовая модуляция 64 кбит/с (ИКМ) (А -закон и μ-закон) |
| G.722 | Широкополосные кодеры, работающие на скорости 64, 56 или 48 кбит/с |
| G.726 | Рекомендации по кодерам АДИКМ, которые охватывают G721 и G723 |
| G.727 | АДИКМ, работающие на скоростях 40, 32, 24 или 16 кбит/с |
| G.728 | Вокодеры с линейным предсказанием, с кодовым возбуждением, с низкой задержкой, скорость 16 кбит/с (LD-CELP) |
| G.729 | Вокодеры с линейным предсказанием, с алгебраическим кодовым возбуждением, с сопряженной структурой, скорость 8 кбит/с (CS-ACELP) |
| G.723.1 | Низкоскоростные вокодеры для связей мультимедиа, работающие на скорости 6,3 и 5,3 кбит/с |
Каждая из приведенных в таблице рекомендаций ITU может служить основой для передачи речи по Интернету и другим сетям, так как все они обеспечивают низкие скорости передачи и достаточно просты в реализации персональным компьютером или в микропроцессорном исполнении.
Основной целью проектирования кодеров является уменьшение скорости передачи речи при безусловном сохранении требуемого уровня качества речи для конкретного приложения. Приложения по передаче речи в Интернет или Интранет могут быть либо самостоятельными, либо в форме мультимедиа. Так как мультимедиа подразумевают наличие нескольких средств кодирования речи, для таких приложений подразумевается, что поток речевых данных передается по линии связи совместно с другими сигналами. Некоторые из таких приложений могут включать:
одновременную передачу речи и видео;
приложения с одновременной цифровой передачей речи и данных (DSVD);
одновременную передачу речи и факса.
Особенности функционирования каналов для передачи речевых данных и прежде всего сети Интернет, а также возможные варианты построения систем телефонной связи на базе Интернет предъявляют ряд специфических требований к речевым кодерам (вокодерам). Благодаря пакетному принципу передачи и коммутации речевых данных отпадает необходимость кодирования и синхронной передачи одинаковых по длительности фрагментов речи.
Наиболее целесообразным и естественным для систем IP-телефонии является применение кодеров с переменной скоростью кодирования речевого сигнала. В основе кодера речи с переменной скоростью лежит классификатор входного сигнала, определяющий степень его информативности и, таким образом, задающий метод кодирования и скорость передачи речевых данных. Наиболее простым классификатором речевого сигнала является детектор активности речи (VAD — Voice Activity Detector), который выделяет во входном речевом сигнале активную речь и паузы. При этом фрагменты сигнала, классифицируемые как активная речь, кодируются каким-либо из известных алгоритмов (как правило, методом CELP) с типичной скоростью 4…8 кбит/с. Фрагменты, классифицированные как паузы, кодируются и передаются с очень низкой скоростью (порядка 0,1.. .0,2 кбит/с) или не передаются вообще. Передача минимальной информации о паузных фрагментах предпочтительна.
С помощью более эффективных классификаторов входного сигнала может более детально осуществляться классификация фрагментов, соответствующих активной речи. Это позволяет оптимизировать выбор стратегии кодирования (скорости передачи данных), выделяя для особо ответственных за качество речи участков речевого сигнала большее число бит (соответственно большую скорость), для менее ответственных – меньше бит (меньшую скорость). В результате могут быть достигнуты еще более низкие средние скорости (2...4 кбит/с) при высоком качестве синтезируемой речи.
Передатчик состоит из кодера речи, VAD, усреднителя фоновых шумов и переключателя на канал, который управляется выходом VAD. Когда на вход есть речь, передатчик постоянно включен. Во время пауз передатчик выключается, но после определенного времени, которое должно быть достаточно коротким, передатчик снова включается на один фрейм, чтобы передать информацию о среднем фоне для точного генерирования в приемнике комфортного шума. На приемной стороне, если определено наличие речи, происходит нормальный синтез. Если определено наличие паузы, выполняется одно из двух действий. Если не передается новой информации о фоне, используются существующие параметры шума, генерируется комфортный шум и используется для текущего фрейма. Если передаются новые параметры фонового шума, то старые параметры заменяются на вновь декодированные, а за тем генерируется новый комфортный шум. Обычно, на стороне декодера также используется индикатор «хороший/плохой» фрейм, чтобы показать верны или нет декодированные параметры, и если нет, используется замена фрейма. Эффективность DTX зависит от точности VAD.
Кодеры стандарта D-AMPS
Цифровой стандарт мобильной радиосвязи D-AMPS (Digital Advanced Mobile Phone Service), принятый в США в 1990 г., по своим функциональным возможностям и предоставляемым услугам приближается к стандарту GSM. Стандарт D-AMPS не принят в европейских странах, за исключением России, где он в основном ориентирован на региональное использование.
Блок предварительной обработки выполняет следующие функции:
предварительную цифровую фильтрацию входного сигнала с целью подъема верхних частот, на долю которых в спектре речевого сигнала приходится меньшая мощность;
«нарезание» сигнала на сегменты по 160 выборок (20 мс).
Для каждого 20-мс сегмента оцениваются параметры фильтра кратковременного линейного предсказания – 10 коэффициентов частичной корреляции ![]() ,
, ![]() (порядок предсказания М
= 10), которые непосредственно кодируются для передачи в канал связи без каких-либо дополнительных преобразований, и оценивается амплитудный множитель р
, определяющий энергию сегмента речи.
(порядок предсказания М
= 10), которые непосредственно кодируются для передачи в канал связи без каких-либо дополнительных преобразований, и оценивается амплитудный множитель р
, определяющий энергию сегмента речи.
Сигнал с выхода предварительной обработки фильтруется фильтром-анализатором кратковременного линейного предсказания A(z)
, имеющего форму трансверсального линейного фильтра, для чего коэффициенты частичной корреляции ![]() преобразуются в коэффициенты линейного предсказания
преобразуются в коэффициенты линейного предсказания ![]() .
.
Выходной сигнал фильтра кратковременного предсказания (остаток предсказания ![]() ) используется для оценки параметров фильтра
) используется для оценки параметров фильтра ![]() долговременного предсказания – задержки τ и коэффициента предсказания
долговременного предсказания – задержки τ и коэффициента предсказания ![]() , причем параметры долговременного предсказания оцениваются в отдельности для каждого из четырех подсегментов по 40 выборок, на которые разделяется сегмент из 160 выборок.
, причем параметры долговременного предсказания оцениваются в отдельности для каждого из четырех подсегментов по 40 выборок, на которые разделяется сегмент из 160 выборок.
Для каждого из подсегментов определяются параметры сигнала возбуждения. Для этого в составе кодера используется схема, аналогичная входящей в состав декодера, которая включает фильтры-синтезаторы кратковременного ![]() и долговременного
и долговременного ![]() предсказания и две кодовые книги и реализует метод «анализа-через-синтез». Каждая из кодовых книг сигнала возбуждения содержит 128 кодовых векторов, по 40 элементов в каждом.
предсказания и две кодовые книги и реализует метод «анализа-через-синтез». Каждая из кодовых книг сигнала возбуждения содержит 128 кодовых векторов, по 40 элементов в каждом.
Все кодовые векторы одной книги являются элементами 7-мерного линейного подпространства в 40-мерном пространстве. Каждая кодовая книга, содержащая 128 векторов, задается семью базисными векторами и 128 кодовыми словами (7-элементными векторами коэффициентов линейных комбинаций) с однобитовыми элементами.
Сигнал возбуждения фильтр синтезатора кратковременного предсказания, в соответствии со схемой декодера рис. 5.4, является суммой векторов возбуждения из двух кодовых книг и вектора с выхода фильтра синтезатора долговременного предсказания. Векторы возбуждения из кодовых книг до подачи на сумматор умножаются на соответствующие коэффициенты усиления ![]() и
и ![]() , а входным сигналом фильтра-синтезатора долговременного предсказания является, в зависимости от участка сегмента, выходной сигнал того же фильтр или суммарный сигнал возбуждения фильтра-синтезатора кратковременного предсказания. Параметры сигнала возбуждения – номера векторов возбуждения
, а входным сигналом фильтра-синтезатора долговременного предсказания является, в зависимости от участка сегмента, выходной сигнал того же фильтр или суммарный сигнал возбуждения фильтра-синтезатора кратковременного предсказания. Параметры сигнала возбуждения – номера векторов возбуждения ![]() и
и ![]() из первой и второй кодовых книг и соответствующие коэффициенты усиления
из первой и второй кодовых книг и соответствующие коэффициенты усиления ![]() и
и ![]() – определяются по критерию минимума среднеквадратичной ошибки на выходе фильтра-синтезатора кратковременного предсказания, входящего в состав кодера. Предварительно базисные векторы обеих кодовых книг ортогонализируются: для первой книги – по отношению к выходному вектору фильтра-синтезатора долговременного предсказания, для второй книги – по отношению к тому же выходному вектору и к базисным векторам первой книги.
– определяются по критерию минимума среднеквадратичной ошибки на выходе фильтра-синтезатора кратковременного предсказания, входящего в состав кодера. Предварительно базисные векторы обеих кодовых книг ортогонализируются: для первой книги – по отношению к выходному вектору фильтра-синтезатора долговременного предсказания, для второй книги – по отношению к тому же выходному вектору и к базисным векторам первой книги.
В результате выходная информация кодера речи для 20-мс сегмента включает:
• параметры фильтра кратковременного линейного предсказания – 10 коэффициентов частичной корреляции ![]() ,
, ![]() , и амплитудный множитель р
– один набор на весь сегмент;
, и амплитудный множитель р
– один набор на весь сегмент;
• параметры фильтра долговременного линейного предсказания – коэффициент предсказания ![]() и задержку τ – для каждого из четырех подсегментов;
и задержку τ – для каждого из четырех подсегментов;
• параметры сигнала возбуждения – номера ![]() и
и ![]() векторов возбуждения из двух кодовых книг и соответствующие коэффициенты усиления
векторов возбуждения из двух кодовых книг и соответствующие коэффициенты усиления ![]() и
и ![]() – для каждого из четырех подсегментов.
– для каждого из четырех подсегментов.
В табл. 5.2 приведено содержание выходной информации кодера с указанием числа бит, используемых для кодирования.
Таблица 5.2
Кодирование выходной информации кодера речи стандарта D-AMPS
| Передаваемые параметры | Число бит | Примечание |
| Параметры кратковременного предсказания (коэффициенты частичной корреляции |
38 |
|
| Амплитудный множитель (энергия сегмента) р | 5 | |
| Задержка фильтра долговременного предсказания τ (для каждого из четырех подсегментов) | 28 | 7 бит на каждый подсегмент |
| Номера векторов возбуждения |
56 | h и i2 по 7 бит |
| Коэффициенты усиления |
32 | 8 бит на каждый подсегмент; векторному квантованию и кодированию подвергаются некоторые функции от |
| Всего на 20-мс сегмент | 159 |
Общий объем информации, выдаваемой для 20-мс сегмента речи, составляет 159 бит. Поскольку исходный объем информации на входе кодера составляет 1280 бит (160 выборок по 8 бит), кодер осуществляет сжатие информации более чем в 8 раз. Перед передачей в канал связи выходная информация кодера речи подвергается дополнительному канальному кодированию, причем разные параметры в зависимости от их важности для обеспечения качества речи кодируются с различной степенью избыточности.
Функционирование декодера осуществляется по следующему алгоритму. Сигнал возбуждения фильтра-синтезатора кратковременного предсказания формируется таким же образом, как и в синтезирующей схеме кодера:
по номерам ![]() и
и ![]() из кодовых книг выбираются векторы возбуждения, которые умножаются соответственно на коэффициенты усиления
из кодовых книг выбираются векторы возбуждения, которые умножаются соответственно на коэффициенты усиления ![]() и
и ![]() и складываются с выходным вектором фильтра-синтезатора долговременного предсказания, определяемого параметрами
и складываются с выходным вектором фильтра-синтезатора долговременного предсказания, определяемого параметрами ![]() и τ.
и τ.
Окончательно сигнал возбуждения фильтруется фильтром-синтезатором кратковременного предсказания, выполненного в форме трансверсального фильтра, т.е. параметры фильтра преобразуются из коэффициентов частотной корреляции ![]() в коэффициенты предсказания
в коэффициенты предсказания ![]() . Для улучшения субъективного качества синтезированной речи выходной сигнал фильтра-синтезатора подвергается цифровой адаптивной постфильтрации и с выхода постфильтра получается восстановленный цифровой речевой сигнал.
. Для улучшения субъективного качества синтезированной речи выходной сигнал фильтра-синтезатора подвергается цифровой адаптивной постфильтрации и с выхода постфильтра получается восстановленный цифровой речевой сигнал.
Кодеры TETRA
TETRA (Trans-European Trunked Radio) представляет собой стандарт цифровой транкинговой радиосвязи, состоящий из ряда спецификаций, разработанных Европейским институтом телекоммуникационных стандартов ETSI.
TETRA — открытый стандарт, т.е. доступ к спецификациям TETRA свободен для всех заинтересованных сторон. В связи с этим оборудование различных производителей должно быть совместимо.
Стандарт TETRA создавался как единый общеевропейский цифровой стандарт. Стандарт разработай на основе технических решений и рекомендаций стандарта GSM и ориентирован на создание систем связи, эффективно и экономично поддерживающих совместное использование сетей различными группами пользователей с обеспечением секретности и защищенности информации.
Речевой кодер TETRA основан на модели кодирования CELP – с линейным предсказанием с кодовым возбуждением. В этой модели блок из N речевых выборок синтезируется путем фильтрации соответствующей обновленной последовательности из кодовой книги, масштабированной коэффициентом усиления ![]() , с помощью двух изменяющихся во времени фильтров.
, с помощью двух изменяющихся во времени фильтров.
Первый фильтр является фильтром долгосрочного предсказания (фильтром основного тона), цель которого – моделирование псевдопериодического речевого сигнала, а второй – фильтр краткосрочного предсказания – моделирует огибающую речевого спектра.
Передаточная характеристика долгосрочного фильтра (или фильтра синтеза основного тона) определяется формулой
![]()
где Т – задержка основного тона; ![]() – коэффициент усиления основного тона. Фильтр синтеза основного тона выполнен как адаптивная кодовая книга, где для задержек, меньших чем длина подфрейма, повторяется последнее возбуждение.
– коэффициент усиления основного тона. Фильтр синтеза основного тона выполнен как адаптивная кодовая книга, где для задержек, меньших чем длина подфрейма, повторяется последнее возбуждение.
Краткосрочный фильтр синтеза определяется формулой
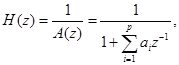
где ![]() ,
, ![]() , – параметры линейного предсказания; р
– порядок предсказателя. В кодере TETRA порядок р
= 10.
, – параметры линейного предсказания; р
– порядок предсказателя. В кодере TETRA порядок р
= 10.
При способе анализа-через-синтез синтезированная речь вычисляется для всех кандидатов – последовательностей, составляя особую последовательность, которая и формирует выходной сигнал, наиболее близкий к исходному, в соответствии с взвешенной величиной измеренных искажений. Фильтр взвешивания, корректирующий ошибку предыскажений в области форманты спектра речи, определяется формулой
![]() (5.1)
(5.1)
где ![]() – обратный (инверсный) фильтр линейного предсказания;
– обратный (инверсный) фильтр линейного предсказания; ![]() (используется значение
(используется значение ![]() ). Для взвешивающего фильтра
). Для взвешивающего фильтра ![]() и фильтра синтеза формант
и фильтра синтеза формант ![]() используются квантованные параметры линейного предсказания.
используются квантованные параметры линейного предсказания.
В алгебраическом CELP (ACELP) используется специальная кодовая книга, имеющая алгебраическую структуру. Эта алгебраическая структура имеет некоторые преимущества в отношении сохранения, сложности поиска и устойчивости (робастности). Кодер TETRA использует специальную динамическую алгебраическую кодовую книгу возбуждения, посредством которой, а также динамической матрицы формы образуются фиксированные векторы возбуждения. Матрица формы – это функция модели A(z) линейного предсказания. Главная ее роль – формировать векторы возбуждения в частотной области так, чтобы их энергии были сконцентрированы в наиболее важных частотных полосах. Используемая матрица формы является триангулярной Теплицевой матрицей низшего порядка, сформированной из импульсного отклика фильтра:
![]() (5.2)
(5.2)
где A(z)
— инверсный фильтр линейного предсказания (в конкретных реализациях ![]() и
и ![]() ).
).
В кодере TETRA используются фреймы речи по 30 мс. Это требуется для того, чтобы параметры краткосрочного предсказания вычислялись и передавались в каждом речевом фрейме. Речевой фрейм разделен на четыре подфрейма по 7,5 мс (60 выборок). Основной тон и параметры алгебраической кодовой книги также передаются в каждом подфрейме. В табл. 5.3 представлено распределение бит для кодера TETRA. Должно быть сформировано 137 бит для каждого фрейма по 30 мс, что в результате дает скорость 4567 бит/с.
Таблица 5.3
| Параметр | Номер сегмента | Всего в кадре | |||
| 1 | 2 | 3 | 4 | ||
| Коэффициенты линейного предсказания | 26 | ||||
| Период основного тона | 8 | 5 | 5 | 5 | 23 |
| Индекс алгебраической кодовой книги | 16 | 16 | 16 | 16 | 64 |
| Коэффициенты усиления | 6 | 6 | 6 | 6 | 24 |
| Всего | 137 | ||||
Кодеры стандарта АРСО 25
АРСО 25 – стандарт транкинговой радиосвязи, описывающий структуру цифровой транкинговой системы и некоторые ее интерфейсы. Для цифровой передачи речи стандарт АРСО 25 предусматривает использование кодера IMBE (Improved MultiBand Excitation, модифицированный метод многополосного возбуждения). Кодер формирует цифровой поток со скоростью 4,4 кбит/с. Для исправления ошибок в цифровом речевом сигнале используется избыточное кодирование, порождающее дополнительный цифровой поток со скоростью 2,8 кбит/с.
Цифровой речевой сигнал передается кадрами длительностью 180 мс. Два речевых кадра образует суперкадр длительностью 360 мс. Перед передачей речи следует преамбула длительностью 82,5 мс, которая содержит синхропакет (48 бит), идентификатор сети (64 бита), служащий для предотвращения конфликтов между радиостанциями, работающими на одной частоте; информацию для алгоритма шифрования, идентификатор ключа алгоритма шифрования и другие служебные идентификаторы (всего 126 бит). Кадры речи, кроме собственно речевой информации, содержат дополнительную информацию (управления связью, канала сигнализации и т.д.)
Речевой IMBE-кодер основан на модели речи, которая относится к моделям с многополосным возбуждением (МВЕ). Основная идея работы кодера состоит в разделении цифрового речевого входного сигнала на перекрывающиеся речевые сегменты (или фреймы) с использованием окна Кайзера. Затем для определенного фрейма оценивается набор параметров.
Речевой MBE-кодер является вокодером, т.е. он не кодирует входной речевой сигнал выборка за выборкой, а синтезирует сигнал, который содержит ту же информацию для восприятия человеком, что и исходный речевой сигнал. Заметим, что когда речь не является вокализованнной, исходный и синтезированный сегменты речи могут не иметь никакого сходства во временной области.
Речевой MBE-кодер имеет два основных преимущества перед ранее используемыми вокодерами: во-первых, он основан на МВЕ речевой модели, которая является более устойчивой, чем традиционные речевые модели в рассмотренных вокодерах; во-вторых, данный метод использует более сложный алгоритм оценки параметров модели речевого синтеза речевого сигнала из параметров модели.
Главное отличие речевых традиционных вокодеров от модели МВЕ состоит в сигнале возбуждения. В обычных речевых моделях для каждого речевого сегмента используется единственное решение вокал/невокал. В отличие от этого речевая модель МВЕ разделяет сигнал возбуждения на несколько неперекрывающихся частотных полос и принимает решение вокал/невокал для каждой частотной полосы. Это позволяет представить сигнал возбуждения для определенного речевого сегмента в виде смеси периодической (вокализованной) энергии и шумоподобной (невокализованной) энергии. Из-за этих множественных определений вокал/невокал эта модель называется моделью с многополосным возбуждением. Такая речевая модель позволяет синтезировать речь с более качеством, чем традиционные модели. Кроме того, речевая модель МВЕ более устойчива к фоновому шуму.
В речевой модели MBE сигнал возбуждения формируется из сигнала основного тона (или основной частоты) и решений вокал/невокал. Для вокализованной речи сигнал возбуждения является периодической импульсной последовательностью, в которой расстояние между импульсами определяется периодом основного тона ![]() . Для невокализованной речи сигнал возбуждения представляет собой белый шум. Периодический спектр создается из взвешенной периодической последовательности импульсов, которая полностью определяется окном взвешивания и периодом основного тона. Его спектр формируется из взвешенной последовательности случайного шума.
. Для невокализованной речи сигнал возбуждения представляет собой белый шум. Периодический спектр создается из взвешенной периодической последовательности импульсов, которая полностью определяется окном взвешивания и периодом основного тона. Его спектр формируется из взвешенной последовательности случайного шума.
Обычно алгоритмы для оценки параметров возбуждения и алгоритмы для оценки параметров огибающей спектра работают независимо. Эти параметры оцениваются на основе нескольких критериев без ясных оснований, насколько синтезированная речь должна быть близка к исходной. Это может проявиться в том, что синтезированный спектр будет слегка отличаться от исходного.
В речевом IMBE-кодере параметры возбуждения и огибающей спектра оцениваются одновременно так, что синтезированный спектр является самым близким к исходному речевому спектру.
Блок-схема алгоритма анализа показана на рис. 5.7.
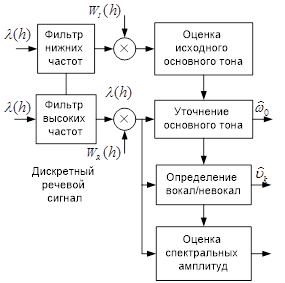
Рисунок 5.7
Параметры МВЕ модели речи, которые должны быть оценены для каждого речевого фрейма следующие:
период основного тона (или основная частота);
решение вокал/невокал;
спектральные амплитуды, характеризующие огибающую спектра.
В декодере вокализированная и невокализированная компоненты синтезируются отдельно и на заключительной стадии объединяются для получения полного речевого сигнала. Алгоритмы, которые используются для синтеза вокализированных и невокализированных частей речи, основаны на двух различных способах.
Невокализованная часть речи генерируется из гармоник, которые объявлены невокализованными. Для каждого фрейма речи блок случайного шума взвешивается и преобразуется с помощью быстрого преобразования Фурье. Области спектра, которые соответствуют вокализованным гармоникам, принимаются равными нулю.
Так как вокализованная речь моделируется ее индивидуальными гармониками в частотной области, на стороне декодера она восстанавливается как совокупный сигнал регулируемых генераторов. Каждой гармонике вокализованной области фрейма поставлен в соответствие генератор, который характеризуется частотой и фазой. Однако из-за того, что вокализованная часть речи не является периодической на интервалах, состоящих нескольких фреймов анализа, отклонения от ожидаемых параметров соседних фреймов могут вызвать скачки по концам фреймов, что приведет к значительному ухудшению качества речи. Для разрешения этой проблемы во время синтеза проверяются параметры текущего и предыдущего фреймов для уверенности, что на границе фреймов происходит плавный переход. Это делается для того, чтобы на границах фреймов вокализированная речь была непрерывной. Для обеспечения непрерывности в начале и конце фрейма речи функция амплитуды линейно интерполируется между значениями оценок для текущего и предыдущего фреймов.
Синтез речи в IMBE-декодере требует информации об основной частоте, решении вокал/невокал, величине спектральных составляющих и фазе вокализованных гармоник. Так как фазы вокализованных гармоник можно предсказать, информация о фазе не передается между кодером и декодером. Основная частота (основой тон) квантуется с половинной точностью выборки во временной области, причем возможный диапазон тона перекрывается восемью битами. Peшение вокал/невокал является двоичным числом и не требует квантования. Общее распределение бит для каждого фрейма приведено в табл. 5.4.
Таблица 5.4.
Распределение бит IMBE-кодера в системе АРСО 25
| Параметр | Число бит |
| Основная частота | 8 |
| Информация вокал/невокал | b |
| Спектральные амплитуды | 79 – b |
| Синхронизация | 1 |
Число полос, на которые разбивается речевой фрейм в частотной области, зависит от основного тона фрейма, но не превышает 12.
Таким образом, в кодере IMBE фрейм речи имеет длительность 20 мс, содержит 144 бита, из которых 56 используются для канального кодирования, 88 – для кодирования параметров речевой модели. Кодер работает на скорости 4,4 кбит/с. Скорость передачи в канале – 7,2 кбит/с.
Кодирование речи в системе INMARSAT-M
Для системы мобильной спутниковой связи INMARSAT была выбрана улучшенная версия речевого кодера МВЕ, описанного в предыдущем параграфе как версия стандарта на скорости 6,4 кбит/с для наземных систем подвижной связи. Размер фрейма кодера 20 мс. При этом обеспечивается кодирование источника и канала с помощью 128 бит на каждый фрейм. Из этих 128 бит 45 (2,25 кбит/с) зарезервированы для коррекции ошибок, а оставшиеся 83 бита (4,15 кбит/с) разделены между различными параметрами речи, как показано в табл. 5.5.
Таблица 5.5
Распределение бит в системе INMARSAT-M
| Параметр | Число бит |
| Основная частота | 8 |
| Информация вокал/невокал | b |
| Спектральные амплитуды | 75 – b |
Синтез речи в МВЕ декодере требует информации об основной частоте, решении вокал/невокал, спектральных величинах и фазах вокализированных гармоник. Так как фазы вокализированных гармоник можно предсказать, информация о фазе не передается от кодера к декодеру. Основная частота (основной тон) обычно квантуется с половинной точностью выборки во временной области, причем возможный диапазон тона перекрывается восемью битами. Решение вокал/невокал является двоичным числом и не требует квантования. Набор спектральных величин требует большей точности и эффективности квантования. Общее распределение бит для каждого фрейма следующее:
1) восемь бит для точного квантования тона;
2) b бит для решения вокал/невокал, где b – число полос принятия решения вокал/невокал;
3) оставшиеся биты для квантования гармоник.
Так как число гармоник зависит от основного тона, который изменяется, число бит, присваиваемых для решения вокал/невокал, может также изменяться. Типичное число вокализированных/невокализированных полос равно 12 (4), что означает, что максимальное число бит для описания вокал/невокал равно 12. Общее число бит ![]() для квантования гармоник определяется формулой
для квантования гармоник определяется формулой
![]()
где максимум b
равен 12; ![]() – общее число бит для фрейма.
– общее число бит для фрейма.
Рассмотрим способ квантования, используемый в системе INMARSAT-M.
Квантование основной частоты. Основная частота квантуется при преобразовании ее в эквивалентный период основного тона ![]() . Значения периода основного тона обычно ограничены диапазоном
. Значения периода основного тона обычно ограничены диапазоном ![]() . В системе МВЕ, предназначенной для работы на скорости 6,4 кбит/с, этот параметр равномерно квантуется с использованием 8 бит при размере шага 0,5, что дает возможность обеспечить половинную точность выборки.
. В системе МВЕ, предназначенной для работы на скорости 6,4 кбит/с, этот параметр равномерно квантуется с использованием 8 бит при размере шага 0,5, что дает возможность обеспечить половинную точность выборки.
Кодирование решений вокал/невокал. b
решений вокал/невокал являются двоичными числами, поэтому могут быть закодированы с использованием одного бита для каждой полосы решения. Система на скорости передачи 2,4 кбит/с использует максимум 12 полос, каждая с шириной ![]() Гармоники вне b
полос вокал/невокал приняты невокализированными.
Гармоники вне b
полос вокал/невокал приняты невокализированными.
Квантование спектральных величин. Перед квантованием спектральных величин для уменьшения их изменения используется этап предсказания.
Остатки предсказания группируются в шесть последовательных блоков, содержащих ![]() остаточных выборок каждый. Каждый блок преобразуется по частоте с использованием дискретного косинусоидального преобразования (ДКП) размером
остаточных выборок каждый. Каждый блок преобразуется по частоте с использованием дискретного косинусоидального преобразования (ДКП) размером ![]() .
.
Постоянные составляющие L шести ДКП-блоков (первые коэффициенты) группируются как вектор и квантуются с использованием кодовой книги шестибитового скалярного усиления и десятибитового вектора формы. Коэффициенты более высокого порядка М квантуются с использованием скалярных квантователей, где в процессе присвоения бит распределяются оставшиеся биты в соответствии с важностью для субъективного восприятия каждой величины. Блок-схема общей процесса квантования величин показана на рис. 5.8.
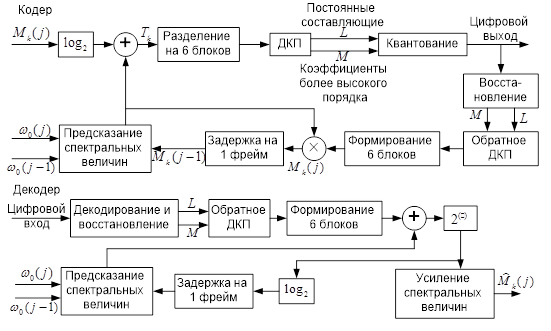
Рисунок 5.8
После правильного восстановления спектральных величин МВЕ-кодер пытается улучшить качество восприятия синтезированной речи с использованием усилителя. Усиление спектральных величин выполняется генерированием набора спектральных весов из принятых параметров текущего фрейма.
В типичном МВЕ-кодере большая часть бит выделена для квантования спектральных величин. В случае системы INMARSAT-M, где кодер источника работает на скорости 4,15 кбит/с при скорости фреймов 50 Гц, только 20 (8+ 12) бит используются для формирования информации об основном периоде и информации «вокал/невокал». Остальные биты используются для квантования спектральных величин. Таким образом, для успешного синтеза речи необходимо точно знать основной период. Для покрытия речевого спектра 4 кГц достаточно 12 полос вокал/невокал. В результате общая скорость кодера может быть уменьшена за счет более эффективного квантования величин. В системе INMARSAT-M все спектральные величины, кроме шести, проквантованы с использованием скалярных квантователей. Сокращение скорости можно добиться также за счет векторного квантования всех величин. Однако, так как число спектральных величин может изменяться от 9 до более чем 60 в зависимости от основной частоты, векторную кодовую книгу, учитывающую эти изменениями, создать очень сложно. Поэтому целесообразно векторное квантование использовать только для основной формы спектра, которая может быть принята независимой от основной частоты.
Глава 3 Перспективы кодирования речи.
В данной главе будут коротко рассмотрены перспективы использования различных речевых кодеков в сетях связи общего пользования.
Рассмотрим некоторые параметры наиболее распространенных кодеков сетей общего пользования.
Однако, кроме кодеков ИКМ по G.711, на ССОП в настоящее время применяются аналого-цифровые преобразователи других типов, использующие те или иные способы компрессии речи и поэтому имеющие меньшую скорость передачи цифрового сигнала по сравнению со стандартным кодеком ИКМ. Основные области применения низкоскоростных кодеков: • системы подвижной связи (в частности, цифровые сотовые и транкинговые системы); • аппаратура DCME (в небольшом количестве используется на сети ОАО «Ростелеком»); • абонентские компьютерные и мультимедийные терминалы, аппараты IP-телефонии;
• цифровые беспроводные телефоны.
Таблица 6.1. Наиболее распространенные кодеки.
| Кодек | Наименование | Скорость кбит/с | Стандарт |
| Standard PCM | Стандартный ИKM кодек для сетей с коммутацией каналов | 64 | ITU-T G.711 |
| GSM-FR PRE-LTP | Кодек 1-го поколения GSM с возбуждением регулярной последовательностью импульсов и долговременным предсказанием | 13 | ETSIGSM 06.16 |
| GSM-HR VCELP | Кодек GSM (с «половинной» скоростью) с линейным предсказанием и возбуждением векторной суммой | 5,6 | ETSIGSM 06.20 |
| GSM-EFR ACELP | Кодек 2-го поколения GSM с алгебраическим кодовым возбуждением и линейным предсказанием | 12,2 | ETSIGSM 06.60 |
| Videophone ACELP | Речевой кодек для мультимедийной связи с алгебраическим кодовым возбуждением и линейным предсказанием | 5,3 | ITU-T G.723.1 |
| Videophone MP-MLQ | Речевой кодек для мультимедийной связи с многоимпульсным квантованием по критерию правдоподобия | 6,3 | ITU-T G.723.1 |
| ADPCM | Кодек АДИКМ (адаптивной дифференциальной ИКМ) | 40, 32, 24, 16 | ITU-TG.726 |
| LD-CELP | Кодек с линейным предсказанием, с кодовым возбуждением и малой задержкой | 16, 12, 8, 9, 6 | ITU-T G.728 |
| CS-ACELP | Кодек с линейным предсказанием, алгебраическим кодовым возбуждением и сопряженной структурой | 8 | ITU-T G.729 |
Низкоскоростным кодекам свойственны определенные ухудшения параметров, влияющие на качество передачи речи, по сравнению со стандартным кодеком ИКМ. Важно, что эти ухудшения накапливаются при тандемном включении как однородных, так и разнородных низкоскоростных кодеков.
Следует отметить следующие основные факторы, влияющие на качество передачи речи при использовании кодеков:
• искажения квантования;
• временная задержка;
• амплитудно-частотные искажения;
• битовые ошибки;
• проскальзывания;
• потеря кадров;
• потеря пакетов.
Планирование речевых соединений требует обязательного учета ухудшений, вносимых каждым переходом А-Ц и Ц-А, и определения на этой основе допустимого количества таких переходов. Для этой цели используется так называемая Е-модель, разработанная ETSI и рекомендуемая МСЭ-Т при планировании речевых соединений «из конца в конец». Эта модель позволяет в комплексе учесть практически все ухудшающие факторы.
Наиболее важным параметром Е-модели является коэффициент ухудшения за счет аппаратуры, обозначаемый Ic . Чем больше этот коэффициент, тем большую долю деградации вносит данная аппаратура (конкретно – кодек). В табл. 6.2 для сравнения показаны значения для различных кодеков.
Таблица 6.2
| Кодек | Скорость кбит/с | Стандарт | Ic (G.113) |
| Standard PCM | 64 | ITU-T G.711 | 0 |
| GSM-FR PRE-LTP | 13 | ETSIGSM 06.16 | 20 (25-42)* |
| GSM-HR VCELP | 5,6 | ETSIGSM 06.20 | 23 (32-45)* |
| GSM-EFR ACELP | 12,2 | ETSIGSM 06.60 | 5 (15-35)* |
| Videophone ACELP | 5,3 | ITU-T G.723.1 | 19 |
| Videophone MP-MLQ | 6,3 | ITU-T G.723.1 | 15 |
| ADPCM | 40, 32, 24, 16 | ITU-TG.726 | 2, 7, 25, 50 |
| LD-CELP | 16, 12, 8, 9, 6 | ITU-T G.728 |
7, 20 |
| CS-ACELP | 8 | ITU-T G.729 |
10 |
| * – при наличии битовых ошибок | |||
Проблема задержки сигнала. Среди многих факторов, влияющих на качество передачи речи, можно отметить задержку сигнала в терминалах и узлах сети.
Желательной является задержка, не превышающая 150 мс, поскольку кроме задержки следует учитывать и другие ухудшающие факторы. Как уже указывалось, задержка, вносимая стандартными кодеками ИКМ, незначительна и составляет меньше 0,4 мс.
Существенное увеличение задержки по сравнению со стандартными кодеками ИКМ дают низкоскоростные кодеки. В частности, только сами кодеки в терминалах GSM вносят задержку в 60 мс, что эквивалентно времени прохождения через волоконно-оптическую линию связи (ВОЛС) длиной 12000 км. Процедура «фрейминга» (формирования кадров) на радиоинтерфейсе добавляет еще 35 мс задержки.
В табл. 6.3 представлены задержки, вносимые речевыми кодеками (МСЭ-Т G.114) различных типов, и соответствующие эквивалентные длины ВОЛС. Из таблицы следует, что задержки в низкоскоростных кодеках весьма велики, что делает дополнительные перекодировки практически недопустимыми. При этом нельзя упускать из виду повышенные задержки в таких сетевых элементах как шлюзы, маршрутизаторы и т. д.
Таблица 6.3
| Кодек | Стандарт | Средняя задержка, мс | Эквивалентная длина ВОЛС, км |
| Standard PCM | ITU-T G.711 | 0,375 | 75 |
| GSM-FR RPE-LTR | ETSI GSM 06.10 | 95 | 19000 |
| GSM-HR VCELP | ETSI GSM 06.20 | 95 | 19000 |
| GSM-EFRACELP | ETSI GSM 06.60 | 95 | 19000 |
| Videophone ACE LP | ITU-TG.723.1 | 97,5 | 19500 |
| Videophone MP-MLQ | ITU-T G.723.1 | 97,5 | 19500 |
| ADPCM | ITU-T G.726 | 0,375 | 75 |
| LD-CELP | ITU-T G.728 | 1.875 | 375 |
| CS-ACELP | ITU-T G.729 | 35 | 7000 |
Таким образом, приходится делать выбор между качеством связи и шириной канала поэтому задача проектирования наиболее качественных кодеков для низкоскоростных каналов с высоким уровнем помех весьма актуальна.
Рассмотрим наиболее эффективные, сегодня методы практической реализации низкоскоростных (1,2—2,4 кбит/с) MELP-вокодеров. предназначенных для работы в канале с высоким процентом канальных ошибок, и основные направления совершенствования данных методов.
В качестве базового алгоритма вокодера был выбран алгоритм MELP–2400, разработанный фирмой TexasInstruments и выигравший открытый конкурс по замене кодека федерального стандарт США FS-1016. Данный алгоритм основан на традиционной параметрической модели кодирования с линейным предсказанием и, кроме того, содержит ряд дополнительных особенностей:
• вся рабочая область частот делится на пять полос; в каждой из которых принимается решение о классе сигнала возбуждения — «шумовой» или «голосовой». Таким образом суммарный сигнал возбуждения является смешанным;
• форма «голосового» сигнала возбуждения реконструируется в декодере с помощью амплитуд коэффициентов Фурье, вычисленных в анализирующей части вокодера:
• для реализации одиночных импульсов возбуждения применяются «апериодические» импульсы;
• с целью улучшения «натуральности» звучания синтезированной речи применяются дисперсионный и адаптивный фильтры.
Суммарный список параметров, передаваемых от колера к декодеру за один речевой фрейм длительностью 22.5 мс, представлен в табл. 6.4.
Таблица 6.4.
| Параметр | «Голосовой» фрейм (бит) |
«Шумовой» фрейм (бит) |
| Линейные спектральные пары | 25 | 25 |
| Амплитуды преобразования Фурье сигнала возбуждения | 8 | – |
| Коэффициенты усиления (2 за фрейм) | 8 | 8 |
| Период основного тона, общая озвученность фрейма | 7 | 7 |
| Озвученность по полосам | 4 | – |
| Флаг периодичности | 1 | – |
| Защита от ошибок | – | 13 |
| Синхробит | 1 | 1 |
| Всего за кадр, 22.5 мс | 54 | 54 |
Выбранный вокодер обеспечивает хорошее звучание синтезированной речи при скорости битового потока 2,4 кбит/с и величине битовых ошибок не более.
Задача практической реализации низкоскоростного вокодера, имевшего приемлемое качество синтезированной речи при ошибках в канале до 5%, решалась в два этапа. Первоначально была снижена скорость битового речевого потока до 1,2 кбит/с без существенной деградации качества выходного речевого сигнала. Далее были выбраны оптимальные в смысле качества синтезированной речи коды, исправляющие ошибки, и разработан метод замены выбитых речевых параметров на интерполированные значения параметров предшествующих фреймов. После этого суммарная скорость потока информационных и проверочных бит составила 2,4 кбит/с.
Вокодер с битовой скоростью 1,2 кбит/с. При понижении скорости битового потока основное внимание уделялось сохранению разборчивости речи. Анализ алгоритма MELP–2400 показал, что амплитуды преобразования Фурье сигнала возбуждения отвечают в основном за узнаваемость диктора и передачу интонации. Поэтому в спроектированном вокодере MELP–1200 они не используются. Передача коэффициента усиления один раз за фрейм также не приводит к существенному ухудшению разборчивости. Для дальнейшего понижения битовой скорости была разработана техника передачи линейных спектральных пар (ЛСП) только по четным фреймам с помощью адаптивного выбора фреймов на основе решетчатой структуры с критичными изменениями. Для нечетных фреймов вектор ЛСП находился с помощью интерполяционных методов. Также для уменьшения числа бит была использована частота границы голосовой активности с двухбитовой кодировкой.
Суммарный список параметров алгоритма MELP-1200, передаваемых от кодера к декодеру за один речевой фрейм длительностью 45 мс, представлен в табл. 6.5.
Таблица 6.5
| Параметр | «Голосовой» фрейм (бит) |
«Шумовой» фрейм (бит) |
| Линейные спектральные пары | 25 | 25 |
| Амплитуды преобразования Фурье сигнала возбуждения | – | – |
| Коэффициенты усиления (2 за фрейм) | 5+5 | 5+5 |
| Период основного тона, общая озвученность фрейма | 7+7 | 7+7 |
| Озвученность по полосам | 2+2 | – |
| Флаг периодичности | 1 | 1 |
| Защита от ошибок | – | – |
| Синхробит | – | – |
| Всего за кадр, 22.5 мс | 54 | 50 |
Вокодер с битовой скоростью 2,4 кбит/с для работы в каналах с величиной ошибок до 5% (MELP–C–2400). Для исправления ошибок битового потока было исследовано несколько классов кодов. Наиболее оптимальными в смысле качества восстановленной речи оказались коды Хэмминга (8,4), позволяющие исправлять одиночную ошибку в четырех информационных битах и определять наличие ошибки в 2 бита, а также коды Голея (23,12), исправляющие три ошибки в двенадцати информационных битах. При проектировании был сделан выбор в пользу кодов Хэмминга. В результате к 54 информационным битам добавлялись 54 проверочных, и общая скорость битового потока составила 2,4 кбит/с.
Предлагаемый алгоритм построения низкоскоростного вокодера MELP—С-2400 был промоделирован на персональном компьютере с использованием языка программирования «СИ» при представлении данных в формате с фиксированной запятой. Для определения качества синтезированной речи использовалась диагностическая мера приемлемости (DiagnosticAcceptabilityMeasure — DAM). Для этой цели были использованы шесть wav-файлов с мужскими голосами и шесть wav-файлов с женскими голосами, которые затем прослушивались на выходе тракта 30 слушателями, после чего определялась средняя оценка мнений — MOS. Такой метод называется методом субъективной оценки качества.
Таким образом, на основании полученных результатов можно сделать следующие выводы:
1. Вокодер MELP-I200 имеет разборчивость синтезированной речи близкую к вокодеру MELP-2400 и может быть использован в каналах с пропускной способностью 1,2 кбит/с,
2. При битовых ошибках в канале более 1% вокодер MELP—С-2400 существенно улучшает качество синтезированной речи.
Что касается улучшения качества корректирующих кодов, то наиболее целесообразным представляется применение сверточных кодов со скоростью 1/3. Как показывают исследования, в этом случае при использовании схемы декодера Виттерби с мягким решением приемлемое качество речи можно обеспечивать при вероятности канальной ошибки до 10%. В каналах с памятью эффективным может оказаться применение каскадных кодов (например, последовательное кодирование кодами Рида-Соломона или сверточными кодами) или турбокодов.
Дальнейшее понижение скорости битового потока вокодера возможно при использовании модифицированных кодовых книг, отражающих возможные сочетания ЛСП, и суммарного векторного кодирования речевых параметров. При этом ожидаемая скорость речепреобразующих устройств может не превысить 800 бит/с при словесной разборчивости речи не менее 90%.
Далее рассмотрим кодеки и протоколы, непосредственно используемые в IP-телефонии. Эта тема очень важна, так как есть концепции по переводу в режим IP-телефонии всех сотовых и стационарных сетей.
Задача управления установлением соединений. Общий принцип действия Интернет-телефонии состоит в передаче аналогового речевого сигнала от телефонного аппарата или учрежденческой АТС в маршрутизатор для сжатия и преобразования речевого сигнала в пакеты данных. Эти пакеты передаются по сети Интернет в удаленный маршрутизатор. Последний преобразует пакеты данных обратно в речевой сигнал, который и передается в телефонный аппарат или на УАТС. В соответствии с такой схемой, описанной, в частности, в рекомендациях МСЭ Н.323/Н.248, требуется выполнение достаточно сложных преобразований между техникой Интернет-телефонии и коммутируемой телефонной сетью общего пользование. Одним из путей преодоления возникших трудностей, предпринятых группой инженерной поддержки Интернета IETF (InternetEngineeringTaskForce), стада разработка протокола запуска соединения SIP (SessionInitiationProtocol). Он применим для интегрированной среды Интернета и коммутируемой телефонной сети общего пользования.
SIP относится к протоколам прикладного уровня семиуровневой эталонной модели ВОС МОС как структура протокола HTTP типа "клиент-сервер". При обработке пакетов этого протокола команды и состояния могут передаваться в виде чистого текста посредством считывания данных пакетов HTTP. Поэтому протокол SIP очень подходит для архитектуры передачи по широкомасштабной информационно-вычислительной сети. В его структуре должен быть сформирован, по крайней мере, один сервер соединений SIP в дополнение к агентам пользователей. Сервер соединений SIP может работать как сервер-представитель (proxy-server), сервер изменения направления (redirectserver), сервер регистрации (registryserver), сервер речевой почты (voicemailserver), и др. Сервер соединений функционально является интегрированным программным обеспечением и может быть соединен с существующей коммутируемой сетью общего пользования, сетью Интернет-телефонии и т.п.
Протоколы Н.323 и SIP во многом схожи. Оба они поддерживают как двухстороннюю, так и многостороннюю связь. Протоколы обеспечивают возможность передачи мультимедийных данных по протоколу реального времени RTP (RealTimeProtocol) и родственному ему управляющему транспортному протоколу реального времени RTCP (RealtimeTransportControlProtocol). Последний выполняет функции поддержки обратной связи, синхронизации, обеспечения пользовательского интерфейса, но не управляет передачей данных. Вместе с тем протоколы Н.323 и SIP резко различаются концепциями и основополагающими принципами. Н.323 довольно тяжеловесен. Его описание занимает 1400 страниц и содержит целый стек протоколов, точно регламентирующих все процедуры. Это упрощает взаимодействие существующих сетей, но вызывает затруднения при адаптации новых применений. Что же касается протокола SIP. то это типичный Интернет-протокол, работа которого основана на обмене короткими тестовыми строками. Его описание занимает гораздо меньший объем (250 страниц), и он хорошо взаимодействует с другими протоколами.
Строго говоря, протокол SIP тоже определяет многоуровневый стек, который включает сетевой уровень, транспортный уровень, уровень транзакций, необязательный уровень диалога и собственно прикладной уровень, или уровень услуги. Однако эти уровни достаточно просты по сравнению с иерархией протокола Н.323. Так, сетевой уровень протокола SIP обеспечивает связь и взаимодействие с соответствующим протоколом сети Интернет (IP), чтобы каждый элемент протокола SIP связывался по Интернету. Транспортный уровень протокола SIP определяет, как клиент посылает запросы и принимает ответы и как сервер принимает запросы и посылает ответы по сети. Сервер протокола SIP представляет собой сетевой элемент, принимающий запросы, чтобы обслужить их и посылает обратно ответы на эти запросы. Транспортный уровень ответствен также за формирование сообщений SIP и их передачу по сети. Следующим уровнем протокола S1P является уровень транзакций. Транзакцией называется запрос, посылаемый уровнем транзакций клиента (с помощью транспортного уровня) уровню транзакций сервера вместе СО всеми ответами на запросы, посланные уровнем транзакций сервера, обратно клиенту. Уровень транзакций ответствен за согласование последовательности сообщений и за повторную передачу и фильтрацию дублирующих сообщений протокола SIP при ненадежности транспортного уровня. В любой задаче, выполняемой клиентом агента пользователя, применяется последовательность транзакций. Уровень, находящийся над уровнем транзакций, – это пользователь транзакций или уровень услуг. Иначе говоря, это приложение, запускаемое на самом верхнем уровне стека протокола SIP, который обеспечивает конкретную функцию элемента.
Между уровнем услуг я уровнем транзакций может существовать необязательный уровень диалога. Диалог по протоколу SIP идентифицирует набор соответствующих транзакций. Например, при стандартном телефонном соединении двумя транзакциями, относящимися к одному диалогу по протоколу SIP, являются установка соединения и разъединение. Уровень диалога ответствен за согласование последовательностей транзакций и управление при их неполноте. Элементы протокола SIP посылают запросы и ответы другим элементам SIP в форме сообщений. Эти сообщения содержат обширную информацию, касающуюся таких деталей, как адреса источников, адреса назначения, подробности маршрутов, указатели соединений, последовательные номера, и другие сведения относительно работы протокола. Формат сообщений SIP обладает значительной гибкостью в том смысле, что информация в заголовке может быть составлена и упорядочена внутри сообщения, и возможна ситуация, когда сообщения логически эквивалентны, тогда как синтаксически они различны. Например, протокол SIP не указывает для многих заголовков порядок, в котором они должны появляться в сообщении. Кроме того, заголовки SIP обычно нейтральны, и стеки протокола от разных поставщиков могут строить сообщения различными способами. Однако важно, что все стеки протокола SIP совместимы друг с другом.
Декодирование сообщений SIP выполняется грамматическим анализатором, который является интегральной составляющей стека протокола SIP. Он изучает сообщение и извлекает информацию, относящуюся к конкретному уровню. Вследствие различия путей, по которым может быть получено сообщение SIP, передающее одну и ту же информацию, грамматический анализатор имеет возможность выделять информацию заголовка, данные о параметрах, и т.п., независимо от формирования сообщения. Например, грамматический анализатор может копировать печатные знаки верхнего и нижнего регистра, варианты выделения заголовка, печатные знаки в строке, пробелы, знаки препинания, знаки в таблицах, и т.п. Таким образом, грамматический анализатор обеспечивает функции комплексного анализа. Стеки протокола SIP обычно представляются как общие готовые компоненты и реализуют полную спецификацию протокола SIP, делая их пригодными для использования с любым типом элемента SIP.
Каждый тип элементов протокола SIP представляет разные степени функциональной сложности, и количество сообщений, обрабатываемых каждым типом элемента, варьируется. Например, компоненты агента пользователя SIP и серверы агента пользователя могут выполнять сложные задачи обработки и связи, например, при установке соединения, хотя число сообщений, обрабатываемых клиентом агента пользователя, обычно сравнительно невелико. Так, сервер агента пользователя может только обрабатывать сообщения в связи с запросами на установление соединений, поступающих от клиента. Если соединение установлено и никаких изменений в его параметрах не произошло, клиент или сервер агента пользователя не будут обрабатывать дальнейшие сообщения до тех пор, пока соединение не завершится. С другой стороны, иные элементы (такие, как серверы изменения направления протокола SIP) выполняют более простые задачи обработки, но принимают значительно большее количество сообщений. Например, сервер изменения направления протокола SIP выполняет сравнительно простую задачу регистрации отображения между адресом источника SIP и адресом IP, которого адрес источника SIP может достичь. Это фундаментальная задача в сети SIP, так как серверы изменения направления используются представителями SIP, чтобы получить IP-адрес аппарата пользователя для маршрутизации соединения. Это важно, в частности, в случаях, когда доступ к сети получают мобильные клиенты, так как обычно адреса IP назначаются динамически и могут часто меняться. Кроме того, для гарантии, что отображаемая информация не устарела, каждый мобильный клиент обычно посылает с частыми интервалами сообщение REGISTER. Из изложенного ясно, что число сообщений, которые должны обрабатываться сервером изменения направления, существенно больше, чем число сообщений, обрабатываемых клиентом агента пользователя. Например, серверы текущей регистрации могут обрабатывать от 200 до 1000 операций регистрации в секунду.
Задачи кодирования речевых сигналов. Важным фактором ощущаемого качества кодера является полоса звуковых частот, в которой передается кодируемый сигнал. До настоящего времени большинство кодеков, используемых в современной телефонной связи, занимают полосу 300...3400 Гц (так называемая узкополосная речь). Это ограничение существует почти 100 лет, причем сами сети полосу частот не ограничивают (ограничение обусловлено характеристиками применяемых преобразователей). Именно частота 3,4 кГц была принята в качестве верхней граничной для коммутируемой телефонной сети общего пользования в стандарте цифровой передачи G.711. Хотя большая часть энергии чаше всего содержится в гласных звуках, которые занимают полосу частот ниже 3 кГц, согласные, несущие критическую информацию, часто требуют полосы частот выше 3 кГц. Поэтому узкополосные системы могут ухудшить разборчивость, например, звуки "с" и "ф" различаются только за счет частот выше 3 кГц. С другой стороны, увеличение полосы частот сигнала до 50...7000 Гц (так называемой широкой полосы), улучшает разборчивость, что требует от слушателя меньшей концентрации внимания, а следовательно, значительно снижает усталость.
Сегодня в эксплуатации много узкополосных речевых кодеров - начиная с G.711, который применяется в КТСОП со скоростью передачи 64 кбит/с, до G.729 (8 кбит/с) и G.723.1 (6,4 и 5,3 кбит/с), которые используются в услугах мультимедиа. Одним из кодеров, разработанных для мобильных сетей и работы с разными скоростями передачи вплоть до 43 кбит/с, является адаптивный многоскоростной кодек AMR (AdaptiveMulti-Rate). В настоящее время мало работ по новым узкополосным кодерам - может быть, потому, что уже существуют кодеры для большинства применений. Единственная область, в которой появляются новые узкополосные кодеры - это специальные разработки для пакетных систем Интернет-телефонии. В них созданы более робастные к потерям пакетов кодеры, чем предыдущие кодеры, разработанные для сетей с коммутацией каналов. Это кодеры iLBC (предложенные комиссией IETF) и EnhancedG.711J производства GlobalIPSound, Steex.
Рассмотрим их основные характеристики и применение.
iLBC (internetLowBitrateCodec) – это свободный от лицензионных отчислений кодек для голосовой связи через интернет. Кодек предназначен для узкополосных интернет каналов, со скоростью передачи аудио сигнала (человеческой речи) 13.33 кбит/с при длине кадра в 30 мс или 15.20 кбит/с при 20 мс. Кодек iLBC позволяет добиться хорошего качества передачи аудио сигнала даже при некоторых искажениях, которые происходят в связи с потерей или задержкой пакетов.
iLBC описан в стандарте в RFC 3951. Это один из кодеков, который используется в GizmoProject, Ekiga, OpenWengo, GoogleTalk, Skype и Yahoo! Messenger.
· Частота дискретизации 8 кГц/16 бит (160 отсчетов для 20-мс кадров, 240 отсчетов для 30-мс кадров)
· Управляемая реакция на потерю пакетов, задержки и джиттер
· Фиксированный битрейт (15.2 кбит/с для 20-мс кадров, 13.33 кбит/с для 30-мс кадров)
· Фиксированный размер кадра (304 бита в кадре для 20-мс кадров, 400 бит в кадре для 30-мс кадров)
· Обеспечивается устойчивость к потерям пакетов на уровне ИКМ со скрытием потерь пакетов, как в ITU-TG.711
· Загрузка процессора на уровне G.729a при более высоком качестве и лучшей реакции на потерю пакетов
· Лицензионная чистота и свобода от лицензионных отчислений
· Коммерческое использование исходного кода, предлагаемого GIPS, требует лицензирования
· Тестирование PSQM при идеальных условиях приводит к усредненной субъективной оценке (MOS) в 4.14 для iLBC (15.2 кбит/с), сравнимой с оценкой 4.45 для G.711 (Мю-закон)
Speex – это свободный кодек для сжатия речевого сигнала, который может использоваться в VoIP приложениях и подкастах. Он не имеет никаких патентных ограничений и лицензирован под последней версией лицензии BSD (без третьей статьи). Speex может быть использован совместно с медиа-контейнером Ogg или передаваться напрямую через UDP/RTP.
Разработчики позиционируют их проект как дополнение к Vorbis, формату сжатия звука общего назначения.
В отличие от многих других кодеков речи, Speex в основном предназначается не для сотовых телефонов, а для использования в VoiceoverIP (VoIP) и создания файлов со сжатым звуком. Speex оптимизирован для получения высококачественного речевого сигнала при низких битрейтах. Для достижения этой цели кодек использует переменный битрейт и поддерживает разные диапазоны частот: сверхширокий (англ. ultra-wideband, частота дискретизации 32 КГц), широкий (англ. wideband, 16 КГц) и узкий (англ. narrowband, качество телефонной линии, 8 КГц). Направленность на VoiceoverIP (VoIP) вместо сотовой связи означает, что Speex должен быть устойчив к потерям пакетов данных, но не к повреждению их, так как UDP (протокол неподтверждаемой доставки сообщений) предоставляет информацию лишь двух видов — данные прибыли неповрежденными или же потеряны. Эта особенность определяет выбор для Speex техники кодирования CodeExcitedLinearPrediction (CELP).
Основные характеристики кодека:
· Свободное и открытое программное обеспечение, не имеет патентных ограничений
· Интеграция широко- и узкополосного канала в одном потоке данных
· Динамическое переключение битрейта и переменный битрейт (англ. Variable bit-rate, VBR)
· Детектор речевой активности (англ. VoiceActivityDetection, VAD, интегрирован с VBR)
· Variable complexity
· Опция декодера — интенсивное стерео (англ. Intensitystereo)
Однако наряду с разработками узкополосных речевых кодеков большое внимание специалистов привлекают широкополосные речевые кодеки, рассчитанные на полосу частот речевого сигнала 50...7000 Гц. Первые широкополосные кодеры G.722 (48. 56 и 64 кбит, с) были стандартизированы МСЭ в 1988 г. Первоначально предполагалось, что они заменят кодеры G.711, когда ЦСИО получат более широкое распространение. Это кодеры со сложной формой сигнала, которые работают с двумя поддиапазонами и имеют хорошие характеристики, но невысокий коэффициент сжатия. Затем последовала рекомендация G.722.1 (24 и 32 кбит/с) на кодер, широко используемый в настоящее время в терминалах конференц-связи.
В 2000 г. проектом 3GPP был стандартизирован кодер AMR-WB (AdaptiveMulti-RateWideBand) для применения в мобильных системах третьего поколения. В 2001 г. он был стандартизирован МСЭ в качестве последнего широкополосного кодера G.722.2. Кодер работает с разными скоростями передачи от 6,6 до 23,85 кбит/с, но его вычислительная сложность может быть ограничена возможностями реализации. Очень важно, что обе организации (МСЭ и 3GPP) приняли один и тот же кодер, так как это устраняет необходимость перекодирования при работе между проводными и беспроводными сервисами. В конечном счете это снизит стоимость и улучшит характеристики передачи "из конца в конец". По проекту 3GPP также реализована версия AMR-WB+ (в 2004 г.). Она позволяет улучшить характеристики при передаче неречевых сигналов и является обратно совместимым расширением стандарта AMR-WB. Цель версии возможность применения в системах передачи с коммутацией пакетов также услуг мультимедиа. В Интернете можно найти сведения и о многих других разработках широкополосных кодеков. Расширен для широкополосного применения и кодек G.729 путем создания возможности многоскоростной передачи (рекомендация G.729EV 2006 г.).
Обзор развития достижений в области техники кодирования речевых сигналов дает основания считать, что в настоящее время существуют все предпосылки для постепенного повсеместного перевода телефонной связи на полосу 50-7000 Гц. Этот вывод относится не только к сети Интернет и пакетной передаче, но и к традиционным цифровым телефонным сетям общего пользования. Скорость передачи 64 кбит/с в таких сетях вполне достаточна для существенного повышения качества передачи и разборчивости речи за счет изменения системы кодирования в оконечных пунктах.
Список литературы.
1. Шелухин О.И., Лукьянцев Н.Ф. «Цифровая обработка и передача речи». М., «Радио и связь», 2000.
2. А.М. Меккель. «Влияние переходов «аналог-цифра и «цифра-аналог» при построении сетей на основе перспективных технологий». «Электросвязь».–2008. –№6. –с. 41-48.
3. М.И. Максимов, Н.А. Сидорова, О.В. Чернояров. «Проектирование низкоскоростных речепреобразующих устройств для каналов с высоким процентом ошибок». «Электросвязь». –2008. – №7. –с. 48-50.
4. А.А. Иванов, О.И. Фаерберг, К.Ю. Никашев. «Концепция модернизация сети общего пользования». «Электросвязь». –2008. –№8. –с. 18-23.
5. В.И. Нейман, Д.А. Селезнев. «Интернет-телефония и перспективы ее развития». «Электросвязь». –2008. –№1. –с. 6-9.
6. http://ru.wikipedia.org/wiki/Speex
7. http://ru.wikipedia.org/wiki/ILBC
Похожие рефераты:
Методы позиционирования и сжатия звука
Машины, которые говорят и слушают
Беспроводные телекоммуникационные системы
Расчет линии связи для системы телевидения
Классификация модемных протоколов
Электромагнитная совместимость сотовых сетей связи
Система криптозащиты в стандарте DES. Система взаимодействия периферийных устройств
Архитектура сотовых сетей связи и сети абонентского доступа
Проектирование устройства передачи данных по радиоканалу
Волоконно-оптическая линия связи
Видеоконференции в сети INTERNET