| Похожие рефераты | Скачать .docx |
Реферат: Елементи дисперсійного аналізу і теорії кореляції
ЕЛЕМЕНТИ ДИСПЕРСІЙНОГО АНАЛІЗУ
І ТЕОРІЇ КОРЕЛЯЦІЇ
Вступ
У більшості розділів математичної статистики передбачається, що кожний із усіх численних компонентів (факторів), які визначають характер поведінки випадкової величини, вносить у формування її значення дуже малий неконтрольований внесок, більш-менш однаковий за потужністю. На відміну від них у дисперсійному аналізі та у теорії кореляції досліджуються випадки наявності серед цих факторів величин, що є домінуючими у тій чи у іншій ступені аж впритул до необхідності їх інтерпретації як також випадкових величин і з'ясування їхнього взаємозв'язку з основною випадковою величиною.
1 Сутність і задачі дисперсійного аналізу. Однофакторний дисперсійний аналіз
Нехай є ![]() груп сукупностей, кожна з яких характеризується випадковою величиною
груп сукупностей, кожна з яких характеризується випадковою величиною ![]() . Це можуть бути підмножини однієї генеральної сукупності чи різні генеральні сукупності. При цьому кожна група сукупностей відповідає визначеному рівню досліджуваного фактора
. Це можуть бути підмножини однієї генеральної сукупності чи різні генеральні сукупності. При цьому кожна група сукупностей відповідає визначеному рівню досліджуваного фактора ![]() (
(![]() ,
, ![]() ,
, ![]() , ... ,
, ... , ![]() ), який якось впливає на випадкову величину
), який якось впливає на випадкову величину ![]() . Рівні фактора
. Рівні фактора ![]() можуть бути фіксованими (обраними і визначеними заздалегідь) чи випадковими, тобто такими, коли кількісний рівень фактора визначається випадковим чином. Крім того, рівні фактора можуть не мати кількісної міри, а розрізнятися між собою тільки якісно.
можуть бути фіксованими (обраними і визначеними заздалегідь) чи випадковими, тобто такими, коли кількісний рівень фактора визначається випадковим чином. Крім того, рівні фактора можуть не мати кількісної міри, а розрізнятися між собою тільки якісно.
Введемо наступні основні обмеження, що накладаються на розглянуту модель:
– випадкові величини ![]() ,
, ![]() ,
, ![]() , ... ,
, ... , ![]() у кожній групі розподілені нормально з математичними сподіваннями
у кожній групі розподілені нормально з математичними сподіваннями ![]() ,
, ![]() ,
, ![]() , ,
, , ![]() і дисперсіями
і дисперсіями ![]() ,
, ![]() ,
, ![]() , ,
, , ![]() ;
;
– дисперсії у групах є рівними між собою, тобто ![]() ;
;
– вибірки, що організовані з ![]() груп сукупностей, є незалежними.
груп сукупностей, є незалежними.
Будь-яке значення випадкової величини ![]() (кількісної характеристики розглянутих сукупностей) може бути поданим у вигляді наступної лінійної моделі
(кількісної характеристики розглянутих сукупностей) може бути поданим у вигляді наступної лінійної моделі
![]() (1)
(1)
де:
![]() –
– ![]() -е значення у групі
-е значення у групі ![]() (при рівні фактора
(при рівні фактора ![]() );
);
![]() – компонента, що обумовлена рівнем
– компонента, що обумовлена рівнем ![]() фактора
фактора ![]() (факторна компонента);
(факторна компонента);
![]() – постійний компонент, що залежить тільки від природи випадкової величини і є незалежним від рівня фактора
– постійний компонент, що залежить тільки від природи випадкової величини і є незалежним від рівня фактора ![]() ;
;
![]() – "похибка" лінійної моделі, що подає собою залишок, який утвориться після вирахування
– "похибка" лінійної моделі, що подає собою залишок, який утвориться після вирахування ![]() і
і ![]() з усього результату випробування, тобто випадкова компонента, що враховує вплив усіх інших факторів, крім розглянутого чинника
з усього результату випробування, тобто випадкова компонента, що враховує вплив усіх інших факторів, крім розглянутого чинника ![]() .
.
Модель (1) відображає те, що у формуванні значення ![]() беруть участь дві компоненти: факторна і випадкова. Якщо припустити, що випадкова компонента відсутня і для різних рівнів фактора
беруть участь дві компоненти: факторна і випадкова. Якщо припустити, що випадкова компонента відсутня і для різних рівнів фактора ![]() отримано по одному невипадковому значенню
отримано по одному невипадковому значенню ![]() ,
, ![]() ,
, ![]() , ... ,
, ... , ![]() , то як показник впливу фактора можна застосувати нормовану суму квадратів відхилень
, то як показник впливу фактора можна застосувати нормовану суму квадратів відхилень ![]() від їх середнього значення
від їх середнього значення
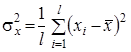 (2)
(2)
де
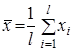
Цю величину, подібну до (2), можна назвати дисперсією фактора ![]() (факторною дисперсією), хоча вона не є характеристикою випадкової величини.
(факторною дисперсією), хоча вона не є характеристикою випадкової величини.
Порівнюючи цю факторну дисперсію з дисперсією випадкової компоненти, що називають дисперсією відтворюваності ![]() , можна зробити висновок про значущість (чи незначущість) їхньої відмінності.
, можна зробити висновок про значущість (чи незначущість) їхньої відмінності.
Якщо факторна дисперсія і дисперсія відтворюваності розрізняються значущо, то слід визнати вплив досліджуваного фактора на результати випробування, а якщо вони розрізняються суттєво, то роблять статистичний висновок про те, що вплив фактора є несуттєвим.
При цьому вивчати вплив фактора ![]() на наслідки випробувань слід не на результатах окремих дослідів, а на середніх значеннях, отриманих при фіксованих рівнях фактора, тому що дисперсії середніх менше дисперсії самої випадкової величини і вплив фактора (якщо він є) проявиться більш наочно.
на наслідки випробувань слід не на результатах окремих дослідів, а на середніх значеннях, отриманих при фіксованих рівнях фактора, тому що дисперсії середніх менше дисперсії самої випадкової величини і вплив фактора (якщо він є) проявиться більш наочно.
Таким чином, за нульову гіпотезу, що буде перевірятися за допомогою дисперсійного аналізу, висувається статистична гіпотеза про рівність математичних сподівань по рівнях фактора ![]()
![]() :
: ![]() (3)
(3)
проти альтернативної гіпотези ![]() : "не менш двох математичних сподівань є різними".
: "не менш двох математичних сподівань є різними".
Припустимо, що для кожного з ![]() рівнів фактора
рівнів фактора ![]() (
(![]() ,
, ![]() ,
, ![]() , ... ,
, ... , ![]() ) отримано
) отримано ![]() значень випадкової величини
значень випадкової величини ![]() , що характеризує досліджувану сукупність (усього
, що характеризує досліджувану сукупність (усього ![]() значень). Результати випробувань подані в таблиці 1.
значень). Результати випробувань подані в таблиці 1.
Обчислимо середнє ![]() по
по ![]() вимірах окремо для кожного рівня фактора, а також загальну середню
вимірах окремо для кожного рівня фактора, а також загальну середню ![]() за всіма
за всіма ![]() спостереженнями
спостереженнями
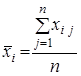 ,
, 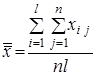 (4)
(4)
Таблиця 1
| Номер випробування | Рівень фактора | |||||
| ... | ... | |||||
| 1 | ... | |||||
| 2 | ... | |||||
| ... | ||||||
| ... | ... | |||||
| ... | ||||||
| ... | ... | |||||
| ... | ... | |||||
Повну суму квадратів відхилень усіх значень від загальної середньої, при обчисленні якої спільно врахуються факторна та випадкова компоненти, можна розкласти на суму двох складових, що подають ці фактори роздільно
 (5)
(5)
Для перетворення цих сум у відповідні дисперсії необхідно їх поділити на відповідні кількості ступенів волі, результати чого представлено в табл. 2, яку називають таблицею однофакторного дисперсійного аналізу.
Таблица 2
| Компонента | Сума квадратів | Число ступенів волі | Дисперсія |
| Факторна | 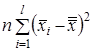 |
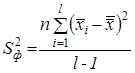 (6) (6) |
|
| Залишкова | 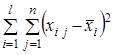 |
 (7) (7) |
|
| Повна | 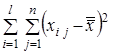 |
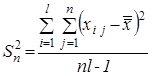 |
Для того, щоб перевірити тепер нульову гіпотезу про рівність математичних сподівань за рівнями фактора ![]() (3), необхідно за критерієм Фішера порівняти факторну
(3), необхідно за критерієм Фішера порівняти факторну ![]() (6) і залишкову дисперсії
(6) і залишкову дисперсії ![]() (7).
(7).
Для цього проведемо розрахунок статистики критерію

і порівняємо її з критичною точкою при рівні значущості ![]() і таких ступенях волі
і таких ступенях волі
![]() ,
, ![]()
![]()
Якщо
![]()
то нульову гіпотезу приймають, тобто при заданому рівні значущості ![]() приймають рішення про те, що вплив фактора
приймають рішення про те, що вплив фактора ![]() можна вважати несуттєвим.
можна вважати несуттєвим.
Якщо
![]()
то вплив фактора ![]() визнають значимим.
визнають значимим.
Отже, метод дисперсійного аналізу складається в перевірці нульової гіпотези про рівність групових середніх нормальних сукупностей з однаковими дисперсіями. Для цього досить перевірити за критерієм ![]() нульову гіпотезу про рівність факторної і залишкової дисперсій.
нульову гіпотезу про рівність факторної і залишкової дисперсій.
2 Поняття про кореляцію і регресію
Оцінка залежності між випадковими величинами та поява можливості прогнозувати при цьому значення однієї випадкової величини за значеннями іншої випадкової величини є важливою проблемою статистичного аналізу.
2.1 Функціональна, статистична і кореляційна залежності
Дві випадкові величини можуть бути незалежними або пов'язаними між собою визначеною функціональною залежністю, або залежністю особливого типу, що називається статистичною (стохастичною).
Статистичною називають залежність, при якій зміна однієї з випадкових величин спричиняє зміну розподілу іншої випадкової величини. Статистична залежність виявляється зокрема в тому, що при зміні однієї з величин змінюється середнє значення іншої; при цьому статистичну залежність називають кореляційною.
Прикладом такої кореляційної залежності є зв'язок між внесеними в землю добривами і отриманим врожаєм зерна. Відомо, що твердого функціонального зв'язку між цими величинами немає у зв'язку з впливом безлічі випадкових факторів (опади, температура повітря й ін.). Однак досвід свідчить, що зміна кількості внесених добрив змінює середню врожайність.
2.2 Умовне математичне сподівання, коефіцієнт кореляції і регресія двовимірної випадкової величини в теорії ймовірностей
У теорії ймовірностей при описі системи двох випадкових величин ![]() і
і ![]() було введено поняття умовного математичного сподівання (регресії) для дискретних і для неперервних випадкових величин, відповідно
було введено поняття умовного математичного сподівання (регресії) для дискретних і для неперервних випадкових величин, відповідно

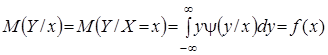
де ![]() – визначене можливе значення випадкової величини
– визначене можливе значення випадкової величини ![]() ;
; ![]() (
(![]() ) – можливі значення величини
) – можливі значення величини ![]() ;
; ![]() – відповідні умовні ймовірності;
– відповідні умовні ймовірності; ![]() – умовна щільність ймовірності випадкової величини
– умовна щільність ймовірності випадкової величини ![]() при
при ![]() ;
; ![]() – функція регресії
– функція регресії ![]() на
на ![]()
![]() (8)
(8)
– рівняння регресії ![]() на
на ![]() .
.
Аналогічно визначаються умовне математичне сподівання випадкової величини ![]() і функція, а також рівняння регресії
і функція, а також рівняння регресії ![]() на
на ![]() :
:
![]() (9)
(9)
Функції ![]() і
і ![]() (рівняння регресії), що уявляють інтерес, у загальному випадку невідомі, тому їх шукають у наближеному вигляді, причому звичайно обмежуються лінійним наближенням:
(рівняння регресії), що уявляють інтерес, у загальному випадку невідомі, тому їх шукають у наближеному вигляді, причому звичайно обмежуються лінійним наближенням:
![]() (10)
(10)
де ![]() і
і ![]() – параметри, що підлягають визначенню. Найчастіше для цього вживають метод найменших квадратів.
– параметри, що підлягають визначенню. Найчастіше для цього вживають метод найменших квадратів.
Функцію ![]() називають "найкращим наближенням"
називають "найкращим наближенням" ![]() у сенсі методу найменших квадратів, якщо математичне сподівання
у сенсі методу найменших квадратів, якщо математичне сподівання
![]() (11)
(11)
приймає найменше можливе значення. При цьому функцію ![]() називають середньоквадратичною регресією
називають середньоквадратичною регресією ![]() на
на ![]() .
.
У теорії ймовірностей доведено, що лінійна середня квадратична регресія ![]() на
на ![]() має вигляд
має вигляд
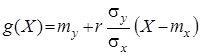
де
![]() ,
, ![]() ,
,
![]() ,
, ![]() ,
,
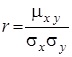 – коефіцієнт кореляції величин
– коефіцієнт кореляції величин ![]() і
і ![]() ,
,
![]() – кореляційний момент цих величин.
– кореляційний момент цих величин.
Можна показати, що кореляційний момент ![]() характеризує зв'язок між величинами
характеризує зв'язок між величинами ![]() і
і ![]() , зокрема, якщо вони незалежні, то
, зокрема, якщо вони незалежні, то
![]()
Коефіцієнт

називають коефіцієнтом регресії ![]() на
на ![]() , а пряму
, а пряму
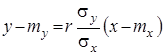 (12)
(12)
називають прямою середньоквадратичної регресії ![]() на
на ![]() .
.
При підстановці знайдених значень ![]() і
і ![]() у формулу (11) отримуємо мінімальне значення функції
у формулу (11) отримуємо мінімальне значення функції ![]() , що дорівнює
, що дорівнює
![]()
Цю величину називають залишковою дисперсією випадкової величини ![]() щодо випадкової величини
щодо випадкової величини ![]() . Вона характеризує похибку, що виникає під час заміни
. Вона характеризує похибку, що виникає під час заміни ![]() лінійною функцією (10). При
лінійною функцією (10). При ![]() залишкова дисперсія дорівнює нулю, тобто в цих випадках лінійна функція (10) точно подає випадкову величину
залишкова дисперсія дорівнює нулю, тобто в цих випадках лінійна функція (10) точно подає випадкову величину ![]() . Це означає, що при цьому
. Це означає, що при цьому ![]() та
та ![]() пов'язані лінійною функціональною залежністю.
пов'язані лінійною функціональною залежністю.
Аналогічний вигляд має і пряма середньоквадратичної регресії ![]() на
на ![]()
 (13)
(13)
Очевидно, що обидві прямі регресії (12) і (13) проходять через спільну точку ![]() , яка називається центром спільного розподілу величин
, яка називається центром спільного розподілу величин ![]() і
і ![]() . Якщо коефіцієнт кореляції
. Якщо коефіцієнт кореляції ![]() дорівнює нулю, то пряма регресії
дорівнює нулю, то пряма регресії ![]() на
на ![]() (12) є паралельною осі
(12) є паралельною осі ![]() , а пряма регресії
, а пряма регресії ![]() на
на ![]() (13) – паралельна осі
(13) – паралельна осі ![]() , тобто вони є взаємно ортогональні. Крім того, при
, тобто вони є взаємно ортогональні. Крім того, при ![]() обидві прямі регресії співпадають.
обидві прямі регресії співпадають.
Таким чином, значення кута між прямими регресії (12) і (13) характеризує тісноту зв’язку між випадковими величинами: чим менше кут, тим більш тісною є зв’язок.
2.3 Умовне середнє і вибіркова регресія
У математичній статистиці вводять вибіркові оцінки умовного математичного сподівання і регресії. У якості оцінки умовного математичного сподівання ![]() беруть умовне середнє
беруть умовне середнє ![]() , яке знаходять за вибірковими даними спостережень.
, яке знаходять за вибірковими даними спостережень.
Умовним середнім ![]() називається середнє арифметичне значень випадкової величини
називається середнє арифметичне значень випадкової величини ![]() , що спостерігаються за умови, яка випадкова величина
, що спостерігаються за умови, яка випадкова величина ![]() при цьому має значення
при цьому має значення ![]() . Аналогічно визначається і умовне середнє
. Аналогічно визначається і умовне середнє ![]() , однак надалі для стислості викладення обмежимося в основному розглядом тільки
, однак надалі для стислості викладення обмежимося в основному розглядом тільки ![]() і пов'язаними з ним питаннями.
і пов'язаними з ним питаннями.
Також як і умовне математичне сподівання ![]() , його вибіркова оцінка є функцією від змінної
, його вибіркова оцінка є функцією від змінної ![]() , що позначимо через
, що позначимо через ![]() і будемо називати вибірковою регресією
і будемо називати вибірковою регресією ![]() на
на ![]() , а її графік – вибірковою лінією регресії
, а її графік – вибірковою лінією регресії ![]() на
на ![]() . Крім того, за аналогією з рівняннями (8) і (9) вводяться вибіркові рівняння регресії
. Крім того, за аналогією з рівняннями (8) і (9) вводяться вибіркові рівняння регресії ![]() на
на ![]() і
і ![]() на
на ![]() , відповідно
, відповідно
![]() (14)
(14)
![]() (15)
(15)
2.4 Визначення параметрів вибіркового рівняння прямої лінії середньоквадратичної регресії за незгрупованих даних
Нехай під час дослідження кількісних ознак (![]() ,
, ![]() ) у результаті
) у результаті ![]() незалежних випробувань отримано
незалежних випробувань отримано ![]() пар чисел:
пар чисел: ![]() ,
,![]() ,...,
,...,![]() . Будемо шукати функцію
. Будемо шукати функцію ![]() в лінійному наближенні (все аналогічно проводиться і для функції
в лінійному наближенні (все аналогічно проводиться і для функції ![]() у випадку регресії
у випадку регресії ![]() на
на ![]() ). Крім того, у припущенні незгрупованих даних спостережень (різні значення
). Крім того, у припущенні незгрупованих даних спостережень (різні значення ![]() ознаки
ознаки ![]() і відповідні їм значення
і відповідні їм значення ![]() ознаки
ознаки ![]() спостерігалися по одному разу)
спостерігалися по одному разу) ![]() і
і ![]() можна замінити на
можна замінити на ![]() і
і ![]() . Під час цього рівняння прямої лінії регресії
. Під час цього рівняння прямої лінії регресії ![]() на
на ![]() можна подати у вигляді
можна подати у вигляді
![]() (16)
(16)
Кутовий коефіцієнт ![]() прямої (16) називається вибірковим коефіцієнтом регресії
прямої (16) називається вибірковим коефіцієнтом регресії ![]() на
на ![]() і позначається
і позначається ![]() . Він є оцінкою коефіцієнта регресії
. Він є оцінкою коефіцієнта регресії ![]() в рівнянні (10). Тепер рівняння (16) можна переписати
в рівнянні (10). Тепер рівняння (16) можна переписати
![]() (17)
(17)
Підберемо параметри ![]() і
і ![]() так, щоб сума квадратів відхилень прямої (17) від точок
так, щоб сума квадратів відхилень прямої (17) від точок ![]() ,
,![]() ,...,
,...,![]() , побудованих за даними спостережень, була б мінімальною
, побудованих за даними спостережень, була б мінімальною
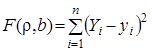 (18)
(18)
де
![]() – ордината, що спостерігається, і є відповідною до
– ордината, що спостерігається, і є відповідною до ![]() ,
,
![]() – ордината точки, що лежить на прямій (17) і має абсцису
– ордината точки, що лежить на прямій (17) і має абсцису ![]() ,
,
![]() .
.
Підставивши значення ![]() з рівняння (17) у формулу (18), одержимо
з рівняння (17) у формулу (18), одержимо
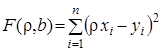 (19)
(19)
Дорівнявши нулю частинні похідні ![]() і
і ![]() функції (19) одержимо систему двох лінійних алгебраїчних рівнянь щодо параметрів
функції (19) одержимо систему двох лінійних алгебраїчних рівнянь щодо параметрів ![]() і
і ![]() для знаходження точки її мінімуму
для знаходження точки її мінімуму
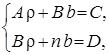 (20)
(20)
де
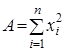 ,
,  ,
, 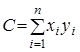 ,
, 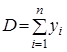
звідкіля остаточно знаходимо
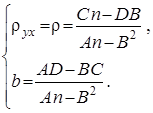
Аналогічно визначається вибіркове рівняння прямої лінії регресії ![]() на
на ![]() .
.
2.5 Знаходження параметрів вибіркового рівняння прямої лінії середньоквадратичної регресії за згрупованими даними
При великій кількості спостережень одне й те ж саме значення ![]() може зустрітися
може зустрітися ![]() раз, значення
раз, значення ![]() –
– ![]() раз, одна й та ж пара чисел
раз, одна й та ж пара чисел ![]() може спостерігатися
може спостерігатися ![]() раз. Тому дані спостережень групують, тобто підраховують відповідні частоти
раз. Тому дані спостережень групують, тобто підраховують відповідні частоти ![]() ,
, ![]() ,
, ![]() . Усі згруповані дані записують у вигляді таблиці, що називають кореляційною.
. Усі згруповані дані записують у вигляді таблиці, що називають кореляційною.
Приклад такої таблиці приведено нижче (табл. 3).
Таблиця 3
| 10 | 20 | 30 | 40 | ||
| 0,4 | 5 | – | 7 | 14 | 26 |
| 0,6 | – | 2 | 6 | 4 | 12 |
| 0,8 | 3 | 19 | – | – | 22 |
| 8 | 21 | 13 | 18 | ||
У першому рядку цієї таблиці дано перелік значень (10; 20; 30; 40) ознаки ![]() , що спостерігаються, а в першому стовпці – спостерігаємі значення (0,4; 0,6; 0,8) ознаки
, що спостерігаються, а в першому стовпці – спостерігаємі значення (0,4; 0,6; 0,8) ознаки ![]() . На перетинанні рядків і стовпчиків знаходяться частоти
. На перетинанні рядків і стовпчиків знаходяться частоти ![]() пар значень ознак. Наприклад, частота 5 вказує, що пара чисел (10; 0,4) спостерігається 5 разів. Риска означає, що відповідна пара чисел, наприклад (20; 0,4), не спостерігається.
пар значень ознак. Наприклад, частота 5 вказує, що пара чисел (10; 0,4) спостерігається 5 разів. Риска означає, що відповідна пара чисел, наприклад (20; 0,4), не спостерігається.
В останньому стовпчикові записані суми частот рядків. В останньому рядку записані суми частот стовпчиків. У нижньому правому куті таблиці, поміщена сума всіх частот (загальна кількість всіх спостережень ![]() ).
).
У випадку згрупованих даних з урахуванням очевидних співвідношень
![]() ,
, ![]() ,
, ![]() ,
, ![]()
систему рівнянь (20) можна переписати у виправленому вигляді
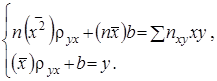
З рішення цієї системи (![]() ,
, ![]() ) знаходимо рівняння прямої регресії
) знаходимо рівняння прямої регресії
![]()
Шляхом нескладних перетворень його можна переписати у вигляді
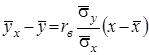
де ![]() ,
,![]() – вибіркові середні квадратичні відхилення величин
– вибіркові середні квадратичні відхилення величин ![]() і
і ![]()
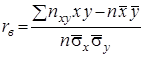 (21)
(21)
– вибірковий коефіцієнт кореляції.
Вибірковий коефіцієнт кореляції. Як відомо з теорії ймовірностей, якщо величини ![]() і
і ![]() незалежні, коефіцієнт їхньої кореляції
незалежні, коефіцієнт їхньої кореляції ![]() , якщо
, якщо ![]() – величини
– величини ![]() і
і ![]() пов'язані лінійною функціональною залежністю. Тобто коефіцієнт кореляції
пов'язані лінійною функціональною залежністю. Тобто коефіцієнт кореляції ![]() характеризує ступінь лінійного зв'язку між
характеризує ступінь лінійного зв'язку між ![]() і
і ![]() .
.
Вибірковий коефіцієнт кореляції ![]() є оцінкою коефіцієнта кореляції
є оцінкою коефіцієнта кореляції ![]() генеральної сукупності, тому він також характеризує міру лінійного зв'язку між величинами
генеральної сукупності, тому він також характеризує міру лінійного зв'язку між величинами ![]() і
і ![]() .
.
3 Поняття про криволінійну кореляцію
Раніше ми обмежилися лінійним наближенням функцій регресії, рівнянь регресії, відповідно і кореляційного зв'язку. Однак теорію можна узагальнити і на наступні наближення.
Нехай дані спостережень над кількісними ознаками ![]() і
і ![]() зведено до кореляційної таблиці. Тим самим значення
зведено до кореляційної таблиці. Тим самим значення ![]() , що спостерігаються, розбито на групи; кожна група містить ті значення
, що спостерігаються, розбито на групи; кожна група містить ті значення ![]() , що відповідають визначеному значенню
, що відповідають визначеному значенню ![]() . Для приклада розглянемо кореляційну таблицю 4.
. Для приклада розглянемо кореляційну таблицю 4.
Таблиця 4
| 10 | 20 | 30 | ||
| 15 | 4 | 28 | 6 | 38 |
| 25 | 6 | – | 6 | 12 |
| 10 | 28 | 12 | ||
| 21 | 15 | 20 | ||
До першої групи відносяться ті 10 значень ![]() (4 рази спостерігалося значення
(4 рази спостерігалося значення ![]() і 6 разів
і 6 разів ![]() ), що відповідають
), що відповідають ![]() . До другої групи – ті 28 значень
. До другої групи – ті 28 значень ![]() (28 разів спостерігалося
(28 разів спостерігалося ![]() і 0 разів
і 0 разів ![]() ), що відповідають
), що відповідають ![]() . До третьої групи відносяться 12 значень
. До третьої групи відносяться 12 значень ![]() (6 разів спостерігалося
(6 разів спостерігалося ![]() і 6 разів
і 6 разів ![]() ).
).
Умовні середні тепер можна назвати груповими середніми: групова середня першої групи
![]()
групова середня другої групи
![]()
для третьої групи
![]()
Оскільки всі значення ознаки ![]() розбито на групи, можна уявити загальну дисперсію ознаки у вигляді суми внутрішньо групової і міжгрупової дисперсій
розбито на групи, можна уявити загальну дисперсію ознаки у вигляді суми внутрішньо групової і міжгрупової дисперсій
![]()
Можна показати, що, якщо між величинами ![]() і
і ![]() є функціональна залежність, то
є функціональна залежність, то
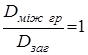
якщо ж вони пов'язані кореляційною залежністю, то

Вибіркове кореляційне відношення. Для оцінки ступені тісноти лінійного кореляційного зв'язку між ознаками у вибірці застосовується вибірковий коефіцієнт кореляції (21). У разі нелінійного кореляційного зв'язку з тою ж метою вводяться нові узагальнені характеристики:
![]() – вибіркове кореляційне відношення
– вибіркове кореляційне відношення ![]() до
до ![]() ;
;
![]() – вибіркове кореляційне відношення
– вибіркове кореляційне відношення ![]() к.
к.![]()
Вони визначаються за формулами:
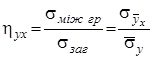 ,
, 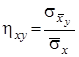
Похожие рефераты:
Курс лекций по анализу экономической деятельности
Шпаргалки к экзамену по истории
Шпаргалки к госэкзамену по экономике и праву
Административное право (шпаргалка)
Шпоры по экономике предприятия 1 курс
Диференційована гіпнотерапія в комплексному лікуванні дітей з неорганічним нічним енурезом
Информатика - шпаргалка на украинском языке