| Скачать .docx |
Реферат: Статистическое наблюдение
Федеральное агентство по образованию
Государственное образовательное учреждение высшего профессионального образования Санкт-Петербургский государственный горный институт им. Г.В.Плеханова
(технический университет)
В.П. СКОБЕЛИНА, Ю.В. ЛЮБЕК, Е.Г. КАТЫШЕВА
СТАТИСТИКА
Учебное пособие
для самостоятельной работы студентов
САНКТ-ПЕТЕРБУРГ
2005
УДК 311(075.80)
ББК 60.6я73
С44
Представлен теоретический материал, дополняющий лекционный курс по общей статистике и ориентированный на изучение статистических методов и способов сводки и группировки, построения и анализа статистических таблиц и графиков, расчета и оценки средних величин, показателей вариации, системы индексов и проведение индексного анализа.
Учебное пособие предназначено для самостоятельного изучения студентами специальностей 060800 «Экономика и управление на предприятии (в горной промышленности и геологоразведке)» и 060500 «Бухгалтерский учет, анализ и аудит».
Научный редактор проф. В.П.Скобелина
Рецензенты: кафедра экономики предприятия и менеджмента Северо-Западного государственного заочного технического университета, проф. Г.А. Маховикова (Санкт- Петербургский государственный университет экономики и финансов).
Скобелина В.П.
С44. Статистика: Учеб. пособие для самостоятельной работы студентов / В.П.Скобелина, Ю.В.Любек, Е.Г.Катышева. Санкт-Петербургский государственный горный институт (технический университет). СПб, 2005. 73 с.
ISBN 5-94211-154-5 Ó Санкт-Петербургский горный
институт им. Г.В.Плеханова, 2005 г.
Введение
Статистика – общественная наука, но от других общественных наук ее отличает то, что любое общественно значимое явление оценивается количественно.
В связи с этим статистика как наука должна отвечать следующим требованиям:
1. Изучение общественных явлений в статистике должно быть нацелено не только на познание качественной сущности, но и на исследование количественной стороны, т.е. изучение количественной стороны явлений должно выполняться в неразрывной связи с его качественной характеристикой. В начале выявляется общая сущность явлений, а затем дается количественная оценка этой сущности. Такое изучение общественных явлений многостадийно и циклично, при этом важно выделить стадию и конец цикла, когда изменения количественной стороны явления приводят к измененению его качественных сторон. В процессе статистического исследования новое качество регистрируется как в пределах изучаемого объекта (статистической совокупности), так и в среде, формирующей условия функционирования (существования) объекта как элемента общественного производства.
2. Статистика должна изучать общественное явление в их взаимосвязи и с учетом воздействия природной среды.
3. Количественную сторону общественных явлений статистика должна изучать в конкретных пространственных и временных границах. Показатель привязан либо к периоду, либо к территории и т.д.
Таким образом, результатом статистического изучения явлений должны быть обобщающие статистические показатели (ОБС) – количественные характеристики одного из свойств или сторон общественных явлений, взятых в определенных границах пространства и времени. Формирование этих показателей возможно при соблюдении следующих принципов:
1) изучаемое явление должно иметь массовый характер;
2) для расчета ОБС должны быть выбраны существенные признаки, а их число должно быть ограничено по соображениям целесообразности;
3) показатели должны отражать тенденции изменения изучаемого явления;
4) показатели должны быть универсальны (применимы в разных спектрах, областях и т.д.).
Итак, статистика изучает массовое общественное явление в определенных временных и пространственных границах на основе формирования и использования статистических обобщающих показателей.
1. Статистическое наблюдение
Классификация признаков явлений
Статистическое наблюдение – это первая и важнейшая стадия статистического исследования, во время которой производится научно организованный и систематический отбор массового материала, характеризующего явления и процессы общественной жизни, с целью получения необходимых данных для расчета статистических обобщающих показателей. С учетом изложенного статистическое наблюдение должно удовлетворять ряду условий:
1. Собранные сведения должны быть полными, а не случайными и отрывочными. Полноту данных можно обеспечить полнотой пространственного охвата (полный охват единиц изучаемой совокупности), полнотой охвата сторон явления (полный охват всех существенных признаков изучаемых явлений) и полным охватом во времени. Однако на практике реализация подобных требований или затруднительна, или невозможна. Поэтому проведение статистического наблюдения допускает ряд ограничений, которые, однако, не снижают качества статистических наблюдений:
· для полноты охвата в пространстве достаточно учесть генеральную часть совокупности, которая характеризуется либо представительностью числа единиц в совокупности, либо их долей в объеме качества по изучаемому признаку;
· для полноты охвата сторон явления можно ограничиться небольшим числом (от шести до восьми) наиболее существенных признаков;
· для полноты охвата во времени период наблюдения должен быть кратным числу циклов изменений исследуемого явления, при этом он должен учитывать экстремальные (минимальные и максимальные) значения изучаемого признака.
2. Собранная в процессе статистического наблюдения информация должна быть достоверной и точной. Точность зависит от масштаба учета явлений и от размерности цифровых показателей.
3. Статистический материал, собранный в разное время, должен быть приведен к единообразной и сопоставимой форме, т.е. содержать одни и те же элементы.
4. Статистическая информация должна поступать к пользователю своевременно.
С точки зрения характеристики состояния исследуемых явлений признаки подразделяются на атрибутивные, различие которых у отдельных единиц совокупности нельзя выразить численно, и количественные, которые у отдельных единиц объекта различаются по величине.
Количественные признаки могут быть прерывными (дискретными) и непрерывными. Прерывные признаки принимают определенные целочисленные значения, а непрерывныемогут быть охарактеризованы любым числом. Кроме того, различают прямые и косвенные количественные признаки. Прямые признаки оценивают состояние и изменение явлений непосредственно. Признаки, которые сказываются на состоянии (или изменении) явления посредством других признаков, опосредовано, называют косвенными. Их воздействие может быть немедленным или отдаленным во времени, ослабленным.
Признаки делятся на функциональные и факториальные. Функциональные – это признаки, изменение которых зависит от других признаков, действие которых может быть зафиксировано аналитической формулой. Каждый из признаков, влияющих на функциональный, является факториальным.
В зависимости от целей анализа одни и те же признаки могут выступать в качестве и функциональных, и факториальных.
Кроме того, среди признаков выделяют существенные и наиболее существенные, а также несущественные. Следует помнить, что атрибутивные признаки всегда существенные; из количественных признаков к существенным относятся признаки производственно-логических связей и в меньшей степени производственно-технологических связей.
2. Сводка и группировка
Сводка . В результате статистического наблюдения получают сведения о единице наблюдения. Чтобы перейти от частных значений признаков к значениям по их совокупности, необходимо обобщить единичные данные, превратив их в статистические данные, т.е. выполнить сводку. Техническая сторона процесса сводки – подведение итогов по частям совокупности и в целом по ней. Вместе с тем грамотно выполненная сводка представляет собой теоретическое обобщение статистических данных, начальный этап образования статистических показателей.
В основе процесса сводки лежит анализ и синтез.
Статистический анализ – это изучение явления посредством выделения его сторон, существенных или зависимых. Анализ нацелен на изучение основных признаков, но при этом сфера исследования обобщающих признаков выходит за рамки изменения совокупности. Чтобы перейти от колебаний отдельных признаков к характеристике изменчивости всей совокупности, нужен синтез, т.е. рассмотрение общего качества. При этом анализ будет качественным, если сводка будет выполнена так, чтобы итоги были подведены по нужным для анализа уровням.
Перед проведением сводки оценивается полнота, достоверность и сопоставимость подлежащего обработке исходного материала.
С организационной точки зрения сводка может быть централизованной и децентрализованной. Первая необходима для подведения итогов крупных специальных обследований. В этом случае весь материал концентрируется в организации, проводящей обследование. Децентрализованная сводка выполняется в два этапа: на первом материалы обобщаются в пределах компании (объединения), на втором этапе агрегированные характеристики обрабатываются и конкретизируются заказавшей обследование организацией.
Группировка . Сведение статистического материала в группы, качественно однородные по одному или нескольким признакам, называется группировкой. Содержательная сторона группировки зависит от задачи, которая решается с ее помощью. Соответственно в основе классификации группировки лежат три задачи.
· Расчленение множества однородных явлений на социально-экономические типы, классы, однокачественные группы или статистические совокупности. Решение этой задачи сопряжено с разделением более крупных категорий на их составные элементы. Обратное решение этой задачи позволяет переходить от отдельных элементов к категориям.
· Выявление внутреннего строения или структуры типа, класса, однокачественной группы.
· Установление связей и зависимостей между явлениями и их признаками внутри изучаемой совокупности, а также выявление факторов развития явлений. Решение данной задачи возможно как при заранее известном характере связи между наблюдаемыми признаками, так и при неопределенности связи.
Группировка выполняется в несколько стадий. На первой важно отобрать группировочный признак. Им должен быть существенный признак из числа заданных. Если в числе заданных есть атрибутивный признак, то именно он становится группировочным признаком. Если группировочных признаков несколько (если признаки атрибутивные, их должно быть не меньше двух), группировка выполняется в несколько стадий.
Группировку по первому признаку называют первичной, а группировку по всем другим признакам – вторичной.
Группировка проводится или по одному или по нескольким взаимосвязанным признакам. Во втором случае выполняется процедура расчета функционального признака по заданным факториальным. Этот функциональный признак будет играть роль группировочного. Группировка должна осуществляться после выполнения сводки, которая, и это следует помнить, возможна только по количественным объемным признакам. Качественные признаки не подлежат сводке (качественный признак всегда есть результат деления объемного или количественного признака на другой объемный признак или на собственную базу).
Результат сводки – вертикальный столбец цифр, записанных беспорядочно. Он замкнут границами уровня выполнения сводки. Для выполнения группировки этот материал должен быть упорядочен (записан в нарастающем или убывающем порядке). Нарастание или убывание определяется тенденцией изменения данного признака (например, себестоимость снижается, производительность труда увеличивается). Такой ряд чисел называется вариационным. Его элементы – числа (уровни ряда). Ряды бывают дискретными(уровень задан одним числом) и интервальными. Дискретные ряды являются исходным материалом выполнения группировки, а интервальные – ее результатом.
3. Ряды распределения
Группировка, содержащая всего два элемента: перечень групп и число единиц, входящих в каждую группу, – называется рядом распределения. Соответственно ряды распределения чаще всего являются результатом группировки.
Ряды распределения бывают первичными и вторичными. К первичнымотносятся упорядоченные (или вариационные) ряды по данным статистического наблюдения. Эти ряды характеризуются дискретной записью уровней и небольшими частотами (часто они равны единице). Вторичныеряды обязательно являются результатом группировки по количественному признаку. Эти ряды могут быть интервальными и смешанными. У интервальных рядов уровень ряда – интервал, у смешанных – интервалы чередуются с дискретным значением уровня. Частоты таких рядов распределяются по уровням неравномерно. Характер распределения частот определяет качество группировки, ее надежность.
Для вторичных рядов кроме частот определяются частости, т.е. частоты, выраженные в долях или процентах к объему ряда (сумме единиц ряда). Интервальные вторичные ряды могут иметь равные или неравные интервалы.
Интервальные ряды распределения – это непосредственный результат группировки, так как каждый интервал цифр в нем – это объем признака, характеризующий определенный объем качества.
Интервальный ряд распределения характеризуют следующие элементы:
· уровни ряда (варианты) – интервальные значения признака;
· частота – число единиц совокупности, соответствующее данному уровню;
· частость – частота в относительном измерении, т.е. частота, отнесенная к объему ряда, где объем ряда – число единиц изучаемой совокупности. Сумма всех частостей равна соответственно единице или 100 %. Равномерность распределения признака в исследуемой совокупности определяется значениями частот или частостей;
· плотность распределения признака – удельная частота в пределах интервала; отношение частоты (частости) к величине интервала. Необходимость в расчете этого показателя возникает в рядах с неравными интервалами, так как колебания объемов признака по уровням качества как правило не характеризуется пропорциональной зависимостью.
Формирование равных интервалов предполагает достаточно однородную совокупность по изучаемому признаку с медленным нарастанием или убыванием последнего. Во всех остальных случаях формируются неравные интервалы.
Независимо от величины интервала группировку начинают с выделения равных интервалов, а затем переходят к неравным.
Построение ряда с равными интервалами предполагает наличие вариационного ряда по группировочному признаку. Построение искомого ряда включает следующие операции:
· определение размаха ряда – разности между крайними значениями ряда Х max – X min ;
· обоснование числа групп вторичного ряда распределения n , которое зависит от объема выборки. Эта зависимость имеет опытно-статистический характер, применяется в зависимости от сферы изучаемого явления и декларируется специальными статистическими таблицами;
· определение величины интервала
![]() ;
;
· построение интервалов прибавлением к минимальному значению признака ![]() : X
min
+ Di
= X
1
. Таким образом, последовательно получаем интервалы [X
min
– X
1
], [X
1
– X
2
] = [X
1
– (X
1
+ Di
)] и т.д., пока не придем к максимальному значению признака.
: X
min
+ Di
= X
1
. Таким образом, последовательно получаем интервалы [X
min
– X
1
], [X
1
– X
2
] = [X
1
– (X
1
+ Di
)] и т.д., пока не придем к максимальному значению признака.
Параметры ряда i и n взаимосвязаны: чем больше длина интервала, тем меньше интервалов. Число интервалов зависит от объема выборки, размаха и некоторых других характеристик ряда. В зависимости от объема выборки N можно принимать следующее число интервалов n :
| N | До 10 | До 10-30 | 30-100 | 100-500 | 500-3000 | Более 3000 |
| n | 3 | 3-4 | 4-8 | 8-9 | 9-13 | 13-18 |
Построение интервального ряда завершается распределением единиц совокупности по выделенным интервалам.
После того, как найдены частоты интервального ряда, строится их график, причем по оси абсцисс откладывают интервальные значения признака, а по оси ординат – частоты. Если полученный график близок к прямой или параболе, группировку можно заканчивать, она качественна. Для рядов с неравными интервалами данный график будет точнее, если вместо частот использовать плотность распределения.
Построению рядов с неравными интервалами предшествует анализ динамики признака по совокупности и регистрация моментов накопления объема признака. Совмещение этих двух направлений анализа сопровождается обычно вторичной группировкой. При первичной группировке этот процесс возможен только путем построения интервального ряда с равными интервалами.
Таким образом, процедура первичной группировки выглядит следующим образом:
1. Формируется ряд (с равными интервалами) на базе ряда распределения.
2. Выполняется графическая проверка полученного результата. График строится следующим образом: по оси абсцисс откладывают интервалы ряда с регистрацией их средних, по оси ординат – частоты (частости). Точки графика получают на пересечении срединных значений уровней ряда и соответствующих ординат.
3. Проводится анализ полученного графика посредством построения линии тренда. Если линия тренда представляет собой прямую линию или параболическую кривую (второго порядка), то полученные результаты являются достаточно надежными (качественными) и группировку можно закончить. Если линия тренда представлена гиперболической или синусоидальной кривой, то результаты группировки нельзя признать надежными и процедуру следует продолжить. Как правило, последующие стадии группировки заканчиваются построением рядов с неравными интервалами.
4. Осуществляется процедура проверки рядов с неравными интервалами:
1) по исходным данным определяется плотность распределения признака в пределах интервала по единицам совокупности;
2) строится график, в котором по оси абсцисс откладывают интервалы ряда с регистрацией середины; по оси ординат – плотность распределения;
3) проводится анализ полученного результата.
Кроме того, результатами группировки могут быть смешанные ряды, когда одни уровни представлены интервальными значениями, а другие – дискретными (геостатистика, гидрометеорологические исследования).
4. Графическое изображение рядов распределения
Любой ряд распределения может быть представлен в виде статистического графика. При этом по оси ординат показываются частоты (частости, плотности распределения), по оси абсцисс – значения признаков.
Построение статистических графиков отличается от построения математических рядом особенностей:
1. Для большей наглядности допускаются разные масштабы по осям координат.
2. Статистические графики могут быть уровневыми и интегральными. Уровневые замыкаются числом или пределами частот, что позволяет комплектовать уровневые статистические графики взаимосвязанных показателей на одном листе.
3. Статистические графики могут строиться как в абсолютном, так и в относительном измерении (по признаку). Последние предпочтительнее для функциональных признаков.
4. Интегральные статистические графики предполагают суммирование не только значений признака, но и частот. При этом возможно полное суммирование последних или их суммирование в ограниченных пределах (интервалах).
5. Статистические графики в зависимости от цели исследований читаются слева направо (прямой порядок) и справа налево (обратный порядок).
6. Статистический график всегда ломаная линия или диаграмма.
4.1 Уровневые графики (гистограмма, полигон распределения)
Для таких графиков важно соблюдать два правила их построения:
1. Количественное значение группы должно следовать за изменением количественной характеристики признака (распространение признака по оси абсцисс первично).
2. При равных интервалах признака по оси ординат откладываются частоты, при неравных – плотность распределения.
Характерными представителями уровневых графиков являются гистограмма (рис.1) и полигон распределения.
 |
Для общего вида гистограммы характерно следующее:
· предельная высота ограничена максимальной частотой, максимальной частостью или плотностью распределения;
· гистограмма характеризует не только интервалы распределения признака (основания прямоугольников), но и распределение объема признака для тех или иных интервалов (площадь прямоугольника);
· вид линии, ограничивающей гистограмму сверху, определяет ресурсы по объему признака;
· вся площадь прямоугольника S по максимальной высоте гистограммы для всего распределения признака характеризует матрицу объема признака.
Гистограмма наглядно иллюстрирует распределение признака, причем двояко:
· долей площади каждого прямоугольника
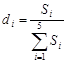 ;
;
· матрицей ![]() , где S
– площадь матрицы.
, где S
– площадь матрицы.
Гистограмма показывает как изменяется объем признака. Для оценки изменений площади соседних прямоугольников суммируются (возможно нарастающим итогом) и эта сумма относится к общему объему признака (сумме площадей всех прямоугольников).
Правильно построенная гистограмма (в пределах установленных масштабов) позволяет выделить генеральную совокупность по объему признака прямым или обратным порядком. Прямой порядок выделения генеральной совокупности сопряжен с нарастающей динамикой объема признака (S 1 + S 2 + S 3 + S 4 ), обратный (S 4 + S 3 + + S 2 + S 1 ) – с убывающей.
Построить гистограмму можно только для интервального ряда распределения, и в этом состоит специфичность гистограммы.
Более универсальным является второй вид уровневого графика – полигон распределения. В дискретных рядах каждому определенному значению признака соответствует своя частота (частость), что отражается на оси абсцисс точками, а не интервалами, а по оси ординат – целыми значениями частоты или дробными частости. В этом случае полигон распределения будет представлен ломаной линией.
Для интервального ряда получение полигона распределения предполагает соединение середин верхней линии гистограммы.
Для смешанного ряда построение полигона распределения предполагает соединение середин верхних линий гистограмм с высотой дискретного значения признака.
Если есть возможность закодировать цифрами стандартную номенклатуру по атрибутивному признаку, то эти цифры могут быть зарегистрированы на оси абсцисс, и это позволит построить полигон распределения (так называемый кодовый полигон распределения).
Универсальность этих графиков снижает их потенциальные возможности по сравнению с гистограммами. Полигон также характеризует распределение признака, но не так конкретно, как гистограмма (затруднен процесс расчета всех площадей). Изменение объема признака регистрируется в целом и нарастающим итогом, поэтому полигон распределения не позволяет выделить генеральную совокупность.
Тем не менее, полигон распределения регистрирует точку или момент перехода количества в качество в процессе нарастания объема признака.
4.2 Интегральные графики
Интегральные графики в экономике представлены главным образом кумулятами. Общей особенностью построения кумулят является накопление не только признака, но и частот по абсциссе и ординате. Различают следующие виды кумулят: полная и неполная; восходящая (прямая) и убывающая (обратная).
Кумуляты аналогичны по виду полигона распределения, а поэтому применимы для всех вариантов рядов распределения.
Полные кумуляты строятся для всех рядов с полным нарастанием частот (без ограничений). Неполные кумуляты строятся и для интервальных рядов, и для смешанных. Первые формируются либо в пределах всего ряда, либо учитываются только характерные группы интервалов (выделенные по минимальному, серединному или максимальному значению интервала), вторые – в пределах всего ряда, но учитываются не все частоты, а только те, которые выше установленного регламента.
Пример. По геологически однородному участку золотой россыпи получены следующие результаты опробования (447 проб):
Содержание, г/т |
0 | 0-0,1 | 0,1-1 | 1-2 | 2-3 | 3-5 | 5-10 | 10-20 | |
| Число проб | 13 | 32 | 51 | 84 | 116 | 96 | 32 | 13 | |
Содержание, г/т |
18,7 | 18,8 | 19,4 | 19,9 | 20 | 29,5 | 47,1 | 92 | 193,4 |
| Число проб | 1 | 1 | 2 | 1 | 1 | 1 | 1 | 1 | 1 |
Определить критическое содержание* золота в пробе, полностью учитываемое при подсчете запасов по этому участку (избыточное содержание будет отнесено к запасам всего месторождения). Установить кондиции для балансовых и забалансовых запасов. Оценить достоверность графиков для подсчета категории запасов.
Решение . Все эти задачи можно решить графически путем построения двух полных кумулят: прямой и обратной. Построение кумулят требует проведения предварительной очистки данных от ложных («грязных») проб, а также обоснования критического содержания по отношению к среднему. Примем, что критическое содержание выше среднего в 10 раз. Кроме того, необходимо выделить ураганные пробы, в которых содержание выше критического.
Необходимую информацию и результаты расчетов сведем в таблицу, где столбцы 1 и 3 содержат исходную информацию, а остальные – расчетную (полужирным шрифтом выделены искомые значения).
Статистический анализ результатов опробования однородного участка золотой россыпи
| Содержание золота, г/т | Среднее по классу, г/т | Число проб в классе | Сумма со-держаний в классе, г/т |
Нарастающая сумма | Убывающая сумма | ||
| г/т | % | г/т | % | ||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 0 | 0 | 13 | 0 | 0 | 0 | 1742,9 | 100 |
| 0-0,1 | 0,05 | 32 | 1,6 | 1,6 | 0,1 | 1742,9 | 100 |
| 0,1-1 | 0,55 | 51 | 28,1 | 29,7 | 1,7 | 1741,3 | 99,9 |
| 1-2 | 1,5 | 84 | 126 | 155,7 | 8,8 | 1713,2 | 98,3 |
| 2-3 | 2,5 | 116 | 290 | 445,7 | 25,6 | 1587,2 | 91,3 |
| 3-5 | 4 | 96 | 384 | 829,7 | 47,6 | 1297,2 | 74,4 |
| 5-10 | 7,5 | 32 | 240 | 1069,7 | 61,5 | 913,2 | 52,4 |
| 10-20 | 15 | 13 | 195 | 1264,7 | 72,5 | 673,2 | 38,5 |
| 18,7 | 18,7 | 1 | 18,7 | 1283,7 | 73,7 | 478,2 | 27,5 |
| 18,8 | 18,8 | 1 | 18,8 | 1302,2 | 74,6 | 459,5 | 26,3 |
| 19,4 | 19,4 | 2 | 38,8 | 1341 | 77,0 | 440,7 | 25,4 |
| г/т | % | г/т | % | ||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 19,9 | 19,9 | 1 | 19,9 | 1360,9 | 78,1 | 401,9 | 23,0 |
| 20 | 20 | 1 | 20 | 1380,9 | 79,3 | 382 | 21,9 |
| 29,5 | 29,5 | 1 | 29,5 | 1410,4 | 81,0 | 362 | 20,7 |
| 47,1 | 47,1 | 1 | 47,1 | 1457,6 | 84,6 | 332,5 | 19,0 |
| 92 | 92 | 1 | 92 | 1549,5 | 88,9 | 285,4 | 15,4 |
| 193,4 | 193,4 | 1 | 193,4 | 1742,9 | 100 | 193,4 | 11,1 |
_________________________________ Примечание. Такая запись указывает на то, что исходная информация не содержит грязных проб, а распределение содержания по уровням ряда соответствует геологической классификации проб. Тем самым пробы, представленные в столбце 3, являются чистыми. |
|||||||
Заполнение столбцов в расчетной части таблицы выполняется следующим образом:
· Столбец 2. Уровни этого ряда представляют собой середины интервальных значений столбца 1.
· Столбец 4.Произведение соответствующих строк столбцов 2 и 3. Каждый уровень ряда этого столбца имеет частное наименование (граммов на тонну) или характеризует удельный объем изучаемого признака (наличие золота в руде). Это возможно, так как данный признак является произведением двух стандартных (цензовых) признаков.
· Столбец 5. Уровни этого ряда получаются путем последовательного суммирования уровней предыдущего ряда. Сумма регистрируется нарастающим итогом.
· Столбец 6. Значения могут быть получены прямым и обратным способом. Прямой способ предполагает выражение в относительном измерении уровней столбца 4 и последующего их наращивания. Обратный способ применим только в пределах всей совокупности. Тогда предельное значение столбца 5 принимается за 100 % и каждый из уровней этого ряда затем соотносится с предельным значением.
· Столбец 7. Уровни этого ряда набираются как разности; последние получаются последовательным вычитанием из конечного значения столбца 5 значений столбца 4, начиная с первого уровня.
· Столбец 8. Процентное выражение убывающей суммы определяется обратным порядком по аналогии со столбцом 6.
Таким образом, среднее содержание по всем 447 пробам составляет 3,9 г/т. Тогда критическое содержание 39 г/т. Тем самым, к ураганным относятся пробы с содержанием 47,1, 192 и 193,4 г/т.
Долю запасов с ураганными пробами можно выделить двумя способами:
· прямым, по убывающей кумуляте (в столбце 8 последние три строки регистрируют данные по ураганным пробам, верхнее соответственно искомое значение 19 %);
· обратным, по нарастающей кумуляте (в столбце 6 выделяют уровень ураганных проб, соседний с ними регистрирует объем запасов без ураганных проб; искомое 100 – 81 = 19 %).
Избыточное содержание
![]()
Суммарное избыточное содержание
 |
8,1 + 53 + 154,4 = 215,5 г/т.
Определим долю запасов избыточного содержания по пропорции* :
155,7 г/т – 8,8 %
215,5 г/т – х
![]() %.
%.
Однако построение кумулят позволяет дать более полную оценку запасов полезного ископаемого (рис.2).
Правильность построения кумулят проверяется соблюдением неравенства
![]()
Абсцисса точки пересечения прямой и обратной кумулят соответствует бортовому содержанию полезного ископаемого.
5. Динамические ряды
Динамические ряды относятся к особым вариантам рядов распределения, направленность распределения признаков которых диктуется фактором времени. При этом время меняется наступательно, в возрастающем порядке. Моменты времени одновременно являются уровнями ряда. При этом уровень регистрирует или момент, или период.
Как ряд распределения динамический ряд имеет характеристики обычного ряда распределения, т.е. значения признака и частоты. Частоты обычно равны единице. Только в тех случаях, когда процесс циклично повторяется, частоты уровней изменяются и оказываются выше единицы.
Динамические ряды имеют и особенности, которые в той или иной степени отражают динамику явления (развитие во времени). Специфическими показателями динамического ряда являются абсолютный прирост (разность между последующим уровнем и предыдущим), темпы роста (цепные и базисные, так как являются относительными величинами динамики), среднегодовой темп роста, базисные и цепные темпы прироста.
Обозначив отдельные уровни динамического ряда последовательно q 0 , q 1 , q 2 , …, qn , получим темпы роста, базисные
![]()
![]() …;
…; ![]()
и цепные
![]()
![]() …;
…; ![]() .
.
Аналогично темпы прироста, базисные и цепные соответственно
![]()
и
![]()
Цепные и базисные темпы роста взаимосвязаны, причем эта связь имеет двойное содержание: произведение цепных индексов динамического ряда равно отношению крайних уровней данного ряда (t 1 t 2 t 3 … tn = qn /q 0 ); при делении последующего базисного темпа на предыдущий получается цепной темп последующего периода:
![]()
Динамические ряды, составленные из темпов роста (прироста), могут быть цепными, базисными или смешанными.
Абсолютный прирост позволяет выявить прерывность динамического ряда. Если колебания соседних абсолютных разностей превышают регламент, установленный содержанием признака, то ряд в этом месте разрывается. Последующие характеристики ряда рассчитываются только для непрерывной его части. Поэтому непрерывным рядом может считаться только ряд с моментными уровнями, так как содержание экономического явления (уровень показателей) регистрируется, как правило, на год. Ряд с периодическими уровнями может быть непрерывным при равных периодах в том случае, если этот период является лагом для данного явления (признака).
Любые варианты смешанных рядов всегда прерывны.
Абсолютные разности позволяют фиксировать точки перегиба ряда, когда знак абсолютной разности меняется на противоположный. Если абсолютная величина разностей соседних уровней не превышает для количественных признаков 30 %, а для качественных 15 %, то ряд считается непрерывным. Доля точек перегиба в объеме ряда может характеризовать вид динамики. Если эта доля не более 5 %, ряд характеризуется направленной динамикой. Если эта доля не более 30 %, имеет место неустойчивая динамика ряда, а если доля превышает 30 %, то динамику называют вибрирующей.
Общую направленность динамики можно определить по базисным темпам роста: если они больше единицы, динамика растущая, если меньше единицы, падающая. Но точное представление о направленности ряда дает среднегодовой темп роста, который позволяет также достаточно надежно оценить интенсивность динамики ряда в среднем за весь период:
![]()
где t 1 , t 2 , ¼, tn – цепные (или базисные) темпы роста.
Однако одной направленности динамики для характеристики ряда мало. Важно выяснить характер динамики: спокойная, интенсивная, пульсивная. При этом спокойная динамика графически выражается прямой с небольшим угловым коэффициентом, интенсивная – прямой с высоким угловым коэффициентом или сложными линиями тренда (сочетание прямой, параболы и т.д.).
Характеристика динамики устанавливается в процессе анализа цепных темпов роста. При этом выделяются зоны стабильной, интенсивной, растущей и падающей динамики. Для такой оценки через цепные темпы роста (разность между цепным темпом роста и единицей) рассчитываются темпы прироста, которые сопоставляются со среднегодовым темпом роста. Чем ближе темп прироста к среднегодовому темпу роста, тем плавнее динамика, чем дальше – тем она интенсивнее.
Особую функцию в характеристике динамических рядов выполняют темпы прироста, рассчитанные через базисные темпы роста. В пределах ряда особый интерес представляет удельная (средняя) характеристика этого показателя, т.е. среднегодовое значение такого прироста. Для его получения нужно прирост за последний год разделить на число моментов изучаемого ряда.
6. Статистические таблицы
Статистические таблицы являются рациональной формой изложения и анализа численных характеристик общественных процессов. Они позволяют не только сжато и компактно изложить результаты комплексной обработки статистических материалов, но и подготовить этот материал к анализу, а в отдельных случаях указать схему анализа. Достигается это тем, что объекты и характеризующие их показатели располагаются в определенной системе, позволяющей словесные пояснения представить в виде заголовков (общих и частных) для признаков и групп.
Порядок разработки таблиц регламентирован следующим образом:
1. Составление заголовка к таблице, который должен отражать основное содержание таблицы.
2. Обоснование перечня признаков (подлежащего и сказуемого), используемых для качественного построения таблицы.
3. Составление макета статистической таблицы.
Макет – это форма таблицы, имеющая общий заголовок и заголовки к горизонтальным строкам и вертикальным графам. Макет составляется до сбора первичного материала, поэтому цифр в нем нет. Для разработки макета важно содержание подлежащего и сказуемого таблицы и их компоновка. При этом подлежащее индексируется буквами, а графы сказуемого нумеруются.
Подлежащимтаблицы называется тот объект, который подвергается в ней изучению. Как правило, подлежащее состоит из набора признаков, распределения признака и единиц изучаемой совокупности. При этом могут быть использованы различные виды группировок по цели их использования (типологическая, аналитическая). В зависимости от схемы группировки подлежащего при помощи таблиц могут решаться различные задачи анализа.
Сказуемымназывается комплекс показателей, которыми характеризуется подлежащее таблицы.
Поскольку таблица регистрирует результаты группировки и эта группировка отражается в подлежащем, то в подлежащее попадают атрибутивные признаки (если они есть), а в сказуемое – только количественные. Из количественных признаков в подлежащее попадают функциональные и прямые; факториальные признаки содержатся в сказуемом.
Для построения таблиц важно знать не только как компонуются подлежащее и сказуемое, но и их расположение. Подлежащее обычно располагается в левой части таблицы в виде наименования строк, сказуемое – в правой части в виде граф (колонок, столбцов). Графы, как правило, объединяются промежуточной сводкой (Итого), колонки – не всегда, а столбцы – только итоговой сводкой (Всего).
Сводка в таблице имеет место и в подлежащем, и если в сказуемом она может быть частичной или полной, то в подлежащем сводка обязательно полная.
Наименования строк называют боковыми заголовками, наименования граф – верхними.
Правильная разработка макета таблицы невозможна без учета задач анализа, которые должны решаться по материалам данной таблицы.
Переход от макета к готовой таблице сопряжен с построением рабочих и вспомогательных таблиц, компоновка которых и позволяет получить искомую таблицу.
Виды таблиц . Несомненным достоинством таблиц по отношению к графикам является возможность с их помощью оценить изучаемое явление многосторонне (по нескольким признакам, определенным образом связанным). Характер связи между признаками подлежащего и сказуемого в определенной мере раскрывается видом таблиц. Классификация таблиц выполняется отдельно по подлежащему и сказуемому, но определяющей является первая.
По содержанию подлежащего таблицы подразделяются следующим образом:
· Простыетаблицы, в подлежащем которых содержится перечень объектов согласно принятой систематизации.
· Групповые таблицы, в подлежащем которых содержатся группы, образованные не только по атрибутивному признаку, но и хотя бы по одному количественному.
· Комбинационные таблицы, в подлежащем которых содержатся группы, образованные по одному или двум взаимосвязанным признакам (чаще атрибутивным). Разновидностью комбинационных таблиц по двум признакам являются балансовые таблицы. Цель балансовых таблиц – установление связей между приходом и расходом ресурсов (учет их движения).
По содержанию сказуемого различают следующие виды таблиц:
· Информационные, которые содержат информацию для анализа. Информация представлена признаками, функционально не связанными друг с другом, но расположенными так, чтобы было удобно проводить анализ (более значимые признаки по цели анализа располагаются левее).
· Аналитические, в которых признаки сказуемого объединены одним или несколькими изолированными функциональными признаками. Особенностью сказуемого аналитической таблицы является то, что на его основе может формироваться иное расположение столбцов за счет перемены мест функциональных признаков. Кроме того, находящийся справа функциональный признак (признаки) может быть отсечен и использован для построения самостоятельной таблицы (таблиц). Такие процедуры часто применимы и к информационным таблицам: возможна перестановка признаков (столбцов), а в отдельных случаях отсечение части столбцов объединяемых производственных и логических признаков.
· Системные, представляющие собой сочетание аналитической таблицы с информационной при одном и том же подлежащем. К системным относятся также аналитические таблицы, в которых функциональные признаки сказуемого взаимосвязаны. Системная таблица, как и аналитическая, допускает сокращение сказуемого за счет отсечения самостоятельных признаков правой части таблицы.
Рассмотренные виды таблиц являются основными. Кроме них в современной статистике используется большое число таблиц-модификаций: корреляционные, наиболее распространенные в практике статистики, матрицы и вариационно-динамические.
Особенностью корреляционных таблиц является то, что в подлежащем и сказуемом расположены количественные и качественные признаки, связанные между собой. При этом признаки подлежащего и сказуемого могут меняться местами в зависимости от цели исследования. Анализ таких таблиц нацелен на количественное измерение связей между подлежащим и сказуемым.
Если в подлежащем таблицы регистрируется количественный признак, то в сказуемом – обязательно качественный. Если в подлежащем качественный признак, в сказуемом также регистрируется качественный. В первом случае связь между признаками прямая, во втором – обратная. Коэффициент корреляции в первом случае положительный, во втором – отрицательный.
Более сложный вариант корреляционной таблицы называется матрицей. Особенность ее в том, что у нее подлежащее располагается в нескольких местах – либо слева и справа (перед сказуемым и за ним, причем за сказуемым – ограничение), в этом случае матрица является открытой; либо слева, справа и под сказуемым (закрытая матрица).
Особенностью вариационно-динамической таблицы является регистрируемый в сказуемом временный вектор. Подлежащее такой таблицы обычно содержит типичную (стандартную) группировку по цензовому признаку и представлено рядом распределения качественной группировки. Таким образом, содержание вариационно-динамической таблицы формируют два ряда: вариационный в подлежащем и динамический в сказуемом.
Жесткие требования к построению вариационно-динамических таблиц обоснованы целями анализа по этим таблицам, а именно:
1) выявление тенденций в изменении явления (подлежащего);
2) выделение зон интенсивного развития явления и зон слабой динамики;
3) построение полной (неполной) структурной группировки, на основе анализа которой в изучаемом периоде времени (в пределах вектора) исследуются структурные сдвиги явления.
Правила построения статистических таблиц следующие:
1. Построение макета таблицы следует начинать с формирования подлежащего, затем сказуемого. Подлежащее должно соответствовать цели исследования или анализа, которая заявлена в названии таблицы.
2. Подлежащее таблицы должно содержать качественную группировку. При его построении разумно использовать небольшое число наиболее существенных (т.е. атрибутивных) признаков.
3. Признаки сказуемого должны располагаться так, чтобы это было удобно для анализа и чтобы были видны функциональные связи признаков.
4. Столбцы (графы) сказуемого нумеруются слева направо, столбцы (графы) подлежащего обозначаются прописными буквами.
5. Заголовки к строкам и столбцам таблицы должны быть краткими, но четкими и ясными.
6. Число признаков сказуемого должно быть достаточным для характеристики подлежащего, но без изменений детализации.
7. Клетки таблиц, в которых отсутствует информация, заполняются прочерком; если клетка лишена смысла, в ней ставится крест; если информации для заполнения этой клетки вообще не существует, в ней ставится многоточие.
8. Таблица должна содержать примечания построчные и общие (выносятся за рамки таблицы). Примечания могут, например, подробно описывать расчет того или иного показателя.
Дополнительные правила, уточняющие процесс построения макета таблицы:
1. Для построения макета имеющиеся признаки ранжируются по их существенности. Из них выделяются признаки с аналитической связью, изолированные прямые, косвенные и т.д. В построении таблицы должны использоваться наиболее существенные функциональные и прямые признаки. При наличии типологических признаков из них выделяются два, наиболее жестко связанные с целью анализа. Сначала формируется подлежащее. В него должен быть включен основной группировочный признак, т.е. атрибутивный, или наиболее существенный из количественных. В подлежащее включаются и единицы наблюдения или совокупности. Все оставшиеся признаки включаются в сказуемое.
2. Признаки сказуемого должны располагаться в определенной последовательности, исходя из вида таблицы.
3. Построение комбинационных таблиц по подлежащему не должно учитывать больше двух атрибутивных признаков.
4. Таблица должна содержать все необходимые итоги по строкам и столбцам и по возможности полную и частичную сводку.
7. Абсолютные и относительные величины
Абсолютные статистические величины. Эти показатели, выражающие размер (объем, уровень) конкретных общественных явлений в единицах меры массы, объема, силы, стоимости и т.д., представляют собой всегда числа именованные. К наиболее значимым и распространенным из них – натуральным – относятся единицы величин, характеризующие единицы совокупности в физических мерах.
Разновидностью натуральных единиц являются условно-натуральные единицы. При их расчете сначала выделяются наиболее существенные из качественных признаков (показателей), которые принимают за единицу. Все остальные корректируются относительно выделенного признака (показателя).
Денежныеединицы измерения используются для характеристики в стоимостном (денежном) выражении абсолютных показателей.
Трудовые единицы измерения (человеко-часы, человеко-дни, человеко-годы) применяются для характеристики затрат труда, использования трудовых ресурсов.
Денежные и трудовые единицы измерения в статистике используются не только самостоятельно, но и как соизмерители. При этом появляется возможность выразить объемы продукции и другие количественные характеристики в условно-трудовом и условно-денежном (стоимостном, цензовом) измерении. В качестве цензовых, стандартных цен сейчас используются цены Международного Европейского рынка, цены основных свободных зон и цены ведущих бирж.
Абсолютные величины подразделяются на индивидуальные и общие (итоговые). К индивидуальным относятся показатели, характеризующие количественное значение признака отдельных единиц совокупности. В результате суммирования индивидуальных величин получают итоговые показатели. Следовательно, общие абсолютные величины характеризуют величину того или иного признака у всех единиц совокупности или у отдельных их групп.
Относительные статистические величины. Относительной величиной в статистике называется мера отношения объема признака или совокупности к принятой базе. Из этого определения следует, что формирование относительных статистических величин возможно несколькими способами. Действительно, объемы признака или совокупности могут сравниваться с другими их состояниями (во времени, в пространстве или плановыми) или со значениями других взаимосвязанных признаков (сравнение значений разноименных признаков); могут также сравниваться части признака или объема совокупности с их общими объемами (сравнение части и целого, конечно, по одному признаку).
Независимо от способа получения относительные величины отражают качество изучаемых процессов, выступают средством обобщения конкретных социальных явлений. Поскольку относительные величины характеризуют качество, их измерение более универсально. Они могут являться коэффициентами (тогда это доли единицы или проценты).
Математически относительные величины получаются в результате сравнения (отношения). Та величина, с которой производится сравнение, называется базой (основанием) сравнения, базовой величиной.
По содержанию относительные величины подразделяются на несколько видов: относительные величины динамики, выполнения плана и планового задания, пространственного сравнения, координации, интенсивности, структуры и др.
Относительные величины динамики используются наиболее широко. Динамикой в статистике называется изменение явления во времени. Относительные величины динамики измеряют скорость изменения явления (темп развития). Относительная величина динамики – это отношение уровня (объема признака или совокупности) отчетного периода к уровню за предшествующий период. Предшествующие периоды (база) бывают смежными и отдаленными. В рыночной экономике существует разница между базой сравнения для хозяйствующего субъекта (ХС) и макроуровня. Для ХС это обязательно смежная база; для макроуровня при анализе показателей финансового характера выбирается база смежная, при оценке состояния экономики – отдаленная.
Различают два вида относительных величин динамики: с переменной (цепные) и с постоянной (базисные) базой сравнения. Цепные формируются от смежной базы, а базисные – от отдаленной базы. В связи с этим возникает необходимость обоснования выбора отдаленной базы. В основе такого обоснования лежит принцип, согласно которому за базу принимаются количественные характеристики признака (явления) за годы, стоящие на границе отдельных существенно различающихся периодов времени (например, для России 1913, 1940, 1991 гг.). Реализация этого принципа требует соблюдения нескольких условий:
1. База должна быть типичной, а не исключительной, т.е. она должна соответствовать анализируемому периоду по структуре совокупности (явления), по форме развития (интенсивное или экстенсивное). Типичная база предполагает наличие четкой характеристики внешнего фона (внешних признаков).
2. База должна быть напряженной (жесткой). Это значит, что база должна максимально использовать условия коммерческой деятельности и требования расширенного воспроизводства.
3. Из второго условия вытекает, что база должна выбираться изолированно для явлений макроуровня и для уровня ХС.
Относительные величины динамики – это темпы роста. Если анализ предполагает расчет последних за три или более моментов времени, то темпы роста можно рассчитать двумя способами: базисным и цепным. Базисный темп роста имеет постоянную базу, в качестве которой может приниматься внутренняя и внешняя (изолированная) база. В свою очередь, внутренней базой может быть момент, смежный с изучаемым периодом, начальный момент изучаемого периода и специально выделенный внутренний момент времени в пределах изучаемого периода. Цепные темпы роста предполагают одну базу – смежную.
Относительные величины выполнения плана и планового задания представляют собой отношение фактического значения признака к его плановому заданию. Иначе говоря, они отражают степень выполнения плана по известному показателю за изучаемый период времени. Такими показателями являются количественные признаки в объемном измерении (объем производства, объем реализации, балансовая стоимость основных средств, фонд оплаты труда и т.д.). План для качественных показателей (роста производительности труда, роста рентабельности, снижения себестоимости) может быть задан и в относительных величинах. Такая формулировка плана называется плановым заданием.
Относительные величины выполнения плананаходятся простым сопоставлением отчетных данных с плановыми.
Расчет относительных величин выполнения планового задания предполагает выполнение дополнительного расчета для определения базового показателя, который находится сопоставлением плана будущего периода с фактическим уровнем отчетного периода. Пусть, например, фактическая стоимость геолого-разведочных работ (ГРР) по партии составляет 4 млрд руб. В планируемом году предполагается снизить этот показатель до 3,9 млрд руб. Относительная величина выполнения планового задания 3,9: 4 × 100 = 97,5 %. Допустим, что фактическая стоимость работ в плановом году составила 3,87 млрд руб. Чтобы рассчитать относительную величину выполнения планового задания, необходимо прежде найти относительную величину изменения стоимости ГРР в плановом году по отношению к ее плановому уровню: 3,87: 3,9 × 100 = 99,5 %, а затем вычислить искомый показатель: 99,5: 97,5 × 100 = 102 %.
Во избежание повторного счета и сопровождающих его ошибок следует помнить следующее: относительная величина выполнения плана равна отношению относительной величины динамики к относительной величине выполнения планового задания.
Относительные величины пространственного сравнения получаются в результате сопоставления одноименных уровней показателей, относящихся к различным объектам, взятых за один и тот же период времени.
Уровень показателя – это уровень управления производством в пределах сферы общественного производства. Для промышленной сферы существует два уровня: производственный и макроуровень; для непромышленной три: производственный, региональный и макроуровень.
Относительная величина пространственного сравнения рассчитывается по одноуровневым одноименным показателям по разным объектам, один из которых принимается за базу. База может быть стандартной или специально выбранной. Обоснованное формирование этих относительных величин сопряжено с выбором предприятий (объектов)-аналогов. Последний выбирается, исходя из цели анализа и динамики изучаемого явления. В общем случае аналог должен являться моделью изучаемого явления.
Относительные величины координации формируются путем сопоставления (соизмерения) двух различных признаков. Такие признаки могут быть одноименными или разноименными, но обязательно взаимосвязанными. Наиболее характерными примерами одноименных признаков являются фондоемкость, фондоотдача, рентабельность (фондорентабельность и рентабельность средств производства), разноименными – показатели душевого производства и потребления, урожайности, съема полезного ископаемого с 1 м2 площади забоя.
Название относительной величины для одноименных признаков содержит в себе суть этих признаков (фондоемкость, фондоотдача). Относительные величины от разноименных признаков сохраняют названия формирующих их признаков, причем сначала указывается признак числителя, затем – знаменателя.
Условиям формирования относительных величин координации соответствует их более высокий качественный уровень по сравнению с рассмотренными выше видами относительных величин. Высокий уровень качества этих величин сопряжен и с выполнением ряда условий их формирования:
1. Прежде всего, необходимо выявление связи между признаками. Один из них рассматривается как первичный, второй как результативный (производный). Первичный признак как исходная база ставится в знаменатель, а результативный – в числитель. Базовый признак может быть либо неизменным, либо скорректированным на темпы динамики признака. В первом случае формируются относительные величины в стандартном или цензовом варианте (например, урожайность, душевое потребление). Во втором случае относительные величины определяются для той или иной экономической ситуации. При неизменной базе рассматриваемые величины сопоставимы независимо от уровня их расчета.
2. Так как базовый признак, формируя качество результативного признака, имеет свою зону качества, построение относительных величин замкнуто зоной качества базисного признака.
3. Наиболее качественные виды относительных величин формируются при стандартной базе. Такая база характеризуется устойчивостью, универсальностью и, как правило, четко выделяется во внешних условиях. Такие относительные величины могут сопоставляться не только на микро- и макроуровнях, но и для разных стран и разных континентов, т.е. они международные.
4. Относительные величины координации, используемые как оценки эффективности затрат живого и овеществленного труда, получают сопоставлением двух относительных величин, и они, как правило, являются коэффициентами. В названии коэффициента содержится исходная формула расчета этой относительной величины (коэффициенты механо- и энерговооруженности труда, коэффициенты соизмерения затрат живого и овеществленного труда, коэффициенты прямых и полных затрат труда).
Относительные величины интенсивности представляют собой отношение величины явления (признака), обладающего какими-либо специфическими признаками (особенностями), к размеру среды, которая его породила. К таким величинам относятся все демографические коэффициенты (рождаемости, смертности и т.д.), коэффициенты преступности, коэффициенты простоев оборудования, текучести рабочей силы. Таким образом, база для расчета этих величин как бы предопределена. Вместе с тем и здесь выделяют относительные величины со стандартной или цензовой базой. Таким цензом является постоянная характеристика – площадь территории. Соответственно все относительные величины с такой базой являются цензовыми (плотность населения, застройка, плотность показателей инфраструктуры) и универсальными.
Относительные величины структуры , в отличие от двух предыдущих, формируются по одному признаку, но по уровню качества они самые высокие. Рассматриваемые относительные величины – это отношение части к целому, или удельный вес части в общем объеме признака. Поэтому различают относительные величины структуры совокупности и относительные величины объема признака в совокупности.
Независимо от содержания относительных величин при их вычислении за базу сравнения берется общий итог по совокупности в целом. В качестве сравниваемых величин выступают части (группы) совокупности или значения нескольких существенных признаков (объем признака по частям или группам совокупности). Перечень признаков и последовательность расчета по ним относительных величин диктуется условиями и задачами анализа, поэтому относительные величины структуры жестко связаны с группировкой и вычисляются на ее основе. Качественной группировке соответствует и набор качественных относительных величин.
Относительные величины структуры могут рассчитываться и за пределами совокупности (например, в пределах группы однокачественных совокупностей); в этих случаях расчет относительных величин должен выполняться с соблюдением требования одномасштабности числителя и знаменателя.
8. Средние величины
8.1 Понятие о средних в статистике
В статистике средние величины рассматриваются как наиболее распространенный вариант статистических обобщающих показателей (СОП). Это связано с тем, что размеры признака, характерные для всей массы единиц совокупности, статистика выражает при помощи средней величины.
Средней величиной в статистике называется обобщающая (типическая) характеристика общественного явления по одному количественному признаку.
При осреднении случайные колебания признака у единиц совокупности погашаются и отчетливо проступают общие черты совокупности. Сопоставление средних в динамике позволяет выявить закономерности в развитии совокупности (явления), а при комплексном анализе ряда однородных совокупностей – тенденции развития явления.
Средняя величина, выступая обобщающей характеристикой совокупностей явлений и процессов, отражает объективный уровень развития явления (процесса) к определенному периоду или моменту времени. Сопоставление таких средних уровней позволяет зарегистрировать структурный сдвиг в развитии явления (процесса).
Статистические средние могут быть более дифференцированными и более агрегированными. Первые формируются в пределах совокупности: отдельных представительных ее групп или частей, вторые рассчитываются в пределах нескольких совокупностей или нескольких уровней.
Из сказанного видно, что средние величины – качественные характеристики, но их особенность состоитв том, что они заданы не на всю совокупность явлений (не на общий объем совокупности), а на отдельные явления (на единицу изучаемой совокупности). Такое качество средних обеспечивает им известную универсальность и удобство их использования.
Преимущества средних заключаются в следующем:
1. Средние могут быть рассчитаны и использованы как в пределах совокупности, так и некоторого числа однородных совокупностей.
2. Более дифференцированные средние, равно как и более агрегированные, сопоставимы со средними данного уровня, т.е. средние по подразделениям хозяйствующего субъекта (ХС) сопоставимы со средними по группе ХС.
3. Расчет средних на единицу облегчает сопоставление показателей, рассчитанных для совокупностей с разной численностью.
Поскольку средняя по сути своей представляет научную абстракцию, ей, кроме положительных черт, присущи и недостатки:
1. В средней погашаются индивидуальные различия отдельных единиц изучаемой совокупности (явления).
2. Статистические способы расчета средней в той или иной мере искажают оценку совокупности, нивелируя процедуру распространения признака по единицам совокупности. В результате возникают ошибки. При отсутствии регламента ошибки ее величина может быть достаточно высокой, что приведет к нарастанию ошибки в последующих расчетах с использованием средних.
8.2 Научные основы исчисления средних величин
Для того, чтобы средняя была более реальной и обеспечивала достаточно надежный результат, она должна быть правильно исчислена или определена. К расчету средних предъявляются следующие требования:
1. Качественная средняя может быть получена только по однородным однокачественным явлениям по изучаемому признаку. Невыполнение этого требования приводит к получению огульных и общих средних. Огульной называется средняя, подсчитанная по разным социально-экономическим типам. В пределах сферы рассчитывать средние нельзя. Предельный масштаб расчета средней – тип. Общаясредняя охватывает разнородные явления с одинаковым экономическим фоном или в одной экономической ситуации. Из двух средних (огульной и общей) ошибка второй меньше. Ошибка первой обязательно должна нивелироваться дополнительной корректировкой. От общих средних всегда можно перейти к менее общим, а от них – к дифференцированным.
2. Качественные средние получаются только на основе структурной группировки.
3. Качественная средняя имеет место при правильном выборе явления (единицы совокупности), на которое рассчитывается средняя. Поэтому реализация этого требования делит все статистические средние по их содержанию на следующие виды: модуль средней, устойчивая средняя, прогрессивная средняя и динамическая средняя. Именно эти четыре величины в их совокупности и позволяют объективно оценивать состояние явления, интенсивность (закономерность) его развития.
4. Получение качественных средних возможно в пределах всей совокупности (всего круга явлений) или в пределах типичной части их.
Классификация средних по способу их расчета. По этому принципу различают следующие величины:
· средняя арифметическая простая
![]()
· средняя квадратическая простая
![]()
· средняя геометрическая
![]()
· средняя гармоническая простая
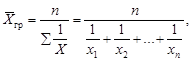
где Х – осредняемый признак; хi – частные (индивидуальные) значения признака у единиц совокупности; n – число единиц изучаемой совокупности.
Анализ приведенных формул позволяет выделить математические операции, основные для расчета той или иной средней. Для средней арифметической – это сложение значений признака в пределах совокупности, для средней квадратической – суммирование квадратов значений, для средней геометрической – произведение значений признаков, для средней гармонической – суммирование обратных значений осредняемого признака.
Эти процедуры в значительной степени определяют значимость средних или распространенность их в экономической статистике. Естественно, наиболее распространенной является средняя арифметическая, т.е. ее основная расчетная процедура – суммирование материальных значений признаков. Применение средней квадратической ограничено расчетами параметров, определяющих величину площади, средней геометрической – специальными расчетами.
Использование средней гармонической предопределено наличием в экономике взаимосвязанных признаков с обратной связью (производительность труда и трудоемкость, фондоемкость и фондоотдача, коэффициент оборачиваемости и коэффициент закрепления).
Приведенные формулы можно записать в несколько ином виде для результата группировки – вариационных рядов. Известно, что вариационный ряд распределения характеризуется не только значениями признака (уровнями ряда), но и частотами (частостями). Обозначив f – частоты, fi – частоту каждой группы вариационного ряда и хi – уровень ряда, получим средние, называемые взвешенными:
· средняя арифметическая взвешенная
![]()
· средняя квадратическая взвешенная
![]()
· средняя гармоническая взвешенная
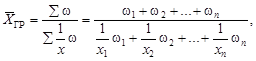
где w – признак (вес).
Таким образом, расчет средних для вариационных рядов предполагает процедуру взвешивания (определения объема качества в пределах уровня ряда), при которой частота является «весом». Для средней геометрической подобной записи не существует, так как процедура взвешивания при произведении невозможна.
Взвешивание, при котором «весом» является частота, называется формальным. Оно позволяет получить модуль средней и в этом случае наиболее распространенным видом средней является средняя арифметическая.
Математические свойства средней арифметической:
1. Сумма отклонений отдельных значений признака (вариантов) от средней арифметической равна нулю.
2. Если от каждого варианта отнять (прибавить) какое-либо произвольное постоянное число, то новая средняя уменьшится (увеличится) на это число.
3. Если каждый вариант умножить (разделить) на какое-либо число, то новая средняя увеличится (уменьшится) во столько же раз.
4. Если все частоты f разделить или умножить на одно и то же число, то средняя не изменится (это всегда дает возможность заменять частоты частостями).
Последнее свойство означает, что величина средней зависит не от абсолютных размеров «весов», а от соотношения между ними. Из этого частного вывода вытекает более общее правило: средняя зависит от размеров вариантов и соотношения «весов», т.е. от структуры совокупности. Именно этот вывод узаконивает наличие в статистике четырех видов средних по их качеству (первые три непосредственно связаны с этим выводом, четвертая косвенно предопределена им):
· модуль среднейжестко связан со структурой совокупности и при ее постоянстве не меняется;
· устойчивая средняя, оставаясь жестко связанной со структурой совокупности, меняется с изменением генеральной совокупности, т.е. устойчивая средняя – это модуль генеральной совокупности;
· прогрессивная средняя жестко связана с той частью совокупности, которая определяет ее развитие. Эта величина – самая мобильная из трех и оценивает предельный (экономически обоснованный) уровень средней при анализе развития явления на перспективу;
· динамическая средняя может быть получена от модуля или устойчивой средней умножением их на темп роста (развития) изучаемой совокупности в пределах устойчивости ее структуры.
Обе классификации средних (по способу их расчета и по качеству) связывает модуль (средняя арифметическая).
При сложной информации с большим числом наблюдений прибегают к комбинированному (унифицированному) способу расчета средних – способу моментов. Формулы для расчета средней этим способом имеют вид
![]()
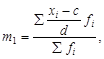
где хi – индивидуальное значение признака (вариант); n – число групп (единиц совокупности); m 1 – первый статистический момент; с – произвольная постоянная величина, на которую уменьшаются все значения хi ; d – общий множитель для всех значений разности (хi – с ); fi – «вес» (частота, частость) i -го уровня.
8.3 Неформальное взвешивание при расчете статистических средних
При расчете статистических средних возможна процедура взвешивания неформального характера. В этом случае в качестве «веса» выбирается признак, функционально связанный с осредняемым. Кроме того, «веса» могут быть простыми (один признак) и сложными (произведение нескольких признаков, которое формирует общий признак, функционально связанный с осредняемым).
Процедура неформального взвешивания обязательнав следующих случаях:
1. Осредняемый признак качественный, т.е. расчет его предполагает использование плановых (стандартизованных) признаков. Например, осредняемые признаки включают содержание полезного компонента в руде, цену продаж, себестоимость, производительность труда. Простые «веса» используются при расчете средних содержаний полезного компонента, себестоимости, производительности труда. Сложные «веса» необходимо применять при расчете средних цен.
2. Осредняемые признаки качественные, комплексные по содержанию и интегральные по схеме образования. Например, для цены продаж «весом» должен быть количественный признак, причем комплексный, рассчитанный как произведение одного количественного признака, связанного с осредняемым прямой или технологической связью, и одного или двух качественных признаков, связанных с количественным признаком жесткой прямой связью. Если осредняемый признак интегрального содержания, то количественный признак должен быть жестко связан с модулем осредняемого признака, а один, два или три качественных признака находиться в функциональной связи с остальной частью осредняемого признака.
3. Количественные признаки с высокой долей качества (себестоимость ГРР, выручка, запасы полезного ископаемого). Для таких показателей «вес» может быть только сложным. В его состав входят два количественных признака и до трех качественных. Количественные показатели связаны функциональной (косвенной) связью с осредняемым признаком или формируют экономический фон существования осредняемого признака. Качественные показатели должны быть стандартными или цензовыми и связанными с количественными признаками.
Если результатом формального взвешивания является модуль средней, то в результате неформальноговзвешивания получают устойчивую (1-й случай) и прогрессивную(2-й и 3-й случаи) средние. От уровня средней зависят многие статистические расчеты и СОП. Поэтому в статистике существует набор приемов по оценке надежности (качества) средней.
Первая группа этих приемов предполагает сопоставление устойчивой и прогрессивной средней с модулем и детерминацию (ограничение) этого отклонения в зависимости от содержания признака. Для количественных признаков отклонение средней от модуля допустимо в диапазоне от 20 до 25 % в сторону увеличения и от 10 до 15 % в сторону снижения. Для качественных признаков устойчивая средняя может отклоняться от модуля от ±3 до ±7 %; прогрессивная в сторону увеличения в пределах 5-8 %, в сторону снижения 10-12 %.
Вторая группа приемов связана с расчетом специальных показателей (моды и медианы), которые позволяют быстро и надежно оценивать качество средних и уточнять их содержание.
Мода – это наиболее часто встречающееся значение признака в изучаемой совокупности (в ряду распределения). Таким образом, мода – это значение признака с максимальной частотой. В интервальном ряду выделяется модальный интервал (интервал с максимальной частотой). Мода в пределах этого интервала определяется или приближенно (середина интервала), или точно по формуле
![]()
где X Мо – начальное значение интервала, содержащего моду; i Мо и f Мо – величина и частота модального интервала; f Мо-1 и f Мо+1 – частота интервала, предшествующего и следующего за модальным.
Медиана – это численное значение признака той единицы совокупности, которая стоит в середине ранжированного ряда (возрастающего). При нечетном числе единиц совокупности медиана – значение признака у четко регистрируемой середины совокупности. При четном числе единиц медианой является средняя арифметическая значений признаков у двух серединных единиц совокупности.
В интервальном ряду сначала аналогично описанной процедуре определяется медианный интервал. В пределах этого интервала медиана рассчитывается или упрощенно (середина интервала), или по формуле
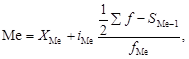
где X Ме – начальное значение интервала, содержащего медиану; i Ме – величина медианного интервала; Sf – сумма частот ряда; S Ме-1 – сумма накопленных частот в интервалах, предшествующих медианному; f Ме – частота медианного интервала.
Применение моды и медианы для оценки надежности (качества) средней зависит от характера ряда. Если значения моды, медианы и средней дискретного ряда совпадают, то средняя надежна и это модуль. Если мода и медиана попадают в другие уровни ряда, то возможны два случая:
· мода находится в предыдущем уровне, медиана – в нижнем уровне по отношению к средней. Это означает, что мы имеем надежную прогрессивную среднюю;
· мода находится в нижнем уровне, а медиана – в предыдущем. Полученная средняя не надежна.
Кроме сказанного возможно, что либо мода, либо медиана попадают в один интервал со средней. Если в один интервал со средней попадает мода, а медиана находится в предыдущем интервале, то получена надежная прогрессивная средняя. Если в один интервал со средней попадает медиана, а мода находится в нижнем интервале, то средняя не надежна.
Если мода, медиана и средняя интервального ряда попадают в один интервал, то получен модуль средней. Если мода и медиана попадают в другие уровни ряда, то возможны два случая:
· мода, медиана и средняя находятся в соседних уровнях. Имеет место надежная прогрессивная средняя;
· мода оказывается выше соседнего интервала* . Получена прогрессивная (стратегическая) средняя.
Если один из показателей (мода или медиана) попадает в один интервал со средней, а другой в соседний – результат аналогичен рассмотренному случаю для дискретного ряда.
9. Вариация признаков и статистические способы ее измерения
Вариацией называется наличие различий в численных значениях признака у единиц совокупности. Измерение вариации позволяет выделить стадии (уровни) изменения качества в пределах совокупности и, как следствие, вскрыть резервы для углубления качества в состоянии совокупности
Для измерения вариации важно установить базу (уровень) регистрации отклонения значений признака у единиц совокупности и содержание признака, вариация которого измеряется.
В экономической статистике для оценки процесса вариации экономических показателей можно принять две базы: модуль средней или устойчивую среднюю признака.
Содержание признака для оценки вариации (процесса) имеет большое значение, так как оно регламентирует показатели вариации для данного признака.
Показатели вариации. В экономической статистике для измерения вариации используются следующие показатели:
· Размах вариации – это разность между наибольшим и наименьшим значениями признака в изучаемой совокупности. Этот показатель регистрирует доверительный интервал колебания признака в изучаемой совокупности, поэтому его применение для оценки вариации крайне ограничено.
· Среднее линейное отклонение – это средняя арифметическая из абсолютных отклонений индивидуальных значений признака от его расчетной базы (модуля или устойчивой средней). Среднее линейное отклонение для первичного и вариационного рядов соответственно
![]()
![]()
· Дисперсия для первичного и вариационного рядов рассчитывается по формулам
![]()
![]()
· Среднее квадратическое отклонение для первичного и вариационного рядов вычисляется следующим образом:
![]()
![]()
· Коэффициенты вариации от среднего линейного отклонения и среднего квадратического отклонения соответственно
![]()
![]()
Здесь ![]() – среднее линейное отклонение; xi
– значение признака i
-й группы;
– среднее линейное отклонение; xi
– значение признака i
-й группы; ![]() – среднее значение признака в исследуемой совокупности; n
– число единиц совокупности; fi
– число единиц i
-й группы (частота или частость).
– среднее значение признака в исследуемой совокупности; n
– число единиц совокупности; fi
– число единиц i
-й группы (частота или частость).
Выбор показателя вариации зависит от содержания признака. Наиболее распространенные способы оценки вариаций признаков следующие:
· вариация количественных признаков – показатель среднего линейного отклонения (если размах вариации не превышает 5 % от стандартного уровня) и дисперсия;
· вариация качественных признаков, стандартных по номенклатуре, – коэффициенты вариации, причем предпочтение отдается V σ ;
· вариация качественных стандартизованных признаков, если они планируются, – коэффициент Vi , прочие – дисперсия;
· вариация количественных признаков с высокой долей качества – дисперсия и коэффициенты вариации. Чем более качественный признак, тем более надежный результат будет получен при использовании коэффициентов вариации.
В зависимости от показателя измерения вариации последние могут использоваться для индивидуальной или сравнительной оценки вариации.
Если оценка вариации ограничена дисперсией, то возможна только сравнительная оценка вариации одного признака в разных совокупностях. Однако такая оценка вариации через дисперсию важна, так как позволяет проводить дисперсионный анализ, в процессе которого выделяется вариация признака под влиянием внешних условий.
Если вариация признака оценивается через дисперсию, то кроме сравнительного анализа одного признака допустим такой же анализ разных признаков совокупности. Эти признаки, как правило, имеют одно наименование, но рассчитываются по-разному.
Если вариация признака измеряется коэффициентами вариации, то возможна нормативная оценка вариации признака. В этом случае, расчетный уровень вариации сопоставляется с нормативом.
Область применения показателей вариации. Если среднее линейное отклонение соответствует установленному регламенту (для количественных признаков), то является показателем устойчивостисредней в обычных рядах (не вариационных).
Дисперсия используется двояко: для оценки вариации признака и как инструмент проведения дисперсионного анализа. Как показатель вариации дисперсия используется для измерения колеблемости признаков одного содержания (одной природы). Кроме того, для стандартизованных признаков дисперсия позволяет установить доверительный интервал допустимого (регламентированного) колебания признака.
Дисперсионный анализ позволяет разделять комплексную причину колебания признака на две основные: внутреннюю и внешнюю по отношению к изучаемой совокупности. Способов проведения дисперсионного анализа достаточно много. Наиболее простой одновременно является базисным и основан на использовании балансовой связи между несколькими показателями дисперсии. Последняя может быть представлена в дифференцированном или агрегированном варианте. В основе перехода от агрегированного к дифференцированному описанию связи, когда число слагаемых растет, лежит дробление слагаемых по арифметической схеме (каждое слагаемое является суммой).
Среднее квадратическое отклонение, как и дисперсия, имеет двойное применение:
· как характеристика устойчивости комплексных признаков с высокой долей качества. При этом выполняется сравнительный анализ устойчивости комплексных признаков (однородных по содержанию) в пределах совокупности и однородных совокупностей;
· как расчетная база для получения наиболее надежных коэффициентов вариации V σ .
Коэффициенты вариации в экономической статистике оценивают в относительном измерении устойчивость признаков и поэтому используются при сравнительном анализе различных признаков, в том числе функционально связанных.
10. Дисперсионный анализ
Виды показателей дисперсии. Процесс группировки позволяет в пределах изучаемой совокупности выделять отдельные ее части по изучаемому признаку или признаку, функционально связанному с ним. Такое разделение возможно при вторичной группировке. Если каждая из выделенных частей не меняет содержания совокупности по данному признаку, то в пределах каждой части могут быть получены частные (внутригрупповые) дисперсии. Тогда дисперсия, определяемая в пределах всей совокупности, будет общей.
Пусть ![]() –
общая средняя;
–
общая средняя; ![]() – частная (внутригрупповая) средняя; j
– порядковый номер части совокупности (ее группы); s2
– общая дисперсия; s2
j
– внутригрупповая дисперсия; i
– порядковый номер значения признака; nj
– число единиц в группе. Тогда общая и внутригрупповая дисперсия соответственно
– частная (внутригрупповая) средняя; j
– порядковый номер части совокупности (ее группы); s2
– общая дисперсия; s2
j
– внутригрупповая дисперсия; i
– порядковый номер значения признака; nj
– число единиц в группе. Тогда общая и внутригрупповая дисперсия соответственно
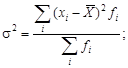
![]()
Найденные показатели дисперсии нельзя складывать, так как они разноуровневые (один по совокупности в целом, другой в пределах ее части). Поэтому частные показатели необходимо вывести на уровень совокупности, т.е. найти среднюю из частных дисперсий. Эта дисперсия получила название групповой:
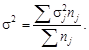
Поскольку ![]() , то для нахождения общей дисперсии через групповую необходимо знать еще одно слагаемое. Им является межгрупповаядисперсия, которая регистрирует изменение признака вследствие колебания внутригрупповых средних по сравнению с общей средней. Межгрупповая дисперсия
, то для нахождения общей дисперсии через групповую необходимо знать еще одно слагаемое. Им является межгрупповаядисперсия, которая регистрирует изменение признака вследствие колебания внутригрупповых средних по сравнению с общей средней. Межгрупповая дисперсия
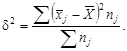
Она оценивает колебание признака под воздействием матричных факторов, формирующих внешнюю среду совокупности.
Правило трех сигм. Если общая и внутригрупповые средние являются модулями, то правомерно равенство
![]()
Это равенство в статистике получило название «правило трех сигм». Если средние (общая и внутригрупповые) устойчивы, то указанное правило принимается с рядом ограничений. Основное ограничение имеет вид ![]() Кроме того, разность
Кроме того, разность ![]() не должна выходить из интервала от 0,84s2
до 0,98s2
. Нижний крайний уровень данного интервала соответствует комплексным признакам с высокой долей качества, верхний – стандартизованным качественным признакам.
не должна выходить из интервала от 0,84s2
до 0,98s2
. Нижний крайний уровень данного интервала соответствует комплексным признакам с высокой долей качества, верхний – стандартизованным качественным признакам.
Это правило является базисной процедурой для выполнения дисперсионного анализа. Оно может использоваться в явном или дифференцированном виде. Кроме того, существует прямой (от агрегированного варианта к дифференцированному) и обратный (от дифференцированного к более агрегированному) порядок формирования балансового уравнения связи. Минимальное число элементов этой связи – от двух до четырех, максимальное – 12.
В экономической статистике горной промышленности агрегированный вариант включает в себя не более трех слагаемых. Для анализа показателей биржевой деятельности и банковских показателей их число увеличивают до четырех. В дифференцированном варианте дисперсионного анализа число показателей еще больше: для горной промышленности 6; для бирж 10-12; для банков 12.
Число слагаемых не влияет на сложность проведения дисперсионного анализа, важно лишь соблюсти следующие необходимые условия:
· однородность совокупности по изучаемому признаку;
· соответствие числа групп, выделенных в анализируемой совокупности, процессу накопления качества по изучаемому признаку;
· улучшение качественной основы изучаемого признака в пределах выделенных групп.
Схема дисперсионного анализа. Дисперсионный анализ проводится на основе «правила трех сигм» (общая дисперсия равна сумме групповой и межгрупповой). При этом в анализе выделяется два направления. Цель первого – характеристика устойчивости признака с учетом влияния на его колебания внешних признаков; цель второго – оценка надежности средней.
Первое направление дисперсионного анализа предполагает следующие процедуры:
1. Определение доли межгрупповой дисперсии в общей:
![]()
Это выражение, вытекающее из «правила трех сигм», без корректировки можно использовать только для количественных признаков. Для качественных признаков эта формула может использоваться, если значение функционального признака выше частного от деления факториальных признаков на 3-5 %. Если это условие не выполняется, то в формулу вводится корректирующий коэффициент Е :
![]() .
.
2. Установление нормативных пределов степени влияния внешних факторов на колебания изучаемого признака. Нормативные пределы влияния внешних факторов зависят от того, в каких пределах этим влиянием можно пренебречь. Нормативы дифференцированы по содержанию признака и по степени стандартизации признака. Для количественных стандартных признаков нормативы ужесточаются. Для количественных признаков допустимое ограничение γσ от 15 до 18 %; для качественных стандартных признаков: соответственно от 1 до 3 %; для количественных с высокой долей качества и одновременно стандартизованных признаков: 5-8 %.
3. Характер стандартности признака.
Второе направление дисперсионного анализа устанавливает связь между структурой общей дисперсии и соотношением моды и медианы. Принято считать, что средняя является модулем, если отношение моды к медиане больше единицы, но не более чем на 3-8 %. Это условие является вторичным и учитывается, если γσ ≤ 2¸3 %. Для устойчивой средней отношение моды к медиане больше единицы на 7-12 %, γσ ≤ 7¸8 %.
Дисперсионный анализ включает также измерение дисперсии так называемых альтернативных признаков, т.е. признаков, которыми обладает не каждая единица совокупности. Дисперсия альтернативного признака равна произведению доли единиц, обладающих этим признаком, на долю единиц, не обладающих им.
При выполнении расчетов дисперсионного анализа часто используется универсальный метод расчетов как общей дисперсии, так и ее слагаемых – способ моментов:
σ2
= d
2
(m
2
– m
1
2
); 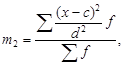
где m 1 – первый статистический момент; m 2 – второй статистический момент; c и d – произвольно выбранные числа.
11. Индексы
Индекс – это комплексный показатель, регистрирующий изменение сложного явления (признака) за известный интервал времени.
Математическая суть индекса – отношение, что нуждается в обосновании знаменателя (базы) индекса. База должна отвечать следующим требованиям:
· общее наименование с изучаемым показателем в исследуемом периоде;
· жестко регламентированный временной уровень (план, конкретный момент времени, конкретный период времени);
База может быть простой, сложной и интегральной. Однако у сложных вариантов базы должен быть модуль (простая база). Комплексный анализ сложного явления сопряжен с получением сложных вариантов базы.
Разнообразие явлений, изучаемых статистикой, предполагает использование системы индексов, в которой выделяются индивидуальные, групповые и общие индексы. Каждый вид индексов, в свою очередь, делится на подвиды. Кроме того, в процессе анализа выделяют связки индексов, которые позволяют легко переходить от частных индексов к обобщающему в пределах вида, а также от одного вида индексов к другому.
Индивидуальные индексы
характеризуют динамику простых процессов, выступающих элементами сложных явлений. Например, сложное явление «Реализация продукции» формируется такими элементами, как объем реализованной продукции в натуральном измерении, цена продажи, движение готовой продукции на складе. Из этих трех элементов цена продажи является простым, а два других – сложными. Соответственно с помощью индивидуальных индексов можно регистрировать только колебания цены продажи. Такой индекс строится по формуле ![]()
где Ц1 – изучаемый простой показатель в отчетном периоде; Ц0 – тот же показатель в базисном временном периоде.
Период колебания индивидуального индекса от 0 до 1. Эти индексы измеряются в долях единицы или в процентах.
Групповые индексы регистрируют колебания простых признаков по группе одноименных единиц совокупности или однородных явлений. Для явления «Реализация продукции» групповые индексы, как и индивидуальные, могут иметь место только для цены продаж. Это будут индексы изменения цены групп одноименных товаров, поставляемых в разные пункты, или одноименных видов продукции, реализуемых в разное время.
Групповые индексы могут быть получены из индивидуальных путем различных связок индексов. Для количественных признаков возможно суммирование (умножение) индивидуальных индексов для получения группового.
Среди групповых индексов выделяется категория субиндексов. Их расчет замыкается рамками части совокупности (генеральной совокупности).
Общие индексы дают сравнительную характеристику сложных явлений в целом, а также их частей. В рассмотренном выше явлении три сложных явления: общее – объем реализации и два формирующих его (объем реализованной продукции в натуральном измерении и движение готовой продукции).
Независимо от объема явления его сравнительная оценка (изменение в определенном интервале времени) выполняется на основе общих индексов.
Из трех рассмотренных видов индексов исходным и базисным является индивидуальный индекс, так как существуют способы и методы перехода от индивидуальных индексов к групповым и от них же к общим. Вместе с тем наиболее широкое применение в статистическом анализе имеют общие индексы.
Общие индексы делятся на две категории: индексы количества (индексы количественных явлений) и индексы качества (индексы качественных явлений). Каждая из подгрупп включает классические индексы, модификации классических индексов и неформальные индексы. Классическиеиндексы регистрируют изменения таких сложных явлений, каждое из которых может быть получено как произведение простых элементов, его формирующих. Модификации допускают такой порядок расчета сложного признака лишь в известных границах или с известными колебаниями простых признаков. Неформальные индексы строятся для сложных явлений интегрального содержания.
12. Общие индексы количественных признаков
Классический индекс. Если признак П может быть записан как произведение простых явлений (П = mLK ), то общий индекс изменения изучаемого признака П в интервале времени от 1 до 0 имеет вид
![]() ,
,
где m – качественный простой признак; L и K – количественные простые признаки.
Заметим, что в математической записи общего классического индекса качественные простые признаки обозначают строчнымибуквами, а количественные – прописными.
Сочетание количественных и качественных признаков зависит от числа признаков и в определенной мере обеспечивает тот или иной уровень глубины анализа, который возможен на базе общего индекса.
Экономическая статистика ограничивает число сомножителей при формировании общих индексов: от семи до двух. Классический вариант построения индекса позволяет перейти от агрегированной записи к дифференцированной. Дифференциации подлежат количественные признаки. При этом следует помнить, что каждому экономическому показателю (явлению) по природе его образования соответствует большее или равное число количественных признаков по отношению к качественным. Если выделено шесть или семь признаков сложного явления, то количественных признаков должно быть на два больше, чем качественных.
Правильно образованный общий индекс количества (общий индекс объема) позволяет сформировать на его основе систему агрегатных индексов.
Агрегатный индекс. Этот индекс оценивает изменение сложного явления вследствие колебания одного из простых признаков, его формирующих. Агрегатный индекс изменения явления П в результате колебания признака m записывается в виде I П(m ) . Запись индекса в результате колебания других признаков аналогична: I П(L ) и I П(K ) .
Критерием корректности анализа с использованием агрегатных индексов является равенство общего индекса произведению агрегатных:
![]()
Жесткость этой связи зависит от числа признаков, от их расположения и от приема дифференцирования. Рассмотрим процедуру построения агрегатных индексов на примере наиболее агрегированного варианта записи общего индекса товарооборота:
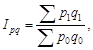
где р – цены продаж (качественный признак); q – объем продаж (количественный признак).
Этот общий индекс может быть разложен на два агрегатных индекса: один (Ipq (p ) ) регистрирует изменение товарооборота pq вследствие колебаний цен; второй (Ipq (q ) ) – изменение общего признака товарооборота вследствие изменения объема продаж.
По содержанию общий признак товарооборота pq является количественным. Его величина в значительной мере определяется объемом продаж q . Поэтому общий индекс товарооборота является произведением двух агрегатных индексов: первый является индексом количества и регистрирует влияние количественного признака, второй – индексом качества и регистрирует влияние качественного признака. Следовательно, уравнение будет выглядеть следующим образом:
![]() .
.
Процедура формирования агрегатного индекса основана на том, что простые признаки, кроме регистрируемого данным индексом, остаются неизменными, а этот признак изменяет свое значение и в числителе, и в знаменателе. Такой признак получил название индексного числа. Второй элемент агрегатного индекса – индексноеотношение – представляет собой совокупность значений простых признаков одного временного периода.
Вернемся к процедуре разложения общего индекса на систему агрегатных. Формируем первый индекс (индекс количества):

Выбор временного периода для признака-«веса» р
диктуется правилами статистики: агрегатный индекс от количественного признака использует «вес» (качественный признак) базового периода. В записанном индексе индексным числом является q
, а индексное отношение имеет вид ![]() .
.
Второй индекс (индекс качества)
![]()
Индексным числом в данном случае является р
. Время признака-«веса» вытекает из условия построения предыдущего индекса, в котором q
учтено в его предельном значении q
1
. Поэтому естественен его учет на этом уровне и в данном индексе. Индексное отношение имеет вид ![]()
Математическая проверка правильности построения агрегатных индексов проводится по формуле
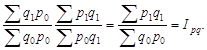
Статистическая проверка грамотности построения агрегатных индексов основана на правиле: индексное число агрегатного индекса количества должно быть правильной дробью, оно же в индексе качества – неправильной.
В теории статистики используются следующие правила формирования системы взаимосвязанных индексов в пределах общего индекса:
1. Первым индексом в цепи взаимосвязанных индексов является агрегатный индекс количества; замыкающим – индекс качества.
2. «Весом» для количественных признаков является качественный признак базисного уровня; для качественных – количественный признак отчетного периода.
3. Удовлетворяющие первым двум правилам построения индексы удовлетворяют и уравнению связи между общим индексом и системой агрегатных.
Строгое соблюдение этих правил реализуется для классических индексов количества и качества.
В статистике существует несколько способов построения системы взаимосвязанных индексов (разложения общего индекса). Наиболее распространенными являются метод цепной подстановки и метод индивидуального учета факторов.
Метод цепной подстановки. Развернем агрегированный классический индекс товарооборота в более дифференцированный вид: Z = pq = p aMk , где a – индекс изменения цен; М – количественный признак объема продаж; k – признак, функционально связанный с М . Такова экономически правильная запись дифференцированной формулы товарооборота.
Соответственно общий индекс товарооборота запишется следующим образом:
![]() .
.
Чтобы выполнить первое условие формирования системы взаимосвязанных индексов, необходимо запись изучаемого количественного признака Z изменить так: Z = Mkp a.
Агрегатные индексы количества примут вид
![]() ;
;
![]() ;
;
![]() ,
,
а агрегатный индекс качества
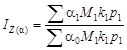 .
.
Однако выполнение этого правила еще не гарантирует достаточно надежную связь между общим индексом и системой агрегатных. Это, в свою очередь, требует соблюдения ряда условий для построения развернутой (неклассической) системы агрегатных индексов:
1. В общей записи изучаемого сложного явления Z число количественных факторов должно быть либо равно числу качественных, либо превышать его хотя бы на единицу. В нашем примере это условие не выполнено.
2. Из количественных признаков выбирается тот, от которого в наибольшей степени зависит величина изучаемого признака Z . Этому признаку присваивается первый номер. Остальные количественные признаки ранжируются по мере снижения их влияния на изучаемый признак.
3. Качественные признаки «привязываются» к количественным на основе функциональной связи между ними, и исходная формула записывается так, чтобы количественные и качественные признаки чередовались; при этом последним признаком должен быть качественный.
4. При таком расположении признаков первый индекс будет обязательно индексом количества, а последний – индексом качества.
5. Запись «весов» (сложных по составу) осуществляется следующим образом: без нарушения перечня признаков не использованный ранее (в других индексах) признак записывается по базисному периоду, а использованный – по отчетному.
Таким методом характеризуется изменение сложных явлений, включающих до восьми простых признаков, причем соблюдение перечисленных выше условий обеспечивает высокую точность расчетов. Предельный дисбаланс составляет 4 % в пользу произведения агрегатных индексов, т.е. общий индекс на 4 % меньше, чем произведение агрегатных. Достаточно надежные результаты требуют учета до пяти признаков.
Следует помнить, что для этого метода очень важно правильное ранжирование количественных факторов, что связано с анализом изучаемого явления.
Хотя в рассмотренном нами примере нарушено одно из условий, правильное ранжирование факторов позволяет получить результат в пределах регламента (4 %).
Метод индивидуального учета факторов. Этот метод менее надежен, но более прост, так как формирование агрегатных индексов (независимо от их содержания) предполагает использование «весов» в одном временном периоде (базисном). Однако необходимо соблюдать следующие требования:
· Соотношение признаков в записи общего, или комплексного, признака должно соблюдаться жестко: 50 % количественных, 50 % качественных; при общем числе признаков более четырех количественных признаков должно быть на один больше.
· Общее число признаков не должно превышать пяти.
Пусть изучаемый признак А записывается формулой: А = mFlC . Для процедуры ранжирования количественных признаков условимся, что признак С имеет больше влияния на А , чем F . Между качественными и количественными признаками существует взаимосвязь, которая позволяет выделить их пары: C – m ; F – l . Таким образом, можно записать исходную формулу в виде, удобном для составления цепи взаимосвязанных индексов: А = СmFl .
Сформируем систему агрегатных индексов:
![]()
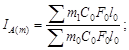
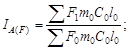
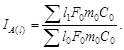
Построение начального индекса согласно и этому методу должно удовлетворять условиям построения агрегатных индексов в пределах общего индекса. Анализ индекса IA (С ) позволяет сделать вывод, что он удовлетворяет основному правилу построения агрегатных индексов по данному способу. Построение индекса IA (m ) не исходит из требований классики. Оно учитывает только требования данного метода. Построение индекса IA (l ) допускает отход от классики, так как это не агрегатный индекс качества, а его некоторая модификация – признаки «веса» в нем имеют не отчетный, а базисный уровень согласно данному методу.
Поскольку в данной записи имеет место отход от основного требования классики в построении цепи взаимосвязанных индексов (начальный признак – индекс количества, замыкающий – качества), то анализ по таким индексам будет не совсем точным. Неточность будет выражаться дисбалансом:
![]()
Рассмотренный метод дает достаточно надежный результат (дисбаланс 1-2 %) при трех факторах и широко применяется при внутрипроизводственном анализе (на предприятиях). Увеличение числа факторов сопряжено со значительным ростом дисбаланса: при пяти факторах до 8-12 %, при шести до 18-23 %.
Несмотря на неточность, этот метод широко используется, когда нет возможности получить информацию отчетного уровня прямым путем (не расчетным). Во всех остальных случаях более надежным является метод цепных подстановок.
Модификации классических агрегатных индексов количества и качества. Построение таких индексов рассмотрим на примере агрегатных индексов объема продаж Ipq (q ) и цены продаж Ipq (p ) . Необходимость построения модификаций связана с невозможностью прямо получить информацию: для признака q такие сложности возникают в отчетном периоде, а для признака р – в базисном. Проделаем выкладки для модификации индекса количества. Запишем формулу индекса:
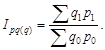
Известно, что индивидуальный индекс признака q
![]() Следовательно,
Следовательно, ![]() Заменим q
1
в формуле индекса этим произведением. Тогда
Заменим q
1
в формуле индекса этим произведением. Тогда
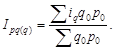
Итак, агрегатный индекс количества может быть выражен через индивидуальные индексы количественного признака. При этом агрегатный индекс является средней арифметической из индивидуальных индексов, «весом» в которой является общий признак базисного периода. Такая модификация действительно не содержит ни одного сомножителя отчетного уровня.
Проделаем аналогичные выкладки для получения модификации индекса качества. Индекс качества
![]() .
.
Так как ![]() то
то ![]() . После подстановки запишем
. После подстановки запишем
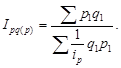
Агрегатный индекс качества также может быть выражен через индивидуальные индексы качественного признака. При этом такой модификацией агрегатного индекса качества является средняягармоническая из индивидуальных индексов, взвешенных по общему признаку отчетного периода. Видно, что в такой записи не содержится ни одного показателя базисного периода.
Полученные модификации не являются самостоятельными индексами, но лишь приемами расчета агрегатного индекса в определенных условиях. Поэтому такие модификации не должны использоваться при построении цепи взаимосвязанных индексов.
13. Абсолютные разности
Индексный анализ независимо от метода построения цепи взаимосвязанных индексов дополняется анализом абсолютных разностей.
Абсолютная разность – это разность между числителем и знаменателем индекса (общего или агрегатного). Точно так же, как существует балансовая связь между общим и агрегатными индексами, существует такая же связь и между абсолютными разностями.
Абсолютная разность по общему индексу равна сумме абсолютных разностей по агрегатным индексам. В общем виде в обозначениях рассмотренного выше примера (А = CmFl ) это записывается так:
![]() .
.
Это уравнение указывает на основное назначение данного анализа; именно наличие баланса абсолютных разностей убеждает в правильности выполненных расчетов. Кроме того, абсолютные разности более точно учитывают дисбаланс. В связи с этим абсолютные разности по разным общим признакам имеют разные пределы дисбаланса.
Абсолютные разности очень существенно дополняют индексный анализ по другой причине. Дело в том, что если индексный анализ всегда замкнут совокупностью (генеральной ее частью), то абсолютная разность может применяться для любых частей совокупности, даже для отдельных единиц совокупности (характерных представителей). Докажем это утверждение. Пусть формула общего индекса имеет вид
![]() .
.
Если замкнуть рамки индексного анализа представителями совокупности, общий индекс преобразуется к виду
![]() .
.
Это выражение непосредственно трансформируется в произведение двух индивидуальных индексов: ![]() .
.
Вместе с тем для отдельной единицы совокупности абсолютная разность по общему признаку может быть рассчитана, поскольку ![]() . Аналогично получим абсолютные разности вследствие изменения количественного и качественного признаков соответственно:
. Аналогично получим абсолютные разности вследствие изменения количественного и качественного признаков соответственно:
![]() ;
;
![]() .
.
Абсолютные разности в отличие от индексов – числа именованные, и потому они более наглядны, а в стоимостном измерении сопоставимы.
Следует помнить, что абсолютные разности классической природы всегда гарантируют баланс независимо от того, замыкается ли анализ рамками совокупности (генеральной части) или отдельными ее представителями. При этом абсолютные разности не образуются на базе модификаций классических индексов.
Метод цепных подстановок. Пусть исходный признак Z рассчитывается по формуле Z = aBC . После ранжирования факторов (Z = BCa ) запишем общий индекс, агрегатные индексы и соответствующие абсолютные разности:
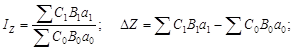
![]()
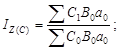
![]()
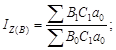
![]()
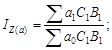
![]()
![]()
Абсолютные разности для характерного представителя совокупности следующие:
![]()
![]()
![]()
![]()
Полная идентичность записи и последовательности процедур анализа позволяет итоговый и промежуточные результаты для отдельных единиц совокупности сопоставлять с такими же результатами по совокупности в целом. Кроме того, результаты абсолютных разностей можно представить в относительном измерении:
![]()
и т.д. В таком варианте результаты могут быть отнесены к индексной базе, что позволяет получить целый набор индексов: для единиц совокупности – индивидуальные и групповые, а для совокупности в целом – агрегатные частные и модифицированные индексы.
Система модифицированных агрегатных индексов используется в статистике для корректировки средних, для уточнения показателей вариации и для разработки шести статистических моментов.
Метод индивидуального учета факторов . Выполним аналогичную процедуру формирования абсолютных разностей. Запишем общий и агрегатные индексы:
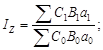
 .
.
Абсолютные разности для совокупности
![]()
![]()
![]()
![]() .
.
Абсолютные разности для отдельного представителя совокупности
![]()
![]()
Общие выводы о целесообразности расчета абсолютных разностей справедливы и в этом случае. Однако этот метод менее надежен, чем предыдущий, что сказывается и на результатах анализа через абсолютные разности. Проявляется это в нарушении баланса уже при четырех признаках. Допустимые пределы дисбаланса для количественных признаков с устойчивым модулем качества 2-4 %, с неустойчивым 3-5 %.
14. Общие индексы качественных признаков – индексы средних
Эта группа индексов представляет собой подсистему общих индексов качества и агрегатных индексов, сформированных на их основе. Построение общих индексов такого типа имеет ряд особенностей:
1. Поскольку изучаемым общим признаком является качественный, то сопоставляются его средние уровни в пределах совокупности (генеральной ее части).
2. Любой общий индекс качества можно представить как комбинацию общего индекса количества и индивидуального индекса количества.
3. Система агрегатных индексов, построенных на основе общего индекса качества, содержит только два индекса: индекс фиксированного состава и индекс структурных сдвигов.
4. Комплексный индексный анализ обязательно дополняется анализом абсолютных разностей, которые регистрируют изменение количественного признака, основным элементом которого является изучаемый качественный признак.
5. Для тех качественных признаков, которые имеют обратную связь (производительность и трудоемкость, фондоемкость и фондоотдача) составляются два варианта общих индексов качества: прямой и обратный.
Из общей теории статистики известно, что качественные признаки – мера качества, которая может быть индивидуальной (для каждой единицы совокупности) или общей (средний уровень по изучаемой совокупности). Поэтому формирование общего индекса качественного признака предполагает соизмерение среднего его значения по совокупности или генеральной части соответственно в отчетном и базисном периоде.
Рассмотрим специфику формирования таких индексов на примере показателя себестоимости. Общая формула для индекса себестоимости имеет вид
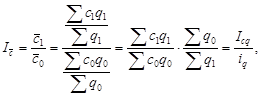
где с
1
и с
0
– показатели себестоимости по единицам совокупности соответственно в отчетном и базисном периодах; q
1
и q
0
– объем выпуска продукции по единицам совокупности в отчетном и базисном периодах; ![]() и
и ![]() – средняя себестоимость по совокупности в отчетном и базисном периодах.
– средняя себестоимость по совокупности в отчетном и базисном периодах.
Полученное выражение не является стадией комплексного статистического анализа, а используется для определения группового и общего индексов количества.
Вернемся к развернутой записи общего индекса: первый сомножитель в ней – общий индекс количества
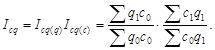
Поменяв индексы местами и разделив второй на дробь ![]() получим
получим
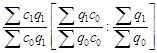 .
.
Выполнив сначала действия в скобках, после преобразований получим произведение агрегатных индексов общего индекса себестоимости:
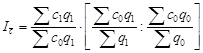 .
.
Общий индекс в такой записи получил название индекса переменного состава. Первый из агрегатных индексов – индекс фиксированного состава; второй – индекс структурных сдвигов.
Индекс фиксированного состава регистрирует изменение себестоимости (общего признака) за счет колебаний себестоимости по единицам совокупности. Эти изменения фиксируются при неизменной структуре совокупности. Последняя оценивается через признак, жестко связанный с изучаемым, – объем производства. При этом относительные величины структуры формируются, исходя из фактических значений такого признака.
Индекс структурных сдвигов, несмотря на необычность его записи, не нарушает записи общего индекса: делимое (числитель) – средняя себестоимость базисного периода при фактической структуре выпуска продукции; делитель (знаменатель) – та же средняя, но при базовой структуре выпуска продукции. Таким образом, этот индекс регистрирует изменение себестоимости вследствие изменений в структуре производства.
Кроме содержательных различий агрегатных индексов, различны и их функции: индекс фиксированного состава регистрирует изменение себестоимости под влиянием внутренних факторов, индекс структурных сдвигов – под влиянием внешних факторов.
В конкретной практике классическая форма индекса фиксированного состава не всегда возможна (например, при расчете индекса цен). В таких случаях используют специальные приемы формирования таких индексов, в основе которых лежит модуль индекса Струмилина.
Абсолютные разности . Абсолютные разности всегда определяются только по количественным признакам. Это требование статистики является исходным для анализа абсолютных разностей любой системы взаимосвязанных индексов. В рассматриваемом случае количественным признаком однородного содержания с изучаемым является сумма производственных затрат (издержки производства). Обозначим ее С . Тогда
С = сi qi ,
где сi – cебестоимость продукции у единицы совокупности; qi – объем продукции у каждой из единиц изучаемой совокупности.
Абсолютная разность сложного количественного признака (в данном случае производственных затрат) определяется как разность числителя и знаменателя его общего индекса:
![]()
где DС – абсолютная разность производственных затрат; с 1 и с 0 – индивидуальные значения себестоимости у единиц изучаемой совокупности в отчетном и базисном периодах соответственно; q 1 и q 0 – объемы производства по единицам совокупности в отчетном и базисном периодах соответственно.
Если вместо индивидуальных значений себестоимости использовать среднюю себестоимость ![]() то формула для расчета производственных затрат примет вид
то формула для расчета производственных затрат примет вид
![]()
Следовательно, изменение производственных затрат можно рассматривать в зависимости от колебаний фактических значений средней от плановых себестоимости и объемов производства в целом по изучаемой совокупности. Иначе говоря, абсолютная разность производственных затрат может быть представлена как сумма
![]()
где ΔС
S
q
и ![]() – абсолютные разности производственных затрат вследствие изменений объема производства и средней себестоимости соответственно.
– абсолютные разности производственных затрат вследствие изменений объема производства и средней себестоимости соответственно.
В свою очередь, первое слагаемое, которое регистрирует изменение производственных затрат под влиянием объема производства, в развернутом виде может быть записано следующим образом:
![]()
Второе слагаемое, характеризующее изменение производственных затрат из-за колебаний средней себестоимости, может быть выражено так:
![]()
Это общая запись абсолютной разности сложного признака (производственных затрат), в состав которого входит изучаемый качественный признак (себестоимость); ее можно дифференцировать, используя формулы агрегатных индексов, выступающих как структурные элементы индекса переменного состава: индекса фиксированного состава ![]() и индекса структурных сдвигов
и индекса структурных сдвигов ![]() .
.
В дифференцированной записи
![]()
Запишем слагаемые в развернутом виде:
![]()
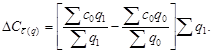
Таким образом, первое слагаемое ![]() является разностью между числителем и знаменателем индекса фиксированного состава, а составляющая
является разностью между числителем и знаменателем индекса фиксированного состава, а составляющая ![]() – соответственно разностью делимого и делителя индекса структурных сдвигов, умноженной на суммарный объем производства в отчетном периоде.
– соответственно разностью делимого и делителя индекса структурных сдвигов, умноженной на суммарный объем производства в отчетном периоде.
Из стоимостных качественных показателей только себестоимость позволяет сформировать индекс фиксированного состава. Все остальные стоимостные показатели для выполнения индексного анализа требуют применения индексов Струмилина.
Особенности построения общих индексов качества обратным методом
. Рассмотрим эти особенности на примере индекса производительности труда. Введем следующие обозначения: р
– производительность труда; Q
– объем производства; N
– численность работников (затраты живого труда). Тогда ![]() .
.
Процедура построения индекса переменного состава прямым методом аналогична рассмотренной выше процедуре формирования этого индекса для себестоимости:
· сначала записываем индекс переменного состава (индекс средней производительности труда) в общем виде:
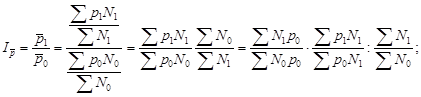
· затем путем перестановки сомножителей и делением второго на дробь ![]() получаем развернутую запись индекса переменного состава:
получаем развернутую запись индекса переменного состава:
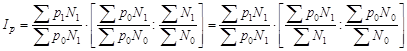 ,
,
где ![]() – индекс фиксированного состава производительности труда;
– индекс фиксированного состава производительности труда; ![]() – индекс структурных сдвигов этого показателя,
– индекс структурных сдвигов этого показателя,
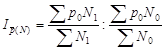 .
.
Анализ с использованием индексов качества подразумевает две стадии: индексный анализ и анализ через абсолютные разности.
Порядок выполнения анализа на базе абсолютных разностей рассмотрен выше для показателя себестоимости. При первом методе определения производительности этот порядок сохраняется. Вначале выбирается сложный количественный признак, в состав которого входит изучаемый (производительность труда). Таким признаком является объем производства ![]() .
.
Выразим объем производства через среднюю производительность труда ![]() и суммарные затраты живого труда (численность работников в целом по изучаемой совокупности SN
).
и суммарные затраты живого труда (численность работников в целом по изучаемой совокупности SN
).
Абсолютная разность объема производства в общем виде
![]()
где
![]()
![]()
Величина ![]() может быть записана в более конкретном виде с учетом влияния факторов, вызывающих изменение средней производительности труда:
может быть записана в более конкретном виде с учетом влияния факторов, вызывающих изменение средней производительности труда:
![]()
Первое слагаемое этой суммы определяется как разность числителя и знаменателя индекса фиксированного состава ![]() , второе – соответственно как разность делимого и делителя индекса структурных сдвигов
, второе – соответственно как разность делимого и делителя индекса структурных сдвигов ![]() , умноженная на суммарную численность в отчетном периоде:
, умноженная на суммарную численность в отчетном периоде:
![]()
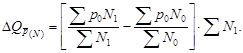
Кроме прямого способа расчета показателя производительности труда, существует обратный (через трудоемкость): ![]() где t
– трудоемкость работ. Отсюда
где t
– трудоемкость работ. Отсюда ![]() т.е. индивидуальный индекс производительности труда через трудоемкость является зеркальным отражением индивидуального индекса этого показателя при прямом способе его расчета
т.е. индивидуальный индекс производительности труда через трудоемкость является зеркальным отражением индивидуального индекса этого показателя при прямом способе его расчета ![]() . С учетом этой зависимости запись процедуры формирования общего индекса производительности труда обратным способом и выделения его составляющих (индексов фиксированного состава и структуры) выглядит следующим образом:
. С учетом этой зависимости запись процедуры формирования общего индекса производительности труда обратным способом и выделения его составляющих (индексов фиксированного состава и структуры) выглядит следующим образом:
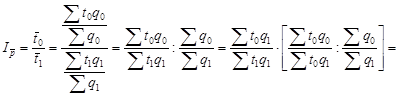
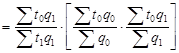 .
.
Анализ записи формулы позволяет выделить два основных момента обратного порядка регистрации общего индекса качества и его составляющих:
· в обратной записи индексное число является зеркальным отражением его дроби в прямой записи (в прямой записи ![]() в обратной
в обратной ![]()
· «веса» в агрегатных индексах не меняют своих временных значений и остаются такими же, как в прямой записи.
Обратный порядок формирования общего индекса качества должен использоваться в следующих случаях:
1) при отсутствии информации (полном или частичном) для расчета изучаемого признака прямым методом;
2) в случае, когда объем продукции представлен продукцией разных наименований или услугами разного содержания. Именно это очень часто определяет выбор записи и, как следствие, необходимость переводить продукцию в трудовое измерение;
3) для универсальных вариантов анализа различных блоков промышленных групп ХС или финансово-промышленных групп.
Рекомендательный библиографический список
Основной:
1. Ефимова М.Р. Общая теория статистики: Учебник / М.Р.Ефимова, Е.В.Петрова, В.Н.Румянцев. М.: ИНФРА-М, 1998. 416 с.
2. Общая теория статистики: Учебник / И.И.Елисеева, М.М.Юзбашев. М.: Финансы и статистика, 2002. 280 с.
3. Общая теория статистики: Учебник / Под ред. Г.С.Кильдишева. М.: Статистика, 1980. 432 с.
4. Теория статистики: Учебник / Под ред. Р.А.Шмоловой. М.: Финансы и статистика, 2002. 560 с.
Дополнительный:
5. Гусаров В.М. Теория статистики: Учеб. пособие для вузов. М.: Аудит, ЮНИТИ, 1998. 247 с.
6. Дубров А.М. Многомерные статистические методы / А.М.Дубров, В.С.Мхитарян, Л.И.Трошин. М.: Финансы и статистика, 2001. 368 с.
7. Практикум по теории статистики: Учеб. пособие / Под ред. Р.А.Шмоловой. М.: Финансы и статистика, 2002. 416 с.
![]()
Оглавление
Введение
1. Статистическое наблюдение. Классификация признаков явлений
2. Сводка и группировка
3. Ряды распределения
4. Графическое изображение рядов распределения
4.1. Уровневые графики (гистограмма, полигон распределения)
4.2. Интегральные графики
5. Динамические ряды
6. Статистические таблицы
7. Абсолютные и относительные величины
8. Средние величины
8.1. Понятие о средних в статистике
8.2. Научные основы исчисления средних величин
8.3. Неформальное взвешивание при расчете статистических средних
9. Вариация признаков и статистические способы ее измерения
10. Дисперсионный анализ
11. Индексы
12. Общие индексы количественных признаков
13. Абсолютные разности
14. Общие индексы качественных признаков – индексы средних
Рекомендательный библиографический список
* В качестве оценочного критерия для россыпей принято критическое содержание, превышающее среднее в 8-13 раз.
* Для составления пропорции используем любой уровень ряда столбцов 5 и 6. Здесь использован 4-й уровень.
* Попадание медианы в нижний интервал исключено.