| Скачать .docx |
Реферат: Курс лекций Операционным системам и среды
Тема 1. Вычислительная система. Состав вычислительной системы
Одной из основных задач технических дисциплин является подбор средств и методов механизации и автоматизации работ. Автоматизация работ с данными имеет свои особенности и для ее реализации используются особые устройства.
Совокупность устройств, предназначенных для автоматической или автоматизированной обработки данных, называется вычислительной техникой .
Конкретный набор взаимодействующих между собой устройств и программ, который предназначен для обслуживания одного рабочего участка, называется вычислительной системой . Центральным устройством большинства вычислительных систем является компьютер . Он предназначен для автоматизации создания, хранения, обработки и передачи данных.
Состав вычислительной системы называется конфигурацией .
Отдельно рассматривают аппаратную конфигурацию вычислительных систем и их программную конфигурацию . Критериями выбора аппаратного или программного решения являются производительность и эффективность.
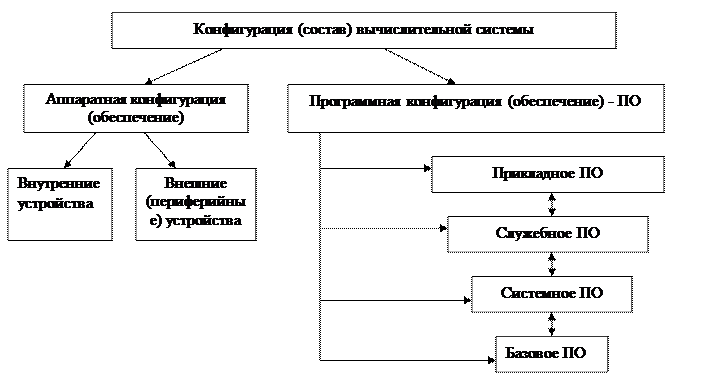
Рис. 1. Состав вычислительной системы
Аппаратное обеспечение
К аппаратному обеспечению вычислительных систем относятся устройства и приборы, образующие аппаратную конфигурацию. Современные компьютеры и вычислительные комплексы имеют блочно-модульную конструкцию — аппаратную конфигурацию, необходимую для исполнения конкретных видов работ, можно собирать из готовых узлов и блоков.
По способу расположения устройств относительно центрального процессора различают внутренние и внешние устройства. Внешними, как правило, являются большинство устройств ввода-вывода данных (их также называют периферийными устройствами) и некоторые устройства, предназначенные для длительного хранения данных.
Согласование между отдельными узлами и блоками выполняют с помощью переходных аппаратно-логических устройств, называемых аппаратными интерфейсами. Стандарты на аппаратные интерфейсы называют протоколами. Таким образом, протокол — это совокупность технических условий, которые должны быть обеспечены разработчиками устройств для успешного согласования их работы с другими устройствами.
Многочисленные интерфейсы, присутствующие в архитектуре любой вычислительной системы, можно условно разделить на две большие группы: последовательные и параллельные .
1. Через последовательный интерфейс данные передаются последовательно, бит за битом, их производительность измеряют битами в секунду (бит/с, Кбит/с, Мбит/с).
2. Через параллельный интерфейс данные передаются одновременно группами битов. Количество битов, участвующих в одной посылке, определяется разрядностью интерфейса, например, восьмиразрядные параллельные интерфейсы передают один байт (8 бит) за один цикл. Параллельные интерфейсы обычно имеют более сложное устройство, чем последовательные, но обеспечивают более высокую производительность. Их применяют там, где важна скорость передачи данных: для подключения печатающих устройств, устройств ввода графической информации, устройств записи данных на внешний носитель и т. п. Производительность параллельных интерфейсов измеряют байтами в секунду (байт/с; Кбайт/с; Мбайт/с).
Первоначально последовательные интерфейсы применяли для подключения «медленных» устройств (простейших устройств печати низкого качества, устройств ввода и вывода знаковой и сигнальной информации, контрольных датчиков, малопроизводительных устройств связи и т. п.), а также в тех случаях, когда отсутствуют существенные ограничения по продолжительности обмена данными.
Однако с развитием техники появились новые, высокоскоростные последовательные интерфейсы, не уступающие параллельным, а нередко и превосходящие их по пропускной способности. Сегодня последовательные интерфейсы применяют для подключения к компьютеру любых типов устройств.
Программное обеспечение
Программы — это упорядоченные последовательности команд. Конечная цель любой компьютерной программы — управление аппаратными средствами.
Состав программного обеспечения вычислительной системы называют программной конфигурацией . Между программами, как и между физическими узлами и блоками существует взаимосвязь — многие программы работают, опираясь на другие программы более низкого уровня, то есть мы можем говорить о межпрограммном интерфейсе . Возможность существования такого интерфейса тоже основана на существовании технических условий и протоколов взаимодействия, а на практике он обеспечивается распределением программного обеспечения на несколько взаимодействующих между собой уровней.
Уровни программного обеспечения представляют собой пирамидальную конструкцию. Каждый следующий уровень опирается на программное обеспечение предшествующих уровней. Каждый вышележащий уровень повышает функциональность всей системы. Так, например, вычислительная система с программным обеспечением базового уровня не способна выполнять большинство функций, но позволяет установить системное программное обеспечение.
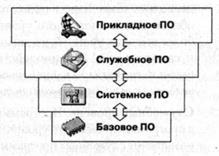 |
Рис. 2. Структура программного обеспечения
1. Базовый уровень. Самый низкий уровень программного обеспечения представляет базовое программное обеспечение. Оно отвечает за взаимодействие с базовыми аппаратными средствами. Как правило, базовые программные средства непосредственно входят в состав базового оборудования и хранятся в специальных микросхемах, называемых постоянными запоминающими устройствами (ПЗУ — ReadOnlyMemory, ROM). Программы и данные записываются («прошиваются») в микросхемы ПЗУ на этапе производства и не могут быть изменены в процессе эксплуатации.
2. Системный уровень. Системный уровень — переходный. Программы, работающие на этом уровне, обеспечивают взаимодействие прочих программ компьютерной системы с программами базового уровня и непосредственно с аппаратным обеспечением, то есть выполняют «посреднические» функции.
– средства обеспечения пользовательского интерфейса – благодаря им компьютер получает возможность вводить данные в вычислительную систему, управлять ее работой и получать результат в удобной для себя форме.
– драйверы – расширяют возможности ОС, позволяя ей работать с тем или иным подключенным устройством, обучая ее новому протоколу обмена данными и т. д.
Совокупность программного обеспечения системного уровня образует ядро операционной системы компьютера. Полное понятие операционной системы мы рассмотрим несколько позже, а здесь только отметим, что если компьютер оснащен программным обеспечением системного уровня, то он уже подготовлен к установке программ более высоких уровней, к взаимодействию программных средств с оборудованием и, самое главное, к взаимодействию с пользователем. То есть наличие ядра операционной системы — непременное условие для возможности практической работы человека с вычислительной системой.
3. Служебный уровень. Программное обеспечение этого уровня взаимодействует как с программами базового уровня, так и с программами системного уровня. Основное назначение служебных программ (их также называют утилитами) состоит в автоматизации работ по проверке, наладке и настройке компьютерной системы. Во многих случаях они используются для расширения или улучшения функций системных программ. Некоторые служебные программы (как правило, это программы обслуживания) изначально включают в состав операционной системы, но большинство служебных программ являются для операционной системы внешними и служат для расширения ее функций.
В разработке и эксплуатации служебных программ существует два альтернативных направления:
а) интеграция с операционной системой - служебные программы могут изменять потребительские свойства системных программ, делая их более удобными для практической работы.
б) автономное функционирование – служебные программыслабо связаны с системным программным обеспечением, но предоставляют пользователю больше возможностей для персональной настройки их взаимодействия с аппаратным и программным обеспечением.
4. Прикладной уровень. Программное обеспечение прикладного уровня представляет собой комплекс прикладных программ, с помощью которых на данном рабочем месте выполняются конкретные задания.
Примеры прикладных программных средств
1. Текстовые редакторы.
Функции:
- ввод и редактировании текстовых данных;
- автоматизация процессов ввода и редактирования.
Для операций ввода, вывода и сохранения данных текстовые редакторы вызывают и используют системное программное обеспечение (это характерно и для всех прочих видов прикладных программ)
2. Текстовые процессоры. Основное отличие текстовых процессоров от текстовых редакторов в том, что они позволяют не только вводить и редактировать текст, но и форматировать его, то есть оформлять. Соответственно, к основным средствам текстовых процессоров относятся средства обеспечения взаимодействия текста, графики, таблиц и других объектов, составляющих итоговый документ, а к дополнительным — средства автоматизации процесса форматирования.
Современный стиль работы с документами подразумевает два альтернативных подхода — работу с бумажными документами и работу с электронными документами (по безбумажной технологии). Поэтому текстовые процессоры позволяют выполнять 2 виды форматирования — форматирование документов, предназначенных для печати , и форматирование электронных документов, предназначенных для отображения на экране . Приемы и методы в этих случаях существенно различаются. Соответственно, различаются и текстовые процессоры, хотя многие из них успешно сочетают оба подхода.
3. Графические редакторы. Это обширный класс программ, предназначенных для создания и (или) обработки графических изображений.
Категории: растровые редакторы, векторные редакторы и программные средства для создания и обработки трехмерной графики (3D-редакторы).
а) Растровые редакторы применяют в тех случаях, когда графический объект представлен в виде комбинации точек, образующих растр и обладающих свойствами яркости и цвета. Такой подход эффективен в тех случаях, когда графическое изображение имеет много полутонов и информация о цвете элементов, составляющих объект, важнее, чем информация об их форме. Это характерно для фотографических и полиграфических изображений. Растровые редакторы широко применяются для обработки изображений, их ретуши, создания фотоэффектов и художественных композиций (коллажей).
Возможности создания новых изображений средствами растровых редакторов ограниченны и не всегда удобны. В большинстве случаев художники предпочитают пользоваться традиционными инструментами, после чего вводить рисунок в компьютер с помощью специальных аппаратных средств (сканеров) и завершать работу с помощью растрового редактора путем применения спецэффектов.
б) Векторные редакторы отличаются от растровых способом представления данных об изображении. Элементарным объектом векторного изображения является не точка, а линия. Такой подход характерен для чертежно-графических работ, в которых форма линий имеет большее значение, чем информация о цвете отдельных точек, составляющих ее. В векторных редакторах каждая линия рассматривается как математическая кривая и, соответственно, представляется не комбинацией точек, а математической формулой (в компьютере хранятся числовые коэффициенты этой формулы). Такое представление намного компактнее, чем растровое, соответственно данные занимают много меньше места, однако построение любого объекта выполняется не простым отображением точек на экране, а сопровождается непрерывным пересчетом параметров кривой в координаты экранного или печатного изображения. Соответственно, работа с векторной графикой требует более производительных вычислительных систем.
Из элементарных объектов (линий) создаются простейшие геометрические объекты (примитивы) из которых, в свою очередь, составляются законченные композиции. Художественная иллюстрация, выполненная средствами векторной графики, может содержать десятки тысяч простейших объектов, взаимодействующих друг с другом. Векторные редакторы удобны для создания изображений, но практически не используются для обработки готовых рисунков. Они нашли широкое применение в рекламном бизнесе, их применяют для оформления обложек полиграфических изданий и всюду, где стиль художественной работы близок к чертежному.
в) Редакторы трехмерной графики используют для создания трехмерных композиций. Они имеют две характерные особенности:
- позволяют гибко управлять взаимодействием свойств поверхности изображаемых объектов со свойствами источников освещения;
- позволяют создавать трехмерную анимацию. Поэтому редакторы трехмерной графики нередко называют также 3D-аниматорами.
4. Системы управления базами данных. Базами данных называют огромные массивы данных, организованных в табличные структуры. Основными функциями систем управления базами данных являются:
• создание пустой (незаполненной) структуры базы данных;
• предоставление средств ее заполнения или импорта данных из таблиц другой базы;
• обеспечение возможности доступа к данным, а также предоставление средств поиска и фильтрации.
Многие системы управления базами данных дополнительно предоставляют возможности проведения простейшего анализа данных и их обработки. В результате возможно создание новых таблиц баз данных на основе имеющихся.
5. Электронные таблицы. Электронные таблицы предоставляют комплексные средства для хранения различных типов данных и их обработки. В некоторой степени они аналогичны системам управления базами данных, но основной акцент смещен не на хранение массивов данных и обеспечение к ним доступа, а на преобразование данных, причем в соответствии с их внутренним содержанием.
В отличие от баз данных для электронных таблиц характерна повышенная сосредоточенность на числовых данных и они предоставляют более широкий спектр методов для работы с данными числового типа.
Основное свойство электронных таблиц состоит в том, что при изменении содержания любых ячеек таблицы может происходить автоматическое изменение содержания во всех прочих ячейках, связанных с измененными соотношением, заданным математическими или логическими выражениями (формулами).
6. Системы автоматизированного проектирования (CAD-системы). Предназначены для автоматизации проектно-конструкторских работ. Кроме чертежно-графических работ эти системы позволяют проводить простейшие расчеты (например, расчеты прочности деталей) и выбор готовых конструктивных элементов из обширных баз данных.
7. Настольные издательские системы. Служат для автоматизации процесса верстки полиграфических изданий. Этот класс программного обеспечения занимает промежуточное положение между текстовыми процессорами и системами автоматизированного проектирования.Теоретически текстовые процессоры предоставляют средства для внедрения в текстовый документ объектов другой природы, например объектов векторной и растровой графики, а также позволяют управлять взаимодействием между параметрамитекста и параметрами внедренных объектов. Однако на практике для изготовления полиграфической продукции эти средства либо функционально недостаточны с точки зрения требований полиграфии, либо недостаточно удобны для производительной работы.
От текстовых процессоров настольные издательские системы отличаются расширенными средствами управления взаимодействием текста с параметрами страницы и с графическими объектами. С другой стороны, они отличаются пониженными функциональными возможностями по автоматизации ввода и редактирования текста. Типичный прием использования настольных издательских систем состоит в том, что их применяют к документам, прошедшим предварительную обработку в текстовых процессорах и графических редакторах.
8. Экспертные системы. Предназначены для анализа данных, содержащихся в базах знаний, и выдачи рекомендаций по запросу пользователя. Такие системы применяют в тех случаях, когда исходные данные хорошо формализуются, но для принятия решения требуются обширные специальные знания. Характерными областями использования экспертных систем являются юриспруденция, медицина, фармакология, химия. По совокупности признаков заболевания медицинские экспертные системы помогают установить диагноз и назначить лекарства, дозировку и программу лечебного курса. По совокупности признаков события юридические экспертные системы могут дать правовую оценку и предложить порядок действий как для стороны обвинения, так и для стороны защиты.
Характерной особенностью экспертных систем является их способность к саморазвитию. Исходные данные хранятся в базе знаний в виде фактов, между которыми с помощью специалистов-экспертов устанавливается определенная система отношений. Если на этапе тестирования экспертной системы устанавливается, что она дает некорректные рекомендации и заключения по конкретным вопросам или не может дать их вообще, это означает либо отсутствие важных фактов в ее базе, либо нарушения в логической системе отношений. И том и в другом случае экспертная система сама может сгенерировать достаточный набор запросов к эксперту и автоматически повысить свое качество.
9. Web -редакторы. Это особый класс редакторов, объединяющих в себе свойства текстовых и графических редакторов. Они предназначены для создания и редактирования так называемых Web-документов (Web-страниц Интернета). Web-документы — это электронные документы, при подготовке которых следует учитывать ряд особенностей, связанных с приемом/передачей информации в Интернете.
Теоретически для создания Web -документов можно использовать обычные текстовые редакторы и процессоры, а также некоторые из графических редакторов векторной графики, но Web -редакторы обладают рядом полезных функций, повышающих производительность труда Web -дизайнеров. Программы этого класса можно также эффективно использовать для подготовки электронных документов и мультимедийных изданий.
10. Браузеры (обозреватели, средства просмотра Web ). К этой категории относятся программные средства, предназначенные для просмотра электронных документов, выполненных в формате HTML(документы этого формата используются в качестве Web –документов).
11. Интегрированные системы делопроизводства. Представляют собой программные средства автоматизации рабочего места руководителя. К основным функциям подобных систем относятся функции создания, редактирования и форматирования простейших документов, централизация функций электронной почты, факсимильной и телефонной связи, диспетчеризация и мониторинг документооборота предприятия, координация деятельности подразделений, оптимизация административно-хозяйственной деятельности и поставка по запросу оперативной и справочной информации.
12. Бухгалтерские системы. Это специализированные системы, сочетающие в себе функции текстовых и табличных редакторов, электронных таблиц и систем управления базами данных. Предназначены для автоматизации подготовки первичных бухгалтерских документов предприятия и их учета, для ведения счетов плана бухгалтерского учета, а также для автоматической подготовки регулярных отчетов по итогам производственной, хозяйственной и финансовой деятельности в форме, принятой для предоставления в налоговые органы, внебюджетные фонды и органы статистического учета. Несмотря на то что теоретически все функции, характерные для бухгалтерских систем, можно исполнять и другими вышеперечисленными программными средствами, использование бухгалтерских систем удобно благодаря интеграции разных средств в одной системе.
13. Финансовые аналитические системы. Программы этого класса используются в банковских и биржевых структурах. Они позволяют контролировать и прогнозировать ситуацию на финансовых, товарных и сырьевых рынках, производить анализ текущих событий, готовить сводки и отчеты.
14. Геоинформационные системы (ГИС). Предназначены для автоматизации картографических и геодезических работ на основе информации, полученной топографическими или аэрокосмическими методами.
15. Системы видеомонтажа. Предназначены для цифровой обработки видеоматериалов, их монтажа, создания видеоэффектов, устранения дефектов, наложения звука, титров и субтитров.
Замечание : Отдельные категории прикладных программных средств, обладающие своими развитыми внутренними системами классификации, представляют обучающие, развивающие, справочные и развлекательные системы и программы. Характерной особенностью этих классов программного обеспечения являются повышенные требования к мультимедийной составляющей (использование музыкальных композиций, средств графической анимации и видеоматериалов)
Классификация служебных программных средств
1. Диспетчеры файлов (файловые менеджеры). С помощью программ данного класса выполняется большинство операций, связанных с обслуживанием файловой структуры: копирование, перемещение и переименование файлов, создание каталогов (папок), удаление файлов и каталогов, поиск файлов и навигация в файловой структуре. Базовые программные средства, предназначенные для этой цели, обычно входят в состав программ системного уровня и устанавливаются вместе с операционной системой.
2. Средства сжатия данных (архиваторы) .Предназначены для создания архивов. Архивирование данных упрощает их хранение за счет того, что большие группы файлов и каталогов сводятся в один архивный файл. При этом повышается и эффективность использования носителя за счет того, что архивные файлы обычно имеют повышенную плотность записи информации.
3. Средства просмотра и воспроизведения. Обычно для работы с файлами данных необходимо загрузить их в «родительскую» прикладную систему, с помощью которой они были созданы. Это дает возможность просматривать документы и вносить в них изменения. Но в тех случаях, когда требуется только просмотр без редактирования, удобно использовать более простые и более универсальные средства, позволяющие просматривать документы разных типов.
4. Средства диагностики. Предназначены для автоматизации процессов диагностики программного и аппаратного обеспечения. Они выполняют необходимые проверки и выдают собранную информацию в удобном и наглядном виде. Их используют не только для устранения неполадок, но и для оптимизации работы компьютерной системы.
5. Средства контроля (мониторинга). Позволяют следить за процессами, происходящими в компьютерной системе. При этом возможны два подхода: наблюдение в реальном режиме времени или контроль с записью результатов в специальном протокольном файле. Первый подход обычно используют при изыскании путей для оптимизации работы вычислительной системы и повышения ее эффективности. Второй подход используют в тех случаях, когда мониторинг выполняется автоматически и (или) дистанционно. В последнем случае результаты мониторинга можно передать удаленной службе технической поддержки для установления причин конфликтов в работе программного и аппаратного обеспечения.
6. Мониторы установки. Программы этой категории предназначены для контроля над установкой программного обеспечения. Необходимость в данном программном обеспечении связана с тем, что между различными категориями программного обеспечения могут устанавливаться связи. Вертикальные связи (между уровнями) являются необходимым условием функционирования всех компьютеров. Горизонтальные связи (внутри уровней) характерны для компьютеров, работающих с операционными системами, поддерживающими принцип совместного использования одних и тех же ресурсов разными программными средствами. И в тех и в других случаях при установке или удалении программного обеспечения могут происходить нарушения работоспособности прочих программ.
Простейшие средства управления установкой и удалением программ обычно входят в состав операционной системы и размещаются на системном уровне программного обеспечения.
7. Средства коммуникации (коммуникационные программы). Они позволяют устанавливать соединения с удаленными компьютерами, обслуживают передачу сообщений электронной почты, работу с телеконференциями (группами новостей), обеспечивают пересылку сообщений и выполняют множество других операций в компьютерных сетях.
8. Средства обеспечения компьютерной безопасности. К этой весьма широкой категории относятся средства пассивной и активной защиты данных от повреждения, а также средства защиты от несанкционированного доступа, просмотра и изменения данных.
В качестве средств пассивной защиты используют служебные программы, предназначенные для резервного копирования. Нередко они обладают и базовыми свойствами диспетчеров архивов (архиваторов). В качестве средств активной защиты применяют антивирусное программное обеспечение. Для защиты данных от несанкционированного доступа, их просмотра и изменения служат специальные системы, основанные на криптографии.
Тема 2. Операционная система: понятия и функции
Особенности ОС
Большинство компьютеров имеет два режима работы: режим ядра и режим пользователя. Операционная система — наиболее фундаментальная часть программного обеспечения, работающая в режиме ядра (этот режим называют еще режимом супервизора ). В этом режиме она имеет полный доступ ко всему аппаратному обеспечению и может задействовать любую инструкцию , которую машина в состоянии выполнить. Вся остальная часть программного обеспечения работает в режиме пользователя, в котором доступно лишь подмножество инструкций машины. Операционная система изолирует аппаратное обеспечение компьютера от прикладных программ пользователей. И пользователь, и его программы взаимодействуют с компьютером через интерфейсы операционной системы.
ОС работает непосредственно с аппаратным обеспечением и является основой всего остального программного обеспечения.
Важное отличие операционной системы от обычного (работающего в режиме пользователя) программного обеспечения состоит в следующем: если пользователь недоволен конкретной программой чтения электронной почты, то он волен выбрать другую программу или, если захочет, написать свою собственную программу, но он не может написать свой собственный обработчик прерываний системных часов, являющийся частью операционной системы и защищенный на аппаратном уровне от любых попыток внесения изменений со стороны пользователя.
Операционные системы отличаются от пользовательских программ (то есть приложений) не только местоположением. Их особенности — довольно большой объем, сложная структура и длительные сроки использования. Исходный код операционных систем типа Linux или Windows занимает порядка пяти миллионов строк. Чтобы представить себе этот объем, давайте мысленно распечатаем пять миллионов строк в книжном формате, по 50 строк на странице и по 1000 страниц в каждом томе (что больше этой книги). Чтобы распечатать такое количество кода, принадлежащего операционной системе, понадобится 100 томов, а это практически целая книжная полка.
Теперь понятно, почему операционные системы живут так долго — их очень трудно создавать, и, написав одну такую систему, владелец не испытывает желания ее выбросить и приступить к созданию новой. Поэтому операционные системы развиваются в течение долгого периода времени. Семейство Windows 95/98/Ме по своей сути представляло одну операционную систему, а семейство Windows NT/2000/XP/Vista — другую. Для пользователя они были похожи друг на друга, поскольку Microsoft позаботилась о том, чтобы пользовательский интерфейс Windows 2000/ХР был очень похож на ту систему, которой он шел на замену, а чаще всего это была Windows 98. Тем не менее у Microsoft были довольно веские причины, чтобы избавиться от Windows 98, и мы еще вернемся к их рассмотрению, когда приступим к подробному изучения системы Windows.
Что такое ОС? Подходы к определению
Большинство пользователей имеет опыт эксплуатации операционных систем, но тем не менее они затруднятся дать этому понятию точное определение. Давайте кратко рассмотрим основные точки зрения.
Подход 1: Операционная система - виртуальная машина
При разработке ОС широко применяется абстрагирование , которое является важным методом упрощения и позволяет сконцентрироваться на взаимодействии высокоуровневых компонентов системы, игнорируя детали их реализации. В этом смысле ОС представляет собой интерфейс между пользователем и компьютером.
Архитектура большинства компьютеров на уровне машинных команд очень неудобна для использования прикладными программами. Например, работа с диском предполагает знание внутреннего устройства его электронного компонента — контроллера для ввода команд вращения диска, поиска и форматирования дорожек, чтения и записи секторов и т. д. Ясно, что средний программист не в состоянии учитывать все особенности работы оборудования (в современной терминологии — заниматься разработкой драйверов устройств), а должен иметь простую высокоуровневую абстракцию, скажем, представляя информационное пространство диска как набор файлов. Файл можно открывать для чтения или записи, использовать для получения или сброса информации, а потом закрывать. Это концептуально проще, чем заботиться о деталях перемещения головок дисков или организации работы мотора.
Аналогичным образом, с помощью простых и ясных абстракций, скрываются от программиста все ненужные подробности организации прерываний, работы таймера, управления памятью и т. д. Более того, на современных вычислительных комплексах можно создать иллюзию неограниченного размера операционной памяти и числа процессоров. Всем этим занимается операционная система.
Таким образом, операционная система представляется пользователю виртуальной машиной, с которой проще иметь дело, чем непосредственно с оборудованием компьютера .
Подход 2: Операционная система - менеджер ресурсов
Операционная система предназначена для управления всеми частями весьма сложной архитектуры компьютера. Представим, к примеру, что произойдет, если несколько программ, работающих на одном компьютере, будут пытаться одновременно осуществлять вывод на принтер. Мы получили бы мешанину строчек и страниц, выведенных различнымипрограммами. Операционная система предотвращает такого рода хаос за счет буферизации информации, предназначенной для печати, на диске и организации очереди на печать. Для многопользовательских компьютеров необходимость управления ресурсами и их защиты еще более очевидна. Следовательно, операционная система, как менеджер ресурсов, осущест вляет упорядоченное и контролируемое распределение процессоров, памяти и других ресурсов между различными программами .
Подход 3:Операционная система - защитник пользователей и программ
Если вычислительная система допускает совместную работу нескольких пользователей, то возникает проблема организации их безопасной деятельности. Необходимо обеспечить сохранность информации на диске, чтобы никто не мог удалить или повредить чужие файлы. Нельзя разрешить программам одних пользователей произвольно вмешиваться в работу программ других пользователей. Нужно пресекать попытки несанкционированного использования вычислительной системы. Всю эту деятельность осуществляет операционная система как организатор безопасной работы пользователей и их программ . С такой точки зрения операционная система представляется системой безопасности государства, на которую возложены полицейские и контрразведывательные функции.
Подход 4: Операционная система - постоянно функционирующее ядро
Наконец, можно дать и такое определение: операционная система — это программа, постоянно работающая на компьютере и взаимодействующая со всеми прикладными программами. Казалось бы, это абсолютно правильное определение, но, как мы увидим дальше, во многих современных операционных системах постоянно работает на компьютере лишь часть операционной системы, которую принято называть ее ядром.
Как мы видим, существует много точек зрения на то, что такое операционная система. Невозможно дать ей адекватное строгое определение. Нам проще сказать не что есть операционная система, а для чего она нужна и что она делает.
На сегодняшний день можно констатировать, что операционная система (ОС) представляет собой комплекс системных управляющих и обрабатывающих программ, которые, с одной стороны, выступают как интерфейс между аппаратурой компьютера и пользователем с его задачами, а с другой стороны, предназначены для наиболее эффективного расходования ресурсов вычислительной системы и организации надежных вычислений.
Функции ОС:
1. Обеспечение интерфейса.
2. Обеспечение автоматического самозапуска.
3. Организация файловой системы.
4. Обслуживание файловой структуры.
5. Прием указаний от пользователя
6. Управление установкой, исполнением и удалением приложений.
7. Взаимодействие с аппаратным обеспечением.
8. Обслуживание компьютера.
9. Дополнительные функции.
10. Идентификация программ и данных
11. Прием и исполнение запросов от программ
12. Обеспечение операций ввода-вывода
13. Обеспечение работы СУФ или СУБД
14. Обеспечение взаимодействия связанных компьютеров
15. Аутентификация и идентификация пользователей
16. Предоставление услуг на случай сбоя системы
1. Обеспечение интерфейса

Интерфейс пользователя – интерфейс между пользователем и программно-аппаратными средствами компьютера.
Аппаратно-программный интерфейс – интерфейс между программным и аппаратным обеспечением.
Программный интерфейс – интерфейс между различными видами программного обеспечения.
| Интерфейс пользователя | |
| Командный | Графический |
| Основное устройство управления – клавиатура. Управляющие команды вводятся в поле командной строки, глее их можно редактировать. Исполнение команды начинается после ее утверждения (например, клавишей Enter). | Основной инструмент управления наряду с клавиатурой – мышь или иное устройство позиционирования. Работа основана на взаимодействии активных и пассивных элементов управления. Активный элемент управления – указатель мыши. Пассивные элементы – графические элементы управления: экранные кнопки, флажки, переключатели, раскрывающиеся списки, строки меню и т. д. Характер взаимодействия между пассивными и активными элементами выбирает пользователь. |
2. Обеспечение автоматического самозапуска
Все ОС обеспечивают свой автоматический запуск. Для дисковых ОС в специальной области диска (системной) создается запись программного кода. Обращение к этому коду выполняют программы, находящиеся в BIOS. Когда эти программы завершают свою работу, то они дают команду на загрузку и исполнение содержимого системной области диска. Недисковые ОС присутствуют в специализированных вычислительных системах. Здесь автоматический запуск ОС производится аппаратно: при подаче питания процессор обращается к фиксированному адресу постоянной памяти, начиная с которого записана программа запуска ОС.
3. Организация файловой системы
Все современные дисковые ОС обеспечивают создание файловой системы, которая служит для хранения данных на дисках и обеспечения доступа к ним. Принцип организации файловой системы – табличный. Эта таблица располагается в системной области диска и содержит информацию о том, в каком месте жесткого диска записан тот или иной файл. ОС контролирует целостность и надежность этих данных.
4. Обслуживание файловой структуры
Данные о местоположении файлов хранятся в табличной структуре, но пользователю они представляются для удобства в виде иерархической структуры, а все преобразования берет на себя ОС. При обслуживании файловой структуры ОС выполняет следующие операции:
5. Прием от пользователя (или от оператора системы) заданий, или команд , сформулированных на соответствующем языке, и их обработка. Задания могут передаваться в виде текстовых команд оператора или в форме указаний, выполняемых с помощью манипулятора (например, с помощью мыши). Эти команды связаны, прежде всего, с запуском (приостановкой, остановкой) программ, с операциями над файлами (, хотя имеются и иные команды.
6. Управление установкой приложений
Для правильной работы приложений они сначала должны пройти процедуру установки . Она нужна из-за того, что при разработке ПО невозможно заранее предвидеть особенности аппаратной и программной конфигурации вычислительной системы, на которой будет работать это ПО. Поэтому дистрибутивный комплект ПО (установочный пакет ) представляет собой не законченный программный продукт, а так называемый полуфабрикат, из которого в процессе установки формируется полноценное приложение. При этом происходит привязка приложения к существующей аппаратно-программной среде и настройка его на работу именно в этой среде.
7. Управление исполнением приложений
а. Загрузка в оперативную память подлежащих исполнению программ.
б. Распределение памяти, а в большинстве современных систем и организация виртуальной памяти.
в. Запуск программы (передача ей управления, в результате чего процессор исполняет программу).
г. возможность одновременной (режим мультипрограммирования) или поочередной работы нескольких приложений (в зависимости от типа ОС);
д. Организация механизмов обмена сообщениями и данными между выполняющимися программами.
е. возможность совместного использования программных, аппаратных, сетевых и прочих ресурсов вычислительной системы несколькими приложениями;
ж. Защита одной программы от влияния другой, обеспечение сохранности данных, защита самой операционной системы от исполняющихся на компьютере приложений.
8. Управление удалением приложений
a) Если в ОС каждое приложение имеет собственные ресурсы, то его удаление не требует вмешательства ОС – достаточно удалить каталог, где размещается приложение.
b) Если в ОС ресурсы используются совместно, то нельзя допустить, чтобы при удалении одного приложения были удалены ресурсы, необходимые другим приложениям (даже если эти ресурсы были установлены с удаляемым приложением). Поэтому в таком случае удаление происходит под контролем ОС.
9. Взаимодействие с аппаратным обеспечением
Из-за многообразия аппаратных средств, разработчики ПО не могут предусмотреть варианты взаимодействия своих программ с ними. Поэтому разработчики прилагают к своим программам специальные средства управления – драйверы .
10. Обслуживание компьютера
С этой целью современные ОС содержат в своем составе служебные приложения:
11. Дополнительные функции
12. Идентификация всех программ и данных.
13. Прием и исполнение различных запросов от выполняющихся приложений . Операционная система умеет выполнять очень большое количество системных функций (сервисов), которые могут быть запрошены из выполняющейся программы. Обращение к этим сервисам осуществляется по соответствующим правилам, которые и определяют интерфейс прикладного программирования (ApplicationProgramInterface, API) этой операционной системы.
14. Обслуживание всех операций ввода-вывода.
15. Обеспечение работы систем управлений файлами (СУФ) и/или систем управления базами данных (СУБД) , что позволяет резко увеличить эффективность всего программного обеспечения.
16. Обеспечение взаимодействия связанных между собой компьютеров ( Для сетевых операционных систем) .
17. Аутентификация и авторизация пользователей (для большинства диалоговых операционных систем). Под аутентификацией понимается процедура проверки имени пользователя и его пароля на соответствие тем значениям, которые хранятся в его учетной записи. Очевидно, что если входное имя (login) пользователя и его пароль совпадают, то, скорее всего, это и будет тот самый пользователь. Термин авторизация означает, что в соответствии с учетной записью пользователя, который прошел аутентификацию, ему (и всем запросам, которые будут идти к операционной системе от его имени) назначаются определенные права (привилегии), определяющие, что он может, а что не может делать на компьютере.
18. Предоставление услуг на случай частичного сбоя системы.
Тема 3. Архитектурные особенности компьютера
На макроуровне компьютер состоит из процессора, памяти и устройств ввода-вывода; при этом каждый компонент представлен одним или несколькими модулями. Чтобы компьютер мог выполнят свое основное предназначение, состоящее в выполнении программ, различные компоненты должны иметь возможность функционировать между собой.
Итак, выделим 4 структурные компоненты компьютера:
1. Процессор . Осуществляет контроль за действиями компьютера и обрабатывает данные. Если в системе есть только один процессор, он называется центральным процессором (CentralProcessingUnit - CPU).
2. Память . Разные виды памяти имеют различное назначение.
3. Устройства ввода-вывода . Служат для передачи данных между компьютером и внешним окружением, состоящим из различных периферийных устройств, в число которых входит вторичная память, коммуникационное оборудование и терминалы.
4. Системная шина . Определенные структуры и механизмы, обеспечивающие взаимодействие между процессором, оперативной памятью и устройствами ввода-вывода.
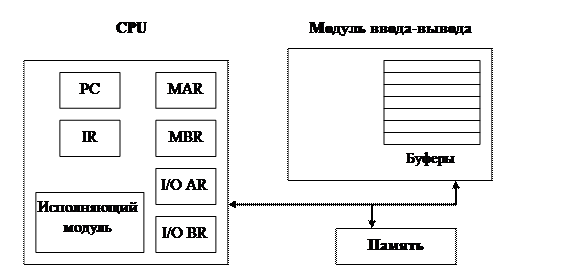
Рис. 3. Макроструктура компьютера
Процессор
Он выбирает из памяти команды и выполняет их. Обычный цикл работы центрального процессора выглядит так: он читает первую команду из памяти, декодирует ее для определения ее типа и операндов, выполняет команду, затем считывает, декодирует и выполняет последующие команды. Таким образом осуществляется выполнение программ.
Для каждого центрального процессора существует набор команд, который он в состоянии выполнить. Например, процессор Pentium не может обработать программы, написанные для SPARC, а процессор SPARC не может выполнить программы, написанные для Pentium.
Доступ к памяти для получения команд или наборов данных занимает намного больше времени, чем выполнение этих команд. Поэтому все центральные процессоры содержат внутренние регистры для хранения ключевых переменных и временных результатов.
Регистр – область памяти быстрого доступа, но намного меньшей емкости, чем основная память.
Регистры выполняют 2 основные функции:
1. Регистры, доступные пользователю . Позволяют программисту хранить в них некоторые данные, чтобы сократить число обращений к основной памяти.
2. Регистры управления и регистры состояния. Используются в процессоре для контроля над выполняемыми операциями. С их помощью привилегированные программы ОС могут контролировать ход выполнения других программ.
Регистры, доступные пользователю
К ним пользователь может обращаться с помощью машинного языка. Обычно к ним имеют доступ все программы – и приложения, и системные.
1. Регистры данных. Программист может применять их в различных целях. В ряде случаев они имеют общее назначение и могут использоваться любой машинной командой для операций с данными. Однако зачастую при этом накладываются определенные ограничения. Например, некоторые регистры предназначены для операций с числами с десятичной точкой, в то время как остальные – для хранения целых чисел.
2. Адресные регистры – в них заносятся адреса команд и данных в основной памяти.
3. SP (stack pointer) – указатель стека. Он содержит адрес вершины стека в памяти. Стек размещается в основной памяти в виде последовательности ячеек. Он похож на стопку бумаг, в которой листы с данными можно брать и класть только сверху. Верхний элемент стека, которому только и возможен доступ, называется вершиной.
Регистры управления и регистры состояния
В большинстве машин эти регистры в основном не доступны пользователю. Некоторые из них могут быть доступны для машинных команд, исполняемых в так называемом режиме операционной системы (режиме ядра).
PC (programcounter) –счетчик программ, содержит адрес следующей команды, которая стоит в очереди на выполнение.
MAR (memoryaddressregister) – регистр адреса памяти, сюда заносится адрес ячейки памяти, в которой будет производиться операция чтения-записи;
MBR (memorybufferregister) – регистр буфера памяти, сюда заносятся данные, предназначенные для записи в память, или те, которые были прочитаны из нее.
I/ O AR (input/outputaddressregister) - регистр адреса ввода-вывода, здесь задается номер устройства ввода-вывода.
I/ O BR (input/outputbufferregister) – регистр буфера ввода-вывода, служит для обмена данными между устройствами ввода-вывода и процессором.
PC (programcounter) –счетчик программ, содержит адрес команды, которая должна быть выбрана из памяти.
IR (instructionregister)– регистр команд, содержит последнюю выбранную из памяти команду.
PSW (programstatusword) – регистр слова состояния программы. Отражает состояние АЛУ в составе процессора при выполнении программ.
Операционная система должна знать все обо всех регистрах. При временном мультиплексировании (выполнение нескольких задач) центрального процессора операционная система часто останавливает работающую программу для запуска (или перезапуска) другой. Каждый раз при таком прерывании операционная система должна сохранять все регистры процессора, чтобы позже, когда программа продолжит свою работу, их можно было восстановить.
Как уже упоминалось, большинство центральных процессоров, за исключением самых простых, используемых во встраиваемых системах, имеют два режима работы: режим ядра и пользовательский режим (режим пользователя). Обычно режимом управляет специальный бит в регистре PSW. При работе в режиме ядра процессор может выполнять любые команды из своего набора и использовать любые возможности аппаратуры. Операционная система работает в режиме ядра, что дает ей доступ ко всему оборудованию.
Для получения услуг от операционной системы пользовательская программа должна осуществить системный вызов, который перехватывается внутри ядра и вызывает операционную систему. Инструкция перехвата осуществляет переключение из пользовательского режима в режим ядра и запускает операционную систему. Когда обработка вызова будет завершена, управление возвращается пользовательской программе, и выполняется команда, которая следует за системным вызовом. Подробности механизма системного вызова будут рассмотрены в этой главе чуть позже, а сейчас его следует считать специальной разновидностью инструкции вызова процедуры, у которой есть дополнительное свойство переключения из пользовательского режима в режим ядра.
Многопоточные и многоядерные микропроцессоры
Закон Мура гласит, что количество транзисторов на одном кристалле удваивается каждые 18 месяцев. Этот «закон», в отличие от закона сохранения импульса, не имеет никакого отношения к физике, он появился в результате наблюдений одного из соучредителей корпорации Intel Гордона Мура (Gordon Moore) за темпами, с которыми шло уменьшение размеров транзисторов. Закон Мура соблюдался в течение трех десятилетий, и, как ожидается, будет соблюдаться как минимум еще одно десятилетие.
Высокая плотность размещения транзисторов ведет к проблеме: как распорядиться их возросшим количеством? Ранее мы уже ознакомились с одним из подходов к ее решению — использованием архитектуры, имеющей множество функциональных блоков. Но с ростом числа транзисторов открываются более широкие возможности. Одно из очевидных решений — размещение на кристалле центрального процессора более объемной кэш-памяти — уже воплощено в жизнь. Однако это порог, за которым дальнейшее увеличение объема кэш-памяти только уменьшает отдачу от этого решения.
Следующим очевидным шагом является дублирование не только функциональных блоков, но и части управляющей логики. Такие свойства, присущие процессору Pentium 4 и некоторым другим микропроцессорам, называются многопоточностью , или гиперпоточностью (hyperthreading по версии Intel). В первом приближении эта технология позволяет процессору сохранять состояние двух различных потоков и осуществлять переключения между ними за наносекунды. (Поток является разновидностью выполняющейся программы) Например, если одному из процессов нужно прочитать слово из памяти (что занимает несколько тактов), многопоточный процессор может переключиться на другой поток. Многопоточность не предлагает настоящей параллельной обработки данных. Одновременно работает только один процесс, но время переключения между процессами сведено до наносекунд.
Кроме процессоров с многопоточностью, существуют процессоры, содержащие на одном кристалле два, четыре и более полноценных процессоров, или ядер. Например, четырехъядерные процессоры, показанные на рис. 4, фактически имеют в своем составе четыре мини-чипа, каждый из которых представляет собой независимым процессор. (Кэши мы рассмотрим чуть позже.) Несомненно, для использования такого многоядерного процессора потребуется многопроцессорная операционная система.

Рис 4. - Четырехъядерный процессор с общей кэш-памятью второго уровня (L2) (а). Четырехъядерный процессор с отдельными блоками кэш-памяти L2 (б)
Память
Второй основной составляющей любого компьютера является память. В идеале память должна быть максимально быстрой (работать быстрее, чем производится выполнение одной инструкции, чтобы работа центрального процессора не замедлялась обращениями к памяти), достаточно большой и чрезвычайно дешевой. Никакая современная технология не в состоянии удовлетворить все эти требования, поэтому используется другой подход. Система памяти создается в виде иерархии уровней.
Верхние уровни обладают более высоким быстродействием, меньшим объемом и более высокой удельной стоимостью хранения одного бита информации, чем нижние уровни, иногда в миллиарды и более раз.

Верхний уровень состоит из внутренних регистров процессора. Они выполнены по той же технологии, что и сам процессор, и поэтому не уступают ему в быстродействии. Следовательно, к ним нет и задержек доступа. Внутренние регистры обычно предоставляют возможность для хранения 32 х 32 бит для 32-разрядного процессора или 64 х 64 бит для 64-разрядного процессора. В обоих случаях этот объем не превышает одного килобайта. Программы могут сами управлять регистрами (то есть решать, что в них хранить) без вмешательства аппаратуры.
Затем следует кэш-память , которая управляется главным образом аппаратурой.
Оперативная память разделяется на кэш-строки, обычно по 64 байт, с адресами от 0 до 63 в кэш-строке 0, адресами от 64 до 127 в кэш-строке 1, и т. д. Наиболее интенсивно используемые кэш-строки оперативной памяти сохраняются в высокоскоростной кэш-памяти, находящейся внутри процессора или очень близко к нему. Когда программе нужно считать слово из памяти, аппаратура кэша проверяет, нет ли нужной строки в кэш-памяти. Если строка в ней имеется, то происходит результативное обращение к кэш-памяти (кэш-попадание), запрос удовлетворяется за счет кэш-памяти без отправки запроса по шине к оперативной памяти. Обычно результативное обращение к кэшу занимает по времени два такта.
Отсутствие слова в кэш-памяти вынуждает обращаться к оперативной памяти, что приводит к существенной потере времени. Кэш-память из-за своей высокой стоимости ограничена в объеме. Некоторые машины имеют два или даже три уровня кэша, каждый из которых медленнее и объемнее предыдущего.
Кэширование играет существенную роль во многих областях информатики, это относится не только к кэшированию строк оперативной памяти. Достаточно часто к кэшированию для повышения производительности прибегают везде, где есть какой-либо объемный ресурс, который можно поделить на части, часть из которых используется намного интенсивнее всех остальных. Операционные системы используют кэширование повсеместно. Например, большинство операционных систем держат интенсивно используемые файлы (или фрагменты файлов) в оперативной памяти, избегая их многократного считывания с диска.
Применение кэширования оказалось настолько удачным решением, что многие современные процессоры имеют сразу два уровня кэш-памяти . Первый уровень, или кэш L1 , всегда является частью самого процессора и обычно подает декодированные команды в процессорный механизм исполнения команд . У многих процессоров есть и второй кэш L1 для тех слов данных, которые используются особенно интенсивно. Обычно каждый из кэшей L1 имеет объем 16 Кбайт . Вдобавок к этому кэшу процессоры часто оснащаются вторым уровнем кэш-памяти, который называется кэш L2 и содержит несколько мегабайт недавно использованных слов памяти . Различия между кэш-памятью L1 и L2 заключаются во временной диаграмме. Доступ к кэшу первого уровня осуществляется без задержек, а доступ к кэшу второго уровня требует задержки в один или два такта.
При разработке многоядерных процессоров конструкторам приходится решать, куда поместить кэш-память. На рис. 4, а показан один кэш L2, совместно использующийся всеми ядрами. Такой подход применяется в многоядерных процессорах корпорации Intel. Для сравнения на рис. 4, б каждое ядро имеет свою собственную кэш-память L2. Именно такой подход применяется компанией AMD. Каждый из подходов имеет свои аргументы «за» и «против». Например, общая кэш-память L2 корпорации Intel требует использования более сложного кэш-контроллера, а избранный AMD путь усложняет поддержание согласованного состояния кэш-памяти L2 разных ядер.
Следующей в иерархии идет оперативная память . Это главная рабочая область системы памяти машины. Оперативную память часто называют ОЗУ (оперативное запоминающее устройство) или памятью с произвольным доступом (RAM, Random Access Memory). В настоящее время блоки памяти имеют объем от сотен мегабайт до нескольких гигабайт, и этот объем стремительно растет. Все запросы процессора, которые не могут быть удовлетворены кэш-памятью, направляются к оперативной памяти .
После оперативной памяти следующим уровнем в нашей иерархии памяти является жесткий диск . Дисковый накопитель в пересчете на бит информации на два порядка дешевле, чем ОЗУ, а его емкость зачастую на два порядка выше. Единственная проблема состоит в том, что время произвольного доступа к данным примерно на три порядка медленнее. Причина низкой скорости доступа к данным заключается в том, что диск является механическим устройством, конструкция которого условно показана на рис. 5.
Жесткий диск состоит из одной или нескольких металлических пластин, вращающихся со скоростью 5400, 7200 или 10 800 оборотов в минуту .
Механический привод поворачивается на определенный угол над пластинами, подобно звукоснимателю старого проигрывателя виниловых пластинок на 33 оборота в минуту.
Информация записывается на диск в виде последовательности концентрических окружностей.
В каждой заданной позиции привода каждая из головок может считывать кольцеобразный участок, называемый дорожкой .
Из совокупности всех дорожек в заданной позиции привода составляется цилиндр .
Каждая дорожка поделена на определенное количество секторов , обычно по 512 байт на сектор. Секторы нумеруются, начиная с 1. На современных дисках внешние цилиндры содержат больше секторов, чем внутренние.
Каждый сектор, кроме данных, содержит различную служебную информацию, необходимую для правильного функционирования контроллера дисковода. В частности эта служебная информация включает такие данные, как номер дорожки и номер сектора. Если на диске имеется место с глубоким нарушением покрытия, то данные здесь не могут сохраниться. Говорят, что на диске появился дефектный сектор.
Самый первый сектор на дорожке 0 поверхности 0 выделяется под стартовый сектор . Он содержит:
· собственно программу, позволяющую считывать данные с диска в оперативную память (загрузочную запись);
· секторов диска в байтах;
· количество секторов на диске;
· количество секторов на дорожке.
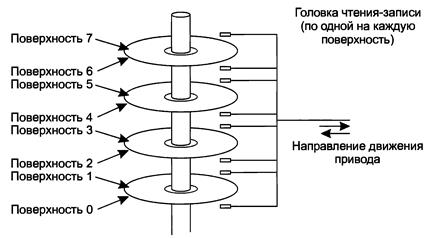
Рис. 5. Конструкция жесткого диска
Когда на диск записывается новый файл, ОС обычно не предоставляет точного числа требующихся байтов, а выделяет дисковое пространство целыми секторами. Минимальное число секторов, выделяемое файловой системой для хранения файла, называется кластером . Размер кластера должен быть кратен размеру физического сектора, т. е. 512 байтам в подавляющем большинстве случаев. Размеры кластеров зависят от емкости используемого диска. Для гибких дисков емкостью 1.44 МВ кластеры включают в себя 1 сектор, а на жестких дисках объем кластера зависит от их емкости.
Файлу, записываемому на диск, выделяется целое число кластеров, причем, что существенно, кластеры могут находиться в различных местах диска. В отличие от файлов, хранящихся в непрерывных областях памяти (непрерывные файлы ), файлы, хранящиеся в различных кластерах, называются фрагментированными .
Перемещение привода с одного цилиндра на следующий цилиндр занимает около 1 мс.
Перемещение к произвольно выбранному цилиндру обычно занимает от 5 до 10 мс, в зависимости от конкретного накопителя.
Когда привод расположен над нужной дорожкой, накопитель должен выждать, когда нужный сектор попадет под головку. Это приводит к возникновению еще одной задержки от 5 до 10 мс, в зависимости от скорости вращения диска.
После попадания требуемого сектора под головку производится операция чтения или записи со скоростью от 50 Мбайт/с (для низкоскоростных дисков) до 160 Мбайт/с (для высокоскоростных).
Многие компьютеры поддерживают схему, которая называется виртуальной памятью (файл подкачки) . Она дает возможность запускать программы, превышающие по объему физическую память компьютера, за счет помещения их на диск и использования оперативной памяти как некой разновидности кэша для наиболее интенсивно исполняемых частей.
ПЗУ - постоянное запоминающее устройство . Оно же память, предназначенная только для чтения, — ROM (ReadOnlyMemory). В отличие от ОЗУ она не утрачивает свое содержимого при отключении питания, то есть является энергонезависимой. ПЗУ программируется на предприятии-изготовителе и впоследствии не подлежит изменению. Эта разновидность памяти характеризуется высоким быстродействием
ПЗУ содержит набор программ:
1) программу первоначальной загрузки компьютера. Программа первоначальной загрузки получает управление после успешного завершения тестов и делает первый шаг для загрузки операционной системы.
2) программу первоначального тестирования компьютера. Эта программа получает управление сразу после включения компьютера. Она проверяет все подсистемы компьютера. В случае обнаружения ошибки или неисправности компьютера отображает на экране соответствующее сообщение;
3) базовую систему ввода-вывода. Она представляет набор программ, используемых для управления основными устройствами компьютера. Базовая система ввода-вывода позволяет отображать на экране компьютера символы и графику, записывать и читать данные с магнитных дисков, печатать на принтере и решать много других важных задач. BIOS может быть обновлена операционной системой в случае обнаружения в BIOS различных ошибок
На материнской плате располагается микросхема, которую называют CMOS-памятью ( ComplementaryMetal-Oxid-Semicondactor – технология «комплементарные пары метал-оксид-полупроводник») . Она энергонезависима. Микросхема CMOS-памяти питается от специальной маленькой батарейки или аккумулятора, которые также находятся на системной плате. Эта память содержит:
1) текущую дату и время (значение текущего времени исправно обновляется, даже если компьютер полностью отсоединен от внешнего источника питания);
2) параметры конфигурации компьютера, например количество и тип дисковых накопителей, тип видеоадаптера;
3) диск, с которого загружается ОС.
Некоторые компьютеры хранят в CMOS-памяти пароль, запрашиваемый сразу при включении питания. Задав пароль вы можете ограничить доступ к компьютеру. Вам надо быть очень осторожным при задании пароля. В случае, если вы его забудете вам придется повозиться, чтобы загрузить компьютер. Для удаления пароля и для заполнения CMOS-памяти значениями, принятыми по умолчанию (они хранятся в ПЗУ), можно отключить питание (аккумулятор) от микросхемы часов, содержащей CMOS-память. Однако если аккумулятор расположен непосредственно в микросхеме часов, вам остается только отправить компьютер в ремонт.
После изменения конфигурации компьютера (например после замены видеоадаптера или дисковода), для изменения текущей даты, времени, пароля необходимо обновить содержимое CMOS-памяти. Для этого предназначена специальная программа, часто называемая SETUP-программой или программой установки конфигурации.
Устройства ввода-вывода
Модуль ввода-вывода служит для передачи данных от внешних устройств как в процессор и память, так и в обратном направлении. Устройства ввода-вывода обычно состоят из двух компонентов: самого устройства и его контроллера.
Контроллер – набор микросхем, которые управляют устройством на физическом уровне. Он принимает от операционной системы команды, например, считать данные с помощью устройства, а затем их выполняет. Достаточно часто непосредственное управление устройством очень сложно, поэтому задачей контроллера является предоставление операционной системе простого (но не упрощенного) интерфейса.
Так как все типы контроллеров отличаются друг от друга, для управления ими требуется различное программное обеспечение. Программа, предназначенная для общения с контроллером, выдачи ему команды и воспринятая поступающих от него ответов, называется драйвером устройства. Каждый производитель контроллеров должен поставлять вместе с ними драйверы для каждой поддерживаемой операционной системы.
Для использования драйвера его нужно поместить в операционную систему, предоставив ему тем самым возможность работы в режиме ядра. Существует три способа установки драйвера в ядро.
1. Первый: заново скомпоновать ядро вместе с новым драйвером и затем перезагрузить систему. Многие устаревшие UNIX-системы именно так и работают.
2. Второй: создать запись в специальном файле операционной системы, сообщающую ей о том, что требуется, и затем перезагрузить систему. Во время загрузки операционная система сама находит нужные ей драйверы и загружает их. Именно так и работает система Windows.
3. Третий: динамическая загрузка драйверов — операционная система может принимать новые драйверы в процессе своей работы и оперативно устанавливать их, не требуя для этого перезагрузки. Этот способ ранее использовался довольно редко, но сейчас он получает все большее распространение.
Существуют внешние устройства, работающие по принципу «горячего подключения » (устройства, которые могут быть подключены к компьютеру или отключены от него без необходимости останавливать работу операционной системы и отключать компьютер от источника питания), они всегда нуждаются в динамически загружаемых драйверах.
Ввод и вывод данных можно осуществлять тремя различными способами.
Программируемый ввод-вывод
1) Пользовательская программа производит системный вызов, который преобразуется ядром ОС в программу вызова соответствующего драйвера.
2) Драйвер приступает к процессу ввода-вывода. В это время драйвер выполняет очень короткий цикл, постоянно опрашивая устройство и отслеживая завершение операции (обычно занятость устройства определяется состоянием специального бита).
3) По завершении операции ввода-вывода драйвер помещает данные (если таковые имеются) туда, куда требуется, и возвращает управление.
4) Затем операционная система возвращает управление вызывающей программе.
Недостаток такого способа заключается в том, что он загружает процессор опросом устройства об окончании работы.
Ввод-вывод с использованием прерываний
1) Драйвер запускает устройство и просит его выдать прерывание по окончании выполнения команды (завершении ввода или вывода данных). Прерывание - сигнал, сообщающий процессору о наступлении какого-либо события.
2) Сразу после этого драйвер возвращает управление ОС.
3) Затем операционная система блокирует вызывающую программу, если это необходимо, и переходит к выполнению других задач.
4) Когда контроллер обнаруживает окончание передачи данных, он генерирует прерывание, чтобы сообщить о завершении операции.
Прямой доступ к памяти
Используется специальный контроллер прямого доступа к памяти (DMA, DirectMemoryAccess). Когда надо прочитать или записать блок данных, то:
1) Процессор посылает модулю DMA следующую информацию:
a. что надо выполнить – чтение или запись;
b. адрес устройства ввода-вывода;
c. сколько байт требуется передать.
2) Затем процессор прекращает работу.
3) Модуль DMA передает весь блок данных в память или из нее, не задействуя процессор.
4) Когда модуль DMAзавершает работу, то он генерирует прерывание, чтобы сообщить процессору об окончании работы.
Таким образом, процессор задействован только в начале и конце передачи данных.
Загрузка компьютера
В кратком изложении загрузка компьютера на базе процессора Pentium происходит следующим образом. У каждого компьютера Pentium есть материнская плата (системная). На материнской плате находится программа, которая называется базовой системой ввода-вывода — BIOS (BasicInputOutputSystem). BIOS содержит низкоуровневое программное обеспечение ввода-вывода, включая процедуры считывания состояния клавиатуры, вывода информации на экран и осуществления, ко всему прочему, дискового ввода-вывода.
При начальной загрузке компьютера BIOS начинает работать первой. Сначала она проверяет объем установленной на компьютере оперативной памяти и наличие клавиатуры, а также установку и нормальную реакцию других основных устройств.
Все начинается со сканирования шин с целью определения всех подключенных к ним устройств. Эти устройства регистрируются. Если присутствующие устройства отличаются от тех, которые были зарегистрированы в системе при ее последней загрузке, то производится конфигурирование новых устройств.
Затем BIOS определяет устройство, с которого будет вестись загрузка, по очереди проверив устройства из списка, сохраненного в CMOS-памяти. Пользователь может внести в этот список изменения, войдя сразу после начальной загрузки в программу конфигурации BIOS. Обычно делается попытка загрузки с гибкого диска, если, конечно, он присутствует в системе. В случае неудачи идет запрос к приводу компакт-дисков и проверяется наличие в нем загрузочного диска. Если отсутствует и гибкий, и компакт-диск, система загружается с жесткого диска. С загрузочного устройства в память считывается первый сектор, а затем выполняется записанная в нем программа. Обычно эта программа проверяет таблицу разделов, которая находится в конце загрузочного сектора, чтобы определить, какой из разделов имеет статус активного. Затем из этого раздела считывается вторичный загрузчик, который в свою очередь считывает из активного раздела и запускает операционную систему.
После этого операционная система запрашивает BIOS, чтобы получить информацию о конфигурации компьютера. Для каждого устройства она проверяет наличие драйвера.
Как только в ее распоряжении окажутся все драйверы устройств, операционная система загружает их в ядро. Затем она создает все необходимые ей фоновые процессы и запускает программу входа в систему или графический интерфейс пользователя.
Тема 4. Основные понятия операционной системы
1. Ресурс.
2. Процесс.
3. Системный вызов.
4. Прерывание.
5. Исключительная ситуация.
6. Файлы.
Ресурсы
Ресурс – любой потребляемый (расходуемый) объект, средство вычислительной системы, которое может быть выделено процессу на определенный интервал времени. Основные ресурсы компьютера – это его аппаратура, т. е. процессор, ОЗУ, периферийные устройства.
ОС упрощает доступ пользователя к ресурсам и распределяет ресурсы между конкурирующими за них процессами.
В отношении каждого ресурса предполагается выполнение трех действий:
1) Запрос
2) Использование
3) Освобождение
При выполнении действия запрос в ответ на требование процесса-пользователя система выделяет ресурс или отказывает в выделении (если ресурс занят).
Если после выполнения действия запрос ресурс дан процессу (становится занят), то процесс может его использовать. Выполняется действия использование .
Действие освобождение выполняется по требованию процесса и сводится к переводу ресурса в свободное состояние.
Классификация ресурсов
По реальности существования
Физический ресурс – это ресурс, который реально существует и при распределении его между пользователями обладает всеми присущими ему физическими характеристиками. Пример : все аппаратные ресурсы.
Виртуальный ресурс – это некоторая модель конкретного физического ресурса. Виртуальный ресурс может предоставить пользователю при работе с ним не только часть тех свойств, которые присущи объекту моделирования (физическому ресурсу), но и свойства, которые ему не присущи. Такими дополнительными свойствами ресурс не обладает, но пользователь вправе утверждать обратное, т. к. он имеет дело не с физическим, а с виртуальным ресурсом, хотя и не подозревает этого. Пример : виртуальная память.
По возможности расширения свойств
Этот признак характеризует ресурс с точки зрения возможности построения на его основе некоторого виртуального ресурса.
Эластичный ресурс – это физический ресурс, который допускает виртуализацию (воспроизведение или расширение своих свойств). Пример : оперативная память, свойства которой реализуются в виртуальной памяти.
Жесткий ресурс – физический ресурс, который по своим внутренним свойствам не допускает виртуализации. Пример : процессор.
По степени активности
Активный ресурс – это ресурс, который может выполнять действия по отношению к другим ресурсам (в том числе и себя самого) или по отношению к процессам (при этом происходит изменение процессов). Пример – процессор.
Пассивный ресурс – это ресурс, над которым можно производить допустимые для него действия. Эти действия могут привести к изменению его состояния, его внутренних и внешних характеристик. Пример : область памяти, выделяемая по требованию, т. к. над этой областью можно выполнять операции считывания и записи информации.
По времени существования
Постоянный ресурс – это ресурс, который существует в системе на протяжении всего времени существования некоторого процесса. Пример : звуковая карта во время воспроизведения аудиофайла.
Временный ресурс – это ресурс, который может появляться или уничтожаться в системе в течение времени существования некоторого процесса. Пример : диск-оригинал при копировании дисков, он может не использоваться в процессе, т. к. копирование выполняется через буфер, которым могут выступать жесткий диск или оперативная память.
Понятия постоянности и временности ресурсов считаются относительными, т. е. ресурсы, которые являются постоянными для одних процессов, могут быть временными для других процессов и наоборот.
По степени важности
Главный ресурс (по отношению к конкретному процессу) – это ресурс, без выделения которого процесс не может развиваться. Пример : диск-копия при копировании дисков.
Второстепенный ресурс (по отношению к конкретному процессу) – это ресурс, который без его выделения допускает альтернативное развитие некоторого процесса. Пример – оперативная память при копировании дисков.
По функциональной избыточности
ресурсы делятся на дорогие и дешевые . В большинстве случаев цена за использование ресурсов при выполнении процесса является зависимой от времени . Чаще всего система предлагает различные условия использования одного и того же ресурса, или предлагает альтернативные ресурсы. В таких случаях перед пользователем стоит выбор – получить быстро требуемый ресурс и дорого заплатить за такую услугу или подождать выделения ресурса и после его использования заплатить дешево. При наличии в системе альтернативных ресурсов водятся разные цены за их использование. Например , в системе имеется несколько трансляторов с одного и того же языка программирования, которые отличаются по времени счета или по занимаемой памяти по отношению к транслируемой программе. Из-за этих различий трансляторов возникает различие и в их цене.
По структуре
Простой ресурс – это ресурс, который не содержит составных элементов и рассматривается при распределении как единое целое. Этот ресурс может быть либо занят, либо свободен. Пример : дисковод.
Составной ресурс – это ресурс, который содержит в своем составе ряд однотипных элементов, обладающих с точки зрения пользователей одинаковыми характеристиками. Этот ресурс может быть либо занят (используются все составные части), либо свободен (ни одна составная часть не используется), либо частично занят (не все части используются). Пример : оперативная память.
VIII. По восстанавливаемости
Воспроизводимый ресурс – это ресурс, при распределении которого допускается многократное выполнение действий в следующей последовательности: ЗАПРОС – ИСПОЛЬЗОВАНИЕ – ОСВОБОЖДЕНИЕ. Пример : оперативная память.
Потребляемый ресурс – это ресурс, отношении которого выполняются действия в последовательности: ОСВОБОЖДЕНИЕ – ЗАПРОС – ИСПОЛЬЗОВАНИЕ. Пример : диск при записи на него данных.
По характеру использования
Последовательно используемый – это ресурс, в отношении которого каждым процессом-потребителем допустимо строго последовательное во времени выполнение цепочек действий «ЗАПРОС – ИСПОЛЬЗОВАНИЕ - ОСВОБОЖДЕНИЕ». Пример : диск во время записи на него файлов.
Параллельно используемый – это ресурс, который предполагает одновременное его использование более чем одним процессом. Пример : оперативная память.
Процессы
Понятие «вычислительный процесс » (или просто – процесс ) является одним из основных прирассмотрении операционных систем. Под процессом обычно понимается последовательность операций при выполнении программы или ее части в совокупности с используемыми данными. В общем случае процесс и программа представляют собой разные понятия. Программа– это план действий, а процесс – это само действие, поэтому понятие процесса включает программный код, данные, содержимое стека, содержимое адресного и других регистров процессора. Таким образом, для одной программы могут быть созданы несколько процессов в том случае, если с помощью одной программы в центральном процессоре вычислительной машины выполняется несколько несовпадающих последовательностей команд. Например, 2 студента запускают программу извлечения квадратного корня. Один хочет вычислить корень из 4, а второй – из 1. С точки зрения студентов, запущена одна и та же программа; с точки зрения компьютерной системы, ей приходится заниматься 2-мя различными вычислительными процессам, т. К. разные исходные данные приводят к разным наборам вычислений.
С каждым процессом связано его адресное пространство — список адресов ячеек памяти от нуля и до некоторого максимума, откуда процесс может считывать и куда записывает данные. Адресное пространство содержит выполняемую программу, данные этой программы и ее стек.
Кроме этого, с каждым процессом связан определенный набор ресурсов , который обычно включает регистры (в том числе счетчик команд и указатель стека), список открытых файлов, необработанные предупреждения, список связанных процессов и всю остальную информацию, необходимую в процессе работы программы. Таким образом, процесс — это контейнер, в котором содержится вся информация, необходимая для работы программы.
Состояния процесса
Все, что выполняется в вычислительных системах, организовано как набор процессов. Понятно, что реально на однопроцессорной компьютерной системе в каждый момент времени может исполняться только один процесс. Для мультипрограммных вычислительных систем псевдопараллельная обработка нескольких процессов достигается с помощью переключения процессора с одного процесса на другой. Пока один процесс выполняется, остальные ждут своей очереди. Таким образом, каждый процесс может находиться как минимум в 2-х состояниях: процесс исполняется и процесс не исполняется .
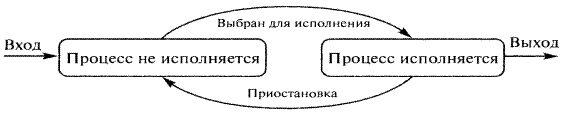
Рис 6 – Простейшая диаграмма состояний процесса
Процесс, находящийся в состоянии процесс исполняется , через некоторое время может быть завершен операционной системой или приостановлен и снова переведен в состояние процесс не исполняется . Приостановка процесса происходит по двум причинам: для его дальнейшей работы потребовалось какое-либо событие (например, завершение операции ввода-вывода) или истек временной интервал, отведенный операционной системой для работы данного процесса. После этого операционная система по определенному алгоритму выбирает для исполнения один из процессов, находящихся в состоянии процесс не исполняется, и переводит его в состояние процесс исполняется . Новый процесс, появляющийся в системе, первоначально помещается в состояние процесс не исполняется.
Это очень грубая модель, она не учитывает, в частности, то, что процесс, выбранный для исполнения, может все еще ждать события, из-за которого он был приостановлен, и реально к выполнению не готов. Для того чтобы избежать такой ситуации, разобьем состояние процесс не исполняется на два новых состояния: готовность и ожидание (рис. 7).

Рис. 7. Более подробная диаграмма состояний процесса
Всякий новый процесс, появляющийся в системе, попадает в состояние готовность . Операционная система, пользуясь каким-либо алгоритмом планирования, выбирает один из готовых процессов и переводит его в состояние исполнение . В состоянии исполнение происходит непосредственное выполнение программного кода процесса. Выйти из этого состояния процесс может по трем причинам:
· операционная система прекращает его деятельность;
· он не может продолжать свою работу, пока не произойдет некоторое событие, и операционная система переводит его в состояние ожидание ;
· в результате возникновения прерывания в вычислительной системе (например, прерывания от таймера по истечении предусмотренного времени выполнения) его возвращают в состояние готовность .
Из состояния ожидание процесс попадает в состояние готовность после того, как ожидаемое событие произошло, и он снова может быть выбран для исполнения.
Наша новая модель хорошо описывает поведение процессов во время их существования, но она не акцентирует внимания на появлении процесса в системе и его исчезновении. Для полноты картины нам необходимо ввести еще два состояния процессов: рождение и закончил исполнение (рис. 8).

Рис. 8. Диаграмма состояний процесса, принятая в курсе
Теперь для появления в вычислительной системе процесс должен пройти через состояние рождение . При рождении процесс получает в свое распоряжение адресное пространство , в которое загружается программный код процесса; ему выделяются стек и системные ресурсы; устанавливается начальное значение программного счетчика этого процесса и т. д. Родившийся процесс переводится в состояние готовность . При завершении своей деятельности процесс из состояния исполнение попадает в состояние закончил исполнение .
В конкретных операционных системах состояния процесса могут быть еще более детализированы, могут появиться некоторые новые варианты переходов из одного состояния в другое. Так, например, модель состояний процессов для операционной системы Windows NT содержит 7 различных состояний, а для операционной системы Unix — 9. Тем не менее, все операционные системы подчиняются изложенной выше модели.
Итак, выделим 5 состояний процесса:
1. Рождение.
2. Готовность.
3. Ожидание.
4. Исполнение.
5. Закончил исполнение.
При рождении процесс получает в свое распоряжение адресное пространство, в которое загружается программный код процесса; ему выделяются стек и системные ресурсы; устанавливается начальное значение программного счетчика этого процесса и т. д
Родившийся процесс переводится в состояние готовность .
Операционная система, пользуясь каким-либо алгоритмом планирования, выбирает один из готовых процессов и переводит его в состояние исполнение . В этом состоянии происходит непосредственное выполнение программного кода процесса. Выйти из этого состояния процесс может по трем причинам:
· операционная система прекращает его деятельность;
· он не может продолжать свою работу, пока не произойдет некоторое событие, и операционная система переводит его в состояние ожидание ;
· в результате возникновения прерывания в вычислительной системе (например, прерывания от таймера по истечении предусмотренного времени выполнения) его возвращают в состояние готовность .
Из состояния ожидание процесс попадает в состояние готовность после того, как ожидаемое событие произошло, и он снова может быть выбран для исполнения.
При завершении своей деятельности процесс из состояния исполнение попадает в состояние закончил исполнение.
Важнейшей частью операционной системы, непосредственно влияющей на функционирование вычислительной машины, является подсистема управления процессами . Для операционной системы процесс представляет собой единицу работы, заявку на потребление системных ресурсов. Подсистема управления процессами планирует выполнение процессов, то есть распределяет процессорное время между несколькими одновременно существующими в системе процессами, а также занимается созданием и уничтожением процессов, обеспечивает процессы необходимыми системными ресурсами, поддерживает взаимодействие между процессами.
Изменяя состояния процессов, ОС выполняет следующие операции:
1) создание процесса;
2) завершение процесса;
3) приостановка процесса (перевод из состояния исполнение в состояние готовность);
4) запуск процесса (перевод из состояния готовность в состояние исполнение);
5) блокирование процесса (перевод из состояния исполнение в состояние ожидание);
6) разблокирование процесса (перевод из состояния ожидание в состояние готовность);
7) изменение приоритета процесса.
Операции создания и завершения процесса являются одноразовыми, так как применяются к процессу не более одного раза (некоторые системные процессы при работе вычислительной системы не завершаются никогда). Все остальные операции, связанные с изменением состояния процессов, будь то запуск или блокировка, как правило, являются многоразовыми.
Планирование процессов
Когда компьютер работает в многозадачном режиме, на нем зачастую запускается сразу несколько процессов или потоков, претендующих на использование центрального процессора. Такая ситуация складывается в том случае, если в состоянии готовности одновременно находятся два или более процесса или потока. Если доступен только один центральный процессор, необходимо выбрать, какой из этих процессов будет выполняться следующим.
Планирование - обеспечение поочередного доступа процессов к одному процессору. Та часть операционной системы, на которую возложено планирование , называется планировщиком , а алгоритм, который ею используется, называется алгоритмом планирования .
Планировщик может принимать решения о выборе для исполнения нового процесса из числа находящихся в состоянии готовность в следующих четырех случаях.
1. Когда процесс переводится из состояния исполнение в состояние закончил исполнение . Процесс больше не может выполняться (поскольку он уже не существует), поэтому нужно выбрать какой-нибудь процесс из числа готовых к выполнению. Если готовые к выполнению процессы отсутствуют, обычно запускается предоставляемый системой холостой процесс.
2. Когда процесс переводится из состояния исполнение в состояние ожидание . Процесс больше не может выполняться (т. к. ждет какое-то событие), поэтому надо выбрать на выполнение некоторый готовый процесс.
3. Когда процесс переводится из состояния исполнение в состояние готовность (например, после прерывания от таймера). Планировщик должен решить, какой процесс ему запускать: тот, что только что перешел в состояние готовности, тот, который был запущен за время прерывания, или какой-нибудь третий процесс.
4. Когда процесс переводится из состояния ожидание в состояние готовность (завершилась операция ввода-вывода или произошло другое событие). Планировщик должен решить, какой процесс ему запускать: тот, что только что перешел в состояние готовности, тот, который был запущен за время ожидания, или какой-нибудь третий процесс.
В случаях 1 и 2 процесс, находившийся в состоянии исполнение , не может дальше исполняться, и операционная система вынуждена осуществлять планирование, выбирая новый процесс для выполнения.
В случаях 3 и 4 планирование может как проводиться, так и не проводиться, планировщик не вынужден обязательно принимать решение о выборе процесса для выполнения, процесс, находившийся в состоянии исполнение может просто продолжить свою работу.
Если в операционной системе планирование осуществляется только в вынужденных ситуациях, говорят, что имеет место невытесняющее планирование ( неприоритетный алгоритм) . При таком режиме планирования процесс занимает столько процессорного времени, сколько ему необходимо. При этом переключение процессов возникает только при желании самого исполняющегося процесса передать управление (для ожидания завершения операции ввода-вывода или по окончании работы). Этот метод планирования относительно просто реализуем и достаточно эффективен, так как позволяет выделить большую часть процессорного времени для работы самих процессов и до минимума сократить затраты на переключение контекста. Однако при невытесняющем планировании возникает проблема возможности полного захвата процессора одним процессом, который вследствие каких-либо причин (например, из-за ошибки в программе) зацикливается и не может передать управление другому процессу. В такой ситуации спасает только перезагрузка всей вычислительной системы.
Если планировщик принимает и вынужденные, и невынужденные решения, говорят о вытесняющем планировании ( приоритетный алгоритм) . Термин "вытесняющее планирование" возник потому, что исполняющийся процесс помимо своей воли может быть вытеснен из состояния исполнение другим процессом. Вытесняющее планирование обычно используется в системах разделения времени. В этом режиме планирования процесс может быть приостановлен в любой момент исполнения. Операционная система устанавливает специальный таймер для генерации сигнала прерывания по истечении некоторого интервала времени – кванта. После прерывания процессор передается в распоряжение следующего процесса. Временные прерывания помогают гарантировать приемлемое время отклика процессов для пользователей, работающих в диалоговом режиме, и предотвращают "зависание" компьютерной системы из-за зацикливания какой-либо программы.
Неудивительно, что в различных условиях окружающей среды требуются разные алгоритмы планирования. Это обусловлено тем, что различные сферы приложений (и разные типы операционных систем) предназначены для решения разных задач. Иными словами, предмет оптимизации для планировщика не может совпадать во всех системах. При этом стоит различать три среды:
1) пакетную;
2) интерактивную;
3) реального времени.
В пакетных системах не бывает пользователей, терпеливо ожидающих за своими терминалами быстрого ответа на свой короткий запрос. Поэтому для них зачастую приемлемы неприоритетные алгоритмы или приоритетные алгоритмы с длительными периодами для каждого процесса. Такой подход сокращает количество переключений между процессами, повышая при этом производительность работы системы. Пакетные алгоритмы носят весьма общий характер и часто находят применение также и в других ситуациях, поэтому их стоит изучить даже тем, кто не работает в сфере корпоративных вычислений с использованием универсальных машин.
В среде с пользователями, работающими в интерактивном режиме, приобретает важность приоритетность, сдерживающая отдельный процесс от захвата центрального процессора, лишающего при этом доступа к службе всех других процессов. Даже при отсутствии процессов, склонных к бесконечной работе, один из процессов в случае программной ошибки мог бы навсегда закрыть доступ к работе всем остальным процессам. Для предупреждения такого поведения необходимо использование приоритетного алгоритма. Под эту категорию подпадают и серверы, поскольку они, как правило, обслуживают нескольких вечно спешащих (удаленных) пользователей.
В системах, ограниченных условиями реального времени, как ни странно, приоритетность иногда не требуется, поскольку процессы знают, что они могут запускаться только на непродолжительные периоды времени, и зачастую выполняют свою работу довольно быстро, а затем блокируются. В отличие от интерактивных систем в системах реального времени запускаются лишь те программы, которые предназначены для содействия определенной прикладной задаче. Интерактивные системы имеют универсальный характер и могут запускать произвольные программы, которые не выполняют совместную задачу или даже вредят друг другу.
Задачи алгоритма планирования
Чтобы создать алгоритм планирования, нужно иметь некое представление о том, с чем должен справиться толковый алгоритм. Некоторые задачи зависят от среды окружения (пакетная, интерактивная или реального времени), но есть и такие задачи, которые желательно выполнить в любом случае. Вот некоторые задачи алгоритма планирования, которых следует придерживаться при различных обстоятельствах, и которые нам вскоре предстоит рассмотреть:
Все системы
1) Равнодоступность — предоставление каждому процессу справедливой доли времени центрального процессора (несправедливо предоставлять одному процессу больше времени центрального процессора, чем другому, эквивалентному ему процессу).
2) Принуждение к определенной политике — наблюдение за выполнением установленной политики (если локальная политика заключается в том, что процессы, контролирующие безопасность, должны получать возможность возобновления своей работы сразу же, как только в этом возникнет необходимость, даже если при этом расчет заработной платы задержится на полминуты, планировщик должен обеспечить осуществление этой политики).
3) Баланс — поддержка загруженности всех составных частей системы (если центральный процессор и все устройства ввода-вывода смогут быть постоянно задействованы, то будет произведен больший объем работы в секунду, чем при простое каких-нибудь компонентов).
Пакетные системы
1) Производительность — выполнение максимального количества заданий в час.
2) Оборотное время — минимизация времени между представлением задачи и ее завершением.
3) Использование центрального процессора — поддержка постоянной загруженности процессора.
Интерактивные системы
1) Время отклика — быстрый ответ на запросы.
2) Пропорциональность — оправдание пользовательских надежд (пользователям свойственно прикидывать (и зачастую неверно) продолжительность тех или иных событий. Когда запрос, рассматриваемый как сложный, занимает довольно продолжительное время, пользователь воспринимает это как должное, но когда запрос, считающийся простым, также занимает немало времени, пользователь выражает недовольство.).
Системы реального времени
Они характеризуются наличием крайних сроков выполнения, которые обязательно или, по крайней мере, желательно должны быть выдержаны. Например, если компьютер управляет устройством, которое выдает данные с определенной скоростью, отказ от запуска процесса сбора данных может привести к потере информации. Поэтому самым главным требованием в системах реального времени является соблюдение всех (или большей части) крайних сроков.
1) Соблюдение предельных сроков — предотвращение потери данных.
2) Предсказуемость — предотвращение ухудшения качества в мультимедийных системах. В некоторых системах реального времени, особенно в мультимедийных системах, существенную роль играет предсказуемость. Редкие случаи несоблюдения крайних сроков не приводят к сбоям, но если аудиопроцесс прерывается довольно часто, то качество звука резко ухудшается. Это относится и к видеопроцессам, но человеческое ухо более чувствительно к случайным искажениям, чем глаз. Чтобы избежать подобной проблемы, планирование процессов должно быть исключительно предсказуемым и постоянным.
Алгоритмы планирования
Планирование в пакетных системах
1) «Первый пришел - первым обслужен» (FIFO - First In Fist Out)
Простейший неприоритетный алгоритм.
Процессор выделяется процессам в порядке поступления их запросов. По сути, используется одна очередь процессов, находящихся в состоянии готовности. Когда рано утром в систему извне попадает первое задание, оно тут же запускается на выполнение и получает возможность выполняться как угодно долго. Оно не прерывается по причине слишком продолжительного выполнения. По мере поступления других заданий они помещаются в конец очереди. При блокировке выполняемого процесса следующим запускается первый процесс, стоящий в очереди. Когда заблокированный процесс переходит в состояние готовности, он, подобно только что поступившему заданию, помещается в конец очереди.
Достоинства: простота, справедливость.
Недостатки: среднее время ожидания и среднее полное время выполнения для этого алгоритма существенно зависят от порядка расположения процессов в очереди. Если у нас есть процесс с длительным временем выполнения, то короткие процессы, перешедшие в состояние готовность после длительного процесса, будут очень долго ждать начала выполнения.
Пример . Пусть в состоянии готовность находятся три процесса p1 , p2 и p3 , для которых известны времена их выполнения в некоторых условных единицах:
Таблица 1
| Процесс | Время выполнения |
| P1 | 13 |
| P2 | 4 |
| P3 | 1 |
Для простоты будем полагать, что вся деятельность процессов ограничивается использованием только одного промежутка времени, что процессы не совершают операций ввода-вывода и что время переключения между процессами так мало, что им можно пренебречь.
Если процессы расположены в очереди процессов, готовых к исполнению, в порядке p1 , p2, p3, то картина их выполнения выглядит так, как показано на рис. 9.
![]()
|


Рис. 9. Выполнение процессов в порядке p1 , p2, p3
Первым для выполнения выбирается процесс p1 , который получает процессор на все время своего выполнения, т. е. на 13 единиц времени. После его окончания в состояние исполнение переводится процесс p2 , он занимает процессор на 4 единицы времени. И, наконец, возможность работать получает процесс p3 .
Время ожидания для процесса p1 составляет 0 единиц времени, для процесса p2 – 13 единиц, для процесса p3 – 13 + 4 = 17 единиц. Таким образом, среднее время ожидания в этом случае – (0 + 13 + 17)/3 = 10 единиц времени.
Полное время выполнения для процесса p1 составляет 13 единиц времени, для процесса p2 – 13 + 4 = 17 единиц, для процесса p3 – 13 + 4 + 1 = 18 единиц. Среднее полное время выполнения оказывается равным (13 + 17 + 18)/3 = 16 единицам времени.
Если те же самые процессы расположены в порядке p3 , p2, p1 , то картина их выполнения будет соответствовать рис. 10.
![]()
|
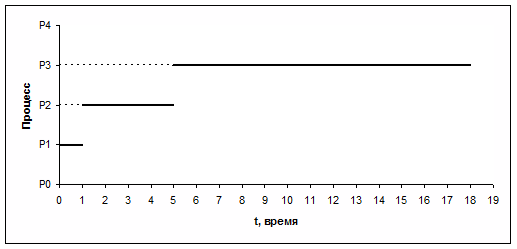

Рис. 10. Выполнение процессов в порядке p3 , p2, p1
Время ожидания для процесса p1 равняется 5 единицам времени, для процесса p2 – 1 единице, для процесса p3 – 0 единиц. Среднее время ожидания составит (5 + 1 + 0)/3 = 2 единицы времени. Это в 5 раз меньше, чем в предыдущем случае.
Полное время выполнения для процесса p1 получается равным 18 единицам времени, для процесса p2 – 5 единицам, для процесса p3 – 1 единице. Среднее полное время выполнения составляет (18 + 5 + 1)/3 = 8 единиц времени, что почти в 2 раза меньше, чем при первой расстановке процессов.
2) «Кратчайшее задание – первое»
Неприоритетный алгоритм для пакетных систем, в котором предполагается, что сроки выполнения заданий известны заранее. Когда в ожидании запуска во входящей очереди находится несколько равнозначных по важности заданий, планировщик выбирает сначала самое короткое задание.
Рассмотрим изображение, приведенное на рис. 11,а. Здесь представлены четыре задания: А, В, С, D сo сроками выполнения 8,4,4 и 4 минуты соответственно. Если их запустить в этом порядке, оборотное время для задания А составит 8 мин, для В — 12 мин, для С — 16 мин и для D — 20 мин, при среднем времени 14 мин.
Теперь рассмотрим запуск этих четырех заданий, когда первым запускается самое короткое из них, как показано на рис. 11,б. Теперь показатели оборотного времени составляют 4, 8,12 и 20 мин при среднем времени 11 мин.

Рис. 11. Пример планирования, когда первым выполняется самое короткое задание
Следует заметить, что алгоритм, основанный на выполнении первым самого короткого задания, прост только в том случае, если все задания доступны одновременно.
Пример : возьмем ряд процессов p1 , p2 , p3 и p4 с различными временами выполнения и различными моментами их появления в очереди процессов, готовых к исполнению (таблица 2).
Таблица 2
| Процесс | Время появления | Время выполнения |
| P1 | 0 | 6 |
| P2 | 2 | 2 |
| P3 | 6 | 7 |
| P4 | 0 | 5 |
В начальный момент времени в состоянии готовность находятся только два процесса, p1 и p4 . Меньшее время выполнения оказывается у процесса p4 , поэтому он и выбирается для исполнения. По прошествии 2 единиц времени в систему поступает процесс p2 . Время его выполнения меньше, чем остаток продолжительности у процесса p4 , который вытесняется из состояния исполнение и переводится в состояние готовность. По прошествии еще 2 единиц времени процесс p2 завершается, и для исполнения вновь выбирается процесс p4 . В момент времени t = 6 в очереди процессов, готовых к исполнению, появляется процесс p3 , но поскольку ему для работы нужно 7 единиц времени, а процессу p4 осталось трудиться всего 1 единицу времени, то процесс p4 остается в состоянии исполнение. После его завершения в момент времени t = 7 в очереди находятся процессы p1 и p3 , из которых выбирается процесс p1 . Наконец, последним получит возможность выполняться процесс p3 .
Время ожидания для процесса p1 составляет 7 единиц времени, для процесса p2 – 0 единицы, для процесса p3 – 7единиц, p4 - 2. Таким образом, среднее время ожидания в этом случае – 4 единиц времени.
Полное время выполнения для процесса p1 составляет 13 единиц времени, для процесса p2 – 2 единицы, для процесса p3 – 14 единиц, р4 – 7 единиц. Среднее полное время выполнения оказывается равным 9 единицам времени.
![]()
Рис. 12. Диаграмма процессов с учетом времени появления
3) Приоритет наименьшему оставшемуся времени выполнения
Это версия алгоритма выполнения первым самого короткого задания.
При использовании этого алгоритма планировщик всегда выбирает процесс с самым коротким оставшимся временем выполнения. Здесь, так же как и прежде, время выполнения заданий нужно знать заранее. При поступлении нового задания выполняется сравнение общего времени его выполнения с оставшимися сроками выполнения текущих процессов. Если для выполнения нового задания требуется меньше времени, чем для завершения текущего процесса, этот процесс приостанавливается и запускается новое здание. Эта схема позволяет быстро обслужить новое короткое задание.
Планирование в интерактивных системах
1) Циклическое планирование
Одним из самых старых, простых, справедливых и наиболее используемых алгоритмов.
Каждому процессу назначается определенный интервал времени, называемый его квантом , в течение которого ему предоставляется возможность выполнения.
Процессы сидят на карусели. Карусель вращается так, что каждый процесс находится около процессора в течение кванта времени. Пока процесс находится рядом с процессором, он получает процессор в свое распоряжение и может исполняться (рис. 13).
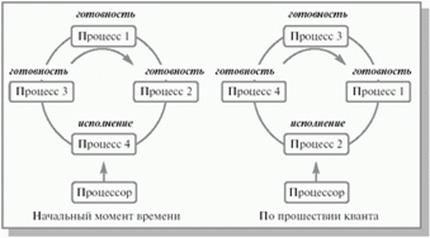
Рис. 13. Процессы на карусели
Планировщик выбирает для очередного исполнения процесс, расположенный в начале очереди. При выполнении процесса возможны два варианта:
- Продолжительность процесса меньше или равна кванта времени. Тогда процесс сам освобождает процессор до истечения кванта времени, на исполнение поступает новый процесс из начала очереди, и отсчет кванта начинается заново.
- Продолжительность процесса больше, чем квант времени. Тогда по истечении этого кванта процесс прерывается и помещается в конец очереди процессов, готовых к исполнению, а процессор выделяется для использования процессу, находящемуся в ее начале.
Пример . Пусть в состоянии готовность находятся три процесса p1 , p2 и p3 , для которых известны времена их выполнения в некоторых условных единицах:
Таблица 3
| Процесс | Время выполнения |
| P1 | 13 |
| P2 | 4 |
| P3 | 1 |
Пусть процессы подвергаются циклическому планированию с величиной кванта 4 мс.
Первым для исполнения выбирается процесс p1 . Продолжительность его больше, чем величина кванта времени, и поэтому процесс исполняется до истечения кванта, т. е. в течение 4 единиц времени. После этого он помещается в конец очереди готовых к исполнению процессов, которая принимает вид p2 , p3 , p1 .
Следующим начинает выполняться процесс p2 . Время его исполнения совпадает с величиной выделенного кванта, поэтому процесс работает до своего завершения. Теперь очередь процессов в состоянии готовность состоит из двух процессов, p3 и p1 .
Процессор выделяется процессу p3. Он завершается до истечения отпущенного ему процессорного времени, и очередные кванты отмеряются процессу p0 – единственному не закончившему к этому моменту свою работу.
Время ожидания для процесса p1 составляет 5 единиц времени, для процесса p2 – 4 единицы времени, для процесса p3 – 8 единиц времени. Таким образом, среднее время ожидания для этого алгоритма получается равным (5 + 4 + 8)/3 = 5,6(6) единицы времени.
Полное время выполнения для процесса p1 составляет 18 единиц времени, для процесса p2 – 8 единиц, для процесса p3 – 9 единиц. Среднее полное время выполнения оказывается равным (18 + 8 + 9)/3 = 11,6(6) единицы времени.
![]()
![]()
Рис. 14. Диаграмма процессов при циклическом планировании
На производительность циклического алгоритма сильно влияет величина кванта времени. Рассмотрим тот же самый пример с порядком процессов p1 , p2 , p3 для величины кванта времени, равной 1. Время ожидания для процесса p1 составит 5 единиц времени, для процесса p2 – тоже 5 единиц, для процесса p3 – 2 единицы. В этом случае среднее время ожидания получается равным (5 + 5 + 2)/3 = 4 единицам времени. Среднее полное время исполнения составит (18 + 9 + 3)/3 = 10 единиц времени.
2) Приоритетное планирование
Каждому процессу присваивается определенное числовое значение – приоритет , в соответствии с которым ему выделяется процессор. Процессы с одинаковыми приоритетами планируются в порядке FIFO. Для алгоритма «Кратчайшее задание - первое» в качестве такого приоритета выступает продолжительности процесса. Чем меньше значение продолжительности, тем более высокий приоритет имеет процесс.
Планирование с использованием приоритетов может быть как вытесняющим , так и невытесняющим .
При вытесняющем планировании процесс с более высоким приоритетом, появившийся в очереди готовых процессов, вытесняет исполняющийся процесс с более низким приоритетом.
В случае невытесняющего планирования он просто становится в начало очереди готовых процессов. Давайте рассмотрим примеры использования различных режимов приоритетного планирования.
Пример . Пусть в очередь процессов, находящихся в состоянии готовность, поступают те же процессы, что и в примере для вытесняющего алгоритма «Кратчайшее задание - первое», только им дополнительно еще присвоены приоритеты (см. табл. 4). В вычислительных системах не существует определенного соглашения, какое значение приоритета – 1 или 4 считать более приоритетным. Во избежание путаницы, во всех наших примерах мы будем предполагать, что большее значение соответствует меньшему приоритету, т. е. наиболее приоритетным в нашем примере является процесс p4 , а наименее приоритетным – процесс p1 .
Таблица 4
| Процесс | Время появления | Время выполнения | Приоритет |
| P1 | 0 | 6 | 4 |
| P2 | 2 | 2 | 3 |
| P3 | 6 | 7 | 2 |
| P4 | 0 | 5 | 1 |
Как будут вести себя процессы при использовании невытесняющего приоритетного планирования?
Первым для выполнения в момент времени t = 0 выбирается процесс p4 , как обладающий наивысшим приоритетом. После его завершения в момент времени t = 5 в очереди процессов, готовых к исполнению, окажутся два процесса p1 и p2 . Больший приоритет из них у процесса p2 , он и начнет выполняться. Затем в момент времени t = 7 для исполнения будет избран процесс p3 , и лишь потом – процесс p1 .
![]()
![]()
Рис. 15. Диаграмма процессов при невытесняющем приоритетном планировании
Иным будет предоставление процессора процессам в случае вытесняющего приоритетного планирования. Первым, как и в предыдущем случае, начнет исполняться процесс p4 , а по его окончании – процесс p2 . Однако в момент времени t = 6 он будет вытеснен процессом p3 и продолжит свое выполнение только в момент времени t = 13. Последним, как и раньше, будет исполняться процесс p1 (рис. 16).
![]()
![]()
Рис. 16. Диаграмма процессов при вытесняющем приоритетном планировании
Планирование в системах реального времени
Внешние события, на которые система реального времени должна реагировать, можно разделить на периодические
(возникающие через регулярные промежутки времени) и непериодические
(возникающие непредсказуемо). Возможно наличие нескольких потоков событий, которые система должна обрабатывать. В зависимости от времени, затрачиваемого на обработку каждого из событий, может оказаться, что система не в состоянии своевременно обработать все события. Если в систему поступает m
периодических событий, событие с номером i
поступает с периодом ![]() и на его обработку уходит
и на его обработку уходит ![]() секунд работы процессора, все потоки могут быть своевременно обработаны только при выполнении условия:
секунд работы процессора, все потоки могут быть своевременно обработаны только при выполнении условия:![]() (k
– количество доступных процессоров). Система реального времени, удовлетворяющая этому условию, называется поддающейся планированию
или планируемой.
(k
– количество доступных процессоров). Система реального времени, удовлетворяющая этому условию, называется поддающейся планированию
или планируемой.
Соотношение ![]() является просто частью процессорного времени
, используемого процессом i
, а сама сумма – это коэффициент использования (или коэффициент загруженности
) процессора, который, естественно, не может быть больше 1.
является просто частью процессорного времени
, используемого процессом i
, а сама сумма – это коэффициент использования (или коэффициент загруженности
) процессора, который, естественно, не может быть больше 1.
Алгоритмы планирования заданий могут быть разделены на статические и динамические .
Статические алгоритмы определяют приемлемый план выполнения заданий по их априорным характеристикам, динамический алгоритм модифицирует план во время исполнения заданий. Издержки на статическое планирование низки, но оно крайне нечувствительно и требует полной предсказуемости той системы реального времени, на которой оно установлено.
Динамическое планирование связано с большими издержками, но способно адаптироваться к меняющемуся окружению.
Пример : Алгоритмы планирования будем рассматривать на примере 3 периодических процессов A, B, C. Предположим, что процесс A запускается с периодом 30 мс и временем обработки 10 мс. Процесс B имеет период 40 мс и время обработки 15 мс. Процесс C запускается каждые 50 мс и обрабатывается за 5 мс. Суммарно эти процессы потребляют 0,808 процессорного времени, что меньше единицы. Соответственно, система в данном примере поддается планированию.
На рис. 16 представлена временная диаграмма работы процессов. Видно, что необходимо применить некоторый алгоритм планирования, так как в определенные моменты времени имеется сразу несколько готовых к выполнению процессов.

Рис. 16. Три периодических процесса с разным периодом и временем обработки
Классическим примером статического алгоритма планирования реального времени для прерываемых периодических процессов является алгоритм RMS (Rate Monotonic Scheduling – планирование с приоритетом, пропорциональным частоте). Этот алгоритм может использоваться для процессов, удовлетворяющих следующим условиям:
1) Каждый периодический процесс должен быть завершен за время его периода
2) Ни один процесс не должен зависеть от любого другого процесса
3) Каждому процессу требуется одинаковое процессорное время на каждом интервале
4) У непериодических процессов нет жестких сроков
5) Прерывание процесса происходит мгновенно, без накладных расходов.
Требование 2 не вполне реалистично, так как на практике разные процессы могут обращаться к одному разделяемому ресурсу и, соответственно, блокироваться. Последнее требование нереально, но вводится для упрощения модели системы.
Алгоритм RMS работает, назначая каждому процессу фиксированный приоритет, обратно пропорциональный периоду и, соответственно, прямо пропорциональный частоте возникновения событий процесса. Например, в примере рис. 16 процесс A запускается каждые 30 мс (33 раза в секунду) и получает приоритет 33. Процесс B запускается каждые 40 мс (25 раз в секунду) и получает приоритет 25. Процесс C запускается каждые 50 мс (20 раз в секунду) и получает приоритет 20. Отметим, что реализация алгоритма требует, чтобы у всех процессов были разные приоритеты.
Во время работы планировщик всегда запускает готовый к работе процесс с наивысшим приоритетом, прерывая при необходимости работающий процесс с меньшим приоритетом. Таким образом, в нашем примере процесс A может прервать процессы B и C, процесс B может прервать C. Процесс C всегда вынужден ждать, пока процессор не освободится.
На рис. 17 показана работа алгоритма планирования для процессов A, B, C.
· Изначально все три процесса готовы к работе.
· Выбирается процесс с максимальным приоритетом – A. Ему разрешается работать в течение 10 мс, требующихся процессу до завершения.
· Когда процесс A освобождает процессор, начинает работать процесс B, а затем процесс C.
· Вместе эти процессы потребляют 30 мс, поэтому, когда процесс C заканчивает работу, снова запускается процесс A.
· Этот цикл повторяется до тех пор, пока в момент времени 70 мс у системы начинается период простоя.
· В момент времени 80 мс процесс B переходит в состояние готовности и запускается.
· Однако в момент времени 90 мс процесс A, обладающий более высоким приоритетом, также переходит в состояние готовности. Поэтому он прерывает выполнение процесса B и работает до момента времени 100 мс, пока не закончит свою работу.
· В этот момент времени система должна выбрать между процессом B, который не закончил обработку, и C, который находится в состоянии готовности. Выбирается процесс B, имеющий больший приоритет.

![]()
Рис. 17. Пример алгоритмов планирования RMS и EDF
Алгоритм RMS может быть использован только при не слишком высокой загруженности процессора. Предположим, что процесс A имеет продолжительность работы не 10 мс, а 15 мс. Коэффициент использования процессора в таком случае равен 0,975. Теоретически для данного случая должен иметься метод планирования. Работа алгоритма показана на рис. 18.
· На этот раз процесс B завершает обработку к моменту времени 30 мс.
· В этот же момент процесс A снова приходит в состояние готовности. К тому времени, когда он заканчивает работу, снова готов процесс B и поскольку у него приоритет больше, чем у C, то запускается процесс B.
· Процесс C пропускает свой критический срок, алгоритм RMS терпит неудачу.

![]()
Рис. 18. Пример, в котором алгоритм RMS не может быть использован
Другим популярным алгоритмом планирования является алгоритм EDF (Earliest Deadline First – процесс с ближайшим сроком завершения в первую очередь). Алгоритм EDF представляет собой динамический алгоритм, не требующий от процессов периодичности. Он также не требует и постоянства временных интервалов использования процессора. Каждый раз, когда процессу требуется процессорное время, он объявляет о своем присутствии и о своем сроке выполнения задания. Планировщик хранит список процессов, сортированный по срокам выполнения заданий. Алгоритм запускает первый процесс в списке, то есть тот, у которого самый близкий по времени срок выполнения. Когда новый процесс переходит в состояние готовности, система сравнивает его срок выполнения со сроком выполнения текущего процесса.
Если у нового процесса график более жесткий, он прерывает работу текущего процесса. Пример работы алгоритма EDF показан на рис. 17.
![]()
· Вначале все процессы находятся в состоянии готовности. Они запускаются в порядке своих крайних сроков.
· Процесс A должен быть выполнен к моменту времени 30, процесс B должен закончить работу к моменту времени 40, процесс C – 50. Таким образом, процесс A запускается первым. Вплоть до момента времени 90 выбор алгоритма EDF не отличается от RMS.
· В момент времени 90 процесс A переходит в состояние готовности с тем же крайним сроком выполнения 120, что и у процесса B.
· Планировщик имеет право выбрать любой из процессов, но поскольку с прерыванием процесса B не связано никаких накладных расходов, лучше предоставить возможность продолжать работу этому процессу.
Рассмотрим рис. 18.
![]()
· В момент времени 30 между процессами A и C возникает спор. Поскольку срок выполнения процесса C равен 50 мс, а процесса A – 60 мс, планировщик выбирает процесс C. Этим данный алгоритм отличается от алгоритма RMS, в котором побеждает процесс A, как обладающий большим приоритетом.
· В момент времени 90 процесс A переходит в состояние готовности в 4 раз. Предельный срок процесса A такой же, что и у текущего процесса, поэтому у планировщика появляется выбор – прервать работу процесса B или нет. Поскольку необходимости прерывать процесс B нет, то он продолжает работу.
· Алгоритм EDF работает с любым набором процессов, для которых возможно планирование. Платой за это является использование более сложного алгоритма.
Решение задач
Задача №7. Пользовательский процесс формирует 1 страницу текста для вывода на принтер, затрачивая на это 200 мс. Формирование новой страницы начинается, если начинает печататься предыдущая страница. Объем буфера равен одной странице. Страница содержит 50 строк текста. Принтер способен напечатать 8 строк за 1 секунду. Будет ли приостанавливаться пользовательский процесс и на какое время? Изменится ли ситуация, если объем буфера будет равен 2 страницам?
1. Определим, сколько времени тратится на печать 1 страницы текста.
8 строк печатается за 1 секунду 50 строк печатается за t секунд |
2. Начинает печататься страница, на это тратится 6250 мс. В это же время начинает формироваться новая строка, на это тратится 200 мс. Прежде, чем приступить к формированию новой строки, процесс должен ждать, пока завершиться печать: 6250-200=6050 мс.
3. Если объем буфера равен 2 страницам, то как только начинает печататься страница, пользовательский процесс формирует 2 строки, на это тратится 400 мс. Затем процесс ждет, пока закончиться печать страницы в течение: 6250-400=5850 мс.
Задача 2. В какой очереди предпочтительней выполнять процессы, если используется алгоритм FIFO: р1, р2, р3, р4 или р4, р2, р1, р3?
| Процесс | Длительность |
| Р1 | 8 |
| Р2 | 2 |
| Р3 | 5 |
| Р4 | 4 |
Данные:
Построим диаграммы процессов для каждой очереди и определим числовые характеристики:
р1, р2, р3, р4
Среднее время ожидания: Среднее время выполнения: |
р4, р2, р1, р3
Среднее время ожидания: Среднее время выполнения: |


Предпочтительней 2-я очередь.
Задача 3. Какой алгоритм предпочтительней использовать для планирования процессов р1, р2, р3, р4: циклический алгоритм с величиной кванта 3 или по кратчайшему времени поступления?
| Процесс | Длительность |
| Р1 | 7 |
| Р2 | 2 |
| Р3 | 5 |
| Р4 | 10 |
Данные:
Построим диаграммы процессов для каждой очереди:
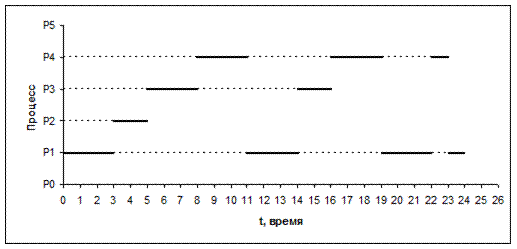
Среднее время ожидания: ![]()
Среднее время выполнения:![]()

Среднее время ожидания: ![]()
Среднее время выполнения:![]()
Задача 4. Определить среднее время ожидания и выполнения процесса. Если используется алгоритм «кратчайшее задание - первое» и известно. Что процессы поступают с интервалом в 2 единицы времени.
| Процесс | Длительность | Время поступления |
| Р1 | 8 | 0 |
| Р2 | 2 | 2 |
| Р3 | 5 | 4 |
| Р4 | 4 | 6 |
Данные:
Построим диаграмму процессов:

Среднее время ожидания: ![]()
Среднее время выполнения:![]()
Задача 5. Построить диаграммы процессов для невытесняющего и вытесняющего приоритетного планирования.
| Процесс | Длительность | Приоритет | Время поступления |
| Р1 | 8 | 4 | 0 |
| Р2 | 5 | 3 | 2 |
| Р3 | 5 | 1 | 4 |
| Р4 | 4 | 2 | 6 |
Данные:
Построим диаграмму процессов для невытесняющего алгоритма:

Построим диаграмму процессов для вытесняющего алгоритма:
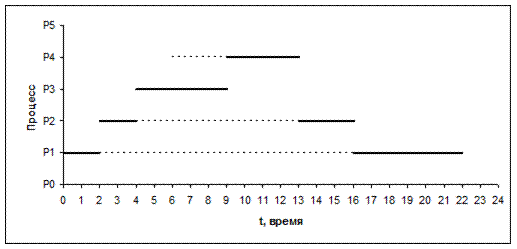
Задача 6. Определить, поддается ли планированию 3-хпроцессорная система реального времени, если известны периоды и времена выполнения процессов:
| Процесс | Период | Время выполнения |
| Р1 | 20 | 10 |
| Р2 | 30 | 15 |
| Р3 | 15 | 5 |
| Р4 | 50 | 20 |
Проверим условие планируемости: ![]() . Значит, система поддается планированию.
. Значит, система поддается планированию.
Задача №6. В систему реального времени поступают 4 периодических процесса с периодами 50, 100, 200, и Х мс. На обработку каждого процесса требуется 35, 20, 10, 15 мс времени процессора. Определить предельное значение Х, при котором система поддается планированию?
Составим условие планируемости:
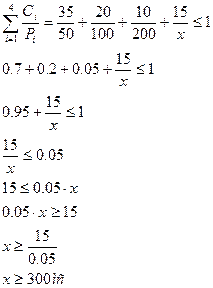
Задача №7. Пользовательский процесс формирует 1 страницу текста для вывода на принтер, затрачивая на это 200 мс. Формирование новой страницы начинается, если начинает печататься предыдущая страница. Объем буфера равен одной странице. Страница содержит 50 строк текста. Принтер способен напечатать 8 строк за 1 секунду. Будет ли приостанавливаться пользовательский процесс и на какое время? Изменится ли ситуация, если объем буфера будет равен 2 страницам?
1. Определим, сколько времени тратится на печать 1 страницы текста.
8 строк печатается за 1 секунду 50 строк печатается за t секунд |
2. Начинает печататься страница, на это тратится 6250 мс. В это же время начинает формироваться новая строка, на это тратится 200 мс. Прежде, чем приступить к формированию новой строки, процесс должен ждать, пока завершиться печать: 6250-200=6050 мс.
3. Если объем буфера равен 2 страницам, то как только начинает печататься страница, пользовательский процесс формирует 2 строки, на это тратится 400 мс. Затем процесс ждет, пока закончиться печать страницы в течение: 6250-400=5850 мс.
Потоки и процессы
Мультипрограммирование , или многозадачность, - это способ организации вычислительного процесса, при котором на одном процессоре попеременно выполняются сразу несколько задач (программ).
Чтобы поддерживать мультипрограммирование, ОС должна определить и оформить для себя те внутренние единицы работы, между которыми будет разделяться процессор и другие ресурсы компьютера. В настоящее время в большинстве операционных систем определены два типа единиц работы.
Более крупная единица работы, обычно носящая название процесса , или задачи, требует для своего выполнения нескольких более мелких работ, для обозначения которых используют термины «поток », или «нить ».
Итак, в чем же состоят принципиальные отличия в понятиях «процесс» и «поток»?
Поток – это объект операционной системы, заключенный в процесс и реализующий какую-либо задачу. Любой процесс содержит несколько потоков (как минимум, один, который называется основным, стандартным.
Если процесс содержит только один поток, то понятия процесса и потока равнозначны.
В операционных системах, где существуют и процессы, и потоки, процесс рассматривается операционной системой как заявка на потребление всех видов ресурсов, кроме одного – процессорного времени. Этот последний важнейший ресурс распределяется операционной системой между другими единицами работы – потоками, которые и получили свое название благодаря тому, что они представляют собой последовательности (потоки выполнения) команд.
В простейшем случае процесс состоит из одного потока, и именно таким образом трактовалось понятие «процесс» до середины 80-х годов (например, в ранних версиях UNIX) и в таком же виде оно сохранилось в некоторых современных ОС. В таких системах понятие «поток» полностью поглощается понятием «процесс», то есть остается только одна единица работы и потребления ресурсов – процесс. Мультипрограммирование осуществляется в таких ОС на уровне процессов.
В традиционных операционных системах у каждого процесса есть адресное пространство и единственный поток управления. Фактически это почти что определение процесса. Тем не менее нередко возникают ситуации, когда неплохо было бы иметь несколько потоков управления в одном и том же адресном пространстве, выполняемых псевдопараллельно, как будто они являются чуть ли не обособленными процессами (за исключением общего адресного пространства).
Однако в системах, в которых отсутствует понятие потока, возникают проблемы при организации параллельных вычислений в рамках процесса. А такая необходимость может возникать. Действительно, при мультипрограммировании повышается пропускная способность системы, но отдельный процесс никогда не может быть выполнен быстрее, чем в однопрограммном режиме (всякое разделение ресурсов только замедляет работу одного из участников за счет дополнительных затрат времени на ожидание освобождения ресурса). Однако приложение, выполняемое в рамках одного процесса, может обладать внутренним параллелизмом, который в принципе мог бы позволить ускорить его решение. Если, например, в программе предусмотрено обращение к внешнему устройству, то на время этой операции можно не блокировать выполнение всего процесса, а продолжить вычисления по другой ветви программы. Параллельное выполнение нескольких работ в рамках одного интерактивного приложения повышает эффективность работы пользователя. Так, при работе с текстовым редактором желательно иметь возможность совмещать набор нового текста с такими продолжительными по времени операциями, как переформатирование значительной части текста, печать документа или его сохранение на локальном или удаленном диске. Еще одним примером необходимости распараллеливания является сетевой сервер баз данных. В этом случае параллелизм желателен как для обслуживания различных запросов к базе данных, так и для более быстрого выполнения отдельного запроса за счет одновременного просмотра различных записей базы.
Потоки возникли в операционных системах как средство распараллеливания вычислений. Конечно, задача распараллеливания вычислений в рамках одного приложения может быть решена и традиционными способами.
Во-первых, прикладной программист может взять на себя сложную задачу организации параллелизма, выделив в приложении некоторую подпрограмму диспетчер, которая периодически передает управление той или иной ветви вычислений. При этом программа получается логически весьма запутанной, с многочисленными передачами управления, что существенно затрудняет ее отладку и модификацию.
Во-вторых, решением является создание для одного приложения нескольких процессов для каждой из параллельных работ. Однако, использование стандартных средств ОС для создания процессов не позволяет учесть, что эти процессы решают единую задачу, а значит, имеют много общего между собой. Они могут работать с одними и теми же данными, использовать один и тот же кодовый сегмент, наделяться одними и теми же правами доступа к ресурсам вычислительной системы. Кроме того, на создание каждого процесса ОС тратит определенные системные ресурсы, которые в данном случае неоправданно дублируются – каждому процессу выделяются собственное виртуальное адресное пространство, физическая память, закрепляются устройства ввода-вывода и т. п.
Из сказанного следует, что в операционной системе наряду с процессами нужен другой механизм распараллеливания вычислений, который учитывал бы тесные связи между отдельными ветвями вычислений одного и того же приложения. Для этих целей современные ОС предлагают механизм многопоточной обработки. При этом вводится новая единица работы – поток выполнения, а понятие «процесс» в значительной степени меняет смысл. Понятию «поток» соответствует последовательный переход процессора от одной команды программы к другой. ОС распределяет процессорное время между потоками. Процессу ОС назначает адресное пространство и набор ресурсов, которые совместно используются всеми его потоками.
Зачем нам нужна какая-то разновидность процесса внутри самого процесса? Необходимость в подобных мини-процессах, называемых потоками, обусловливается целым рядом причин. Рассмотрим некоторые из них.
1) Основная причина использования потоков заключается в том, что во многих приложениях одновременно происходит несколько действий, часть которых может периодически быть заблокированной. Модель программирования упрощается за счет разделения такого приложения на несколько последовательных потоков, выполняемых в псевдопараллельном режиме.
2) Вторым аргументом в пользу потоков является легкость (то есть быстрота) их создания и ликвидации по сравнению с более «тяжеловесными» процессами. Во многих системах создание потоков осуществляется в 10-100 раз быстрее, чем создание процессов. Это свойство особенно пригодится, когда потребуется быстро и динамично изменять количество потоков.
3) Третий аргумент в пользу потоков также касается производительности. Когда потоки работают в рамках одного центрального процессора, они не приносят никакого прироста производительности, но когда проводятся значительные вычисления, а также значительная часть времени тратится на ожидание ввода-вывода, наличие потоков позволяет этим действиям перекрываться по времени, ускоряя работу приложения.
4) И наконец, потоки весьма полезны для систем, имеющих несколько центральных процессоров, где есть реальная возможность параллельных вычислений.
Понять, в чем состоит польза от применения потоков, проще всего на конкретных примерах. Рассмотрим в качестве первого примера текстовый процессор.
Предположим, что текстовый процессор написан как двухпоточная программа. Один из потоков взаимодействует с пользователем, а другой занимается печатью в фоновом режиме. Пока пользовательский поток продолжает отслеживать события клавиатуры и мыши, реагируя на простые команды вроде прокрутки первой страницы, второй поток с большой скоростью передает данные. Ну, раз уж начали, то почему бы не добавить и третий поток? Многие текстовые процессоры обладают свойством автоматического сохранения всего файла на диск каждые несколько минут, чтобы уберечь пользователя от утраты его дневной работы в случает программных или системных сбоев или отключения электропитания. Третий поток может заниматься созданием резервных копий на диске, не мешая первым двум. Если бы программа была рассчитана на работу только одного потока, то с начала создания резервной копии на диске и до его завершения игнорировались бы команды с клавиатуры или мыши. Пользователь ощущал бы это как слабую производительность. Можно было бы сделать так, чтобы события клавиатуры или мыши прерывали создание резервной копии на диске, позволяя достичь более высокой производительности, но это привело бы к сложной модели программирования, основанной на применении прерываний. Программная модель, использующая три потока, гораздо проще. Первый поток занят только взаимодействием с пользователем. Второй поток по необходимости занимается переформатированием документа. А третий поток периодически сбрасывает содержимое ОЗУ на диск. Вполне очевидно, что три отдельных процесса так работать не будут, поскольку с документом необходимо работать всем трем потокам. Три потока вместо трех процессов используют общую память, и, таким образом, все они имеют доступ к редактируемому документу.
![]()
Рис. 19. Текстовый процессор, использующий три потока
Аналогичная ситуация складывается во многих других интерактивных программах. Например, электронная таблица является программой, позволяющей поддерживать матрицу, данные элементов которой предоставляются пользователем. Остальные элементы вычисляются исходя из введенных данных с использованием потенциально сложных формул. Когда пользователь изменяет значение одного элемента, нужно пересчитывать значения многих других элементов. При использовании потоков пересчета, работающих в фоновом режиме, поток, взаимодействующий с пользователем, может позволить последнему, пока идут вычисления, вносить дополнительные изменения. Подобным же образом третий поток может сам по себе периодически сбрасывать на диск резервные копии.
Поскольку потоки обладают некоторыми свойствами процессов, их иногда называют облегченными процессами . Термин многопоточный режим также используется для описания ситуации, при которой допускается работа нескольких потоков в одном и том же процессе.
На рис. 20, а показаны три традиционных процесса. У каждого из них имеется свое собственное адресное пространство и единственный поток управления. В отличие от этого, на рис. 20, б показан один процесс, имеющий три потока управления. Хотя в обоих случаях у нас имеется три потока, на рис. 20, а каждый из них работает в собственном адресном пространстве, а на рис. 20, б все три потока используют общее адресное пространство.

Рис. 20. Три процесса, у каждого из которых по одному потоку (а). Один процесс с тремя потоками (б)
В многозадачном режиме за счет переключения между несколькими процессами система создавала иллюзию параллельно работающих отдельных последовательных процессов. Многопоточный режим осуществляется аналогичным способом. Центральный процессор быстро переключается между потоками, создавая иллюзию, что потоки выполняются параллельно, пусть даже на более медленном центральном процессоре, чем реально используемый. При наличии в одном процессе трех потоков, ограниченных по скорости вычисления, будет казаться, что потоки выполняются параллельно, и каждый из них выполняется на центральном процессоре, имеющем скорость, которая составляет одну треть от скорости реального процессора.
Многопоточная обработка повышает эффективность работы системы по сравнению с многозадачной обработкой. Например, в многозадачной среде Windows можно одновременно работать с электронной таблицей и текстовым редактором. Однако, если пользователь запрашивает пересчет своего рабочего листа, электронная таблица блокируется до тех пор, пока эта операция не завершится, что может потребовать значительного времени. В многонитевой среде в случае, если электронная таблица была разработана с учетом возможностей многонитевой обработки, предоставляемых программисту, этой проблемы не возникает, и пользователь всегда имеет доступ к электронной таблице.
Различные потоки в процессе не обладают той независимостью, которая есть у различных процессов. У всех потоков абсолютно одно и то же адресное пространство, а значит, они так же совместно используют одни и те же глобальные переменные. Поскольку каждый поток может иметь доступ к любому адресу памяти в пределах адресного пространства процесса, один поток может считывать данные из стека другого потока, записывать туда свои данные и даже стирать оттуда данные. Защита между потоками отсутствует, потому что 1) ее невозможно осуществить и 2) в ней нет необходимости. В отличие от различных процессов, которые могут принадлежать различным пользователям и которые могут враждовать друг с другом, один процесс всегда принадлежит одному и тому же пользователю, который, по-видимому, и создал несколько потоков для их совместной работы, а не для вражды. Чтобы организовать взаимодействие и обмен данными, потокам вовсе не требуется обращаться к ОС, им достаточно использовать общую память – один поток записывает данные, а другой читает их. С другой стороны, потоки разных процессов, по-прежнему, хорошо защищены друг от друга.
В дополнение к использованию общего адресного пространства все потоки могут совместно использовать одни и те же открытые файлы, дочерние процессы, ожидаемые и обычные сигналы и т. п. Поэтому структура, показанная на рис. 20, а может использоваться, когда все три процесса фактически не зависят друг от друга, а структура, показанная на рис. 20, б, может применяться, когда три потока фактически являются частью одного и того же задания и активно и тесно сотрудничают друг с другом.
Подобно традиционному процессу (то есть процессу только с одним потоком), поток должен быть в одном из состояний, присущих процессу.
Итак, потоки имеют собственные: · программный счетчик, · стек, · регистры, · состояние. |
Потоки разделяют: · адресное пространство, · глобальные переменные, · открытые файлы, · таймеры, · статистическую информацию. |
Контекст и дескриптор процесса
При управлении процессами операционная система использует два основных типа информационных структур: дескриптор процесса и контекст процесса .
Дескриптор процесса содержит такую информацию о процессе, которая необходима ядру в течение всего жизненного цикла процесса независимо от того, находится он в активном или пассивном состоянии, находится образ процесса в оперативной памяти или выгружен на диск. В дескрипторе содержится информация о состоянии процесса, о расположении образа процесса в оперативной памяти и на диске, о значении отдельных составляющих приоритета, а также о его итоговом значении – глобальном приоритете, об идентификаторе пользователя, создавшего процесс, о родственных процессах, о событиях, осуществления которых ожидает данный процесс, и другая информация.
Дескрипторы отдельных процессов объединены в список, образующий таблицу процессов. Память для таблицы процессов отводится динамически в области ядра. На основании информации, содержащейся в таблице процессов, операционная система осуществляет планирование и синхронизацию процессов.
Очереди процессов представляют собой дескрипторы отдельных процессов, объединенные в списки. Таким образом, каждый дескриптор, кроме всего прочего, содержит по крайней мере один указатель на другой дескриптор, соседствующий с ним в очереди. Такая организация очередей позволяет легко их переупорядочивать, включать и исключать процессы, переводить процессы из одного состояния в другое.
Контекст процесса содержит менее оперативную, но более объемную часть информации о процессе, необходимую для возобновления выполнения процесса с прерванного места: содержимое регистров процессора, коды ошибок выполняемых процессором системных вызовов, информация обо всех открытых данным процессом файлах и незавершенных операциях ввода-вывода и другие данные, характеризующие состояние вычислительной среды в момент прерывания. Контекст, так же как и дескриптор процесса, доступен только программам ядра, то есть находится в виртуальном адресном пространстве операционной системы, однако он хранится не в области ядра, а непосредственно примыкает к образу процесса и перемещается вместе с ним, если это необходимо, из оперативной памяти на диск.
Диспетчеризация заключается в реализации найденного в результате планирования решения, то есть в переключении процессора с одного процесса на другой и непосредственном переводе процесса из состояния готовности в состояние исполнения.
Диспетчеризация: реализация результатов планирования. Включает в себя:
· переключение потоков;
· сохранение контекста текущего потока;
· загрузка контекста нового потока;
· запуск нового потока.
Поскольку операция переключения контекстов существенно влияет на производительность вычислительной системы, программные модули ОС выполняют диспетчеризацию потоков совместно с аппаратными средствами процессора.
Создание процессов и потоков
Создать процесс – это, прежде всего, означает создать дескриптор процесса .
Создание описателя процесса знаменует собой появление в системе еще одного претендента на вычислительные ресурсы. Начиная с этого момента при распределении ресурсов ОС должна принимать во внимание потребности нового процесса.
Создание процесса включает загрузку кодов и данных исполняемой программы данного процесса с диска в оперативную память. Для этого ОС должна обнаружить местоположение программы на диске, перераспределить оперативную память и выделить память исполняемой программе нового процесса. Затем необходимо считать программу в выделенные для нее участки памяти и, возможно, настроить программу в зависимости от размещения ее в памяти. В системах с виртуальной памятью в начальный момент может загружаться только часть кодов и данных процесса, с тем чтобы «подкачивать» остальные по мере необходимости. Существуют системы, в которых на этапе создания процесса не требуется непременно загружать коды и данные в оперативную память, вместо этого исполняемый модуль копируется из того каталога файловой системы, в котором он изначально находился, в область подкачки – специальную область диска, отведенную для хранения кодов и данных процессов. При выполнении всех этих действий подсистема управления процессами тесно взаимодействует с подсистемой управления памятью и файловой системой.
В многопоточной системе при создании процесса ОС создает для каждого процесса как минимум один поток выполнения. При создании потока так же, как и при создании процесса, операционная система генерирует специальную информационную структуру – описатель потока, который содержит идентификатор потока, данные о правах доступа и приоритете, о состоянии потока и другую информацию. В исходном состоянии поток (или процесс, если речь идет о системе, в которой понятие «поток» не определяется) находится в приостановленном состоянии. Момент выборки потока на выполнение осуществляется в соответствии с принятым в данной системе правилом предоставления процессорного времени и с учетом всех существующих в данный момент потоков и процессов. В случае если коды и данные процесса находятся в области подкачки, необходимым условием активизации потока процесса является также наличие места в оперативной памяти для загрузки его исполняемого модуля.
Во многих системах поток может обратиться к ОС с запросом на создание так называемых потоков-потомков. В разных ОС по-разному строятся отношения между потоками-потомками и их родителями. Например, в одних ОС выполнение родительского потока синхронизируется с его потомками, в частности после завершения родительского потока ОС может снимать с выполнения всех его потомков. В других системах потоки-потомки могут выполняться асинхронно по отношению к родительскому потоку. Потомки, как правило, наследуют многие свойства родительских потоков. Во многих системах порождение потомков является основным механизмом создания процессов и потоков.
Программный код только тогда начнет выполняться, когда для него операционной системой будет создан процесс.
Создать процесс - это значит:
· создать информационные структуры, описывающие данный процесс, то есть его дескриптор и контекст;
· включить дескриптор нового процесса в очередь готовых процессов;
· загрузить кодовый сегмент процесса в оперативную память.
Прерывания
Прерывания представляют собой механизм, позволяющий координировать параллельное функционирование отдельных устройств вычислительной системы и реагировать на особые состояния, возникающие при работе процессора, то есть прерывание — это принудительная передача управления от выполняемой программы к системе (а через нее — к соответствующей программе обработки прерывания), происходящая при возникновении определенного события.
Идея прерывания была предложена также очень давно — в середине 50-х годов, — и можно без преувеличения сказать, что она внесла наиболее весомый вклад в развитие вычислительной техники.
Основная цель введения прерываний — реализация асинхронного режима функционирования и распараллеливание работы отдельных устройств вычислительного комплекса.
Механизм прерываний реализуется аппаратно-программными средствами. Структуры систем прерывания (в зависимости от аппаратной архитектуры) могут быть самыми разными, но все они имеют одну общую особенность — прерывание непременно влечет за собой изменение порядка выполнения команд процессором .
Механизм обработки прерываний независимо от архитектуры вычислительной системы подразумевает выполнение некоторой последовательности шагов.
1. Установление факта прерывания (прием сигнала запроса на прерывание) и идентификация прерывания (в операционных системах идентификация прерывания иногда осуществляется повторно, на шаге 4).
2. Запоминание состояния прерванного процесса вычислений. Состояние процесса выполнения программы определяется, прежде всего, значением счетчика команд, содержимым регистров процессора, и может включать также спецификацию режима (например, режим пользовательский или привилегированный) и другую информацию.
3. Управление аппаратно передается на подпрограмму обработки прерывания. В простейшем случае в счетчик команд заносится начальный адрес подпрограммы обработки прерываний, а в соответствующие регистры — информация из слова состояния. В более развитых процессорах, например в 32-разрядных микропроцессорах фирмы Intel (начиная с i80386 и включая последние процессоры Pentium IV) и им подобных, осуществляются достаточно сложная процедура определения начального адреса соответствующей подпрограммы обработки прерывания и не менее сложная процедура инициализации рабочих регистров процессора.
4. Сохранение информации о прерванной программе, которую не удалось спасти на шаге 2 с помощью аппаратуры. В некоторых процессорах предусматривается запоминание довольно большого объема информации о состоянии прерванных вычислений.
5. Собственно выполнение программы, связанной с обработкой прерывания. Эта работа может быть выполнена той же подпрограммой, на которую было передано управление на шаге 3, но в операционных системах достаточно часто она реализуется путем последующего вызова соответствующей подпрограммы.
6. Восстановление информации, относящейся к прерванному процессу (этап, обратный шагу 4).
7. Возврат на прерванную программу.
Шаги 1-3 реализуются аппаратно, шаги 4-7 — программно.
Прерывания, возникающие при работе вычислительной системы, можно разделить на два основных класса: внешние (их иногда называют асинхронными) и внутренние (синхронные).
Внешние прерывания вызываются асинхронными событиями , которые происходят вне прерываемого процесса, например:
· прерывания от таймера;
· прерывания от внешних устройств (прерывания по вводу-выводу);
· прерывания по нарушению питания;
· прерывания с пульта оператора вычислительной системы;
· прерывания от другого процессора или другой вычислительной системы.
Внутренние прерывания вызываются событиями, которые связаны с работой процессора и являются синхронными с его операциями . Примерами являются следующие запросы на прерывания:
· при нарушении адресации (в адресной части выполняемой команды указан запрещенный или несуществующий адрес, обращение к отсутствующему сегменту или странице при организации механизмов виртуальной памяти);
· при наличии в поле кода операции незадействованной двоичной комбинации;
· при делении на ноль;
· вследствие переполнения или исчезновения порядка;
· от средств контроля (например, вследствие обнаружения ошибки четности, ошибок в работе различных устройств).
Могут еще существовать прерывания в связи с попыткой выполнить команду, которая сейчас запрещена. Во многих компьютерах часть команд должна выполняться только кодом самой операционной системы, но не прикладными программами. Это делается с целью повышения защищенности выполняемых на компьютере вычислений.
Соответственно в аппаратуре предусмотрены различные режимы работы, и пользовательские программы выполняются в режиме, в котором некоторое подмножество команд, называемых привилегированными, не исполняется. К привилегированным командам помимо команд ввода-вывода относятся и команды переключения режима работа центрального процессора, и команды инициализации некоторых системных регистров процессора. При попытке использовать команду, запрещенную в данном режиме, происходит внутреннее прерывание, и управление передается самой операционной системе.
Наконец, существуют собственно программные прерывания . Эти прерывания происходят по соответствующей команде прерывания, то есть по этой команде процессор осуществляет практически те же действия, что и при обычных внутренних прерываниях. Этот механизм был специально введен для того, чтобы переключение на системные программные модули происходило не просто как переход на подпрограмму, а точно таким же образом, как и обычное прерывание. Этим, прежде всего, обеспечивается автоматическое переключение процессора в привилегированный режим с возможностью исполнения любых команд.
Системные вызовы
В любой операционной системе поддерживается механизм, который позволяет пользовательским программам обращаться к услугам ядра ОС.
Когда непосвящённым объясняют, что такое ПО (или ОС), то говорят обычно следующее: компьютер сам по себе - это железяка, а вот софт - это то, благодаря чему от этой железяки можно получить какую-то пользу. Грубовато, конечно, но в целом, в чём-то верно. Так же я сказал бы наверно об ОС и системных вызовах. На самом деле, в разных ОС системные вызовы могут быть реализованы по-разному, может розниться число этих самых вызовов, но так или иначе, в том или ином виде механизм системных вызовов есть в любой ОС. Каждый день пользователь явно или не явно работает с файлами. Он конечно может явно открыть файл для редактирования в своём любимом MS Word'е или Notepad'е, а может и просто запустить игрушку, исполняемый образ которой, к слову, тоже хранится в файле, который, в свою очередь, должен открыть и прочитать загрузчик исполняемых файлов. В свою очередь игрушка также может открывать и читать десятки файлов в процессе своей работы. Естественно, файлы можно не только читать, но и писать (не всегда, правда, но здесь речь не о разделении прав и дискретном доступе :) ). Всем этим заведует ядро. Само по себе порождение нового процесса - это также услуга, предоставляемая ядром ОС. Если бы небыло некого механизма, с помощью которого пользовательские приложения могли выполнять некоторые достаточно обыденные и, в то же время, нужные вещи (на самом деле, эти тривиальные действия при любом раскладе выполняются не пользовательским приложением, а ядром ОС - авт. ), то ОС была просто вещью в себе - абсолютно бесполезной или же напротив, каждое пользовательское приложение само по себе должно было бы стать операционной системой, чтобы самостоятельно обслуживать все свои нужды.
Системные вызовы – это интерфейс между операционной системой и пользовательской программой. Это обращения прикладной программы к ядру операционной системы для выполнения какой-либо операции. Они создают, удаляют и используют различные объекты, главные из которых – процессы и файлы. Пользовательская программа запрашивает сервис у операционной системы, осуществляя системный вызов. Имеются библиотеки процедур, которые загружают машинные регистры определенными параметрами и осуществляют прерывание процессора, после чего управление передается обработчику данного вызова, входящему в ядро операционной системы. Цель таких библиотек – сделать системный вызов похожим на обычный вызов подпрограммы.
Основное отличие состоит в том, что при системном вызове задача переходит в привилегированный режим или режим ядра. Поэтому системные вызовы иногда еще называют программными прерываниями , в отличие от аппаратных прерываний, которые чаще называют просто прерываниями.
В этом режиме работает код ядра операционной системы, причем исполняется он в адресном пространстве и в контексте вызвавшей его задачи. Таким образом, ядро операционной системы имеет полный доступ к памяти пользовательской программы, и при системном вызове достаточно передать адреса одной или нескольких областей памяти с параметрами вызова и адреса одной или нескольких областей памяти для результатов вызова.
Системный вызов позволяет приложению обратиться к операционной системе с просьбой выполнить то или иное действие, оформленное как процедура (или набор процедур) программного кода ОС.
Для прикладного программиста операционная система выглядит как некая библиотека, предоставляющая некоторый набор полезных функций, с помощью которых можно упростить прикладную программу или выполнить действия, запрещенные в пользовательском режиме, например обмен данными с устройством ввода-вывода.
Реализация системных вызовов должна удовлетворять следующим требованиям:
1. обеспечивать переключение в привилегированный режим;
2. обладать высокой скоростью вызова процедур ОС;
3. обеспечивать по возможности единообразное обращение к системным вызовам для всех аппаратных платформ, на которых работает ОС;
4. допускать легкое расширение набора системных вызовов;
5. обеспечивать контроль со стороны ОС за корректным использованием системных вызовов.
В большинстве ОС системные вызовы обслуживаются по централизованной схеме, основанной на существовании диспетчера системных вызовов .
При любом системном вызове приложение выполняет программное прерывание с определенным номером. Перед вы-полнением программного прерывания приложение тем или иным способом передает операционной системе номер системного вызова, который является индексом в таблице адресов процедур ОС, реализующих системные. Также передаются аргументы системного вызова.
Диспетчер системных вызовов обычно представляет собой простую программу, которая:
1. сохраняет содержимое регистров процессора в системном стеке,
2. проверяет, попадает ли запрошенный номер вызова в поддерживаемый ОС диапазон (то есть не выходит ли номер за границы таблицы),
3. передает управление процедуре ОС, адрес которой задан в таблице адресов системных вызовов.
Процедура реализации системного вызова извлекает из системного стека аргументы и выполняет заданное действие. Это действие может быть весьма простым, например чтение значения системных часов, так что системный вызов оформляется в виде одной функции. Более сложные системные вызовы, такие как чтение из файла или выделение процессу дополнительного сегмента памяти, требуют обращения основной функции системного вызова к нескольким внутренним процедурам ядра ОС, принадлежащим к различным подсистемам, таким как подсистема ввода-вывода или управления памятью.
После завершения работы системного вызова управление возвращается диспетчеру, при этом он получает также код завершения этого вызова. Диспетчер восстанавливает регистры процессора, помещает в определенный регистр код возврата и выполняет инструкцию возврата из прерывания, которая восстанавливает непривилегированный режим работы процессора.
Описанный табличный способ организации системных вызовов принят практически во всех операционных системах. Он позволяет легко модифицировать состав системных вызовов, просто добавив в таблицу новый адрес и расширив диапазон допустимых номеров вызовов.
Операционная система может выполнять системные вызовы в синхронном или асинхронном режимах.
Синхронный системный вызов означает , что процесс, сделавший такой вызов, приостанавливается (переводится планировщиком ОС в состояние ожидания) до тех пор, пока системный вызов не выполнит всю требующуюся от него работу. После этого планировщик переводит процесс в состояние готовности и при очередном выполнении процесс гарантированно может воспользоваться результатами завершившегося к этому времени системного вызова. Синхронные вызовы называются также блокирующими , так как вызвавший системное действие процесс блокируется до его завершения.
Асинхронный системный вызов не приводит к переводу процесса в режим ожидания после выполнения некоторых начальных системных действий, например запуска операции вывода-вывода, управление возвращается прикладному процессу.
Большинство системных вызовов в операционных системах являются синхронными, так как этот режим избавляет приложение от работы по выяснению момента появления результата вызова. Вместе с тем в новых версиях операционных систем количество асинхронных системных вызовов постепенно увеличивается, что дает больше свободы разработчикам сложных приложений. Особенно нужны асинхронные системные вызовы в операционных системах на основе микроядерного подхода, так как при этом в пользовательском режиме работает часть ОС, которым необходимо иметь полную свободу в организации своей работы, а такую свободу дает только асинхронный режим обслуживания вызовов микроядром.
Исключительная ситуация
Исключительная ситуация — событие, возникающее в результате попытки выполнения программой команды, которая по каким-то причинам не может быть выполнена до конца. Примерами таких команд могут быть попытки доступа к ресурсу при отсутствии достаточных привилегий или обращения к отсутствующей странице памяти. Исключительные ситуации, как и системные вызовы, являются синхронными событиями , возникающими в контексте текущей задачи.
Исключительные ситуации можно разделить на исправимые и неисправимые.
1. К исправимым относятся такие исключительные ситуации, как отсутствие нужной информации в оперативной памяти. После устранения причины исправимой исключительной ситуации программа может выполняться дальше. Возникновение в процессе работы операционной системы исправимых исключительных ситуаций считается нормальным явлением.
2. Неисправимые исключительные ситуации чаще всего возникают в результате ошибок в программах (например, деление на ноль). Обычно в таких случаях операционная система реагирует завершением программы, вызвавшей исключительную ситуацию.
Файлы
Файл – это именованная совокупность данных на диске.
Характеристики файла:
1. Имя.
2. Тип.
3. Метаданные.
Имя файла – это обозначение файла, необходимое для обращения к нему.
Конкретные правила составления имен файлов варьируются от системы к системе, но все ныне существующие операционные системы в качестве допустимых имен файлов позволяют использовать от одной до восьми букв. Поэтому для имен файлов можно использовать слова andrea, bruce и cathy. Зачастую допускается также применение цифр и специальных символов, поэтому допустимы также такие имена, как 2, urgent!, и Fig.2-14. Многие файловые системы поддерживают имена длиной до 255 символов.
Некоторые файловые системы различают буквы верхнего и нижнего регистров, а некоторые не делают таких различий. Система UNIX подпадает под первую категорию, a MS-DOS — под вторую. Поэтому система UNIX может рассматривать все последующие сочетания символов как имена трех разных файлов: maria, Maria и MARIA. В MS-DOS все эти имена относятся к одному и тому же файлу.
Многие операционные системы поддерживают имена файлов, состоящие из двух частей, разделенных точкой, как в имени prog.с. Та часть имени, которая следует за точкой, называется расширением имени файла и, как правило, несет в себе некоторую информацию о файле. К примеру, в MS-DOS имена файлов состоят из 1-8 символов, плюс к этому необязательное расширение, состоящее из 1-3 символов. В UNIX размер расширения, если таковое имеется, выбирает сам пользователь, и имя файла может иметь даже два и более расширений, как в имени homepage.html.zip, где .html указывает на наличие веб-страницы в коде HTML, a .zip — на то, что этот файл (homepage.html) был сжат программой zip.
Основные правила именования файлов:
1) Короткое имя (формат MS DOS, формат 8.3). До появления ОС Windows 95 был принят формат имени 8.3 (MS-DOS). Имя файла состоит из двух частей: собственно имени и расширения . В MS-DOS имя файла может содержать от 1 до 8 символов. Расширение имени файла является необязательным, однако многие программы требуют, чтобы файл конкретного типа обладал и конкретным расширением. Оно, как правило, описывает содержание файла, поэтому использование расширения весьма удобно. Расширение начинается с точки, за которой следует от одного до трех символов. Имя и расширение могут состоять из прописных и строчных латинских букв, цифр и символов, кроме недопустимых
\ / пробел , ; . : + = * ? [ ] < >
Соглашение 8.3не является стандартом, и потому в ряде случаев отклонения от правильной формы записи допускаются как операционной системой, так и ее приложениями. Так, например, в большинстве случаев система «не возражает» против использования некоторых специальных символов (восклицательный знак, символ подчеркивания, дефис, тильда и т. п.), а некоторые версии MS-DOSдаже допускают использование в именах файлов символов русского и других алфавитов.
2) Длинное имя (формат Windows). Основным недостатком «коротких» имен является их низкая содержательность. Далеко не всегда удается выразить несколькими символами характеристику файла, поэтому с появлением операционной системы Windows 95было введено понятие «длинного» имени. Такое имя может содержать до 255 символов. Этого вполне достаточно для создания содержательных имен файлов. «Длинное» имя может содержать любые символы, кроме девяти специальных:
\ /:*?«<>|
В имени разрешается использовать пробелы и несколько точек. Расширением имени считаются все символы, идущие после последней точки, их может быть и больше трех.
В некоторых системах (например, в UNIX) расширения имен файлов используются в соответствии с соглашениями и не навязываются операционной системой. Файл file.txt может быть текстовым файлом, но это скорее напоминание его владельцу, чем передача некой значимой информации компьютеру. С другой стороны, компилятор языка С может выдвигать требование, чтобы компилируемые им файлы имели расширение .с, и отказываться проводить компиляцию, если они не имеют такого расширения.
Подобные соглашения особенно полезны, когда одна и та же программа должна управлять различными типами файлов. Например, компилятору языка С может быть предоставлен список файлов, которые он должен откомпилировать и скомпоновать, причем некоторые из этих файлов могут содержать программы на языке С, тогда как другие — являться ассемблерными файлами. В таком случае компилятор сможет отличить одни файлы от других именно по их расширениям.
Система Windows, напротив, знает о расширениях имен файлов и назначает каждому расширению вполне определенное значение. Пользователи (или процессы) могут регистрировать расширения в операционной системе, указывая программу, которая станет их «владельцем». При двойном щелчке мыши на имени файла запускается программа, назначенная этому расширению, с именем файла в качестве параметра. Например, двойной щелчок мыши на имени file.doc запускает Microsoft Word, который открывает файл file.doc в качестве исходного файла для редактирования.
Для обозначения группы файлов используют шаблоны - это специальные записи, в которых применяют символы * и ? .
* заменяет любое число любых символов в имени или расширении файла;
? заменяет один символ в данной позиции.
Примеры:
*.* — все файлы.
*.ехе - файлы с расширением ехе.
ргоg.* - файлы с именем ргоg, расширение любое.
???gruppa.txt - три первых символа любые, затем символы gruppa, расширение txt.
Типы файлов
Многие операционные системы поддерживают несколько типов файлов.
![]()
Обычными считаются файлы, содержащие информацию пользователя.
Текстовые файлы состоят из строк символов, представленных в ASCII-коде. Это могут быть документы, исходные тексты программ и т.п. Текстовые файлы можно прочитать на экране и распечатать на принтере.
Двоичные файлы не используют ASCII-коды, они часто имеют сложную внутреннюю структуру, например, объектный код программы или архивный файл.
Специальные файлы – это файлы, ассоциированные с устройствами ввода-вывода и дисками, которые позволяют пользователю выполнять операции, используя обычные команды записи в файл или чтения из файла. Эти команды обрабатываются вначале программами файловой системы, а затем на некотором этапе выполнения запроса преобразуются ОС в команды управления соответствующим устройством.
Символьные специальные файлы имеют отношение к вводу-выводу и используются для моделирования последовательных устройств ввода-вывода, к которым относятся терминалы, принтеры и сети.
Блочные специальные файлы используются для моделирования дисков.
Каталоги – это файлы специального вида, в которых регистрируются обычные файлы. В них хранятся имена файлов, сведения о размере файлов, времени их последнего обновления, атрибуты (свойства) файлов и т. д. Если в каталоге хранится имя файла, то говорят, что этот файл находится в данном каталоге.
Каждая операционная система должна распознавать по крайней мере один тип файла — свой собственный исполняемый файл .
Метаданные
У каждого файла есть свое имя и данные. Вдобавок к этому все операционные системы связывают с каждым файлом и другую информацию, к примеру, дату и время последней модификации файла и его размер. Мы будем называть эти дополнительные сведения метаданными.
Список метаданных существенно варьируется от системы к системе. В табл. показаны некоторые из возможных метаданных, но кроме них существуют также и другие метаданные. Ни одна из существующих систем не имеет всех этих метаданных, но каждый из них присутствует в какой-либо системе.
Первые четыре метаданных относятся к защите файла и сообщают о том, кто может иметь к нему доступ, а кто нет. Возможно применение разнообразных схем, некоторые из них мы рассмотрим чуть позже. В некоторых системах для доступа к файлу пользователь должен ввести пароль, в этом случае этот пароль может быть одним из метаданных файла.
Атрибуты и флаги представляют собой биты или небольшие поля, с помощью которых происходит управление некоторыми конкретными свойствами или разрешение их применения. Например, скрытые файлы не появляются в листинге файлов. Атрибут архивации представляет собой бит, с помощью которого отслеживается, была ли недавно сделана резервная копия файла. Этот атрибут сбрасывается программой архивирования и устанавливается операционной системой при внесении в файл изменений. Таким образом, программа архивирования может определить, какие файлы следует архивировать. Флаг «временный» позволяет автоматически удалять помеченный им файл по окончании работы создавшего его процесса.
Различные показатели времени позволяют отслеживать время создания файла, время последнего доступа к этому файлу, его последнего изменения. Эти сведения могут оказаться полезными для достижения различных целей. К примеру, если исходный файл был изменен уже после создания соответствующего объектного файла, то он нуждается в перекомпиляции. Необходимую для этого информацию предоставляют поля времени.
Текущий размер показывает, насколько большим является файл в настоящее время. Некоторые старые операционные системы универсальных машин требуют при создании файла указывать его максимальный размер, чтобы позволить операционной системе заранее выделить максимальное место для его хранения. Операционные системы рабочих станций и персональных компьютеров достаточно разумны, чтобы обойтись без этой особенности.
| Метаданное | Значение |
| Защита | Кто и каким образом может получить доступ к файлу |
| Пароль | Пароль для получения доступа к файлу |
| Создатель | Идентификатор создателя файла |
| Владелец | Текущий владелец |
| Атрибут «только для чтения» | О — для чтения-записи; 1 — только для чтения |
| Атрибут «скрытый» | О — обычный; 1 — не предназначенный для отображения в перечне файлов |
| Атрибут «системный» | 0 — обычный; 1 — системный |
| Атрибут «архивный» | 0 — прошедший резервное копирование; 1 — нуждающийся в резервном копировании |
| Флаг ASCII-двоичный | 0 —ASCII; 1 —двоичный |
| Флаг произвольного доступа | 0 — только последовательный доступ; 1 — произвольный доступ |
| Флаг «временный» | 0 — обычный; 1 — удаляемый по окончании процесса |
| Флаги блокировки | 0 — незаблокированный; ненулевое значение — заблокированный |
| Время создания | Дата и время создания файла |
| Время последнего доступа | Дата и время последнего доступа к файлу |
| Время внесения последних изменений | Дата и время внесения в файл последних изменений |
| Текущий размер | Количество байтов в файле |
| Максимальный размер | Кол-во байт, до которого файл может увеличиваться |
Размещение файлов на диске
Файл представляет собой бессистемную последовательность байтов. В сущности, операционной системе все равно, что содержится в этом файле. Она видит только байты. Какое-либо значение этим байтам придается программами на уровне пользователя. Эта файловая модель используется всеми версиями UNIX, MS-DOS и Windows.
В современных ОС файлы хранятся на дисках и являются файлами произвольного доступа – ОС считывает байты файла вне порядка их размещения.
Информация, с которой работает человек, обычно структурирована. Это, прежде всего, позволяет более эффективно организовать хранение данных, облегчает их поиск, предоставляет дополнительные возможности в именовании. Аналогично, и при работе с файлами желательно ввести механизмы структурирования. Проще всего организовать иерархические отношения. Для этого достаточно ввести понятие каталога.
Каталоги . Имена файлов регистрируются на дисках в каталогах (или директориях). В Windows каталоги называются также папками. Каталог – это специальное место на диске, в котором хранятся имена файлов, сведения о размере файлов, времени их последнего обновления, атрибуты (свойства) файлов и т. д. Если в каталоге хранится имя файла, то говорят, что этот файл находится в данном каталоге. На каждом диске может быть несколько каталогов. В каждом каталоге может быть много файлов, но каждый файл всегда регистрируется только в одном каталоге.
Имена каталогов . Требования к именам каталогов те же, что и к именам файлов. Как правило, расширение имени для каталогов не используется, хотя делать этого никто не запрещает.
Корневой каталог . На каждом диске имеется один главный, или корневой, каталог (он создается после форматирования). Для его обозначения используют символ \. В нем регистрируются файлы и подкаталоги (каталоги 1-го уровня). В каталогах 1-го уровня регистрируются файлы и каталоги 2-го уровня и т. д. Получается иерархическая древообразная структура каталогов на диске. Эту структуру часто называют деревом.
Подкаталоги и надкаталоги . Все каталоги, кроме корневого, на самом деле являются файлами специального вида. Каждый каталог имеет имя, и он может быть зарегистрирован в другом каталоге. Если каталог Х зарегистрирован в каталоге У, то говорят, что Х – подкаталог У, а У – надкаталог или родительский каталог для Х.
Текущий каталог – это каталог, с которым пользователь работает в данный момент.
Путь . Когда вы используете файл не из текущего каталога, необходимо указать, в каком каталоге этот файл находится. Это можно сделать с помощью указания пути к файлу. Путь – это последовательность из имен каталогов, разделенных знаком \ , которые нужно последовательно открыть, чтобы найти файл (включая диск). Этот путь задает маршрут от корневого каталога диска к тому каталогу, в котором находится нужный файл.
Полное имя файла , или спецификация , включает в себя диск, путь, собственно имя и расширение имени, т. е. путь\имя.расширение
Например , D:\school\profes\music.exe
Файловые системы
Для управления файлами создаются соответствующие файловые системы.
Файловая система — это часть операционной системы, назначение которой состоит в том, чтобы организовать эффективную хранение данных на диске, и обеспечить пользователю удобный доступ к этим данным и интерфейс при работе с такими данными.
Организовать хранение информации на магнитном диске непросто. Это требует, например, хорошего знания устройства контроллера диска, особенностей работы с его регистрами. Непосредственное взаимодействие с диском — прерогатива компонента системы ввода-вывода ОС, называемого драйвером диска. Для того чтобы избавить пользователя компьютера от сложностей взаимодействия с аппаратурой, была придумана ясная абстрактная модель файловой системы. Операции записи или чтения файла концептуально проще, чем низкоуровневые операции работы с устройствами.
Главная задача файловой системы — скрыть особенности ввода-вывода и дать программисту простую абстрактную модель файлов, независимых от устройств.
Перечислим основные функции файловой системы :
1. Идентификация файлов . Связывание имени файла с выделенным ему пространством внешней памяти.
2. Распределение внешней памяти между файлами . Для работы с конкретным файлом пользователю не требуется иметь информацию о местоположении этого файла на внешнем носителе информации. Например, для того чтобы загрузить документ в редактор с жесткого диска, нам не нужно знать, на какой стороне какого магнитного диска, на каком цилиндре и в каком секторе находится данный документ.
3. Обеспечение надежности и отказоустойчивости . Обеспечение защиты от несанкционированного доступа .
4. Обеспечение совместного доступа к файлам , так чтобы пользователю не приходилось прилагать специальных усилий по обеспечению синхронизации доступа.
5. Обеспечение высокой производительности .
Специальное системное программное обеспечение, реализующее работу с файлами по принятым спецификациям файловой системы, часто называют системой управления файлами . Именно системы управления файлами отвечают за создание, уничтожение, организацию, чтение, запись, модификацию и перемещение файловой информации, а также за управление доступом к файлам и за управление ресурсами, которые используются файлами.
Назначение системы управления файлами — предоставление более удобного доступа к данным, организованным как файлы, то есть вместо низкоуровневого доступа к данным с указанием конкретных физических адресов нужной нам записи используется логический доступ с указанием имени файла и записи в нем.
Благодаря системам управления файлами пользователям предоставляются следующие возможности :
1. создание, удаление, переименование (и другие операции) именованных наборов данных (файлов) из своих программ или посредством специальных управляющих программ, реализующих функции интерфейса пользователя с его данными и активно использующих систему управления файлами;
2. работа с недисковыми периферийными устройствами как с файлами;
3. обмен данными между файлами, между устройствами, между файлом и устройством (и наоборот);
4. работа с файлами путем обращений к программным модулям системы управления файлами;
5. защита файлов от несанкционированного доступа.
Любая система управления файлами не существует сама по себе – она разработана для функционирования в конкретной ОС. То есть, для работы с файлами, организованными в соответствии с некоторой файловой системой, для каждой ОС должна быть разработана соответствующая система управления файлами. Эта система управления файлами будет работать только в той ОС, для которой она и создана. Но при этом она позволит работать с файлами, созданными с помощью системы управления файлами другой ОС и организованными в файловую систему по тем же основным принципам.
В некоторых ОС может быть несколько систем управления файлами, что обеспечивает им возможность работать с несколькими файловыми системами.
Системы управления файлами, будучи компонентом ОС, не являются независимыми от этой ОС, поскольку они активно используют соответствующие вызовы прикладного программного интерфейса API (application program interface ). С другой стороны, системы управления файлами сами дополняют API новыми вызовами. Можно сказать, что основное назначение файловой системы и соответствующей ей системы управления файлами – организация удобного доступа к данным, организованным как файлы, то есть вместо низкоуровневого доступа к данным с указанием конкретных физических адресов нужной записи используется логический доступ с указанием имени файла и записи в нем.
Термин «файловая система» определяет, прежде всего, принципы доступа к данным, организованным в файлы. Этот же термин часто используют и по отношению к конкретным файлам, расположенным на том или ином носителе данных. А термин «система управления файлами» следует употреблять по отношению к конкретной реализации файловой системы. То есть система управления файлами – это комплекс программных модулей, обеспечивающих работу с файлами в конкретной операционной системе.
Файловая система FAT
В FAT пространство любого диска делится на части:

1. BOOT-сектор содержит основные количественные параметры дискового тома и файловой системы, а также может содержать программу начальной загрузки ОС.
2. таблица FAT (File Allocation Table) – содержит информацию о размещении файлов и свободного места на диске. Ввиду критической важности этой таблицы она всегда хранится в двух экземплярах, которые должны быть идентичны. Каждая операция, изменяющая содержимое FAT, должна одинаковым образом изменять оба экземпляра.
3. ROOT – корневой каталог системы, содержащий данные о файлах и о подкаталогах верхнего уровня, каждый из которых в свою очередь может содержать файлы и подкаталоги.
4. Область данных – массив кластеров, содержащий все файлы и все каталоги (кроме корневого).
Область данных разбивается на кластеры. Кластеры представляют один или несколько смежных секторов в области данных. Кластер – минимальная адресная единица дисковой памяти, выделенная файлу. Кластеры, принадлежащие одному файлу, связываются в цепочки. Каждый файл занимает целое число кластеров. Последний кластер при этом может быть задействован не полностью, что при большом размере кластера может приводить к заметной потере дискового пространства.
Разбиение области данных на кластеры вместо секторов имеет смысл по причинам:
- Уменьшается размер самой FAT;
- Уменьшается возможная фрагментация файлов;
- Ускоряется доступ к файлу, т.к. в несколько раз сокращается длина цепочек – фрагментов дискового пространства, выделенного файлу.
Т.к. FAT интенсивно используется, то она помещается в ОЗУ, а на диске хранится в двух экземплярах. Используется только первый, если он оказывается поврежден, то происходит обращение ко второму экземпляру.
Записи FAT «по историческим причинам» нумеруются, начиная с 2 и заканчивая максимальным номером кластера, каждая запись FAT описывает соответствующий кластер с тем же номером. Запись может принимать следующие значения:
1. если кластер принадлежит некоторому файлу (или каталогу) и является последним (или единственным) в этом файле, то запись FAT содержит специальное значение – FFFF;
2. если кластер принадлежит некоторому файлу (или каталогу), но не является последним в файле, то запись FAT содержит номер следующего кластера того же файла;
3. если кластер свободен, то запись содержит все нули;
4. если кластер дефектный (т.е. при проверке диска выяснилось, что данный кластер содержит хотя бы один дефектный сектор), то запись содержит специальное значение FFF7.
| FAT16 | |
| Длина записи (под номер кластера) | 16 бит (разрядов) |
| Количество записей | 216 |
| Размер кластера | 32 Кбайт (64 сектора) |
| Максимальный объем диска | 2 Гбайт |
| Кол-во элементов в корневом каталоге | 512 |
Длина кластера составляет 32 Кбайт (64 сектора). Это не вполне рациональный расход рабочего пространства, поскольку любой файл (даже очень маленький) полностью оккупирует весь кластер, которому соответствует только одна адресная запись в таблице размещения файлов. Даже если файл достаточно велик и располагается в нескольких кластерах, все равно в его конце образуется некий остаток, нерационально расходующий целый кластер.
Такие системы не могут работать с дисками, объем которых больше 2 Гбайт.
В каталоге среди основной информации хранится номер первого кластера, который занимает файл, а остальные кластеры можно последовательно определить по записям таблицы FAT.
Теперь мы знаем, каким образом в системе FAT хранится информация о размещении сегментированного файла. Номер первого кластера файла хранится в записи каталога, а остальные кластеры можно последовательно определить по записям таблицы FAT.
Файловые системы VFAT и FAT32
Одной из важнейших характеристик исходной файловой системы FAT было использование имен файлов формата 8.3. К стандартной системе FAT (имеется в виду прежде всего реализация FAT16) добавились еще две разновидности, используемые в широко распространенных ОС от Microsoft (конкретно — в Windows 95 и Windows NT):
· VFAT (виртуальная система FAT);
· система FAT32, используемая в одной из редакций ОС Windows 95 и Windows 98.
1) Ныне файловая система FAT32 поддерживается и такими последними системами, как Windows Millennium Edition, Windows 2000 и Windows XP. Имеются реализации FAT32 и для Windows NT, и для Linux.
2) Файловая система VFAT впервые появилась в Windows 3.11 (Windows for Workgroups).
3) С выходом Windows 95 в VFAT добавилась поддержка длинных имен файлов (Long File Name, LFN). Тем не менее, VFAT сохраняет совместимость с исходным вариантом FAT; это означает, что наряду с длинными именами в ней поддерживаются имена формата 8.3, а также существует специальный механизм для преобразования имен 8.3 в длинные имена, и наоборот.
4) Именно файловая система VFAT поддерживается исходными версиями Windows 95, Windows NT 4, Windows 2000 и Windows XP.
Основными недостатками файловых систем FAT и VFAT, которые привели к разработке новой реализации файловой системы, основанной на той же идее (таблице размещения файлов), являются большие потери на кластеризацию при больших размерах логического диска и ограничения на сам размер логического диска.
Поэтому в Microsoft Windows 95 на смену системе VFAT пришла файловая система FAT32, которая является полностью самостоятельной 32-разрядной файловой системой и содержит многочисленные усовершенствования и дополнения по сравнению с предыдущими реализациями FAT.
Самое принципиальное отличие заключается в том, что FAT32 намного эффективнее расходует дисковое пространство. Прежде всего, кластеры в этой системе меньше, чем кластеры в предыдущих версиях, в которых могло быть не более 65 535 кластеров на логический диск (соответственно с увеличением размера диска приходилось увеличивать и размер кластеров). Следовательно, даже для дисков размером до 8 Гбайт FAT32 может использовать 4-килобайтные кластеры. В результате по сравнению с дисками FAT 16 экономится значительное дисковое пространство (в среднем 10-15 %). В FAT32 проблема решается за счет того, что собственно сама таблица размещения файлов в этой файловой системе может содержать до 228 кластеров (В 32-разрядном слове FAT32, используемом для представления номера кластера, фактически учитываются только 28 разрядов, что приводит к тому, что размер таблицы размещения файлов в этой системе не может превышать 228 элементов).
Помимо повышения максимального объема логического диска и уменьшения эффекта кластеризации, файловая система FAT32 вносит ряд необходимых усовершенствований в структуру корневого каталога. FAT32 также может перемещать корневой каталог и использовать резервную копию FAT вместо стандартной. Загрузочная запись FAT32 позволяет создавать копии критически важных структур данных; это повышает устойчивость дисков FAT32 к нарушениям структуры таблицы размещения файлов по сравнению с предыдущими версиями. Корневой каталог в FAT32 может находиться в произвольном месте диска, что снимает действовавшее ранее ограничение на размер корневого каталога (512 элементов). В FAT32 было увеличено их количество с 512 до 2048.
| FAT32 | |
| Длина записи (под номер кластера) | 32 бит |
| Количество записей | 228 |
| Размер кластера | 4 Кбайт |
| Максимальный объем диска | 8 Гбайт |
| Кол-во элементов в корневом каталоге | 2048 |
Файловая система NTFS (New Technology File System)
Эта файловая система содержит ряд усовершенствований и изменений по сравнению с другими файловыми системами. Файлы по-прежнему хранятся в каталогах (теперь называемых папками). В NTFS повышена эффективность работы с дисками большого объема. Имеются средства для ограничения доступа, введены механизмы для повышения надежности файловой системы.
Основные возможности файловой системы NTFS
При проектировании NTFS особое внимание было уделено надежности, механизмам ограничения доступа к файлам и каталогам, расширенной функциональности, поддержке дисков большого объема и пр.
Надежность
Высокопроизводительные компьютеры и системы совместного использования должны обладать повышенной надежностью, которая является ключевым элементом структуры и функционирования NTFS. Система NTFS обладает определенными средствами самовосстановления . Она поддерживает различные механизмы проверки целостности системы, включая ведение журналов транзакций , позволяющих воспроизвести файловые операции записи по специальному системному журналу. При протоколировании файловых операций система управления файлами фиксирует в специальном служебном файле (журнале) происходящие изменения. В начале операции, связанной с изменением файловой структуры, делается соответствующая пометка. Если во время файловых операций происходит какой-нибудь сбой, то из-за упомянутой отметки операция остается помеченной как незавершенная. При выполнении процедуры проверки целостности файловой системы после перезагрузки машины эти незавершенные операции отменяются, и файлы возвращаются в исходное состояние. Если же операция изменения данных в файлах завершается нормальным образом, то в файле журнала эта операция отмечается как завершенная.
Поскольку NTFS разрабатывалась как файловая система для серверов, для которых очень важно обеспечить бесперебойную работу без перезагрузок, в ней для повышения надежности был введен механизм аварийной замены дефектных секторов резервными. Другими словами, если обнаруживается сбой при чтении данных, то система постарается прочесть эти данные, переписать их в специально зарезервированное для этой цели пространство диска, а дефектные сектора пометить как плохие и более к ним не обращаться.
Ограничения доступа к файлам и каталогам
Файловая система NTFS поддерживает объектную модель безопасности операционной системы Windows NT и рассматривает все тома, каталоги и файлы как самостоятельные объекты. Система NTFS обеспечивает безопасность на уровне файлов и каталогов. Это означает, что разрешения доступа к томам, каталогам и файлам могут зависеть от учетной записи пользователя и тех групп, к которым он принадлежит.
Каждый раз, когда пользователь обращается к объекту файловой системы, его разрешения на доступ проверяются по списку управления доступом для данного объекта. Если пользователь обладает необходимым уровнем разрешений, его запрос удовлетворяется; в противном случае запрос отклоняется. Эта модель безопасности применяется как при локальной регистрации пользователей на компьютерах с Windows NT, так и при удаленных сетевых запросах.
Поддержка дисков большого объема
Система NTFS создавалась с расчетом на работу с большими дисками. Она уже достаточно хорошо проявляет себя при работе с томами объемом 300-400 Мбайт и выше. Чем больше объем диска и чем больше на нем файлов, тем больший выигрыш мы получаем, используя NTFS вместо FAT16 или FAT32. Максимально возможные размеры тома (и размеры файла) составляют 16 Эбайт (один экзабайт равен 264 байт, или приблизительно 16 000 млрд гигабайт), в то время как при работе под Windows NT/2000/XP диск с FAT 16 не может иметь размер более 4 Гбайт, а с FAT32 — 32 Гбайт. Количество файлов в корневом и некорневом каталогах при использовании NTFS не ограничено. Время поиска файлов в NTFS не связано с их количеством (в отличие от систем на базе FAT). Наконец, помимо немыслимых размеров томов и файлов, система NTFS также обладает встроенными средствами сжатия, что позволяет экономить дисковое пространство и размещать в нем больше файлов. Напомним, что сжатие можно применять как к отдельным файлам, так и целым каталогам и даже томам (и впоследствии отменять или назначать их по своему усмотрению).
Структура тома с файловой системой NTFS
Рассмотрим теперь структуру файловой системы NTFS.
Прежде всего, одним из основных понятий, используемых при работе с NTFS, является понятие тома (volume). Том означает логическое дисковое пространство, которое может быть воспринято как логический диск, то есть том может иметь букву (буквенный идентификатор) диска. Частным случаем тома является логический диск.
![]()
Все дисковое пространство в NTFS делится на две неравные части.
1) Зона MFT (Master File Table — главная таблица файлов) - первые 12 % диска. Эта зона содержит служебные файлы файловой системы и таблицу MFT (с учетом ее будущего роста), представляющей собой специальный файл со служебной информацией, позволяющей определять местонахождение всех остальных файлов. Запись каких-либо данных в зону MFT невозможна — она всегда остается пустой, чтобы при росте MFT по возможности не было фрагментации.
2) Остальные 88 % тома представляют собой обычное пространство для хранения файлов .
Первые 16 файлов в MFT-зоне – это метафайлы , В них содержится служебная информация, они имеют фиксированное положение и они недоступны даже операционной системе. Кстати, первым из этих 16 является сам MFT - файл.
Таблица MFT – это файл. Это последовательность записей фиксированного размера (1 кбайт). Каждая запись MFT описывает один файл или один каталог. Она содержит имя файла и список дисковых адресов (где расположены его блоки).
Первые 16 записей таблицы MFTсоответствуют метафайлам. Копии этих первых записей располагаются посередине диска.
Зона MFTостается зарезервированной и пустой для записей о файлах. В том случае, если в области данных не остается места, то запись обычных файлов в эту зону возможна. Обычные файлы могут перемежаться со служебными и возникает фрагментация MFT-зоны.
Итак, все файлы тома представлены в таблице MFT. За исключением собственно данных, в этой структуре хранится вся информация о файлах: имя файла, размер, положение на диске отдельных фрагментов и т. д. Если для информации не хватает одной записи MFT, то используются несколько записей, причем не обязательно последовательных. Если файл имеет не очень большой размер, тогда в ход идет довольно удачное решение: данные файла хранятся прямо в соответствующей записи таблицы MFT в оставшемся от служебных данных месте. Таким образом, файлы, занимающие не более сотни байтов, обычно не имеют своего «физического» воплощения в основной файловой области — все данные таких файлов хранятся прямо в таблице MFT.
Выделение дискового пространства
Каждый том NTFS (например, дисковый раздел) содержит файлы, каталоги, битовые массивы и другие структуры данных. Каждый том организован как линейная последовательность блоков (которые в терминологии компании Microsoft называются кластерами ), причем размер блоков для каждого тома фиксирован (в зависимости от размера тома он может изменяться от 512 байт до 64 Кбайт). Большинство дисков NTFS использует блоки размером 4 Кбайт — это компромисс между применением больших блоков (для эффективной передачи данных) и использованием маленьких блоков (для снижения внутренней фрагментации).
Итак, у системы есть файлы - и ничего кроме файлов. Что включает в себя это понятие на NTFS?
- Прежде всего, обязательный элемент - запись в MFT, ведь, как было сказано ранее, все файлы диска упоминаются в MFT. В этом месте хранится вся информация о файле, за исключением собственно данных. Имя файла, размер, положение на диске отдельных фрагментов, и т.д. Если для информации не хватает одной записи MFT, то используются несколько, причем не обязательно подряд.
- Опциональный элемент - потоки данных файла. Может показаться странным определение "опциональный", но, тем не менее, ничего странного тут нет. Во-первых, файл может не иметь данных - в таком случае на него не расходуется свободное место самого диска. Во-вторых, файл может иметь не очень большой размер. Тогда идет в ход довольно удачное решение: данные файла хранятся прямо в MFT, в оставшемся от основных данных месте в пределах одной записи MFT. Файлы, занимающие сотни байт, обычно не имеют своего "физического" воплощения в основной файловой области - все данные такого файла хранятся в одном месте - в MFT.
Каждый файл на диске в системе NTES представлен с помощью потоков данных (streams), то есть у файла нет «просто данных», а есть «потоки данных». Чтобы правильнее понять эту сущность (поток данных), достаточно знать, что один из потоков имеет привычный нам смысл — это собственно данные файла. Кстати, большинство атрибутов файла (за исключением основных) — это тоже потоки данных. Таким образом, получается, что базовая сущность у файла только одна - номер в MFT, а всё остальное опционально.
Данный подход довольно удобен. Так, файлу можно назначить еще один поток данных, записав в него любые данные, например информацию об авторе и содержании файла, как это сделано в Windows 2000 (эта информация представлена на одной из вкладок диалогового окна свойств файла). Интересно, что эти дополнительные потоки н е видны стандартными средствами для работы с файлами операционной системы: наблюдаемый размер файла — это лишь размер потока основных (традиционных) данных. Можно, к примеру, удалить файл нулевой длины, и при этом освободится несколько мегабайтов свободного места — просто потому, что какая-нибудь «хитрая» программа или технология назначила ему поток дополнительных (альтернативных) данных такого большого размера.
Модель отслеживания дисковых блоков состоит в том, что они выделяются последовательными участками, насколько это возможно (из соображений эффективности). Например, если первый логический блок потока помещен в блок 20 диска, то система будет очень стараться поместить второй логический блок в блок 21, третий логический блок — в блок 22 и т. д. Одним из способов достижения непрерывности этих участков является выделение дискового пространства по нескольку блоков за один раз (по мере возможности).
Блоки потока описываются последовательностью записей, каждая их которых описывает последовательность логически смежных блоков. Для потока без пропусков будет только одна такая запись. К этой категории принадлежат такие потоки, которые записаны по порядку с начала и до конца. Для потока с одним пропуском (например, определены только блоки 0-49 и блоки 60-79) будет две записи. Такой поток может быть получен при помощи записи первых 50 блоков, а затем пропуском до 60 блока и записи еще 20 блоков. Когда такой пропуск считывается, то все недостающие байты — нулевые. Файлы с пропусками называются разреженными файлами ( sparse files ). Каждая запись начинается с заголовка, в котором дается смещение первого блока потока. Затем идет смещение первого не описанного данной записью блока. В приведенном выше примере в первой записи будет заголовок (0,50) и будут даны дисковые адреса этих 50 блоков. Во второй записи будет заголовок (50,20) и дисковые адреса этих 20 блоков. За заголовком записи следует одна или несколько пар (в каждой дается дисковый адрес и длина участка). Дисковый адрес — это смещение дискового блока от начала раздела; длина участка — это количество блоков в участке. В записи участка может быть столько пар, сколько необходимо.
Доступ к файлу (получение информации, списка дисковых адресов файла) осуществляется по имени.
Каталог на NTFS представляет собой специфический файл, хранящий ссылки на другие файлы и каталоги, создавая иерархическое строение данных на диске. Файл каталога поделен на блоки, каждый из которых содержит имя файла, базовые атрибуты и ссылку на элемент MFT, который уже предоставляет полную информацию об элементе каталога. Внутренняя структура каталога представляет собой бинарное дерево. Вот что это означает: для поиска файла с данным именем в линейном каталоге, таком, например, как у FAT-а, операционной системе приходится просматривать все элементы каталога, пока она не найдет нужный. Бинарное же дерево располагает имена файлов таким образом, чтобы поиск файла осуществлялся более быстрым способом - с помощью получения двухзначных ответов на вопросы о положении файла. Вопрос, на который бинарное дерево способно дать ответ, таков: в какой группе, относительно данного элемента, находится искомое имя - выше или ниже? Мы начинаем с такого вопроса к среднему элементу, и каждый ответ сужает зону поиска в среднем в два раза. Файлы, скажем, просто отсортированы по алфавиту, и ответ на вопрос осуществляется очевидным способом - сравнением начальных букв. Область поиска, суженная в два раза, начинает исследоваться аналогичным образом, начиная опять же со среднего элемента.

Характеристики NTFS
| Характеристика | Значение |
| Максимальный размер диска | 16 Эбайт (1 Эбайт=264 бат=16 млрд Гбайт) |
| Минимальный размер диска | 10 Мбайт |
| Размер файла | 16 Эбайт |
| Количество записей в MFT | 248 |
| Длина пути | Не ограничена |
| Количество элементов в корневом каталоге | Не ограничено |
| Размер кластера | 1 – 128 сек = 512 – 64 Кбайт |
| Поддержка длинных имен | да |
Достоинства:
1) NTFS лучше всего подходит для использования с томами размером более 400 МБ. С увеличением размера тома производительность файловой системы NTFS не падает, как у FAT.
2) Благодаря способности к восстановлению в NTFS отсутствует необходимость использования каких-либо программ восстановления диска.
3) Папки и файлы NTFS могут иметь назначенные им права доступа. NTFSпозволяет назначать права доступа к различным файлам. Устанавливая пользователям определенные разрешения для файлов и каталогов, пользователь может защищать конфиденциальную информацию от несанкционированного доступа.
4) NTFS имеет встроенную поддержку сжатия дисков.
5) Следующее, очень полезное свойство файловой системы NTFS - это возможность введения квот. Это свойство, как правило необходимо системным администраторам, больших компаний, где работают большое количество пользователей, у которых нет привычки следить за актуальностью информации, и которые хранят ненужные файлы, тем самым занимая дисковое пространство. Так как администратор не может проследить за всем этим, он может ввести квоту на использование диска определенному пользователю. После установки квот пользователь может хранить на томе ограниченный объем данных, в то время как на этом диске может оставаться свободное пространство. Если пользователь превысит выданную ему квоту, в журнал событий будет внесена соответствующая запись. Чтобы включить квоты на диске нужно прежде всего, чтобы он был в формате NTFS, затем в свойствах папки (Вид) убрать флажок Использовать простой общий лоступ . Это нужно для того, чтобы в свойствах диска появилась вкладка Квота .
6) Размер кластера.
Недостатки:
1) Из-за дополнительного расхода дискового пространства файловую систему NTFS не рекомендуется использовать с томами размером менее 400 МБ. Такой расход объясняется необходимостью хранения системных файлов NTFS (в разделе размером 100 МБ для этого требуется около 4 МБ).
2) С помощью файловой системы NTFS нельзя форматировать дискеты. Windows NT форматирует дискеты с помощью FAT, так как объем служебной информации, необходимой для функционирования NTFS, не помещается на дискете.
3) Более высокие требования к объему оперативной памяти по сравнению с FAT 32/
4) Больший износ диска.