| Скачать .docx |
Курсовая работа: Проблематика штучного інтелекту
М і н і с т е р с т в о о с в і т и і н а у к и У к р а ї н и
Н а ц і о н а л ь н и й у н і в е р с и т е т “Львівська політехніка ”
Кафедра „ІСМ”

Курсова робота
на тему: „Проблематика штучного інтелекту”
з дисципліни: Системи штучного інтелекту
Виконав:
ст. гр. ФЛ-44
Водарський Я.Є.
Прийняв:
Марковець О.В.
Львів-2007
Зміст курсової роботи
Вступ 3
1.1. Інтуїтивне розуміння поняття “інтелект” 4
1.2. Деякі визначення та їх критика 7
2.1 Основні проблемні середовища штучного інтелекту 8
2.2 Проблема винятків 9
2.3 Проблема неточних і неповних знань 11
2.4 Деякі проблеми виведення 12
3.1Деякі інтелектуальні задачі 13
3.2Тест Тьюринга і фатичний діалог 17
3.3Метод комп’ютерної реалізації фатичного діалогу 18
3.4Групові залежності. Проблемні сфери.20
3.5Принцип віртуальної семантичної сітки. 21
4.1 Продукційні правила 22
4.2 Компонент виведення 22
4.3 Нечітке виведення 22
5. Фрейми 24
6.1 Семантичні мережі 25
6.2 Різні способи задання семантичних мереж: переваги і недоліки 27
7. Нейронні мережі 30
8. Генетичні алгоритми 32
Висновок 34
Використана література 35
Вступ
Основним завдвнням цієї курсової роботи є знаходження і розкриття суттєвих проблемних середовищ штучного інтелекту, з якими ми стикаємося при розвязанні інтелектуальних задач.
Можна стверджувати, що “штучний” інтелект у тому чи іншому розумінні повинен наближатися до інтелекту природного і у ряді випадків використовуватися замість нього; так само, як, наприклад, штучні нирки працюють замість природних. Чим більше буде ситуацій, у яких штучні інтелектуальні системи зможуть замінити людей, тим більш інтелектуальними будуть вважатися ці системи.
Центральні задачі ШІ полягають в тому, щоб зробити ОМ більш корисними і щоб зрозуміти принципи, що лежать в основі інтелекту. Оскільки одна із задач полягає в тому, щоб зробити ОМ більш корисними, вченим і інженерам, що спеціалізуються в обчислювальній техніці, необхідно знати, яким чином ШІ може допомогти їм в розв"язку важких проблем.
Досліджувана тема стає все більш актуальною, оскільки область застосування систем штучного інтелекту поширюється в різних галузях і включає: доведення теорем; ігри; розпізнавання образів; прийняття рішень; адаптивне програмування; створення машинної музики; обробка даних природною мовою; мережі, що навчаються (нейромережі); вербальні концептуальні навчання та ін.
1.1 . Інтуїтивне розуміння поняття “інтелект”
З давніх-давен людині були необхідні помічники для полегшення виконання тих чи інших операцій. Були винайдені різноманітні механізми, машини і т.п. Поява електронно-обчислювальних машин дала змогу автоматизувати виконання трудомістких розрахункових робіт. Згодом стало ясно, що ці машини можна використовувати не тільки для обчислень, але й для керування різними пристроями, складними автоматизованими виробництвами тощо. Широкого поширення набули роботи - програмно керовані пристрої, здатні безпосередньо взаємодіяти з фізичним світом та виконувати в ньому певні дії [Крин]. Такі роботи широко використовуються у виробництві.
Природня мова на сучасному етапі малопридатна для цього через свою складність та неоднозначність. Один із шляхів вирішення цієї задачі є формулювання інструкцій мовою, зрозумілою виконавцю, тобто написання програм. Програмування полягає у перекладі інструкцій, написаних мовою, близької до природної, на мову, яку здатна сприйняти обчислювальна система. Відомі складності сучасного програмування, пов’язані з необхідністю надмірної алгоритмізації, тобто детального ретельного розписування інструкцій з урахуванням усіх можливих ситуацій. З цієї ситуації існує єдиний вихід - підвищення рівня “розумності”, інтелектуальності сучасних комп’ютерів та роботів. Постає питання, що розуміється під такими поняттями, як “інтелектуалізація”, "штучний інтелект"?
Можна стверджувати, що “штучний” інтелект у тому чи іншому розумінні повинен наближатися до інтелекту природного і у ряді випадків використовуватися замість нього; так само, як, наприклад, штучні нирки працюють замість природних. Чим більше буде ситуацій, у яких штучні інтелектуальні системи зможуть замінити людей, тим більш інтелектуальними будуть вважатися ці системи.
Навряд чи є сенс протиставляти поняття штучного інтелекту і інтелекту взагалі. Тому слід спробувати визначити поняття інтелекту, незалежно від його походження.
Людина вважається інтелектуальною “від природи”, і цей інтелект був вироблений на протязі мільйонів років еволюції. Людина вміє вирішувати багато інтелектуальних задач. Кожна людина вважає, що вона розуміє значення слова “інтелект”, але якщо попросити дати визначення цього слова, в переважній більшості чіткої відповіді не буде. І дійсно, дати визначення поняття інтелекту, яке б задовольняло всіх, очевидно, неможливо. Далі будуть проаналізовані деякі спроби визначення цього поняття та їх критика. Але відсутність чіткого визначення не заважає оцінювати інтелектуальність на інтуїтивному рівні. Можна навести як мінімум два методи такої оцінки: метод експертних оцінок іметод тестування [Посп ].
При застосуванні методу експертних оцінок рішення про ступінь інтелектуальності приймає досить велика група експертів (незалежно або у взаємодії між собою);відомо багато способів організації взаємодії між експертами.
При застосуванні методу тестування пропонується розв’язати ті чи інші тестові завдання. Існує значна кількість інтелектуальних тестів, апробованих практикою, для оцінки рівня розумових здібностей людини, що знайшли застосування в психології та психіатрії [ Айзенк, Дюк, Клайн]. Наведемо декілька прикладів.
Приклад 1.1. Вставте число, яке пропущене:
36 30 24 18 6
Приклад 1.2. Викресліть зайве слово:
лев лисиця жираф щука собака
Потрібно наголосити, що поняття “штучний інтелект” не можна зводити лише до створення пристроїв, які повністю або частково імітують діяльність людини. Не менш важливою є інша задача: виявити механізми, які лежать в основі діяльності людини, щоб застосувати їх при вирішенні конкретних науково-технічних задач. І це лише одна з можливих проблем.
Отже, штучний інтелект (ШІ) - це наука про концепції, що дозволяють обчислювальним машинам (ОМ) робити такі речі, які у людей виглядають розумними. Але що ж являє собою інтелект людини? Чи є у них здатність роздумувати? Чи є здатність засвоювати і використовувати знання? Чи є здатність оперувати і обмінюватися ідеями? Безсумнівно, всі ці здібності являють собою частину того, що є інтелектом. Насправді дати визначення в звичайному значенні цього слова, мабуть, неможливо, тому що інтелект - це сплав багатьох навичок в області обробки і представлення інформації.
Центральні задачі ШІ полягають в тому, щоб зробити ОМ більш корисними і щоб зрозуміти принципи, що лежать в основі інтелекту. Оскільки одна із задач полягає в тому, щоб зробити ОМ більш корисними, вченим і інженерам, що спеціалізуються в обчислювальній техніці, необхідно знати, яким чином ШІ може допомогти їм в розв"язку важких проблем.
Область застосування.
· Доведення теорем;
· Ігри;
· Розпізнавання образів;
· Прийняття рішень;
· Адаптивне програмування;
· Створення машинної музики;
· Обробка даних природною мовою;
· Мережі, що навчаються (нейромережі);
· Вербальні концептуальні навчання.
На початку 80-х років у дослідженнях зі штучного інтелекту сформувався самостійний напрямок, що одержав назву "експертні системи" (ЕС).
Експертна система - це програмний засіб, що використовує експертні знання для забезпечення високоефективного вирішення неформалізованих задач у вузькій предметній області. Основу ЕС складає база знань (БЗ) про предметну область, що накопичується в процесі побудови й експлуатації ЕС. Нагромадження й організація знань - найважливіша властивість усіх ЕС.
1. 2 . Деякі визначення та їх критика
Було зроблено чимало спроб дати формальне визначення поняття інтелекту, зокрема, штучного. Очевидно, найбільш відомим є визначення предмету теорії штучного інтелекту, яке було введене видатним дослідником у галузі штучного інтелекту Марвіном Мінським. Воно потрапило до багатьох словників та енциклопедій з невеликими змінами і відображає таку основну думку: “штучний інтелект є дисципліна, що вивчає можливість створення програм для вирішення задач, які при вирішенні їх людиною потребують певних інтелектуальних зусиль”. Але і це визначення має вади. Головна з них полягала в поганій формалізації поняття “певні інтелектуальні зусилля”. “Певних інтелектуальних зусиль” вимагає, наприклад, виконання простих арифметичних операцій, але чи можна вважати інтелектуальною програму, яка здатна до виконання тільки таких операцій? Відтак у ряді книг та енциклопедій до наведеного визначення додається поправка: "сюди не входять задачі, для яких відома процедура їх розв’язку". Важко вважати таке формулювання задовільним. Розвиваючи цю думку далі, можна було б продовжити: отже, якщо я не знаю, як виконувати деяку задачу, то вона є інтелектуальною, а якщо знаю - то ні. Наступний крок - це відомі слова Л.Теслера: “Штучний інтелект - це те, чого ще не зроблено” [Мичи]. Цей парадоксальний висновок лише підкреслює дискусійність проблеми.
Є деякі більш конструктивні визначення інтелекту. Наприклад, в [Ендрю] наводиться одне з них: “інтелект є здатність правильно реагувати на нову ситуацію”. Там же наводиться і критика цього визначення: не завжди зрозуміло, що слід вважати новою ситуацією. Уявіть собі, наприклад, звичайний калькулятор. Цілком імовірно, що на ньому ніколи не обчислювали суму двох нулів. Тоді завдання “обчислити нуль плюс нуль” можна вважати ситуацією, новою для калькулятора. Безумовно, він з нею впорається (“правильно відреагує на нову ситуацію”), але чи можна на цій підставі вважати його інтелектуальною системою?
2.1 Основні проблемні середовища штучного інтелекту
Виділимо декілька типів проблемних середовищ, що найбільш часто зустрічаються.
Тип 1 . Статичне проблемне середовище: статична предметна область; сутності представляються як сукупність атрибутів і їхніх значень; склад сутностей незмінний; БЗ не структуровані; вирішуються статичні задачі аналізу, використовуються тільки спеціалізовані що виконуються твердження.
Тип 2 . Статичне проблемне середовище: статична предметна область; сутності представляються у виді атрибутів із значеннями або вироджених об'єктами (фреймів); склад сутностей незмінний; ієрархія БЗ або відсутня, або слабко виражена (нема спадкування властивостей); вирішуються статичні задачі аналізу, використовуються спеціалізовані твердження, що виконуються.
Тип 3 . Статичне проблемне середовище: статична предметна область; сутності представляються у виді об'єктів; склад сутностей змінюваний; БЗ структуровані; вирішуються статичні задачі аналізу і синтезу, використовуються загальні і спеціалізовані що виконуються твердження.
Тип 4 . Динамічне проблемне середовище: динамічна предметна область; сутності представляються сукупністю атрибутів і їхніх значень; склад сутностей незмінний; БЗ не структуровані; вирішуються динамічні задачі аналізу, використовуються спеціалізовані твердження, що виконуються.
Тип 5 . Динамічне проблемне середовище: динамічна предметна область; сутності представляються у виді об'єктів; змінюваний склад сутностей; БЗ структуровані; вирішуються динамічні задачі аналізу і синтезу; використовуються загальні і спеціалізовані що виконуються твердження.
2.2 Проблема винятків
З успадкуванням пов’язана дуже серйозна проблема – проблема винятків . Вона полягає в тому, що деякі підкласи можуть не успадковувати ті чи інші властивості надкласів. Інакше кажучи, характерні риси класу успадковуються всіма його підкласами, крім деяких .
Нехай відомо, що літають всі птахи, крім пінгвінів (існують деякі інші види птахів, які не літають. Але для наших цілей це не має суттєвого значення). Якби це твердження відразу потрапило до бази знань саме в такому вигляді, особливих проблем не виникало б (хоча і в цьому випадку треба було б передбачити належну обробку винятків).
Але, як було зазначено раніше, експерт не завжди може сформулювати свої знання в явному вигляді. Зокрема, він може не знати або не пам”ятати всіх винятків. Тому він може спочатку включати до бази знань твердження про те, що всі птахи літають, а потім пригадати, що пінгвіни не літають, і додати це до бази знань.
У результаті ми могли б отримати базу знань, подібну до такої:

Рис. 1. Ілюстрація наслідування та обробки виключень
Усі птахи літають.
Ластівка є птахом.
Юкко є ластівкою.
Пінгвін є птахом.
Пінгвіни не літають.
Бакс є пінгвіном.
Якби три останні твердження не були включені до бази знань, система просто дійшла б хибного висновку, що Бакс літає. Але включення даних відомостей до бази знань ще більше ускладнює ситуацію. Система знань стає суперечливою: зодного боку, система повинна дійти висновку, що Бакс літає, а з іншого – що Бакс не літає. У даному випадку кажуть про втрату монотонності дедуктивної системи.
Система дедуктивного виведення називається монотонною, якщо виконується така властивість: якщо з набору тверджень (q1,…, qn) випливає твердження v , то v випливає і з набору тверджень (q1,…., qn, r).
Інакше кажучи, в монотонній теорії додавання нових фактів і правил не повинно впливати на істинність висновків, які могли бути отримані без них.
Додавання ж винятків до наявної бази знань може порушити монотонність. Існує багато підходів до вирішення цієї проблеми. Розробляються спеціальні немонотонні логіки : Рейтера, Мак-Дермотта та інші. Проте існують досить прості практичні прийоми. Наприклад, список виключень можна підтримувати явним чином. Інший корисний сформульований прийом : у разі виникнення суперечностей підклас успадковує відповідну властивість лише від найблищого попередника, тобто від класу, найближчого до нього в ієрархії класів.
Далі буде показано, як проблема винятків може вирішуватись в рамках продукційних систем і семантичних мереж.
У семантичних мережах можна також вводити зв’язки, що задають імплікацію, явно.
Слід відмітити, що формалізм семантичних мереж є зручним для задання знань і не дуже зручним для формалізації логічного виведення. Деякі конкретні методи логічного виведення на семантичних мережах описані в [Иск.интел, Вагин, Предст. зн]. Багато з них спираються на механізми дедуктивного виведення, характерні для логічних моделей та продукційних систем (в першу чергу - метод резолюцій). Ряд методик використовує співставлення зі зразком; таке співставлення є більш характерним для фреймових моделей. Але існують і методики, специфічні для семантичних мереж як графових моделей. В основі цих методик лежить інтерпретація логічного виведення та пошуку потрібної інформації в базі знань, яка задана семантичною мережею, як пошуку на графі . Зокрема, в [Предст.зн.] коротко описаний спосіб виведення, який називається перехресним пошуком . Відповідь на запитання формується на основі знаходження та аналізу шляхів між об’єктами, які фігурують у запитанні.
Наприклад, при аналізі мережі, зображеної на рис. 1, на запитання “Що спільного між Баксом та Юкко?” система може відповісти “Обидва вони птахи, але різних видів”.
2.3 Проблема неточних і неповних знань
Раніше ми розглядали проблеми, які необхідно було вирішувати при проектуванні та розробці баз знань. Серед інших проблем можна відмітити такі.Знання можуть бути неповними. Це означає, що для доведення або спростування певного твердження може не вистачати інформації. У багатьох системах логічного виведення прийнято постулат замкненості світу. Це означає, що на запит про істинність деякого твердження система відповідає „так” тоді і тільки тоді, коли його можна довести; якщо ж довести це твердження неможливо, система відповідає „ні”. Водночас „неможливо довести через нестачу інформації” і „доведено, що ні” - це зовсім не одне й те саме. З огляду на це бажано, щоб експертна система запитувала у користувача про факти, яких не вистачає.
Знання можуть бути недостовірними. Наприклад, на результат виконання продукції можуть впливати випадкові чинники (об”єктивна невизначенність) або ж експерт може бути не зовсім впевненим у деякому факті чи правилі виведення (суб”єктивна невизначенність).
Ненадійність знань і недостовірність наявних фактів обов”язково повинні враховуватися в процесі логічних побудов. Звичайно, можна було б просто відкидати факти та првила виведення, які викликають сумнів, але тоді довелося б відмовитися від цінної інформації. Тому необхідно розвивати процедури, які дозволяють здійснювати логічні побудови при недостовірних даних, і використовувати ці процедури в експертних системах. Необхідно враховувати модальність, а саме: необхідність або можливість того чи іншого факту, ставлення суб”єкта до деякого твердження і т.п. Крім того, в таких системах часто доводиться мати справу з неточно визначеними, нечіткими поняттями, такими, як „великий”, „маленький” тощо.
2.4 Деякі проблеми виведення
Нехай ми маємопродукційне правило А=>В (якщо А, то В), при цьому коефіціент упевненості цього правила дорівнює (y ). Зпогляду теорії ймовірностей цей коефіцент упевненості можна проінтерпретувати як Р(В\А) – умовну ймовірність В за умови А.
Нехай коефіціент упевненості твердження А дорівнює (а). Тут ми розглядаємо коефіціенти упевненості окремих тверджень як їх ймовірності.
Чому (в) дорівнює = Р(В) – коефіціент упевненості висновку В? Зразу ж необхідно сказати, що ми не можемо обчислити Р(В) точно – для цього не вистачає інформації. Натомість ми можемо обчислити інтервал, до якого потрапить ця ймовірність.
Очевидно, події А та А складають повну групу подій. Тоді відповідно до формули повної ймовірності маємо:
в=Р(В)=Р(А)Р(В\А)+Р(А)Р(В\А)=ау+(1-а)*Р(В\А).
У цій формулі фігурує невідоме значення Р(В\А), і саме тому точне обчислення (в) не є можливим. Але, оскільки 0=<P(B\A)=<1, маємо
ау=<Р(В) =<ау+(1-а),
в Є[ay, ay+(1-a)].
Отже, інтервал невизначенності для висновку В є тим меншим, чим юільшим є коефіціент упевненості умови А. Якщо а=1, (в) визначається точно.
Якщо ж а=0, інтервал невизначенності для (в) становить [0,1], а це еквівалентно повній відсутності будь-якої корисної інформації.
Ми бачимо, що навіть у найпростіших випадках пряме застосування теоретико-ймовірнісних співвідношень спричиняє проблеми. Ситуація ще більше ускладнюється, якщо невизначеність носить „суб”єктивний” характер. Тому необхідно мати наближені, але простіші методики обчислення коефіціентів упевненості, які у більшості випадків давали б прийнятний результат.
3 . 1 Деякі інтелектуальні задачі
Розглянемо і проаналізуємо в загальних рисах деякі проблеми, які доводиться постійно вирішувати людському розумові: розпізнавання образів, мислення та обчислювальні задачі.
На інтуїтивному рівні можна сформулювати декілька типових задач розпізнаванняобразів (або просто розпізнавання):
n задачаідентифікації [1] полягає в тому, що об’єкт, якийспостерігається людиною, потрібно вирізнити серед інших (наприклад, побачивши іншу людину, впізнати у ній свою дружину);
n проблема розпізнавання в класичній постановці: об’єкту, що спостерігається, до одного з заздалегідь відомих класів об’єктів (наприклад, відрізнити легковий автомобіль від вантажного).
Людина робить класифікацію просто. Наприклад, чоловік, повернувшись додому з роботи, відразу ж пізнає свою дружину, але більшість людей в повному обсязі не зможе пояснити, як він це робить. Як правило, раціонального пояснення немає. Теорія розпізнавання, яка інтенсивно розвивається, необхідна для того, щоб навчити розв’язувати задачі розпізнавання штучні інтелектуальні системи на основі досвіду розпізнавання людиною. Зокрема, сформульовано такий ключовий принцип [Хант)]: будь-який об`єкт у природі - унікальний; унікальні об`єкти - типізовані. У відповідності до цього принципу, розпізнавання здійснюється на основі аналізу певних характерних ознак. Вважається, що в природі не існує двох об’єктів, для яких співпадають абсолютно всі ознаки, і це теоретично дозволяє здійснювати ідентифікацію. Якщо ж для деяких об’єктів співпадають деякі ознаки, ці об’єкти теоретично можна об’єднувати в групи, або класи, за цими співпадаючими ознаками. Проблема полягає у тому, що різноманітних ознак існує незліченна кількість. Незважаючи на легкість, з якою людина проводить розпізнавання, вона дуже рідко в змозі виділити ознаки, суттєві для цього. До того ж, об’єкти, як правило, змінюються з часом. Ми далі спробуємо показати, що розпізнавання об’єктів і ситуацій має виняткове значення для орієнтації людини в навколішньому світі і для прийняття вірних рішень. Розпізнавання, як правило, здійснюється людиною на інтуїтивному, підсвідомому рівні, людина навчилася цьому за мільйони років еволюції.
Інша інтелектуальна задача – моделювання мислення;.Можна виділити два типи процесів мислення:
n підсвідоме інтуїтивне мислення, механізми якого на сучасному етапі вивчені недостатньо і яке дуже важко формалізувати та автоматизувати;
n дедуктивнілогічні побудови за формалізованими законами логіки. Дедукцією називається перехід від загального до часткового, виведення часткових наслідків з загальних правил.І тут пересічна людина рідко в змозі пояснити, за якими алгоритмами вона здійснює логічне виведення. Але методики таалгоритми, за якими можна автоматизувати виведення наслідків з фактів або логічну перевірку тих чи інших фактів, досить відомі.
Перш за все, це формальна логіка Аристотеля на основі конструкцій, які отримали назву силогізмів. Вони практично неподільно панували в логіці аж до початку XIX століття, тобто до появи булевої алгебри. Немає ніякої необхідності давати якісь формальні визначення силогізмів. Наведемо лише один класичний приклад.
Перше твердження. Усі люди смертні.
Друге твердження. Сократ - людина.
Висновок: Сократ смертний.
Якщо перше та друге твердження у силогізмі істинні та задовольняють певним загальним формальним вимогам, тоді і висновок буде істинним незалежно від змісту тверджень, що входять до силогізму. При порушенні цих формальних вимог легко припуститися логічних помилок, подібних до таких:
Всі студенти вузу А знають англійську мову
Петров знає англійську мову.
Отже, Петров - студент вузу А.
Або:
Іванов не готувався до іспиту і отримав двійку.
Сидоров не готується до іспиту.
Отже, і Сидоров отримає двійку.
Аристотелем було запропоновано декілька формальних конструкційсилогізмів, які він вважав достатньо універсальними. Лише у XIX столітті почала розвиватися сучасна математична логіка, яка розглядає силогізми Аристотеля як один із часткових випадків. Основою більшості сучасних систем, призначених для автоматизації логічних побудов, є метод резолюцій Робінсона. Він буде описаний пізніше. Але практична реалізація логічних зіткнулася з серйозними проблемами. Головна з них - це феномен,який Річард Беллман назвав прокляттям розмірності. На перший погляд, описати знання про зовнішній світ можна було б, наприклад, таким чином: “об’єкт А має рисиX, Y, Z. В відрізняється від А тим, що має рису Н, і т.д”.Але зовнішній світ є винятково складним переплетінням різноманітних об’єктів та зв’язків між ними.Для того, щоб тільки ввести всю цю інформацію до пам’яті інтелектуального пристрою, може знадобитися не одна тисяча років. Ще більше років буде потрібно, щоб врахувати всі необхідні факти при логічному виведенні. Реальні програми, що здійснюють логічне виведення (вони часто називаються експертними системами) мають досить обмежене застосування. Вони мають обмежений набір фактів та правил з певної, більш-менш чітко окресленої предметної галузі і можуть використовуватися лише у цій галузі. Що ж стосується людини, то якість її логічного мислення також часто буває далекою від бездоганної. Люди часто роблять логічні помилки, а інколи взагалі керуються принципами, невірними з точки зору нормальної логіки. Дуже часто свідоме логічне виведення на певному етапі обривається, і рішення знову-ж таки приймається на підсвідомому, інтуїтивному рівні. Зрозуміло, що таке рішення може бути помилковим. Але, якби в основі поведінки людини лежали спроби проводити дедуктивні побудови з логічного початку до логічного кінця, людина була б практично не здатною до будь-якої діяльності: фізичноїабо розумової – це вимагало б значного часу аналізу. Спільною рисою згаданих вище проблем була їх погана формалізованість, відсутність або незастосовністьчітких алгоритмів розв’язку. Вирішення подібних задач і є основним предметом розгляду в теорії штучного інтелекту. До зовсім іншого класу відносяться задачі, пов’язані з обчисленнями.В принципі, важко відповісти на запитання, як саме людина здійснює ті чи інші обчислення. Добре відомими є і низька швидкість, і невисока надійність цього виду людської діяльності. Але були запропоновані ефективні принципи комп’ютерних обчислень, які радикально відрізняються від тих, які застосовуються людиною.і добре формалізовані, алгоритмічні методики забезпечили рівень вирішення обчислювальних задач, абсолютно недосяжний для людського інтелекту. Водночас цей високий рівень алгоритмізації значною мірою зумовив слабкість традиційних комп’ютерних систем при розв’язанні тих інтелектуальних задач, з якими людина справляється непогано. З появою таких обчислювальних потужностей мрійники шістедесятих – сімдесятих років ХХ століття ставили задачу моделювання в повному обсязі роботу людського мозку. Теоретично, цю задачу з певними обмеженнями можна було б вирішити. Але складність потрібних обчислень виявилася такою, що змусила більшість дослідників відійти від поставленої задачі і перейти до більш простих задач; моделювання принципів роботи людського мозку при розв’язку конкретно визначених типів задач.
3 . 2 Тест Тьюринга і фатичний діалог
Відомий англійський учений Алан Tьюринг сформулював тезу, спрямовану на визначення моменту, з якого машину можна вважати інтелектуальною [ Поспелов]. Нехай експерт за допомогою телефону або подібного віддаленого пристрою спілкується з кимось (або чимось), що може бути як людиною, так і машиною. Експерт дає певні тести-завдання. За результатами відповідей він повинен визначити, з ким він має справу - з людиною чи з ЕОМ. Якщо він приймає комп'ютер за людину, комп'ютер може вважатися інтелектуальним. Така перевірка дістала назву тесту Тьюринга. Багато спеціалістів вважали, що тест Тьюринга є цілком задовільним для визначення рівня інтелектуальності комп’ютерної системи.Але виявилось, що це не зовсім так. В основі тесту Тьюринга лежить неявне припущення про те, що необхідною умовою ведення діалогу є розуміння співрозмовника. Але у кінці 60-х рр. американський кібернетик Дж. Вейценбаум створив дві програми - ЕЛІЗА і ДОКТОР для використання в психіатрії. Виявилось, що вони можуть невірно зорієнтувати експерта в умовах тесту Тьюринга. В основі побудови цих програм лежить ідея фатичного діалогу.
Визначення. Фатичним діалогом називається діалог без розуміння співрозмовника, на основі формального перефразування почутого.
Так, наприклад, на висловлення пацієнта "Ви не відверті зі мною" програма може відповісти "Чому Ви думаєте, що я не відверта з Вами?" У ряді випадків програма може видати заздалегідь заготовлену фразу. Так, на слова пацієнта "Мій батько мене не любив" вона може відповісти "Розкажіть мені про Вашу сім’ю".
Звичайно, це не має ніякого відношення ні до розуміння, ні до інтелекту, але багато людей, які проводили з цими програмами тест Тьюринга, вирішили, що мають справу з людиною.
3 . 3 Метод комп’ютерної реалізації фатичного діалогу
В основіпсевдоінтелектуальних програм, які можуть підтримувати фатичний діалог з людиною або з іншими аналогічними програмами, можуть лежати дуже прості алгоритми співставлення зі зразками. Тут описується класичний метод, що дозволяє писати подібні програми [Уїнстон].
Розглянемо “анатомію” програми ДОКТОР у дещо спрощеному вигляді. Діалог з цією програмою може бути, наприклад, таким:
ДОКТОР: Я Вас слухаю.
ЛЮДИНА: Мене бентежить погода.
ДОКТОР: Як давно Вас бентежить погода?
ЛЮДИНА: Відтоді, як померла моя мати.
ДОКТОР: Розкажіть про Вашу сім’ю.
ЛЮДИНА: Всі вони захоплюються комп’ютерами.
ДОКТОР: Машини Вас лякають.
ЛЮДИНА: Ні.
ДОКТОР: Будь ласка, не будьте так небагатослівні…
І так далі до нескінченності.
В основі методу, необхідного для реалізації такого діалогу,можележати механічне порівняння речень, які вводяться людиною,зі зразками(шаблонами) речень, що зберігаються програмою. Якщо речення співпало в повній мірі з одним із зразків, видається одна з відповідей, заздалегідь заготовлених для цього зразка.
Можна розглянути декілька варіантів порівнянь, кожний з них може бути легко запрограмований.
Варіант 1(повний збіг). Якщо речення, що вводиться, повністю збігається з одним із зразків, може бути відповідь: “Так, Ви маєте рацію”, або навпаки: “Ви помиляєтесь, тому що…”, і після “рацію” або “тому що” програміст може написати будь-який текст, що імітує глибоке розуміння специфіки предметної області. Наприклад, дуже непогано буде виглядати такий діалог:
Людина: Квадрат гіпотенузи дорівнює сумі квадратів катетів.
Програма: Так, але є подібний результат і для непрямокутних трикутників; це теорема косинусів.
Навряд чи після декількох подібних відповідей у когось залишаться сумніви в інтелектуальних здібностях програми. Але, звичайно, повні збіги бувають дуже рідко. Тому доводиться використовувати інші типи порівнянь.
Варіант 2(використання замінювачів). Типовим є використання замінювачів * і ?. З замінювачем * співставляється довільний фрагмент тексту, з замінювачем ? співставляється будь-яке окреме слово. Наприклад, шаблон (* комп’ютери*) успішно співставляється з будь-яким реченням, в якому згадується про комп’ютери; шаблон (Я люблю ? яблука) - з такими реченнями, як (Я люблю червоні яблука), (Я люблю солодкі яблука), тощо (але не з реченням (Я люблю їсти зелені яблука)).
Варіант 3(надання значень змінним в процесі співставлення). При цьому можливості програми, що реалізує фатичний діалог, значно розширюються. Вона набуває здібності до генерації відповідей, що залежать від запитань. Так, правило
(Я ? *) (Що ви ще <a> ?) дозволяє на речення Я люблю яблука відповісти Що Ви ще любите?, а на речення Я ненавиджу дощі - Що Ви ще ненавидите? У цьому прикладі при успішному співставленні зміннійaнадається значення слова, з яким співставився замінювач ?. Безумовно, при використанні українських фраз замість англійських потрібно ще стежити за узгодженням суфіксів
Варіант 4(універсальний зразок). Зі зразком (*) співставляється будь-яке речення. Звичайно, і відповіді, що відповідають цьому зразкові, повинні бути такими ж універсальними, наприклад:
(Я Вас не дуже розумію)
(Не будьте такими небагатослівними)
(Чому це має для Вас значення?)
3.4Групові залежності . Проблемні сфери .
Розглядаючи зв’язки між виділеними СГ, можна знайти, що деякі з цих зв’язків відносяться, по-перше, не лише до окремих елементів СГ, а до груп в цілому та, по-друге, можуть бути віднесені до класів “бути видом (родом) або “бути невід’ємною властивістю”. Такі зв’язки між парами СГ назвемо груповими залежностями (ГЗ) та будемо позначати так:
I = ГЗ (J ) (1.7)
де I , J – ідентифікатори груп. Вираз вигляду (1.7) означає, що група I “залежить” від групи J ; інакше кажучи, всі елементи I пов’язані з елементами J відношенням “бути видом (родом)” або “бути невід’ємною властивістю”.
Формально ГЗ можуть бути встановлені шляхом аналізу графа зв’язків між СГ. “Залежні” групи (позначені індексом І у виразі (1.7)) відповідають термінальним вершинам цього графу.
Розглянемо тепер зв’язки між елементами семантичних груп. Елементи, що належать до однієї семантичної групи (точніше, поняттям, що їм відповідають), на мають безпосередніх зв’язків. Вони можуть пов’язуватися лише через елементи інших СГ.
Зв’язки одного вигляду між елементами двох різних СГ задаються таблицею, яка називається проблемною сферою (ПС). Кожен такий зв’язок може бути описано виразом
ЗВ’ЯЗОК ::= <I > <N > <p > <J > <M > (1.7)
де I , J – ідентифікатори СГ; N , M – числа, номера елементів СГ; р – ідентифікатор виду зв’язку. Якщо вид зв’язку однозначно визначається пов’язаними елементами, то ідентифікатор р можна опустити:
ЗВ’ЯЗОК ::= <I > <N > – <J > <M > (1.7a)
Ідентифікатор проблемної сфери описується виразом
<ІДЕНТИФІКАТОР ПС> ::= <I > <p > <J > (1.8)
<ІДЕНТИФІКАТОР ПС> ::= <I > – <J > (1.8а)
Одна з ПС, так звана ПС-АЛЬФА, представляє структуру бази знань. Вона містить інформацію про зв’язки між семантичними групами та проблемними сферами. Така ПС пов’язує дві особі СГ: ГРУПИ та СФЕРИ.
3.5 Принцип віртуальної семантичної сітки.
Швидкість бази знань при виведенні відповіді на питання суттєво залежить від розміщення знань у пам’яті ЕОМ. Найбільшого прискорення можна досягти, якщо помістити всі знання в оперативну пам’ять. Але для промислових ІІС це не є можливим через великий обсяг знань. Структурування знань ІІС дозволяє розміщувати структурні елементи сітки на зовнішніх носіях та викликати в оперативну пам’ять лише ті елементи сітки, які необхідні для виведення відповіді на задане питання. Структурними елементами сітки є так звані проблемні сфери (ПС). З вибраних в оперативну пам’ять ПС повинна бути зібрана локальна семантична сітка, релевантна до даного питання. Цю сітку будемо називати проблемною семантичною сіткою (ПСС). Даний метод представлення структурованої семантичної сітки можна назвати методом віртуальної семантичної сітки . Користувачу, що задає питання базі знань, здається, що виведення відповіді базується на повній семантичній сітці, тоді як насправді у виведенні відповіді бере участь лише невелика частина структурних елементів семантичної сітки бази знань. Для реалізації цього методу необхідні:
a) Розробка алгоритму перетворення вхідного питання в релевантну проблемну семантичну сітку;
b) Розробка алгоритму виведення відповіді на основі зібраної ПСС;
c) Визначення структури системи керування базою знань (СКБЗ), в якій повинні виконуватися наведення вище алгоритми.
d) Мовні рівні перетворення запитів у базі знань. Структура системи керування базою знань.
4.1 Продукційні правила
У системах, побудованих на основі правил , поведінка визначається множиною правил виду: умова -> дія. Умова задає образ даних, при виникненні якого дія правила може бути виконана. Формування поведінки здійснюється по такій схемі. Умови правил співставляються з поточними даними, і ті правила, умови яких задовольняються значеннями поточних даних, стають претендентами на виконання. Потім по визначеному критерії здійснюються вибір одного правила серед претендентів і його виконання (тобто виконання дії, зазначеної в правій частині правила). Підкреслимо, що правила - претенденти можуть виконуватися одночасно при наявності декількох процесів.
4.2 Компонент виведення
Його дії засновані на застосуванні правила виведення, яке звичайно називається модус поненс, і якого полягає в наступному: нехай відомо, що істинне твердження А та існує правило виду «Якщо А, то В», тоді твердження В так само істинне. Правила спрацьовують, коли знаходяться факти, що задовольняють їхній лівій частині.
Хоча в принципі на перший погляд здається, що таке виведення легко може бути реалізоване на комп'ютері, проте на практиці людський мозок усе рівно виявляється більш ефективним при рішенні задач.
Компонент виведення повинний мати здатність функціонувати при будь-яких умовах. Механізм виведення повинний бути здатний продовжити міркування і згодом знайти рішення навіть при недостатній інформації. Це рішення може і не бути точним, однак система ні в якому разі не повинна зупинятися через те, що відсутня яка-небудь частина вхідної інформації.
4.3 Нечітке виведення
В експертних системах, що базуються на логіці , база знань складається з тверджень у виді пропозицій логіки предикатів.
Так само як і в системі на правилах експертна система, що базується на логіці, має множину правил, що можуть викликатися за допомогою даних із вхідного потоку. Система має також інтерпретатор, що може вибирати й активізувати модулі, що включаються в роботу системи.
Також і в системі, що базується на правилах, даний циклічний процес є процесом розпізнавання-дія. Переваги системи, заснованої на логіці, полягають у тому, що вона відбиває структуру самого Турбо-Пролога. Під цим розуміється, що вона дуже ефективна в роботі. Найбільш важливим аспектом для бази знань у системі, заснованої на логіці, є проектування бази знань, її тверджень і її структури. База знань повинна мати недвозначну логічну організацію, і вона повинна містити мінімум надлишкової інформації. Так само як і в системі, що базується на правилах, мінімально достатня кількість даних утворять найбільш ефективну систему.
Нечітка підмножина відрізняється від звичайної тім, що для елементів x з E немає однозначної відповіді "ні" відносно властивості R. У зв'язку з цим, нечітка підмножина A універсальної множини E визначається як множина впорядкованої пари A = {A(х)/х}, де A(х) - характеристична функція приналежності (або просто функція приналежності), що приймає значення в деякій впорядкованій множині M (наприклад, M = [0,1]).
Функція приналежності вказує ступінь (або рівень) приналежності елемента x до підмножини A. Множина M називають множиною приналежностей. Якщо M = {0,1}, тоді нечітка підмножина A може розглядатися як звичайна або чітка множина.
Розглянемо множину X всіх чисел від 0 до 10. Визначимо підмножину A множини X всіх дійсних чисел від 5 до 8.
A = [5,8]
Покажемо функцію приналежності множини A, ця функція ставить у відповідність число 1 чи 0 кожному елементу в X, у залежності від того, належить даний елемент підмножині A чи ні. Результат представлений на наступному малюнку:

Рис.2. Графічне зображення функції приналежності.
Можна інтерпретувати елементи, яким поставлена у відповідність 1, як елементи, що знаходяться в множині A, а елементи, яким поставлений у відповідність 0, як елементи, що не знаходяться в множині A.
Ця концепція використовується в багатьох областях застосувань. Але можна легко знайти ситуації, в яких даній концепції буде бракувати гнучкості.
5. Фрейми
В основі теорії фреймів лежить сприйняття стереотипних ситуацій, що мають, наприклад, місце в процесі функціонування складних об'єктів, зокрема, виробничих. Для подання й опису стереотипних об'єктів, подій або ситуацій було введено поняття "фрейми", що є складними структурами даних. У загальному вигляді фрейм можна розглядати як сітку, що складається з кількох вершин і відношень. На верхньому рівні фрейму подана фіксована інформація:факт стосовно стану об'єкта, який звичайно вважається істинним, На наступних рівнях розташовано множину так званих термінальних слотів (терміналів), які обов'язково повинні бути заповнені конкретними значеннями та даними. У кожному слоті задається умова, яка повинна виконуватися при встановленні відповідності між значеннями (слот або сам встановлює відповідність, або це робить дрібніша складова фрейму). Проста умова позначається позначкою і може, наприклад, містити вимога, щоб відповідність встановлював користувач, щоб досить повним був опис значень тощо. Складні умови вказують відношення між фактами, що відповідають декільком терміналам.
Поєднавши множину фреймів, що є відношеннями, можна побудувати фреймову систему, найважливішою перевагою якої є можливість перетворення фреймів в одній системі.
6.1 Семантичні мережі
Звичайні семантичні мережі складаються з вершин, що відповідають об’єктам чи поняттям, а також дуг, що відповідають відношенням, та зв’язують ці вершини. У таких мережах вершини можуть відповідати не тільки об’єктам чи поняттям, але і відношенням, логічним складовим частинам інформації (фактам істинності та хиби), комплексним об’єктам тощо. Усьому, що може розглядатися, як самостійна одиниця, повинна бути співставлена власна вершина. Наприклад, вершини можуть бути співставлені завершеним подіям або ситуаціям. Вершини поділяються на два класи: визначені (в -вершини) та невизначені (н -вершини). Перші відповідають впізнаним об’єктам, виявленим відношенням розпізнаним подіям, ситуаціям. Другі – невпізнаним, невиявленим.
Окрім зазначених, вводяться вершини з’вязку. Вони поєднуються поміченими ребрами (ребрами різних типів) з вершинами, взятими з множини вищезазначених вершин. Фактично, ребра помічаються цифрами, що визначають семантичний відмінок відношення. В результаті утворюється фрагмент, що відповідає елементарній ситуації, тобто об’єктам, що пов’язані відношенням. Такий фрагмент називають елементарним. Елементарний фрагмент можна представити у вигляді павука з поміченими лапками. При цьому тіло такого павука є вершина зв’язку, а лапки – ребра, якими він ціпляється за інші вершини. Номер, або тип лапки, визначає роль, яку грають схоплені ним вершини, у представленій ситуації, тобто або це вершина-об’єкт, вершина-відношення, вершина, що відповідає факту істинності – хиби, або вершина, що відповідає всій елементарній ситуації. Спеціальний поділ перерахованих вершин на множини, що не перетинаються, не виконується. Кожна з них може грати будь-яку роль. Таким чином, ситуація або логічні складові, можуть бути пов’язані своїми відношеннями, відношення також можуть бути об’єктами іншого відношення і.т.д. В результаті забезпечуються широкі можливості представлення.
Обробка системних знань базується на принципі накладення мереж, послідовному співставленні їх фрагментів. Процедура такого співставлення визначається графами, тобто операціями, що вони задають. В результаті знаходяться невизначені компоненти інформації. На відміну від звичайного співставлення таблиць або зразків (фреймів) при накладенні мереж використовується більш складний підхід – окільний . Для пошуку невизначених компонент використовують їх околи. При цьому доводиться постійно шукати співставлювані компоненти, обирати напрям пошуку. Все це робить процедуру накладання достатньо складною, проте і більш універсальною.
Зазначені принципи було покладено у основу механізмів, що забезпечують обробку інформації, реалізацію різних видів діяльності. Обробка у багатьох випадках зводиться до формування графів та виконання операцій, що задаються графами. Таким чином забезпечується вирішення двох основних задач – конкретизації та перетворення. Перша задача полягає у знаходженні невизначених складових вхідної інформації, у виконанні різноманітних перевірок, а друга задача – у перетворенні інформації. Перетворення керується за допомогою спеціальних засобів, що називаються мережними продукціями . Такі засоби можна вважати певним різновидом графів, які задають спеціальні операції пошуку мереж визначених конструкцій, їх вилучення та заміни на інші мережі. За допомогою таких продукцій представляються різні визначення, а також деякі види умовних речень.
Слід зазначити, що далеко не кожна мережа, складена з фрагментів, буде представляти правильну чи допустиму інформацію. Фрагменти можуть представляти відношення, що ніяк не узгоджуються одне з одним, наприклад відношення бути братом (R1 ) та мати квадратну форму (R2 ). Тоді мережа
<x3 , t, r1 , a1 , x1 > ° <x4 , t, r2 , x1 >
буде репрезентувати Дехто Х1 , який є братом А1 , має квадратну форму . Щоб уникнути подібних неузгодженостей, згідно схеми обробки в процесі вводу інформації виконується перевірка на її допустимість. Для цього використовуються так звані обов’язкові знання, роль яких відіграють семантичні графи.
6.2Різні способи задання семантичних мереж: переваги і недоліки
Ми уже зазначали, що одні й ті самі твердження можна зображати різними семантичними мережами і концептуальними графами. Повернемося до речення “Студент Іванов отримав 5 на іспиті з штучного інтелекту” .
Цьому концептуальному графі відповідає такий набір бінарних фактів у формі “об’єкт – атрибут – значення”:
Іванов – Є – Студент
Іванов – Здав – Шт. Інтелект
Іванов – Оцінка – 5
Шт. Інтелект – Є – Іспит

Рис.3. Концептуальний граф: перший варіант
Основна перевага цього рішення – його “природність”. “Об’єкт” “Іванов” відповідає реальній сутності – студентові Іванову.
Але таке рішення має очевидні вади. Це, зокрема, слабка інтерпретованість дуг “Здає” та “Оцінка”, ігнорування того факту, що “Шт. Інтелект” – це не тільки “Іспит”, але й наукова дисципліна і т.п. Але найважливіший недолік – це складність задання зв’язків “один до багатьох” і “багато до багатьох”.
Уявіть собі, що в базі знань зберігається ще один факт про цього ж студента, а саме “Студент Іванов отримав 2 на іспиті з Ліспу ”. Цей факт може бути описаний аналогічним концептуальним графом, але як об’єднати ці два графи в семантичну мережу? “Очевидний” розв’язок є незадовільним через свою неоднозначність: незрозуміло, яку оцінку з якого предмету отримав Іванов.

Рис.4. Незадовільне задання зв ’ язків “один до багатьох”
Можна запропонувати різні виходи з такого становища. Наприклад, можливе таке рішення:
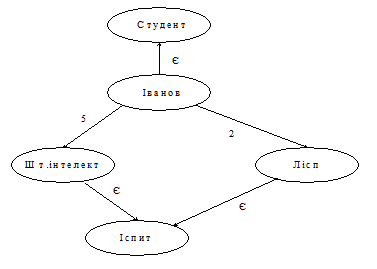
Рис.5. Семантична мережа з неінтерпретованими дугами
Недолік такого рішення – повна неінтерпретованість міток “5” і “2”; вирішити цю проблему можна лише шляхом додавання до відповідних дуг допоміжних зв’язків.
Можна запропонувати розв’язки на основі структурованих семантичних мереж, для яких характерна певна внутрішня структура. Цю структуру можна ввести, наприклад, таким чином:
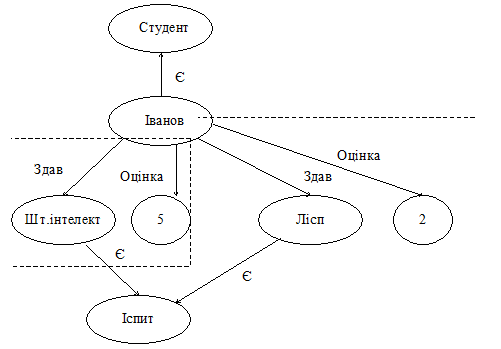
Рис.6. Приклад структурованої семантичної мережі
Рамками обведені фрагменти семантичної мережі, дуги яких об’єднані заданим відношенням (у даному випадку відношенням кон’юнкції). Але навряд чи подібна структуризація, яка неминуче ускладнює програмування, є необхідною для таких простих мереж.
Нарешті, можна застосувати такий типовий прийом.
Вводяться додаткові предикати, які відображають відношення “Студент Х здав іспит У ” . Тоді твердження “Студент Іванов отримав 5 на іспиті з штучного інтелекту ” та “Студент Іванов отримав 2 на іспиті з Ліспу ” можуть бути подані як кон’юнкції таких бінарних фактів:
Іванов – Є – Студент Ісп_1 – Є – Іспит Ісп_1 – Хто_Здав_ - Іванов Ісп_1 – Предмет - Шт.Інт Ісп_1 – Оцінка - 5 |
Іванов – Є – Студент Ісп_2 – Є – Іспит Ісп_2 – Хто_Здав - Іванов Ісп_2 – Предмет – Лісп Ісп_2 – Оцінка - 2 |
Зверніть особливу увагу на номери в предикатних іменах: кожному фактові здачі іспиту відповідає свій номер, для іншого студента або для іншого предмету предикатне ім’я буде іншим (інакше при описі відношення “багато до багатьох” знову виникне неоднозначність.
7. Нейронні мережі
Нейронні мережі , або штучні нейронні мережі, являють собою розвиток моделей, які виникли в результаті спроб імітування механізму мислення людини. Для визначення класів задач штучного інтелекту (насамперед, розпізнавання, інтелектуального управління динамікою складних механічних систем тощо) нейромережні моделі часто забезпечують ефективніше рішення, ніж традиційні символьні підходи.
У самих загальних рисах результатом функціонування нейронної мережі є сигнал, що ідентифікує належність вхідного зображення до одного з кількох класів (тобто мережа здійснює категоризацію зображень).
Елементарна складова мережі - нейрон - має кілька входів і один вихід. Елементи вхідного вектора множаться на вагові коефіцієнти W1 .W2 ,...,Wn ;зважені значення сумуються і надходять до входу порогового елемента, двійковий вихід якого є виходом нейрона. У загальному випадку для відтворення нелінійності можуть використовуватися не тільки "ступеневі", а й "похилі" функції.
Однією, з найважливіших особливостей нейромереж є їх спроможність до навчання. В процесі навчання нейрона відбувається піднастроювання вагових коефіцієнтів таким чином, щоб він правильно класифікував максимальну кількість вхідних зображень. При поданні чергового навчаючого зображення оцінюється різниця (похибка) між потрібним вхідним значенням сумуючого елемента і його фактичним значенням. Звичайно для піднастроювання ваги використовується алгоритм, який мінімізує суму квадратів відхилень за період навчаючої послідовності.
Окрім того, не можна гарантувати, що розроблена мережа є оптимальною мережею. Застосування нейромереж вимагає від розробника виконання ряду умов.
Ці умови включають:
· множину даних, що включає інформацію, яка може характеризувати проблему;
· відповідно встановлену за розміром множину даних для навчання і тестування мережі;
· розуміння базової природи проблеми, яка буде вирішена;
· вибір функції суматора, передатної функції та методів навчання;
· розуміння інструментальних засобів розробника;
· відповідна потужність обробки.
Новий шлях обчислень вимагає вмінь розробника поза межами традиційних обчислень. Спочатку, обчислення були лише апаратними і інженери робили його працюючим. Потім, були спеціалісти з програмного забезпечення: програмісти, системні інженери, спеціалісти по базах даних та проектувальники. Тепер є нейронні архітектори. Новий професіонал повинен мати кваліфікацію відмінну від його попередників. Наприклад, він повинен знати статистику для вибору і оцінювання навчальних і тестових множин. Логічне мислення сучасних інженерів програмного забезпечення, їх емпіричне вміння та інтуїтивне відчуття гарантує створення ефективних нейромереж.
Сучасні дослідження фізіології мозку відкривають лише обмежене розуміння роботи нейронів і процесу мислення. Дослідники працюють як в біологічній, так і в інженерній галузях для розшифрування ключових механізмів нейронної обробки, що допомагає створювати потужніші і більш стислі нейромережі.
Для складних проблем класифікації з подібними вхідними прикладами, мережа вимагає великої карти Кохонена з багатьма нейронами на клас. Це вибірково може бути подолано вибором доцільних навчальних прикладів або розширенням вхідного прошарку.
Мережа квантування навчального вектора страждає від дефекту, що деякі нейрони мають тенденцію до перемоги занадто часто, тобто налаштовують свої ваги дуже швидко, а інші постійно залишаються незадіяними. Це часто трапляється, коли їх ваги мають значення далекі від навчальних прикладів. Щоб пом'якшити цю проблему, нейрон, який перемагає занадто часто штрафується, тобто зменшуються ваги його зв'язків з кожним вхідним нейроном. Це зменшення ваг є пропорційним до різниці між частотою перемог нейрону та частотою перемог середнього нейрону.
8. Генетичні алгоритми
Задачі оптимізації - найбільш розповсюджений і важливий для практики клас задач. Їх приходиться вирішувати кожному з нас або в побуті, розподіляючи свій час між різними справами, або на роботі, домагаючись максимальної швидкості роботи програми чи максимальної прибутковості компанії - у залежності від посади. Серед цих задач є розв'язувані простим шляхом, але є і такі, точне рішення яких знайти практично неможливо.
Як правило, у задачі оптимізації ми можемо керувати декількома параметрами (позначимо їх значення через x1, x2, ..., xn, а нашою метою є максимізація (чи мінімізація) деякої функції, f(x1, x2, ..., xn), що залежить від цих параметрів. Функція f називається цільовою функцією. Наприклад, якщо потрібно максимізувати цільову функцію "дохід компанії", тоді керованими параметрами будуть число співробітників компанії, обсяг виробництва, витрати на рекламу, ціни на кінцеві продукти і т.д. Важливо відзначити, що ці параметри зв'язані між собою - зокрема, при зменшенні числа співробітників швидше за все впаде й обсяг виробництва.
Генетичний алгоритм - новітній, але не єдино можливий спосіб рішення задач оптимізації.
Відомо два основні шляхи рішення таких задач - переборний та градієнтний. Розглянемо класичну задачу комівояжера. Суть задачі полягає у знаходженні короткого шляху проходження всіх міст.
Переборний метод є найпростішим. Для пошуку оптимального рішення (максимум цільової функції) потрібно послідовно обчислити значення функції у всіх точках. Недоліком є велика кількість обчислень.
Іншим способом є градієнтний спуск. Обираємо випадкові значення параметрів, а потім значення поступово змінюють, досягаючи найбільшої швидкості зросту цільової функції. Алгоритм може зупинитись, досягнувши локального максимуму. Градієнтні методи швидкі, але не гарантують оптимального рішення (оскільки цільова функція має декілька максимумів).
Генетичний алгоритм являє собою комбінацію переборного та градієнтного методів. Механізми кросоверу (схрещування) та мутації реалізують переборну частину, а відбір кращих рішень - градієнтний спуск.
Тобто, якщо на деякій множині задана складна функція від декількох змінних, тоді генетичний алгоритм є програмою, яка за зрозумілий час знаходить точку, де значення функції знаходиться достатньо близько до максимально можливого значення. Обираючи прийнятний час розрахунку, отримуємо одне з кращих рішень, які можна отримати за цей час.
Висновок
У цій курсовій роботі ми розглянули основні проблемні середовища штучного інтелекту. Розрізняють статичне та динамічне проблемне середовище. Для статичних проблемних середовищ характерним є вирішення статичних задач аналізу і синтезу; використання загальних і спеціалізованих тверджень, що виконуються; статична предметна область;сутності представляються у виді об'єктів;склад сутностей змінюваний; БЗ структуровані, а для динамічних - вирішення динамічних задач аналізу і синтезу; динамічна предметна область; сутності представляються сукупністю атрибутів і їхніх значень; склад сутностей незмінний; БЗ не структуровані.
Важливими проблемами для вирішення є проблеми неточних і неповних знань; проблеми виведення; та винятків.
Ненадійність знань і недостовірність наявних фактів обов”язково повинні враховуватися в процесі логічних побудов. Звичайно, можна було б просто відкидати факти та првила виведення, які викликають сумнів, але тоді довелося б відмовитися від цінної інформації. Тому необхідно розвивати процедури, які дозволяють здійснювати логічні побудови при недостовірних даних, і використовувати ці процедури в експертних системах. Необхідно враховувати модальність, а саме: необхідність або можливість того чи іншого факту, ставлення суб”єкта до деякого твердження і т.п.
З успадкуванням пов’язана дуже серйозна проблема – проблема винятків. Вона полягає в тому, що деякі підкласи можуть не успадковувати ті чи інші властивості надкласів. Інакше кажучи, характерні риси класу успадковуються всіма його підкласами, крім деяких.
Відомі складності сучасного програмування, пов’язані з необхідністю надмірної алгоритмізації, тобто детального ретельного розписування інструкцій з урахуванням усіх можливих ситуацій.
Використана література :
1). Глибовець М.М., Олецький О. В., „Штучний інтелект”, К. 2002;
2). Герман О.В. Введення в теорію експертних систем і опрацювання знань. – Мінськ: ДизайнПРО, 1995.
3). В.Брауэр. Введення в теорію кінцевих автоматів.-М.: "Радіо і зв'язок", 1987.
4). Б олотова Л.С., Смольянинов А.А. Неформальные модели представления знаний в системах искусственного интеллекта / Московский институт радиотехники, электроники и автоматики (ТУ) – М., 1999.
5). Клыков Ю.И., Горьков Л.Н. Банки данных для принятия решений. - М., 1980.
6). Представление и использование знания / под ред. Х.Уэно, М.Исидзука. - М., 1989.
7). Джексон П. Введение в экспертные системы. – М.-С-П.-К.: Изд. дом “Вильямс “, 2001.