| Скачать .docx |
Реферат: Проведение выборочного наблюдения
Федеральное агентство по образованию
Государственное образовательное учреждение высшего профессионального образования
«Санкт-Петербургский государственный политехнический университет»
Факультет экономики и менеджмента
Кафедра «Предпринимательство и коммерция»
ЛАБОРАТОРНАЯ РАБОТА №2
По дисциплине «Статистика»
На тему
«Проведение выборочного наблюдения»
Санкт-Петербург 2008
Целью лабораторной работы является освоение методики организации и проведения выборочного наблюдения; статистических методов и методов компьютерной обработки полученной информации; методов оценки параметров генеральной совокупности на основе выборочных данных.
Выборочное наблюдение – важнейший вид не сплошного наблюдения. Теория выборочного наблюдения, т.н. выборочный метод, – совокупность принципов и способов отбора единиц совокупности, а также способов и методов оценки параметров генеральной совокупности на основе выборочных единиц. Выборочный метод в настоящее время получил широкое практическое применение, поскольку обладает целым рядом преимуществ по сравнению со сплошным наблюдением и иными видами несплошного наблюдения.
Преимущества выборочного наблюдения по сравнению со сплошным:
1. Экономия времени, финансовых, трудовых, материальных ресурсов.
2. Возможность расширить программу наблюдения.
С другими видами не сплошного наблюдения:
3. Благодаря хорошо разработанной теории выборки и используемых при выборочных наблюдениях способах формирования выборки появляется возможность дать вероятностную оценку параметров генеральной совокупности.
Генеральная совокупность – совокупность, которая собственно интересует исследователя и из которой отбираются единицы в выборочную совокупность. Выборочная совокупность – совокупность отобранных единиц, по которым будут фиксироваться значения тех или иных признаков.
Основной принцип формирования выборочной совокупности – случайность отбора, т.е. всем единицам генеральной совокупности должна быть обеспечена равная вероятность попадания в выборку. Этот принцип обеспечивает объективность выборочного наблюдения, поскольку позволяет сформировать репрезентативную выборку. Репрезентативность способствует получению несмещённой выборки, т.е. структура или закономерность распределения в выборочной совокупности соответствует распределению единиц в генеральной совокупности.
Способы отбора единиц в выборочную совокупность:
1. Случайный отбор. Реализуют методом жеребьёвки или с использованием таблиц случайных чисел.
2. Механический отбор – частный случай случайного отбора. Рассчитывается шаг отбора, который равен отношению объёма совокупности к объёму выборки: ![]() .
.
Отбор может проводиться по принципу бесповторного отбора, когда, извлекаемая из генеральной совокупности, единица назад не возвращается, и повторного отбора [1].
Виды выборки:
1. Собственно случайная.
2. Типологическая (стратифицированная).
3. Гнездовая (серийная).
4. Многоступенчатая.
5. Многофазная.
Лабораторная работа выполнена на основе исходных данных первой лабораторной: данные сборника Росстата Регионы России [2], а именно статистическая информация о числе собственных легковых автомобилей на 1000 человек населения в различных регионах России в 1990 году. Объём исходной совокупности – 88 единиц.
1. Расчёт необходимого объёма выборочной совокупности
Ошибка выборки – это различие в значениях какого-либо параметра генеральной совокупности и его оценки, полученной на основе выборки. Ошибка выборки присутствует всегда, т.к. её возникновение связано с самой сутью выборочного наблюдения: по части судят о целом. Распределение единиц выборочной совокупности не может в полной мере соответствовать распределению единиц генеральной совокупности. Понятию ошибки выборки и методике её определения посвящены многие работы теории выборки (учёные – Я. Бернулли, П.Л. Чебышев, А.М. Ляпунов, А.А. Марков, А.А. Чупров и др.).
Теорема Чебышева. При неограниченном увеличении числа наблюдений в генеральной совокупности с ограниченной дисперсией с вероятностью, близкой к единице, можно утверждать, что величина ошибки выборки не превысит сколь угодно малой положительной величины ξ.
![]()
![]() ,
,
где ![]() – выборочное среднее,
– выборочное среднее, ![]() – генеральное среднее,
– генеральное среднее, ![]() – вероятность события, заключённого в скобки.
– вероятность события, заключённого в скобки.
Теорема Чебышева доказывает принципиальную возможность оценки параметров генеральной совокупности на основе выборочных данных, утверждая, что в условиях большой выборки вероятность получить незначительную величину ошибки близка к 1. Однако, практически не ясно, чему равна эта вероятность, и какова величина ошибки выборки.
Теорема Ляпунова. При неограниченном увеличении числа наблюдений в генеральной совокупности с ограниченной дисперсией вероятность того, что ошибка выборки не превысит величины tμ, равна нормированной функции Лапласа:
![]() ,
,
где μ – средняя ошибка выборки, 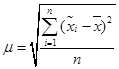 ,
, ![]() – среднее выборочное по i‑й выборке, n – число выборок.
– среднее выборочное по i‑й выборке, n – число выборок.
Математической статистикой доказано, что величина μ2
прямо пропорциональна дисперсии генеральной совокупности (s2
) и обратно пропорциональна объёму выборки (n): ![]() .
.
Известно, что ![]() (S2
– дисперсия выборки). Если выборка большого объёма, то
(S2
– дисперсия выборки). Если выборка большого объёма, то ![]() , следовательно, на практике сомножитель
, следовательно, на практике сомножитель ![]() опускают и
опускают и ![]() .
.
Предельная ошибка выборки ![]() . Плотность нормального распределения:
. Плотность нормального распределения: ![]() , где нормированное отклонение выборочной средней от генеральной средней
, где нормированное отклонение выборочной средней от генеральной средней ![]() .
.
Данное исследование проводится с вероятностью 0,95. Этому значению в таблице Лапласа соответствует t=1,96, которое на практике округляют до 2. В этом случае ![]() . Тогда
. Тогда ![]() .
.
Важным вопросом подготовки выборочного наблюдения является определение объема выборочной совокупности, необходимой и достаточной для оценки тех или иных свойств генеральной совокупности. В практике экономико-статистических исследований, как правило, используется процедура бесповторного отбора единиц в выборочную совокупность. Первым этапом подготовки выборочного наблюдения является расчет объема выборки. Расчет, как правило, проводится по следующей формуле: ![]() [3].
[3].
Расчёт объёма выборки проводится многократно с учётом разной величины ошибки и с разным уровнем вероятности. По полученным результатам выбирают оптимальный вариант. В лабораторной работе будет сформировано три выборки, объёмом 70, 25 и 15 единиц каждая.
2. Формирование выборочных совокупностей и обработка выборочных данных
Методом случайного бесповторного отбора формируются большая (70 единиц) и две малых выборки (25 и 15 единиц). Затем, при помощи ППП Statistica рассчитываются основные статистические характеристики, данные занесены в таблицу ниже.
Таблица 2.1 . Основные статистические характеристики выборок

В таблице 2.1 «NewVar1» обозначает выборку размером 70 единиц, «NewVar2» – 25 единиц, «NewVar3» – 15 единиц. В графе «Mean» указаны значения средних по каждой выборке, «Std. Dv.» – стандартное отклонение, «N» – объём выборки, «Std. Err.» – средняя ошибка выборки, «Confidence -95,000%» и «Confidence +95,000%» – соответственно нижняя и верхняя границы доверительного интервала при вероятности 95%, «Reference» – гипотетическое значение генеральной средней величины (известно из первой лабораторной работы), «t-value» – расчетное значение t‑критерия для проверки гипотезы о значении генеральной средней, «df» – число степеней свободы, «p» – расчетный уровень значимости t‑критерия.
Среднее значение выборки, состоящей из 70 единиц, равно 53,64286, оно отличается от генеральной средней на 2,06309, величина среднеквадратического отклонения равна 16,66183. Средняя ошибка этой выборки – 1,991470, а интервал оптимальности ![]() , т.е. с вероятностью 95% можно утверждать, что в среднем по России число собственных легковых автомобилей на 1000 человек населения в 1990 году находилось в указанных пределах. Расчётное значение t-критерия составляет -1,03596, меньше 2, следовательно, различия между генеральной и выборочной средней случайны, и выборочное среднее является достоверной оценкой генеральной средней. Расчётный уровень значимости t-критерия также подтверждает это (
, т.е. с вероятностью 95% можно утверждать, что в среднем по России число собственных легковых автомобилей на 1000 человек населения в 1990 году находилось в указанных пределах. Расчётное значение t-критерия составляет -1,03596, меньше 2, следовательно, различия между генеральной и выборочной средней случайны, и выборочное среднее является достоверной оценкой генеральной средней. Расчётный уровень значимости t-критерия также подтверждает это (![]() ).
).
3. Распространение результатов выборочного наблюдения на генеральную совокупность
Теперь необходимо провести оценку существенности разности двух выборочных средних. Если разность между средними величинами статистически значима, это означает, что различие вызвано неслучайными факторами, или выборки не принадлежат одной генеральной совокупности. Иначе эта задача формулируется как проверка статистической гипотезы о равенстве двух средних: ![]() .
.
В лабораторной работе содержательно гипотеза формулируется следующим образом: взяты выборки из одной или из разных генеральных совокупностей? В контексте решаемой задачи ответ очевиден – выборки взяты из одной и той же совокупности. Но следует обратить особое внимание на проявление эффекта случайной ошибки репрезентативности. Реализация процедуры проверки гипотезы может дать, в редких случаях, парадоксальный результат, а именно, показать на основе t‑критерия, что выборки как бы взяты из разных генеральных совокупностей с разными значениями средних величин. С дидактической точки зрения такой результат весьма полезен для понимания существа статистических выводов и степени их условности. Для демонстрации этого эффекта рекомендуется взять такие две выборки, из ранее полученных, для которых разность между средними выборочными значениями максимальна [3].
В данной работе для сравнения взяты выборки, объёмом 70 и 25 единиц. Результаты анализа занесены в таблицу ниже.
Таблица 3.1 . Результаты расчёта t-критерия для выборок, объёмом 70 и 25 единиц
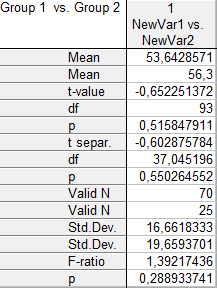
В полученной таблице рассчитаны следующие показатели:
- Mean – среднее значение по двум выборкам.
- t-value – t‑критерий, необходимый для оценки существенности разности двух средних: 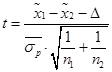 , т. к.
, т. к. ![]() , то
, то 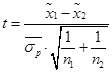 .
.
- df – число степеней свободы.
- p – расчётный уровень значимости t‑критерия.
- t-separ– расчетное значение t‑критерия с учетом различных дисперсий. Очевидно, что в этом примере оно не изменяется, однако программа выдаёт другой результат.
- df – число степеней свободы t‑критерия при условии неравных дисперсий. 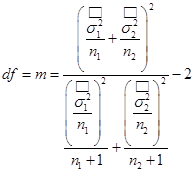 . Расчетное значение mокругляется до целого значения в силу того, что число степеней свободы есть целое число по определению.
. Расчетное значение mокругляется до целого значения в силу того, что число степеней свободы есть целое число по определению.
- p– расчетный уровень значимости t‑критерия при условии неизвестных и неравных дисперсий.
- ValidN – объём каждой выборки.
- Std. Dev. – среднее квадратическое отклонение: 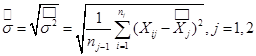
- F-ratio– F‑критерий (дисперсионное отношение), используемый для оценки существенности различия значений двух дисперсий: 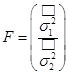 .
.
- p –расчетный уровень значимости P‑критерия.
Гипотеза принимается, если ![]() . Здесь
. Здесь ![]() . Табличное значение t‑критерия равно
. Табличное значение t‑критерия равно ![]() . Таким образом
. Таким образом ![]() , следовательно, испытуемая гипотеза принимается. Аналогичный вывод можно получить на основе сравнения расчетного и принятого уровней значимости:
, следовательно, испытуемая гипотеза принимается. Аналогичный вывод можно получить на основе сравнения расчетного и принятого уровней значимости: ![]() .
.
4. Проверка статистических гипотез о значении генеральной средней и о равенстве двух выборочных средних
Для наглядного и компактного представления результатов проведенного выборочного наблюдения необходимо воспользоваться графическими возможностями ППП STATISTICA. Весьма существенным, с дидактической точки зрения, является то, что последовательное выполнение рассматриваемых лабораторных работ, дает возможность наглядного сравнения результатов выборочного и сплошного наблюдений. Вполне очевидно, что, по определению, такое сравнение исключено в реальных практических условиях [3].
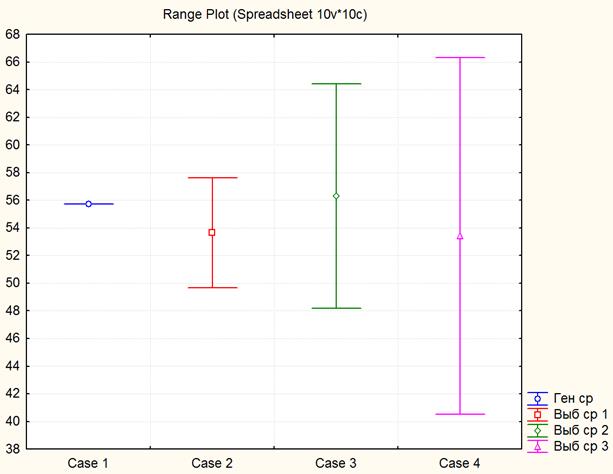
Рисунок 4.1. Графическое сравнение результатов сплошного и выборочного наблюдения
График наглядно показывает, что доверительные интервалы, построенные по всем выборкам, накрывают генеральную среднюю, что естественно. Если бы, какой либо доверительный интервал, рассчитанный по результатам выборки, не включал в себя значение генеральной средней, то в реальных условиях, это означало бы получение ошибочного вывода на основе выборки.
Диаграмма наглядно демонстрирует возможный результат выборочного зондирования исследуемой генеральной совокупности и убедительно иллюстрирует объективную неоднозначность выводов, формулируемых на основе выборочных данных.
Заключение
Среднее значение выборки, состоящей из 70 единиц, равно 53,64286, оно отличается от генеральной средней на 2,06309, величина среднеквадратического отклонения равна 16,66183. Средняя ошибка этой выборки – 1,991470, а интервал оптимальности ![]() , т.е. с вероятностью 95% можно утверждать, что в среднем по России число собственных легковых автомобилей на 1000 человек населения в 1990 году находилось в указанных пределах. Расчётное значение t-критерия составляет -1,03596, меньше 2, следовательно, различия между генеральной и выборочной средней случайны, и выборочное среднее является достоверной оценкой генеральной средней. Расчётный уровень значимости t-критерия также подтверждает это (
, т.е. с вероятностью 95% можно утверждать, что в среднем по России число собственных легковых автомобилей на 1000 человек населения в 1990 году находилось в указанных пределах. Расчётное значение t-критерия составляет -1,03596, меньше 2, следовательно, различия между генеральной и выборочной средней случайны, и выборочное среднее является достоверной оценкой генеральной средней. Расчётный уровень значимости t-критерия также подтверждает это (![]() ).
).
По результатам проверки гипотезы о равенстве двух выборочных средних получены следующие выводы: расчётное значение t-критерия меньше табличного, следовательно, с вероятностью 95% можно утверждать, что две выборочных средних равны и получены не случайным образом (это подтверждает и расчётный уровень значимости, больший 0,05).
График наглядно показывает, что доверительные интервалы, построенные по всем выборкам, накрывают генеральную среднюю, что естественно. Если бы, какой либо доверительный интервал, рассчитанный по результатам выборки, не включал в себя значение генеральной средней, то в реальных условиях, это означало бы получение ошибочного вывода на основе выборки.
Список использованных источников
1. Лекции по дисциплине статистика. Лектор – доц. О.А. Пономарёва, 2008.
2. Сборник Росстата Регионы России. Социально-экономические показатели. 2006.
3. Учебное пособие. Статистика. Методы анализа распределений. Выборочное наблюдение. Н.В. Куприенко, О.А. Пономарёва, Д.В. Тихонов. 132 с. – 2008.