| Скачать .docx |
Курсовая работа: Представление текстовой и графической информации в электронном виде
ФЕДЕРАЛЬНОЕ АГЕНТСТВО ПО ОБРАЗОВАНИЮ
РОССИЙСКОЙ ФЕДЕРАЦИИ
ПЕНЗЕНСКИЙ ГОСУДАРСТВЕННЫЙ ПЕДАГОГИЧЕСКИЙ
УНИВЕРСИТЕТ ИМЕНИ В.Г. БЕЛИНСКОГО
Кафедра «Вычислительных систем и моделирования»
КУРСОВАЯ РАБОТА
по дисциплине «Вычислительные системы, сети и телекоммуникации»
Тема: «Представление текстовой и графической информации в электронном виде»
Выполнил: студентка гр. ПЭ-31 А-1
Васькова Е.О.,
студентка гр. ПЭ-31 А-1
Гусева Д.И
Проверил: к.т.н., доцент Коннов Н.Н.
2007
Для выполнения работы в текстовом редакторе был набран текст лекций по курсу «Вычислительные системы, сети и телекоммуникации». Все изображения были созданы в графическом редакторе MicrosoftOfficeVisio.
На основе подготовленных документов создан электронный учебник, который можно просмотреть на прилагаемом диске. Некоторые фрагменты учебника представлены в приложении.
Вычислительная система
Вычислительная система - комплекс аппаратных систем, решающих задачи на основе программы.
Вычислительные устройства по принципам решения задач и представления информации делятся на:
1) Аналоговые
Обрабатываемая информация представляется в виде непрерывно изменяющихся физических параметров. Обработка информации представляет собой воспроизведение сигналов, параметры которых изменяются в соответствии с определенным законом.
2) Цифровые
Манипулируют символами (цифрами). Необходимо иметь физические устройства, позволяющие различать устойчивые состояния (например, замкнутая и незамкнутая цепь).
1) Предтеча современных компьютеров - «аналитическая машина», над созданием которой в 1830-е годы работал Чарльз Бэббидж, считывала программы с бумажных носителей – перфокарт. Данные хранились на специальном механическом устройстве.
2) В конце 19 веке появились арифмометры, разработанные на основе колеса Однера, которое имело переменное количество зубцов и 10 устойчивых состояний.
3) В начале 20 в. (период Первой Мировой войны) были разработаны электронно-вычислительные системы
Полный промышленный цикл обработки перфокарт реализовал Герман Холлерит – создатель одной из фирм прародителей корпорации IBM.
4) Во время Второй Мировой войны Генрих Цузер разработал машину Ц-3 на основе электромагнитного реле.
5) Современный этап
Первое поколение (1949-1958)
Основным активным элементом ЭВМ первого поколения является электронная лампа.
Для построения оперативной памяти применялись ферритовые сердечники. В качестве устройств ввода/вывода (УВВ) сначала использовалось стандартная телеграфная аппаратура, а затем специально для ЭВМ были разработаны электромеханические УВВ на перфокартах и перфолентах. Машины этого поколения характеризуются огромными размерами, малым быстродействием, малой емкостью оперативной памяти (ОП), невысокой надежностью; недостаточно развитым программным обеспечением (ПО). Первой настоящей ЭВМ считается ENIAC.
Американский математик Джон фон Нейман сформулировал основные принципы программного управления:
- Информация, обрабатываемая машиной ( данные и команды), должна представляться двоичным кодом
- Каждая команда задает вид операции и адреса операндов в памяти.
- Команды и данные располагаются в ячейках памяти. Память машины имеет линейную структуру.
- Программа - упорядоченная последовательность команд, при этом реализуется естественный порядок выполнения команд (в порядке возрастания адресов ячеек памяти). Для нарушения этого порядка применяются специальные команды передачи управления.
Второе поколение (1959-1963)
Основной активный элемент - транзистор. По сравнению с первым поколением уменьшены размеры, стоимость, масса и потребляемая мощность, повышена надежность и быстродействие, увеличен объём памяти. Отличительные черты: специализация, появление алгоритмических языков, многопрограммных ЭВМ, применение УВВ на магнитных носителях.
Третье поколение (1964-1976)
Характеризуется широким применением интегральных схем (ИС). ИС (кристалл) - это законченный функциональный блок, соответствующий сложной транзисторной схеме, вытравленной на поверхности кремниевого кристалла. Позднее стали применяться ИС малой (10-100 компонентов на кристалл) и средней (100-1000 компонентов на кристалл) степени интеграции. Отличительные черты: увеличение количества используемых УВВ, дальнейшее развитие ПО, особенно операционных систем, возможность удаленного доступа пользователей к ЭВМ, виртуальное использование ЭВМ в режиме разделения времени, применение методов автоматического проектирования; унификация ЭВМ.
Четвёртое поколение (1977-1990г.г.)
Характеризуется применением больших интегральных схем (БИС) и сверхбольших интегральных схем (СБИС). Отличительные черты: тенденция к унификации ЭВМ и развитию мини- и микроЭВМ, использование быстродействующих систем памяти и Моп-технологий, создание машин, представляющих единую систему (ЕС ЭВМ), появление первых персональных компьютеров и рабочих станций, основной носитель информации - гибкий магнитный диск.
Пятое поколение (настоящее время)
ЭВМ пятого поколения (кроме высокой производительности и надежности при более низкой стоимости) должны удовлетворять следующим функциональным требованиям:
- обеспечить простоту применения ЭВМ путем реализации систем ввода/вывода информации голосом, диалоговой обработки информации с использованием естественных языков;
- возможности обучаемости, ассоциативных построений и логических выводов;
- упростить процесс создания программных средств путем автоматизации синтеза программ по спецификациям исходных требований на естественных языках;
- улучшить основные характеристики и эксплуатационные качества ВТ для удовлетворения различных социальных задач,
- улучшить соотношения затрат и результатов, быстродействия, легкости, компактности ЭВМ;
- обеспечить их разнообразие, высокую адаптируемость к приложениям и надежность в эксплуатации.
Структура современной машины
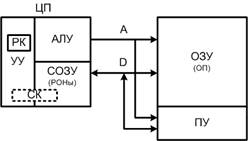
Обобщенная структура простейшей фон-неймановской ЭВМ
А – адресная шина
Д – шина данных
РК – регистр команд
ЗПР – запросы прерывания
СОЗУ – сверхоперативная память
УУ – устройство управления
Любая ВМ может быть разделена на три части:
- обрабатывающая часть – процессор (ЦП);
- оперативное запоминающее устройство (ОЗУ);
- периферийные устройства (ПУ).
В состав ЦП входят:
- арифметико-логическое устройство (АЛУ), обрабатывающее данные;
- внутренняя память процессора (сверхоперативная память - СОЗУ), которая используется для хранения операндов, адресов, в том числе и очередной команды на специальном регистре СК (счётчик команд). Делится на программно доступную (регистры, которые видны программисту) и скрытую;
- устройство управления (УУ), которое выделяет последовательность сигналов контролирующих передачу информации между остальными устройствами в соответствии с содержимым регистра команд (РК), на который принимается очередная команда.
Разрядность процессора – максимальная разрядность данных, обрабатываемых одной командой.
Адресное пространство процессора – максимальное количество ячеек ОП, которые могут им адресоваться. Если rA - разрядность, то адресное пространство 2rA .
Ширина выборки – количество данных, которые могут считываться одновременно в ЦП из ОП.
Производительность – количество задач, решаемых в единицу времени.
Быстродействие – время выполнения одной операции.
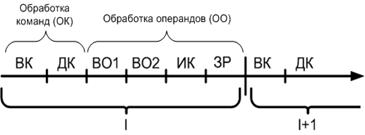
Выполнение операции включает в себя следующие фазы:
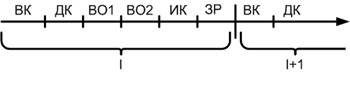
ВК (выборка команды): процессор вычисляет адрес ячейки памяти, где хранится команда(этот адрес он берет из СК), обращается к памяти, считывает команду, помешает на внутренний регистр памяти, вычисляет адрес следующей команды(модифицирует СК).
ДК (дешифрация команды): по значению кода определяется раскладка полей (формат) команды, в соответствии с чем настраиваются устройства.
ВО1, ВО2, …(выборка операнда):вычисление адресов операндов и обращение к ним, помещение операндов из ОП в регистры СОЗУ.
ИК (исполнение команды): действия над операндами.
ЗР (запись результата): полученный результат записывается в регистр памяти.
Фазы ВК, ДК и ИК являются обязательными. После ЗР выполняются фазы следующей команды или фаза прерывания.
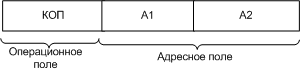
Структура команды:
Структурная схема микропроцессора intel8086
Первые процессоры, появившиеся в персональных ЭВМ были 16-разрядные. Процессор, стоявший в компьютере IBM PC, был изготовлен фирмой Intel, назывался i8086 и работал на тактовой частоте 4,77 МГц. Процессоры следующего поколения, 80186, 80188, 80286, тоже были 16-ти разрядными, хотя имели более высокую тактовую частоту и возможность работы с памятью выше 1 Мбайта в защищенном режиме .
Коротко 16-ти битные процессоры можно описать:
· Разрядность ядра - 16 бит
· Число регистров - 14
· Разрядность шины данных : внутренняя - 16 или 8 бит, внешняя - 16 бит
· Адресная шина - 20 бит (память до 1 Мбайта)
· Внутренняя кэш-память - отсутствует
· Внешняя шина для подключения устройств ввода/вывода - ISA (Industry Standard Architecture), 16 бит, 8 МГц
На рисунке представлена структурная схема микропроцессора 8086, в состав которого входят: устройство управления, арифметико-логическое устройство, блок преобразования адресов и регистры.
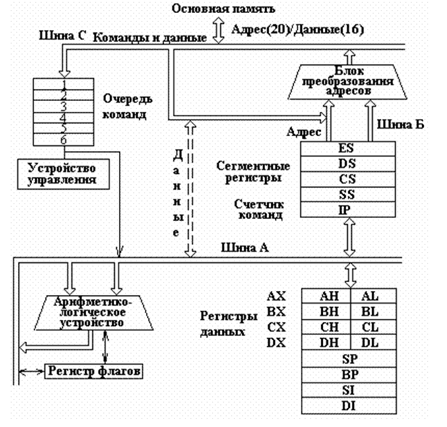
Устройство управления дешифрирует коды команд и формирует необходимые управляющие сигналы.
Арифметико-логическое устройство осуществляет необходимые арифметические и логические преобразования данных. Выполнение арифметических операций фиксируется флагом:
CF – признак переноса из старшего разряда при выполнении операции
ZF – признак нуля: 1 - число = 0
AF – признак дополнительного переноса, сигнал, возникающий между тетрадами в двоичной операции.
SF – признак знака: 1 - число < 0, 0 - число > 0
PF – признак четности;
ОF – признак переполнения;
DF – признак направления;
IF – признак прерывания;
ТF – признак трассировки;
В блоке преобразования адресов формируются физические адреса данных, расположенных в основной памяти. Наконец, регистры используются для хранения управляющей информации: адресов и данных.
Всего в состав микропроцессора i8086 входит четырнадцать 16-битовых регистров (см. рис.):
a) четыре регистра общего назначения (регистры данных):
AX - регистр-аккумулятор,
BX - базовый регистр,
СХ - счетчик,
DX - регистр-расширитель аккумулятора (по умолчанию для хранения данных в командах умножения и деления);
б) три адресных регистра:
SI - регистр индекса источника,
DI - регистр индекса результата,
BP - регистр-указатель базы (позволяет прочитать произвольный элемент стека);
в) три управляющих регистра:
SP - регистр-указатель стека (адрес последнего числа, записанного в стек),
IP - регистр-счетчик команд (указывает адрес команды, подлежащей выполнению, т.е. следующей),
регистр флагов;
Данные регистры составляют сверхоперативную память.
г) четыре сегментных регистра:
CS - регистр сегмента кодов,
DS - регистр сегмента данных,
ES - регистр дополнительного сегмента данных,
SS - регистр сегмента стека.
Способы адресации
Процессор при обработке программы взаимодействует с оперативной памятью, которая представляется единым массивом однобайтных ячеек, обращение к которым происходит по их номерам (физическим адресам). Число ячеек зависит от разрядности шины адреса и составляет для процессора i8086 1Мбайт.
Для обращения к памяти процессор предварительно помещает адрес ячейки в один из своих регистров. Шестнадцатиразрядный процессор i8086 не может хранить в своих регистрах двадцатиразрядный адрес, поэтому в нем применена так называемая сегментация памяти, которая заключается в том, что истинный, физический адрес ячейки хранится в двух регистрах. Один из них – сегментный (хранит адрес начала блока памяти). Второй регистр хранит величину смещения адреса требуемой ячейки от начала сегмента. Адрес ячейки памяти записывается в виде двойного слова (4 байта): <сегмент>:<смещение>.
Команды могут формировать адреса операндов различными способами. Реализованы следующие режимы адресации:
1. Регистровая прямая (посылочная) - операнд находится в регистре.
Обозначение - <регистр>,< регистр > - АХ, ВХ, СХ, DX, SI, DI, BP, SP, AL, BL, СL, DL, AH, BH, CH, DH.
Пример: (приведен операторами языка ассемблера)
mov АХ,SI ; переслать содержимое регистра SI в регистр АХ.
2. Непосредственная - непосредственный операнд (константа) присутствует в команде.
Обозначение - < константное выражение > .
Пример:
mov AX, 093Ah ; занести константу 093Ah в регистр АХ.
3. Прямая (абсолютная)- исполнительный адрес операнда присутствует в команде.
Обозначение - < переменная >+/-< константное выражение >.
Пример:
mov AX, WW ; переслать в АХ слово памяти с именем WW
mov BX, WW+2 ; переслать в ВХ слово памяти отстоящее от переменной с именем WW на 2 байта.
4. Регистровая косвенная - регистр содержит адрес операнда.
Обозначение - [< регистр >], < регистр > - ВХ. ВР. SI, DI.
Пример:
mov [ BX ], CL ; переслать содержимое регистра CL по адресу, находящемуся в регистре ВХ.
5. Регистровая относительная - адрес операнда вычисляется как сумма содержимого регистра и смещения.
Обозначение - < переменная >[< регистр >] или [< регистр >]< константное выражение >, < регистр > - SI или DI индексная адресация, ВХ или ВР - базовая адресация.
Пример:
mov АХ, WW[SI] ; переслать в АХ слово из памяти, адрес которого вычисляется как сумма содержимого регистра SI и смещения WW.
6. Индексно - базовая - адрес операнда вычисляется как сумма содержимых базового и индексного регистров и смещения.
Обозначение - [< базов. регистр>][< индексн. регистр>] или <переменная >[<базов. регистр >][< индекс. регистр >] или [<базов. регистр >][< ин-декс. регистр >]< константное выражение>, где < индекс. регистр > - SI или DI, < базов. Регистр > - ВХ или ВР.
Пример:
mov [BX+ SI+ 2], CL; переслать содержимое регистра CL по адресу, вычисляемому как сумма содержимого регистров ВХ, SI и константы 2.
7.Стековая адресация - реализует неявное задание адреса операнда. Хотя адрес обращения в стек отсутствует в команде, он формируется с помощью указателя SP в котором автоматически при записи или чтении устанавливается номер последней занятой ячейки стека.
Прерывания
Прерывания осуществляют механизм переключения с одной задачи на другую. Прерывания рассматриваются с двух сторон:
- программно определенные события (предусмотрены текущей программой),
- события не предопределенные, поэтому процессор должен переключаться на какую-то задачу
Следовательно, различают 2 вида прерываний: аппаратные и программные.
1. Программные вызываются из программы с помощью команды int.
2. При аппаратном прерывании процедура прерывания инициируется внешним сигналом IRQ, поступившим с программируемого контроллера прерываний (КПР). Обработка запроса в КПР происходит по следующей схеме:
Происходит фиксация запросов и их селекция по принципу приоритета, который задается номером: запрос с меньшим номером имеет высший приоритет, и наоборот.
КПР выдает сигнал int в процессор. Периодически в конце каждой команды процессор анализирует сигнал int. Если это событие произошло, то процессор прекращает выполнять текущую операцию и приступает к процедуре прерывания:
ЦП записывает в стек содержимое регистра флагов IF (флаг разрешения прерывания), CS и указатель IP, чтобы сохранить состояние текущей команды в момент прерывания. Затем он сбрасывает флаг и передает управление программе обработки прерывания, загружая в регистр CS и IP адрес вектора прерываний, который представляет собой 2 числа (4 байта), задающие местонахождение обработчика прерывания. В оперативной памяти размещаются 256 векторов прерываний (1024 байта).
Адрес вектора прерывания с номером прерывания N вычисляется как N*4. В младшем байте хранится значение IP, а в старшем CS.
Чтобы вернуться из прерывания, необходимо использовать команду iret, которая восстанавливает из стека содержимое CS, IP и регистра флагов.
Программные прерывания применяются в первую очередь для вызова системных обслуживающих программ - функций DOS и BIOS. Большая часть векторов прерываний зарезервирована для выполнения определенных действий; часть из них автоматически заполняется адресами системных программ при загрузке системы. Вектора прерываний можно условно разбить на следующие группы:
векторы внутренних прерываний процессора (0lh, 02h и др.);
векторы аппаратных прерываний (08h...0Fh и 70h...77h);
программы BIOS обслуживания аппаратуры компьютера (10h, 13h, 16h и др.);
программы DOS (21h, 22h, 23h и др.);
адреса системных таблиц BIOS
Запоминающие устройства ЭВМ
Ключевым принципом построения памяти ЭВМ является ее иерархическая организация (принцип, сформулированный еще Джоном фон Нейманом), которая предполагает использование в системе памяти компьютера запоминающих устройств (ЗУ) с различными характеристиками.

ВЗУ – энергонезависимая память, используемая для хранения больших объемов информации. Её емкость больше, чем в ОЗУ, но быстродействие во много раз меньше.
ОЗУ используется для хранения данных и программ (RAM – устройство с произвольным доступом). ОЗУ характеризуется следующими параметрами:
1. Время обращения: время чтения, время записи.
![]() 2. Емкость – количество адресуемых элементов в памяти. Ячейка памяти – то, что считывается за одно обращение. Количество данных (разрядность), считываемых за одно обращение называется шириной выборки. Адресуемый элемент <> ширины. Емкость может рассматриваться как физическая и как размер адресного пространства.
2. Емкость – количество адресуемых элементов в памяти. Ячейка памяти – то, что считывается за одно обращение. Количество данных (разрядность), считываемых за одно обращение называется шириной выборки. Адресуемый элемент <> ширины. Емкость может рассматриваться как физическая и как размер адресного пространства.
Все современные ОЗУ – полупроводниковые устройства:
1. Статические ОЗУ.
В качестве элемента памяти используется триггер. Статические ЗУ обладают меньшей плотностью хранения информации. Однако триггер со времен первых компьютеров был и остается самым быстродействующим элементом памяти. Поэтому статическая память позволяет достичь наибольшего быстродействия, обеспечивая время доступа в единицы и даже десятые доли наносекунд, что и обусловливает ее использование в ЭВМ, главным образом, в высших ступенях памяти – кэш-памяти всех уровней. Триггер создается на двух транзисторах, охваченных обратной связью, и имеет два различных устойчивых состояния. Статические ОЗУ поддерживают режимы хранения, чтения, записи, чтения и записи. Главными недостатками статической памяти являются ее относительно высокие стоимость и энергопотребление.
2. Динамические ОЗУ.
Запоминающая ячейка представляет собой один моп-транзистор, который управляется напряжением и ведет себя практически как ключ. Недостатки, связанные с необходимостью регенерации информации из-за утечки тока и относительно невысоким быстродействием, компенсируются другими показателями малыми размерами элементов памяти и, следовательно, большим объемом микросхем этих ЗУ, а также низкой их стоимостью.
СОЗУ – сверхоперативное запоминающее устройство. Его быстродействие примерно в 100 раз больше быстродействия ОЗУ (реализовано на той же базе, что ЦП, поэтому по быстродействию сравнимо с ним), но емкость в несколько раз меньше.
1. Регистровая СОЗУ.
Входит в состав процессора и представляет собой набор регистров процессора, которые являются линейками триггеров. Предназначена для хранения небольшого количества информации (до нескольких десятков слов, а в RISC-архитектурах – до сотни), которая обрабатывается в текущий момент времени или часто используется процессором. Это позволяет сократить время выполнения программы за счет использования команд типа регистр-регистр и уменьшить частоту обменов информацией с более медленными ЗУ ЭВМ. Реализует возможность одновременных чтения и записи данных. Недостатком является очень быстрое заполнение по мере выполнения задач.
2. Кэш-память (буферная).
Её назначение состоит в сокращении времени передачи информации между процессором и более медленными уровнями памяти компьютера. Обеспечивает автоматическую подмену наиболее часто используемых данных кэш-ячейками, т.е. временно ячейка КЭШа заменяет собой ячейку оперативной памяти. Классический кэш представляет собой ассоциативное ЗУ, т.е. информация ищется по некоторому признаку. Кэш эффективен, когда ЦП долго работает с локальной областью памяти, в противном случае возникают коллизии.
Кэш обычно дублирует группу соседних ячеек памяти (блок) для улучшения временных характеристик.
Около 90% всех обращений удовлетворяется КЭШем.
Кэш прямого отображения строится на базе статических ОЗУ.
За каждой ячейкой памяти зафиксирован свой уровень, на котором она продублирована, поэтому при поиске осуществляется одно сравнение. Но в случае, когда у нескольких ячеек один уровень, эффективность КЭШа снижается.
По степени близости к ЦП различают:
L1 – кэш первого уровня (внутренний) – встроен в ЦП, раздельный (один – для хранения команд, два – данных);
L2 - либо также входит в микросхему процессора, либо может быть реализован в виде отдельной памяти, непосредственно подключенной к ЦП;
L3 (используется редко) – в виде отдельного устройства, которое крепится к той же шине, что и память.
Как правило, на параметры быстродействия процессора большее влияние оказывают характеристики кэш-памяти первого уровня.
Время обращения к кэш-памяти, которая обычно работает на частоте процессора, составляет от десятых долей до единиц наносекунд, т.е. не превышает длительности одного цикла процессора.
Интерфейсы
Под интерфейсами понимаются:
- шины (связывающие устройства),
- процедуры обмена информацией по этим шинам,
- механические подключения (разъёмы).
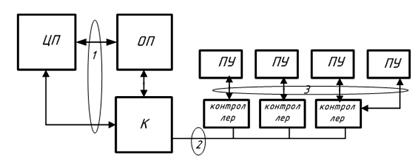
ПУ – периферийные устройства
К – канал ввода/вывода (в/в)
В вычислительной системе различают:
1) интерфейс «процессор - оперативная память – процессор – каналы ввода/вывода» (самый быстрый);
2) интерфейс ввода/вывода (расширения), с помощью которого контроллеры ПУ подключаются к системе;
3) интерфейс периферийных устройств, с помощью которого они подключаются к своим контроллерам (адаптерам). Адаптер – простейшее устройство, преобразующее сигналы одного интерфейса в сигналы другого. Контроллер – более сложная система (блок управления).
Виды интерфейсов
По способу передачи
1. Параллельные: разряды данных передаются одновременно, параллельно (шины ISA, PCI, IDE, Centronics).
2. Последовательные: информация передается последовательно по одному биту (шины USB, RS-232)
Синхронизация обмена
2 способа синхронизации:
1) механизм стробирования данных: по линии шины данных передаются либо “1” либо “0” Для того чтобы приемник надежно различал эти события, используют специальный стробирующий сигнал, который подается одновременно с данными в момент времени, когда на линии устанавливаются действительное значение данных.
2) синхронизация квитированием. Данный способ использует для реализации 2 сигнала – прямой и обратный. После того, как данные с передающего устройства будут зафиксированы в принимающем устройстве, последнее выдаст сигнал, что данные приняты, затем будет выдан сигнал о готовности принимать следующую информацию.
По топологии (характеру связи между устройствами) бывают:
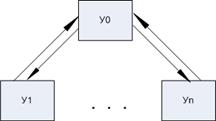
1) с индивидуальной (радиальной) системой шин, которая включает в себя
- главное устройство, к которому подключаются другие, ведомые;
-провода прямой и обратной передачи;
- сигналы синхронизации и управления (сигнал выборки со стороны главного устройства, указывающий, что с главным устройством устройству можно работать).
У - устройство
2) с коммунальной (магистральной) системой шин: все устройства взаимодействуют через общую магистраль.
У0 выставляет по шине адреса номер вызываемого абонента. Каждое устройство сравнивает его со своим. В случае совпадения устройство начинает работать (только одно) В противном случае, устройство не реагирует на сигнал.
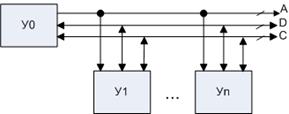
А – шина адреса
D – шина данных
С – шина управления и синхронизации
Организация ввода/вывода
Организацией обмена между системой и периферийными устройствами управляет комплекс аппаратно-программных средств, называемый каналом ввода/вывода.
2 типа:
- программно управляемые (ПУК)
- канал прямого доступа в память (КПДП)
1. В программно-управляемых каналах при обмене информацией используется аппаратура ЦП с помощью команд IN/OUT (обмен между регистрами и портами ввода/вывода)
Скорость обмена определяется самым медленным устройством.
По производительности устройства делятся на классы:
Низкоскоростные: передается меньше 1000 символов/сек (например, клавиатура,)
Среднескоростные: до 100000 символов/сек (принтер, дискеты)
Высокоскоростные: более 100000 символов/сек (видеокарта, диски).
ЦП видит периферийные устройства как порты. Каждое устройство логически представлено в виде нескольких портов:
- порты (регистры) данных на в/в;
- регистр управления, содержимое которого формируется ЦП-ом и передается в периферийное устройство, его разряды используются для задания операций
- регистр состояния (статусный): отдельные биты формируются периферийным устройством и передаются в ЦП (7-ой и 15-ый бит указывают на готовность участия в обмене: «готов/не готов», «ошибка/нет ошибки»).
При программной реализации алгоритма обмена, в свою очередь, различают два способа в/в, в зависимости от того, каким образом обнаруживается готовность ПУ к обмену:
1. Путем опроса флага готовности ПУ
2. По прерываниям процессора от ПУ.
Алгоритм обмена, основанный на опросе флага готовности (ввод- вывод по условию готовности) включает следующие шаги.
1. На этапе начальной подготовки ЦП опрашивает состояние ПУ (включено, исправно, свободно) и запускает механизм ПУ.
Функционирование ПУ начинается лишь после того, как носитель информации достигнет рабочей скорости. Только после этого начинается обмен информацией с носителем, то есть этап передачи данных.
2. Контроллер ПУ обеспечивает управление процессом считывания (записи) информации с носителя. Считывание (запись) информации обычно осуществляется байтами данных. Прочитанный с носителя байт заносится в буферный регистр данных (РД), после чего устанавливается флаг ГТ (Готов). В случае записи контроллер ПУ обеспечивает перепись байта данных из регистра данных на носитель, после чего устанавливается флаг ГТ, что означает готовность принять из ЭВМ очередной байт данных.
Процессор, обнаружив факт установки флага, осуществляет ввод (вывод) данных из РД, а контроллер ПУ - сброс флага ГТ. Далее процессор формирует адрес ячейки памяти, с которой ведется обмен и подсчитывает количество переданной информации.
Далее осуществляется анализ на конец передачи блока данных и, если переданы еще не все данные, то выполняется сканирование флага готовности.
3. На этапе завершения обмена опрашивается состояние ПУ и выключается механизм ПУ, приводящий в движение носитель информации.
Рассмотренный способ обмена обладает существенным недостатком - непроизводительные затраты процессорного времени на ожидание готовности ПУ.
В/в по прерываниям процессора с точки зрения производительности ЭВМ более эффективен, так как время ожидания готовности ПУ процессор может использовать для выполнения другой программы. При этом способе в момент готовности контроллер ПУ вырабатывает сигнал прерывания, по которому процессор прерывает выполнение текущей программы и приступает к обслуживанию данного ПУ. Обслуживание осуществляется путем передачи управления специальной подпрограмме обмена, написанной для данного ПУ, которая обеспечивает обмен с РД ПУ. После ее завершения управление возвращается прерванной программе. Сигналов прерывания вырабатывается столько, сколько байтов информации вводится (выводится). Недостаток обмена по прерываниям процессора - это ощутимые накладные расходы времени на передачу одного байта данных, поэтому обмен по прерываниям процессора применяется для обслуживания медленнодействующих ПУ (клавиатура, принтер и т. п.).
2. Контроллер прямого доступа в память (КПДП).
Обменом управляет специальный контроллер или сопроцессор ввода/вывода , который инициализируется ЦП и передает данные от заданного ПУ в заданную область ОП, или наоборот.
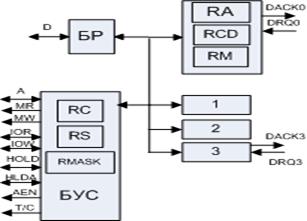
DRQ – запрос на обмен, который говорит, что устройство готово участвовать в обмене
DASK – разрешение запроса
БР – буферный регистр
БУС – блок управления синхронизации
КПДП состоит из 4 одинаковых каналов. Каждый канал содержит 3 регистра: управляющие процедурой обмена с данным устройством:
RA – регистр адреса области памяти, участвующей в обмене (16-разрядный),
RCD – счетчик данных (количество байт, участвующих в операции (макс. 64 Кбайт))
RM – регистр режима, который задает направление обмена между ОП и ПУ.
Канал может работать в 4 режимах:
1) побайтный обмен: передав 1 байт, КПДП отключается и дает возможность работать ЦП или другим устройствам;
2) блочный обмен: начавшаяся операция будет поддерживаться, пока не передадутся все данные.
в) блочный обмен с ожиданием: контроллер будет выполнять операцию, не пуская другие устройства к работе
г) режим каскадного подключения.
3 фазы работы КПДП.
1. Инициирование.
2. Обмен.
3. Завершение.
В канал загружается адрес, количество слов, режим работы канала. Соответствующий канал размаскировывается, ЦП переключается на другую работу. ПУ, когда готово участвовать в обмене, передает сигнал DRQ, который анализируется контроллером. Контроллер посылает в ЦП сигнал HOLD (уступить шину). ЦП отключается от системной шины и передает контроллеру сигнал HLDA (освободил). Контроллер устанавливает сигнал AEN, вследствие чего все устройства отключаются от системной шины, кроме пославшего сигнал.
После этого контроллер выдает ПУ сигнал DACK. Этот сигнал после завершения обмена убирается, счетчик данных уменьшается на 1, контроллер убирает HOLD и AEN, ЦП захватывает шину и убирает HLDA. Контроллер готов реагировать на следующий сигнал DRQ.
Повышение производительности вычислительных систем
Производительность – это количество операций в единицу времени. Быстродействие – время выполнения операций. Пусть существует функция F, которую можно разделить на F1, F2, F3. При выполнении задачи F методом, описанным на рисунке, время выполнения F вычисляется как сумма времени выполнения операций F1, F2, F3.
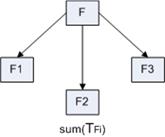
При выполнении задачи F методом, описанным на рисунке, время выполнения F вычисляется как максимальное из значений времени выполнения операций F1, F2,F3.

Для ускорения выполнения операций используется конвейеризация (локальное совмещение команд – одновременное выполнение различных фаз соседних команд).

Выполнение команд последовательно осуществляется по следующей схеме:
![]()
При конвейеризации используется другой принцип:

При этом время выполнения операций не изменилось, но производительность увеличилась в 2 раза.
Для обработки операндов и команд используется буферная память.

БК – буфер команд
БД – буфер данных
Принцип конвейеризации по-разному реализуется в современных микропроцессорах. Структура микропроцессора типа CISC предполагает, что команды имеют разную длину и время выполнения, поэтому они сложны аппаратурно. Процессоры типа RISC предполагают, что все команды имеют одинаковый формат, Цикл выполнения команд тоже одинаков. В них количество команд сведено до минимума (содержат набор простых, чаше всего встречающихся команд). Уменьшено количество различных вариантов обращения к памяти. ЦП ориентирован на работу с регистрами, а не с памятью. Но удлинение кода приводит к увеличению затрат ОП.
Команды имеют следующий формат:
![]()
КОП – код операции
M – признак команды
R1 – номер регистра
R2 – номер ячейки
R3 (L) - смещение
Конфликты, возникающие при использовании принципа конвейеризации.
1. Структурный – возникает при одновременном обращении в различных фазах к одному тому же ресурсу.

Например, фазы ВО и ВК, ВК и ИК, выполняемые в одно время, требуют обращения к памяти. Решение – введение отдельных КЭШей (для команд и для данных).
2. Зависимость по данным. Например, при выполнении следующих операций
сложить R1 R2 R3 (результат сложения R2 и R3 записывается в R1)
умножить R4 R1 R5
При выполнении ВО второй команды требуется элемент R1, который будет получен только при выполнении ЗР первой операции. Это невозможно. Решение:
1) введение дополнительной пустой операции (приторможение конвейера)
2) заранее выявить конфликт и изменить порядок команд
3. Конфликт по управлению.
Например, такой конфликт возникает при:
сложить R1 R2 R3 (результат сложения R2 и R3 записывается в R1)
условный переход Z![]()
![]() умножить R2 R3 R4
умножить R2 R3 R4
Решение:
1) вставить нейтральные команды («пузырь»),
2) спекулятивное выполнение,
3) предсказание перехода (если условие выполняется→переход к кэш-условию).
Мультипрограммирование
Особенность организации МП режима в том, что он реализуется в однопроцессорной машине. На рисунке представлена схема работы ЦП над двумя задачами одновременно.
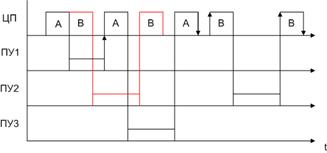
Для работы ЦП по данной схеме используется принудительное переключение. Цикл активности – время непрерывного решения задачи ЦП-ом., которое лимитируется.
Аппаратные о программные средства для поддержания МП.
1. Канал по обслуживанию периферийных устройств.
2. ЦП должен иметь таймер.
3. Система прерываний.
2 и 3 – механизмы переключения.
4. Диспетчер определяет порядок выполнения программы.
5. Память: внешняя (файловая система) и ОП.
При МП решаются задачи защиты и распределения памяти. Динамическое распределение памяти – это выделение памяти каждой программе по мере и в объемах ее необходимости.
Защита – это предотвращение влияния одной программы на другую через общую память.
Распределение памяти
Для распределения памяти используются таблицы массивов, содержащие следующие параметры: базовый адрес, длина. Первая строка таблицы описывает начальный адрес свободной области памяти. Память должна освобождаться в порядке, обратном ее заполнению. Обращение к памяти происходит по адресу B+адрес, указанный в программе. Для защиты необходимо выполнение следующего условия: Bi+ni<Ai*<=Bi, где Ai* - адрес при обращении к i-ому массиву.
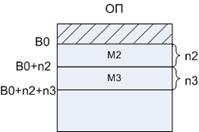
Виртуальная память – это расширение ОП за счет дисковой памяти.
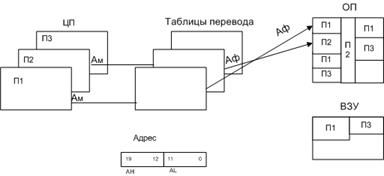
Ам – математический адрес (сформированный в ЦП)
Aф – физический адрес (сформированный при помощи таблиц перевода)
Аh – старшая часть, указывающая номер страницы
Al – младшая часть, указывающая ячейки внутри страницы.
Схема преобразования математического адреса в физический.

Sм – указатель на строку таблицы страниц (ТС)
Sф – физический адрес соответствующей страницы
ДП – диспетчер памяти
Метод защиты памяти
При страничной организации используется метод «ключ-замок». Ключ – это код, который ставится в соответствие программе. Замок - это код, который ставится в соответствие области памяти. При обращении к памяти происходит сравнение ключа с замком, и в случае совпадения разрешается доступ к памяти.
Сегментация памяти
Процессор при обработке программы взаимодействует с оперативной памятью ОП, которая представляется единым массивом однобайтных ячеек, обращение к которым происходит по их номерам (физическим адресам). Для обращения к памяти процессор предварительно помещает адрес ячейки в один из своих регистров. Шестнадцатиразрядный процессор не может хранить в своих регистрах двадцатиразрядный адрес. Поэтому в нем применена так называемая сегментация памяти, которая заключается в том, что истинный, физический адрес ячейки хранится в двух регистрах. Один из них - сегментный, он хранит адрес начала блока памяти, который и называется сегментом. Если к шестнадцати разрядам сегмента справа дописать четыре двоичных нуля (16+4=20), то получим физический адрес начала сегмента в ОЗУ. Второй регистр хранит величину смещения адреса требуемой ячейки от начала сегмента. Адрес ячейки памяти записывается в виде двойного слова (4 байта): <сегмент>:<смещение>. Сегмент всегда начинается с ячейки, номер которой заканчивается на 4 двоичных нуля. Минимальная длина сегмента 16 байтов (параграф). Максимальная длина определяется длиной регистра, хранящего смещение и равна 64 Кбайта. Пара регистров CS: IP определяют адрес следующей команды программы. Для адресации данных используются сегментные регистры DS и ES, а в качестве регистров, хранящих смещение, используются регистры общего назначения BX, SI, DI. Для работы с сегментом стека используют сегментный регистр SS и регистр BP.
Режимы формирования адреса
Режим R86 (реальный) используется при включении питания. Это BIOS – этап, на котором происходит конфигурирование, тестирование системы.
В защищенном режиме P86 происходит запуск Windows.
1.ЦП получает набор специальных управляющих регистров (трассировки и тестирования).
2.Он изменяет способ формирования адреса, при этом не используются коды команд, написанных для R86 (для их выполнения используется V86).
3.Обеспечивается МП режим работы (включены механизмы распределения и защиты памяти). V86 обеспечивает согласование режимов на уровне кодов команд.
Адресация памяти в P86 происходит следующим образом: ЦП формирует 32-разрядный адрес. Но этот адрес не физический. Формируется линейный, линейно-страничный адрес (страничная организация поверх линейной памяти)
В R86 сегментный регистр задает местонахождение базы. Старшие 13 разрядов этого сегмента – селектор – указатель номера строки в таблице дескрипторов. Существует 2 таблицы дескрипторов:
GDT (Global)-единственная, создается до работы в P86 (R86), общая для всех решаемых программ,
LDT (Local).
Каждая программа может иметь свою собственную DT, которая описывает структуру памяти и используется только данной программой. Переключение GDT на LDT выполняется следующим битом сегментного регистра. Местонахождение GDT задается специальным регистром GDTR. RPL (младшие 2 разряда сегмента) – указатель, используемый для допуска к соответствующей области памяти (ключ). Дескриптор – это код, описывающий некоторую область памяти (и других информационных структур: шлюзов, задач). Дескриптор состоит из:
1) 32-разрядной базы (адрес сегмента, сегмент может начинаться с любого байта)
2) границы (20 разрядов)
3) DPL (2 разряда) – замка, который используется для защиты сегмента
4) Внутри дескрипторов есть поле некоторых признаков (10), которые указывают, что именно описывает дескриптор:
а) признак гранулярности: размер сегмента может быть задан либо в байтах, либо в страницах.
б) тип (назначение): сегмент кода, данных, принадлежности ОС или пользовательской программе.
в) доступность: по границе (база <= линейного адреса< границы); DPL – имеет 4 кольца защиты, информация о программе должна относиться к определенному уровню защиты, меньший номер имеет большую защищенность. Для осуществления доступа к памяти необходимо выполнение следующего условия: max(RPL,CPL)<=DPL, где RPL- текущий уровень защиты, CPL – RPL сегментного регистра CS.
Чтобы контролируемо обойти ограничения, накладываемые системой защитой памяти, используются шлюзы. Например, шлюз задач позволяет вызвать задачу с более высоким приоритетом.
Для обеспечения защиты памяти и правильного обращения к ней используется TTS (таблица состояния процесса). Это регистр обращения (страница размером 4096 байт, в которой отображается текущее состояние регистров процессора), бинарная таблица в/в, в которой каждый бит ассоциирован с некоторым регистром (портом в/в). Если установлена 1, то порт для данной программы закрыт. Таким образом, осуществляется контроль за обращением к памяти и портом.
Организация материнской платы ( i8086)
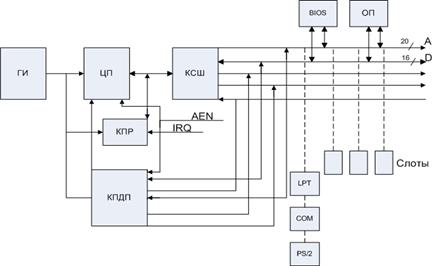
AEN – указывает, кто хозяин шины (ЦП или контроллер)
КСШ – контроллер системной шины
Слоты – преобразуют сигналы ISA в сигналы шины Centronics
КПР – контроллер прерываний
КПДП – контроллер прямого доступа в память
COM – порт, осуществляющий обмен по интерфейсу RS232C скоростью до 115-200 Кбит/сек (модемы).
LPT – разъем для принтера.
PS/2 – разъем для мыши и клавиатуры
Общее адресное пространство: 20 Мбайт (640 байт - ОП, ост.- BIOS, память монитора и т.д.)
Системный интерфейс: собирает все компоненты в единое целое.
Интерфейс ПУ поддерживает стандарт EISA, который позволяет подключаться к 16-ти и 32-ти машинам.
Шина расширения: сегодня используются шины PCI – это 32 или 64-разрядная шина с тактовой частотой – 33МГц. Адресное пространство указывает производителей, настройки шины и режим обмена, тип устройства, младшие порты, которые определяются пользователем. Данная шина поддерживает режим plug&play, то есть система может сама себя конфигурировать. Используется режим пакетного обмена, что повышает скорость обмена.
Логическая схема системной платы
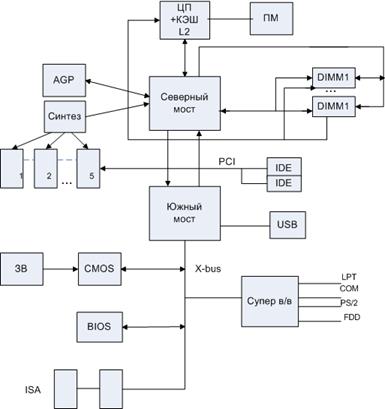
AGP – упрощенный вариант PCI.
IDE – контроллер, преобразующий сигналы шины PCI в сигналы дисковых устройств.
CMOS – энергонезависимая память, хранящая параметры настройки, системные часы, питается от литиевого аккумулятора.
BIOS – базовая система в/в
EISA – интерфейс внутренней шины x-bus.
Быстродействие различных компонентов компьютера (ЦП, ОП и контроллеров периферийных устройств) может существенно различаться. Для согласования быстродействия на системной плате устанавливаются специальные микросхемы (чипсеты), включающие в себя контроллер ОП (северный мост) и контроллер периферийных устройств (южный мост).
К северному мосту подключается шина PCI, которая обеспечивает обмен информацией с контроллерами периферийных устройств. Контроллеры периферийных устройств (звуковая карта, сетевая карта, модемы) устанавливаются в слоты расширения системной платы. Для подключения видеокарты используется специальная шина AGP.Южный мост обеспечивает обмен информацией между северным мостом и портами для подключения периферийного оборудования.
Для подключения сканеров и цифровых камер обычно используется порт USB (UniversalSerialBus – универсальная последовательная шина).
К кристаллу супер в/в подключается принтер через параллельный порт LPT, клавиатура, мышь с помощью порта PS/2, модем через COM-порт.
Многопроцессорные вычислительные системы
По организации информационно-логического взаимодействия (потокам) выделяют системы, действующие по схеме:
1) «ОКОД» - один поток команд, один поток данных – используют для выполнения команд с двумя операндами и одним результатам (скалярный процессор)
2) «ОКМД» - одна команда, много данных: одна команда поступает сразу в несколько ЦП, но каждый работает со своими данными (векторный, или матричный, процессор)
3) «МКОД» - много команд, одни данные: в каждый момент времени в каждый процессор поступает своя команда. Такие системы используются при обработке звука и изображения.
4) «МКМД» - много команд, много данных.
По функциональному значению различают:
1) сети: машины обмениваются файлами через каналы связи (больше ничего общего не имеют);
2) вычислительные комплексы (кластерные системы) – несколько машин, каждая из которых работает по своей ОС, но обмен информацией происходит через общую внешнюю или ОП. Плюс такой системы – обеспечение надежности и высокой готовности.
3) Параллельные системы (ОКМД)
2 вида: массивно-параллельные и векторно-конвейерные.
Сети ЭВМ – это две и более машин, объединенные каналами связи.
По размеру различают
1) локальные (LAN), которые, как правило, располагаются в одном помещении, здании, группе зданий. Это самые производительные сети: чем ближе пользователи друг к другу, тем больший объем информации предается. Поскольку для таких сетей характерны небольшие расстояния (500 м-2 км), а всё оборудование работает в комфортных условиях, то в них не возникает вопросов по проблеме целостности информации при передаче из-за невысокого уровня электромагнитных помех.
2) территориально-распределенные (WAN). Так как машины могут находиться на достаточно большом расстоянии друг от друга, то могут возникнуть помехи, что приведет к искажению канала.
3) кампусная («лагерь») – сеть микрорайона, совмещающая технологию LAN и WAN.
Основными составляющими любой сети являются
- абонентские машины (хосты)
- узлы распределения информации (коммутаторы)
- скоростной канал
- сеть абонентского доступа
По принципам коммутации:
- коммутация каналов (КК) – работает как телефонная сеть,
- коммутация сообщений (КС) – функционирует по принципу телеграфа,
- коммутация пакетов (КП) – сообщения делятся на части (пакеты).
Выделяют ряд этапов обмена информацией, которые отражаются в модели взаимодействия открытых систем (ВОС).

7 уровней модели ВОС:
1) нижний – физический уровень – это канал аппаратуры, обеспечивающий надежность взаимодействия, т.е.передачи сигналов 0 и 1. Он организовывает физическое взаимодействие между устройствами сети.
2) на канальном уровне IP-протокол обеспечивает структурирование информации, передает пакеты по звеньям.
Структура пакеты:
![]()
Флаг-признак начала пакета,
Адрес и управление – адреса отправителя и получателя
Данные
Контрольная сумма (КС)
Флаг – признак окончания пакета
3) сетевой уровень определяет правила движения пакета по сети сложной конфигурации, т.е. правила маршрутизации.
Все 3 уровня используются во всех участниках обмена.
Последующие уровни работают на абонентских машинах.
4) транспортный, задача которого заключается в том, чтобы на передающем конце делить сообщения на пакеты, а другом конце – собирать.
5) сеансовый: синхронизация взаимодействия машин: проверка готовности абонента к приему информации, приостановка сообщения в случае неуспевания обработки, возобновление, разъединение.
6) представительский: определяется, каким образом кодируется сообщение.
7) Пользовательский: определяет вид оказания услуги, непосредственное взаимодействие с пользователем.
Интерфейс – это правила взаимодействия соседних уровней на одной машине. Стек – набор согласованных протоколов различных уровней, которые определяют какую-либо технологию. Протокол – правила, по которым взаимодействуют уровни системы.
Механизм управления передачи
Механизм подразумевает некоторые средства, которыми обладают сетевые компоненты для обеспечения определенного уровня взаимодействия устройств. Задачи:
- целостность информации
- согласование производительности различных устройств (в обратном случае это может привести к искажению и потери информации)
Механизмы работают на канальном и транспортном уровнях, но не на сетевом.
1. Обеспечение целостности сообщений
структура пакета (на канальном уровне)
![]()
Флаг – это уникальная комбинация, которая не встречается внутри пакета.
Он определяет, начался пакет или закончился
Контрольная сумма – это несколько байт (2,4), которые используются для выявления ошибок.
Часть пакета, не считая флаги, рассматривается как большое двоичное число.
Оно при передаче делится на заранее известное постоянное число (как правило, это простое число). В результате выбирают остаток – это контрольная сумма. На приеме проводится та же операция, и полученное число сравнивается с принятой КС. При совпадении ошибка не выявлена. При несовпадении – ошибка.
Способ исправления ошибки - режим повторной передачи, реализующийся в методе квитирования.

Квитанция – это служебный пакет, либо квитанция спрятана внутрь управляющей части обычного пакета. Она может быть положительной и сообщать, что «Всё в порядке», а может быть отрицательной и информировать о том, что следует произвести повтор передачи.
На передающем объекте (устройстве) переданное сообщение будет сохранено до получения положительной квитанции. Если за время T (таймер) квитанция не придет к источнику, считаем, что пакет не принят, и отправляем его заново. При такой работе часть пропускной способности канала затрачивается на передачу служебной информации (квитанции). Поэтому разработан метод квитирования, основанный на использовании окон. Окно – это некоторое количество пакетов (данных), которое может быть передано без квитанции. В сетях X25 размер окна заранее известен – 8 пакетов.

Квитанция К4 говорит о том, что приемник принял 3 пакета, ожидает 4-ый.
Каждый передаваемый пакет имеет метку, указывающую номер в окне. Каждая квитанция имеет 2 счетчика: количество принятых и переданных пакетов. Если 3-5 попыток передать пакет оказываются неудачными, связь в канале разрывается и посылается сообщение в вышестоящий уровень.
2. Управление потоком предполагает согласование пропускной способности.
Коммутационное устройство (КУ) может рассматриваться как коммутатор, если это канальный уровень, или маршрутизатор на сетевом уровне. Если все передаваемые пакеты идут на один порт, то может произойти превышение пропускной способности, образуется так называемая «пробка». Данная ситуация разрешима. В этом случае на КУ включается буфер, и пакеты, которые не могут быть переданы, встают в очередь (по принципу FIFO: «последним вошел, последним вышел»). Однако физической памяти может не хватить, и данные могут быть потеряны и уничтожены. В этой ситуации КУ обмениваются специальными пакетами с сообщениями «готов/не готов» (RDY/NRDY), поэтому главный КУ посылает другим машинам сигнал «не готов». Последние перестают передавать данные, а главный обрабатывает очередь. В этом случае порт закрыт, но данные идут. В результате может произойти блокировка значительной части сети.
Локальные сети
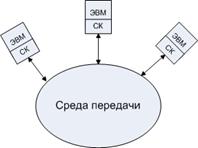
СК – сетевая карта
Через среду передачи можно осуществить прямой доступ к различным ЭВМ.
Коллизия – это столкновение двух передач. Локальные сети различают по способу организации доступа:
1) «доступ разрешен всем»: используется механизм разрешения коллизий (сеть Ethernet)
2) сеть с маркерным доступом, не допускает возникновения коллизий.
Соединение компьютеров между собой производится с помощью кабелей различных типов (коаксиального, витой пары, оптоволоконного). Важнейшей характеристикой локальных сетей является скорость передачи информации по сети. Общая схема соединения компьютеров в сети называется топологией сети.
Топологии могут быть различны:
Шинные (линейные, bus)
Кольцевые (петлевые, ring)
Радиальные (звездообразные, star)
Распределенные радиальные (сотовые, cellular)
Иерархические (древовидные, hierarchy)
Полносвязные (сетка, mesh)
Смешанные (гибридные)
Сети с шинной топологией используют линейный моноканал передачи данных, к которому все узлы подсоединены через интерфейсные платы посредством относительно коротких соединительных линий. Данные от передающего узла сети распространяются по шине в обе стороны. Промежуточные узлы не ретранслируют поступающих сообщений, информация поступает на все узлы, но принимает сообщения только тот, кому оно адресовано. Шинная топология – одна из самых простых. Такую сеть легко наращивать и конфигурировать, а также адаптировать к различным системам. Она устойчива к возможным неисправностям отдельных узлов.
В сети с кольцевой топологией (например, TokenRing) все узлы соединены в единую замкнутую петлю каналами связи. Выход одного узла сети соединяется со входом другого. Информация по кольцу передается от узла к узлу, и каждый узел ретранслирует посланное сообщение. В каждом узле имеется своя интерфейсная и приемо-передающая аппаратура, позволяющая управлять прохождением данных в сети. Передача данных по кольцу с целью упрощения приемо-передающей аппаратуры выполняется только в одном направлении. Принимающий узел распознает и получает только адресованные ему сообщения.
Основа последовательной сети с радиальной топологией составляет сервер, к которому подсоединяются рабочие станции, каждая по своей линии связи. Вся информация передается через центральный узел, который ретранслирует, переключает и маршрутизирует информационные потоки в сети. Используются и широковещательные радиальные сети с пассивным центром, в которых вместо центрального сервера устанавливается КУ (обычно концентратор, hub), обеспечивающее подключение одного передающего канала сразу ко всем остальным. Помимо концентратора существуют и другие КУ.
Репитор (усилитель), работающий на физическом уровне и используемый при передаче на очень большие расстояния. Максимум можно объединить 4 сектора, т.е. последовательно подключить только 3 репитора.
Если в одной сети работают более 20-ти станций, используется мост – устройство, которое работает на физическом и канальном уровнях. Станциям мосты не видны. Цель моста – локализовать трафик внутри каждого сегмента сети. Мост запоминает MAC станции и в каком она сегменте, и далее работает как фильтр. Широковещательный пакет пропускается мостом и доставляется всем станциям.
Для организации доступа к среде используется протокол MAC: все станции все время принимают информацию, циркулирующую в этой линии. Если станция хочет передать, она «ждет молчания». Если хотят передать сразу несколько станций, то каждая из них замолкает на случайное время.
Структура передаваемого пакета
![]()
MAC1 – адрес приемника
MAC2 – адрес станции-передатчика
PAD – дополнитель (используется, если длина информационного поля меньше 64 байт, т.е. PAD+Инф.поле >=64, в fastEthernet до 400 байт)
Управление – это некоторая комбинация: либо длина следующего поля, либо тип информации следующего поля.
Коммутируемый Ethernet
Это дальнейшее развитие моста. Идея состоит в том, чтобы повысить пропускную способность сети за счет установления нескольких независимых соединений.
В каждом порту принимаемые сигналы буферизируются. Коммутационная матрица может объединить 2 любых порта. ЦП анализирует адреса буферизированных пакетов, запоминает их и устанавливает соответствие между адресами пакетов и номерами портов. В дальнейшем ЦП знает, какой порт к какой машине принадлежит. Следовательно, несколько пар портов могут работать одновременно, что повышает пропускную способность системы, работа по разным портам может осуществляться на разной скорости.
Сеть с маркерным доступом ( Token Ring )
Пакеты имеют добавок – маркер – это байт со следующей структурой:
![]()
Маркер генерирует специальное устройство – контроллер. ММ – это тип, который указывает на то, идет или не идет за маркером пакет (если пустой→в кольце ничего не передается). Кадр – это MAC получателя. Станция, получив маркер, смотрит, следует ли за ним пакет: если пакета нет, то она пропускает маркер через себя или отправляет свой пакет. Если же за ним следует пакет, она проверяет кадр: если пакет направлен к ней, то она его читает, а тип маркера устанавливается в пустой. Если станция получила пустой маркер и хочет отправить пакет, она изменяет тип маркера и прицепляет кадр. R и X – это указания приоритета, который исключает монополизацию одной станцией кольца. R может изменяться только контроллером домена. В соответствии с этим приоритетом станции разбиваются на 8 групп. X – это приоритет, который станция устанавливает сама, если ее приоритет выше уже записанного. При полном прохождении кольца в X записывается R. Таким образом, в сети никогда не передаются одновременно 2 пакета.
Интернет
Интернет – это механизм межсетевого взаимодействия, позволяющий различным локальным сетям работать друг с другом.
Первая версия Интернет (Arpanet) была изобретена в 1969г. по заказу министерства обороны США с целью разработать технологию передачи по сети, устойчивую к ядерному удару.
Интернет – это собирательное название множества сетей из разных стран мира, которые построены на различном технологическом оборудовании, администрируются различными лицами, но все они отвечают определенным правилам. Они включают:
1) набор протоколов (TCP/IP - протоколы), стек которых состоит из трех частей:
- IP (сетевой протокол, определяющий правила передачи информации по сети)
- TCP (управление передачи: протокол транспортного и сеансового уровней)
- HTTP, FTP (решение прикладных задач)
2) IP-адресация, предполагающая, что любая машина в Интернет имеет свой уникальный номер
3) Клиент-серверная организация работы приложений. Все услуги, оказываемые Интернет, стандартизированы. Каждая услуга оказывается двумя программами. Серверная – хранит и обрабатывает информацию. Машины-серверы всегда подключены к сети Интернет. Абонентские программы включают упрощенную функцию (схему) приема и представления информации.
4) свободный обмен информацией.
Организация Интернет
Юридическое лицо, оказывающее доступ к Интернету, - это ISP (InternetServiceProvider).Провайдеры работают от территории. Существует несколько уровней провайдеров. Провайдеры 1-го уровня обращаются в организацию Internic, которая распределяет IP-адреса. Провайдеры 1-го уровня обслуживают провайдеров 2-го уровня (обслуживают регион), которые арендуют канал, покупают IP-адреса и распространяют их провайдерам 3-го уровня. Это, как правило, частные лица и организации.
IP -адресация
Различают 2 вида IP-адресов:
1) временный IP-адрес: при входе в сеть пользователю выделяется определенный IP-адрес, который закрепляется за ним на время его нахождения в сети. После выхода этого пользователя он может быть предоставлен другому пользователю;
2) постоянный IP-адрес.
IP-адрес – это двоичное 32-разрядное число (4 байта). Каждый байт представляет собой отдельное число 0..255.
Различают 2 модели адресации: классовую и бесклассовую.
Классовая модель.
Классы сетей: A, B, C - адрес указывает на два параметра: номер сети и номер машины в сети.
Класс A
Старший разряд равен нулю. Следующие 7 разрядов определяют номер сети, остальные – номер станции.
Количество сетей = ![]()
Количество машин = ![]()
Класс B
Первые 2 бита – 1,0. Номер сети занимает 14 разрядов (6+8=14). Адрес станции – 16 битов.
Количество сетей = ![]()
Количество машин = ![]()
Класс C
Первые 3 бита – 1,1,0. Номер сети занимает 21 бит (5+8+8=21). Адрес станции – 8 битов.
Количество сетей = ![]()
Количество машин = ![]()
Применяется мнемоническая форма IP-адреса, удобная для человека. При этом используется доменное имя. Выделяют несколько уровней доменов.
1-й и 2-й уровни распределяет Internic, последующие – провайдер. Домены 1-го уровня имеют фиксированное имя. Оно определяется двумя способами:
1) по генетическому происхождению (в зависимости от типа пользователя):
com – коммерческая организация
org – общественная организация
gov – правительственная организация
edu – учебное заведение
mil – военная организация
net – класс «связисты»
3) по географическому принципу
ru – Россия
de - Германия
uk – Украина
Для преобразования IP в доменное имя в каждой сети создается сервер DNS (DomainNameSystem) - таблицы перевода имени домена в адрес. Каждая машина знает, каким DNS она обслуживается. Если наш запрос неизвестен DNS, он перенаправляется другим DNS. В процессе поиска все участники запоминают IP и домен в соответствии с запросом.
Бесклассовая модель. Классовая модель нерационально использует адреса. Поэтому при адресации машин используются 2 параметра: IP-адрес и маска.
Маска – это 32-разрядное число, некоторый код, в котором единицы указывают на данные о номере сети, нули – номера машин внутри сети.
В каждой сети обязательно должно прописываться:
IP и маска
Шлюз – адрес машины локальной сети, работающей наружу
Адрес DNS-сервера
Маршрутизация
Для маршрутизации используется IP-протокол. Каждый IP-пакет снабжается IP-заголовком (стандартный размер 20 байт – пять 32-разрядных слов или 20 байт+опции-дополнительное расширение).
IP-заголовок обязательно содержит:
1) номер версии IP-протокола (1 байт);
2) время жизни пакета (TTL)
TTL измеряется в HOPах – это прохождение одного маршрутизатора.
3) два IP-адреса: приемника и источника (без маски)
4) управление фрагментированием – признак, выполнено фрагментирование или нет; если выполнено, то указывается последний фрагмент в пакете.
Маршрутизация бывает прямая и косвенная. Прямая выполняется внутри локальной сети: источник сообщений непосредственно передает напрямую пакет получателю. Косвенная маршрутизация применяется, когда приемник и получатель находятся в разных локальных сетях, т.е. нужно воспользоваться хотя бы одним посредником (маршрутизатором). Для этого в каждой локальной сети существует шлюз, имеющий номер сетевой карты или MAC-адрес, или IP-адрес. Используется протокол ARP, который позволяет по IP-адресу узнать МАС-адрес получателя. Машина-источник посылает ARP-запрос, который имеет следующую структуру:
![]()
FFF – ARP-запрос принимается всеми машинами
Все машины сравнивают IP получателя со своим. При совпадении получатель посылает «эхо» со своим МАС-адресом. Если никто не ответил, пакет посылается в шлюз, который работает как маршрутизатор, используя косвенную маршрутизацию. Она предполагает использование маршрутных таблиц, где содержатся: IP получателя, следующий маршрутизатор, номер порта, метрика (число НОРов для достижения искомого адреса). Таблицы бывают статические (в небольших сетях с 2-3 маршрутизаторами, прописываются вручную) и динамические (позволяют маршрутизаторам самим составлять таблицы). Периодически каждый маршрутизатор обменивается своим маршрутными таблицами с изменениями в них с дмаршрутизаторами-соседями. При получении нескольких путей выбирается кратчайший (используется метрика).
Приложение

Рис.1 – Главная страница

Рис.2 – Одна из страниц учебника.